혼공9기 혼공머신 1주차 시작합니다.
✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 01-02
기본 미션: 구글코랩 만들기, 코랩 캡처,
선택 미션: 02-1 확인문제 풀고, 풀이 과정 정리
코랩 노트북을 하나 만들어서 처음부터 02-2까지 한 번에 주욱 했습니다.
기본 미션: 코랩
01-3 마켓과 머신러닝
도미와 빙어 데이터로 생선 분류 하기
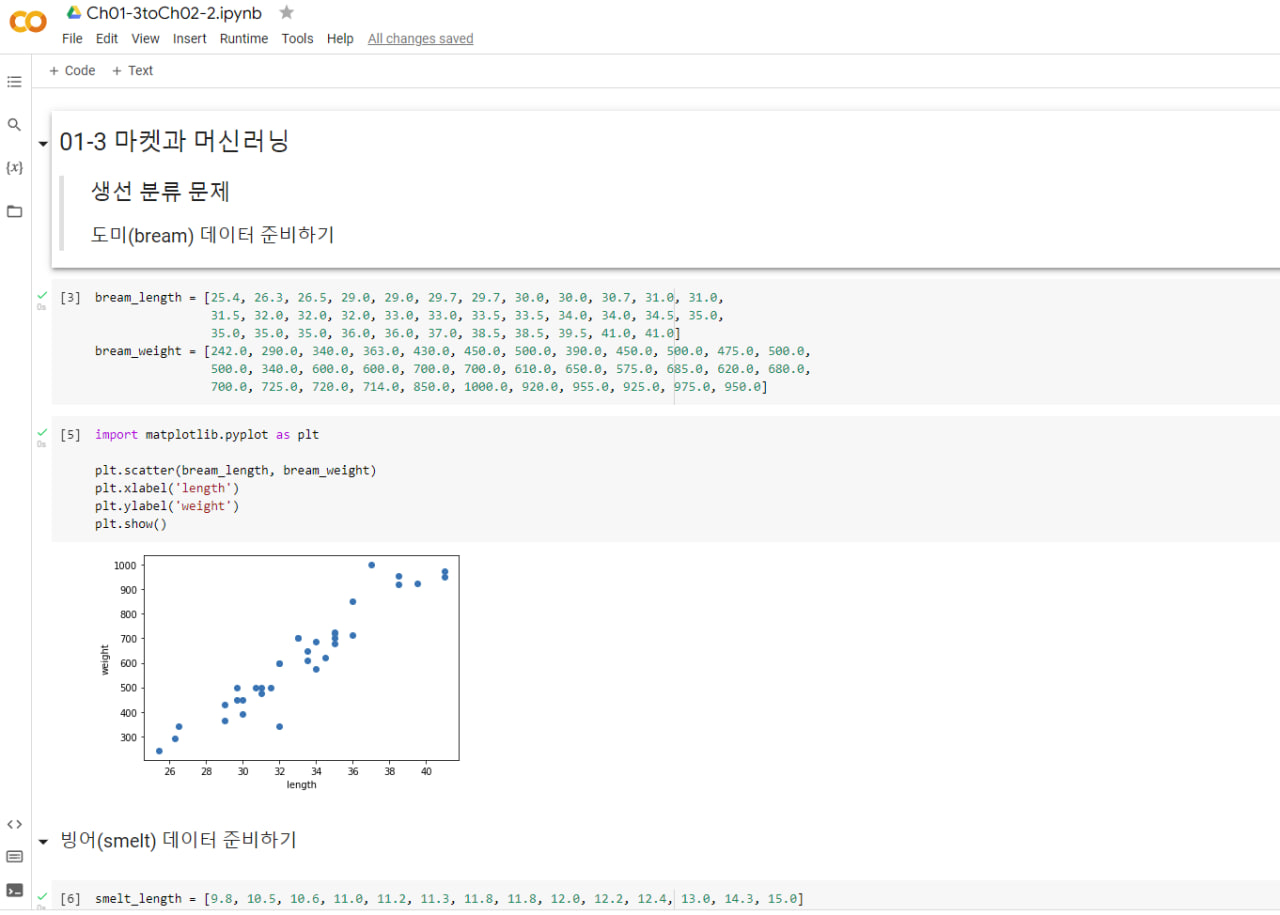
첫 번째 머신러닝 프로그램
확인 문제
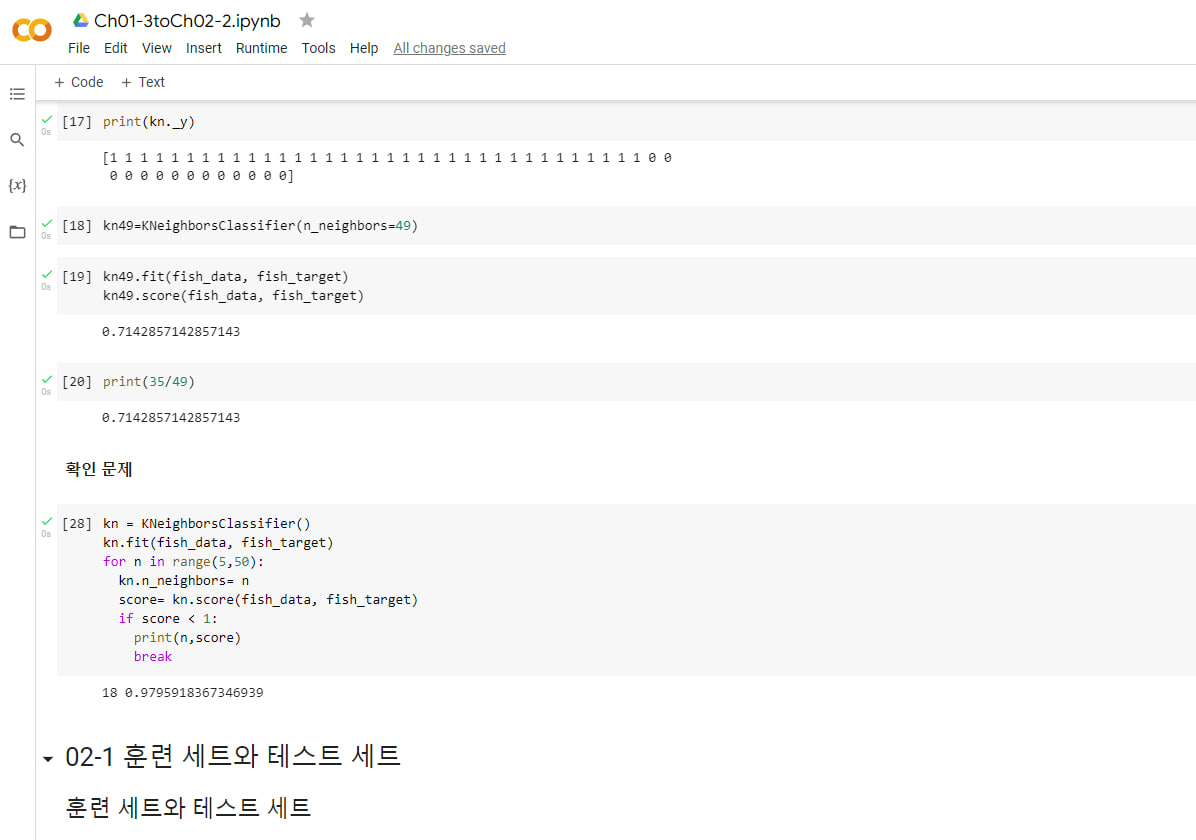
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
for n in range(5,50):
kn.n_neighbors= n
score= kn.score(fish_data, fish_target)
if score < 1:
print(n,score)
break
02-1 훈련 세트와 테스트 세트
두 번째 머신러닝 프로그램
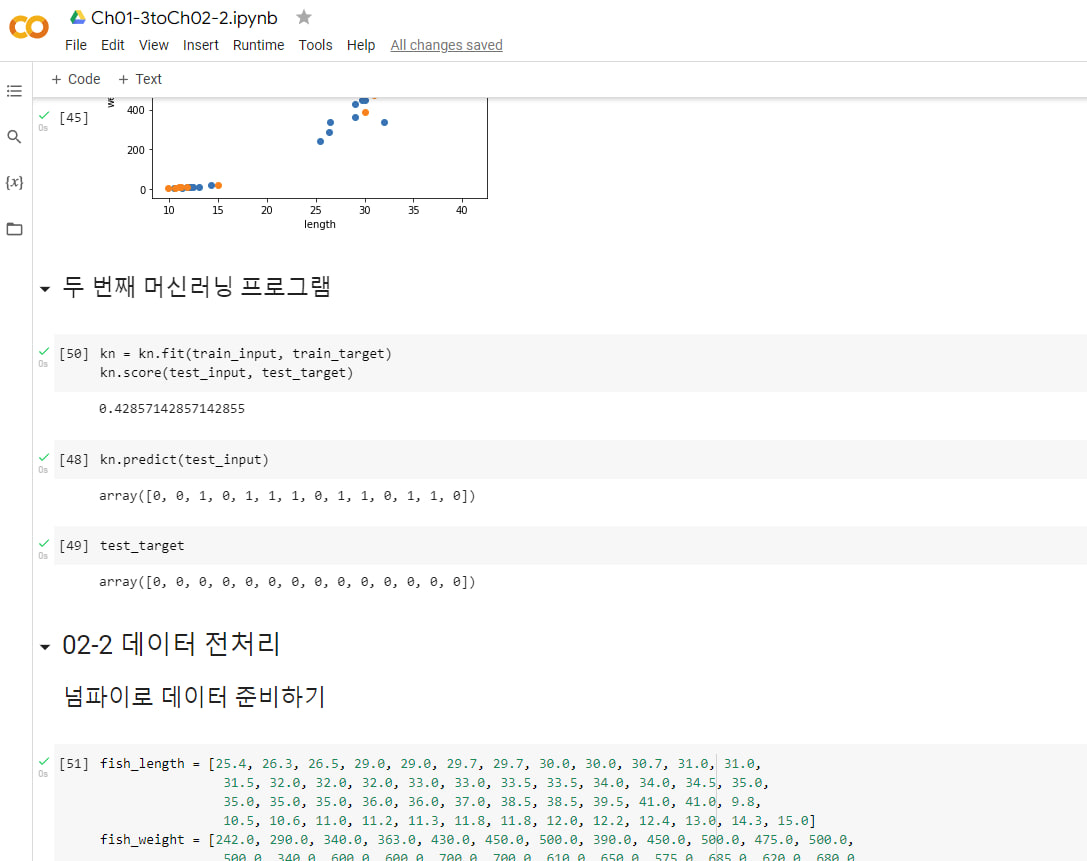
02-2 데이터 전처리
데이터를 표현하는 기준이 다르면 거리 기반인 알고리즘이 예측불가능. 특성값을 일정한 기준으로 맞춰주는 것이 데이터 전처리.
표준점수(Z점수)는 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냄. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교 가능
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
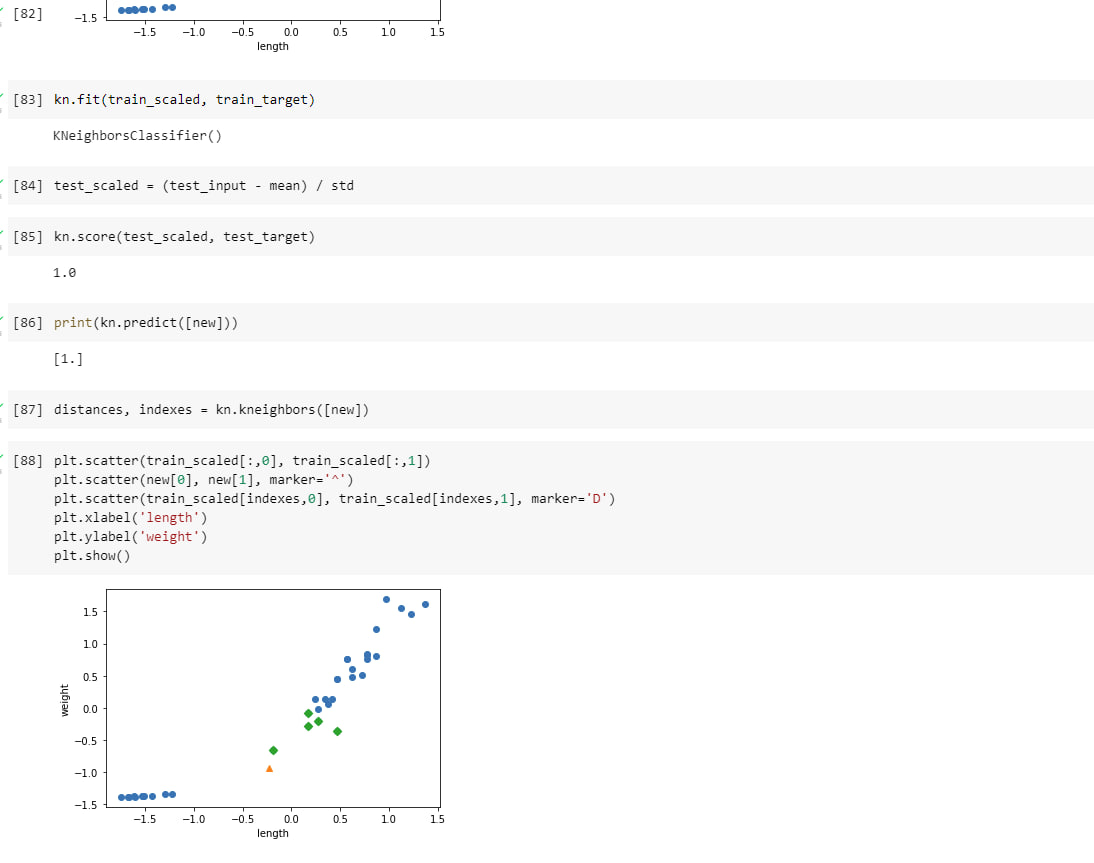
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
kn.score(test_scaled, test_target)
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
Github
https://gist.github.com/rickiepark
선택 미션: 확인 문제
-
지도학습은 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는데 활용. 1장부터 사용한 k-최근접 이웃이 지도학습 알고리즘.
-
샘플링이 한쪽으로만 치우쳤다는 의미의 샘플링 편향. 훈련 세트와 테스트 세트를 나누기 전에 데이터를 섞든지 아니면 골로루 샘플을 뽑아서 세트들을 만들어 주어야 함. 파이썬의 배열 라이브러리 넘파이numpy가 이런 작업을 간편하게 처리할 수 있도록 해 줌.
-
행 - 선 - 샘플 갯수
열 - 특성 - 생선 무게나 길이 같은 데이터 표현하는 성질
🙋♂️Q&A: 박해선 저자님의 github
💻유튜브 강의: 👉전체 강의 목록
