혼공 2주차 미션 완수.
✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 03
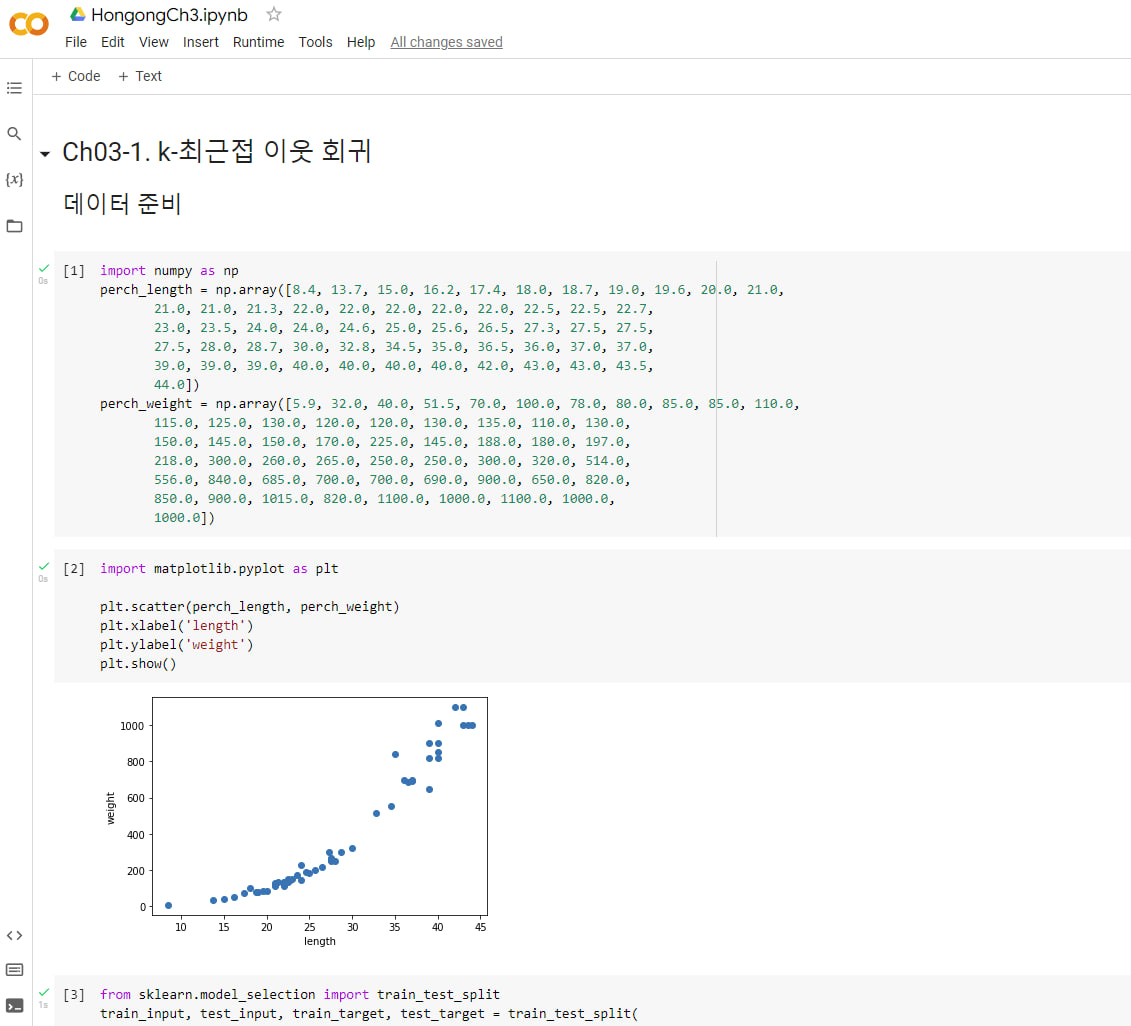
기본 미션: Ch.03-1 2번 문제 출력 그래프 인증하기
선택 미션: 모델 파라미터에 대해 설명하기
#혼공학습단 #혼공 #혼공머신
잠깐 복습: 저자 유튜브 직강
numpy broadcasting 브로드캐스팅은 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능
scikit-learn train_test_split 훈련세트와 테스트세트로 나누는 함수. 기본 값 0.25. stratify 매개변수에 클래스 레이블이 담긴 배열을 전달하면 클래스비율에 맞게 훈련 세트와 테스트 세트를 나눕니다.
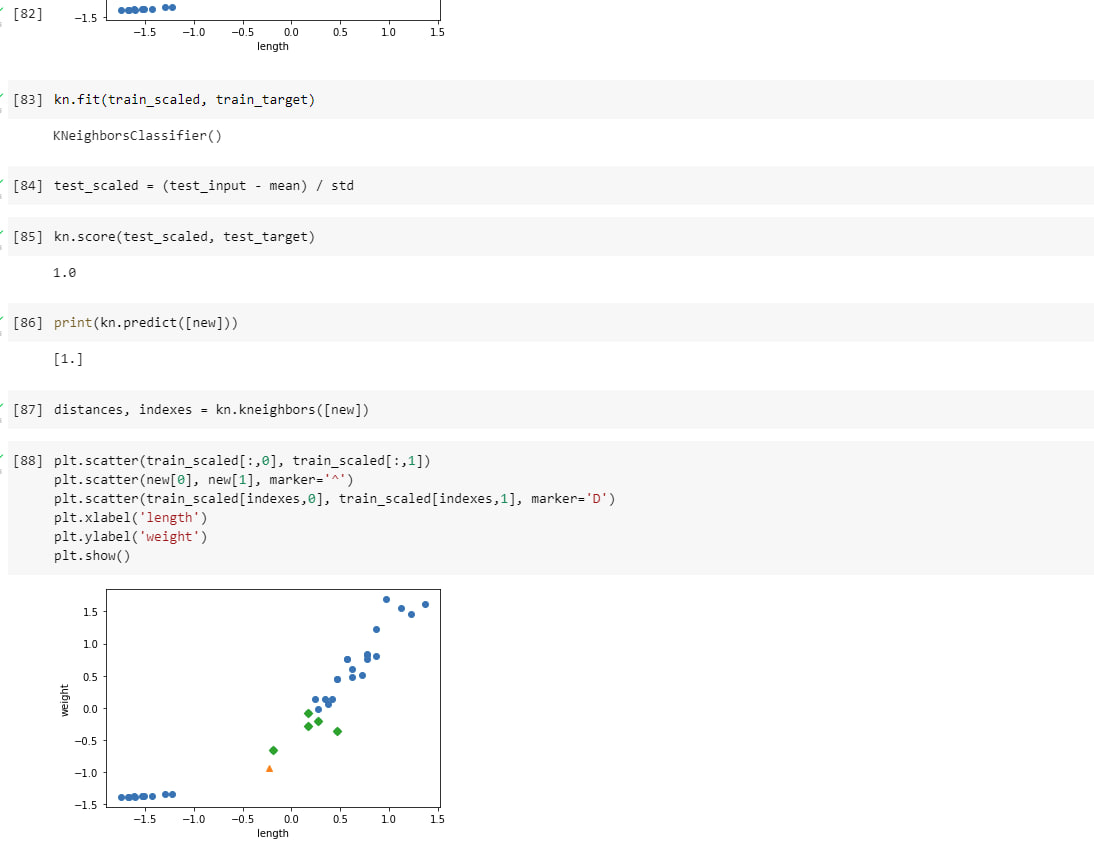
kneighbors()는 k-최근접 이웃 객체의 매서드. 입력한 데이터에 가장 가까운 이웃을 찾아 거리와 이웃 샘플의 인덱스를 반환.
Ch3. 회귀 알고리즘과 모델 규제 직강
6강. 회귀 문제를 이해하고 k-최근접 이웃 알고리즘으로 풀어 보기
k-최근접 이웃 회귀는 k-최근접 이웃 알고리즘을 사용해 회귀 문제를 품. 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측으로 삼음.
결정계수(R2)는 대표적인 회귀 문제의 성능 측정 도구. 1에 가까울수록 좋고, 0에 가까울수록 성능 나쁜 모델.
과대적합: 모델의 훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때 일어남.
과소적합: 모든 세트 성능이 모두 동일하게 낮거나, 훈련 세트 성능 < 테스트 세트 성능. 더 복잡한 모델을 사용해 훈련 세트에 잘 맞는 모델을 만들어야 함.
기본 미션: Ch.03-1 2번 문제 출력 그래프 인증하기
k-최근접 이웃 회귀 객체
knr = KNeighborsRegressor()
x = np.arange(5, 45).reshape(-1, 1)
for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target)
prediction = knr.predict(x)
# 훈련 세트와 예측 결과 그래프
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()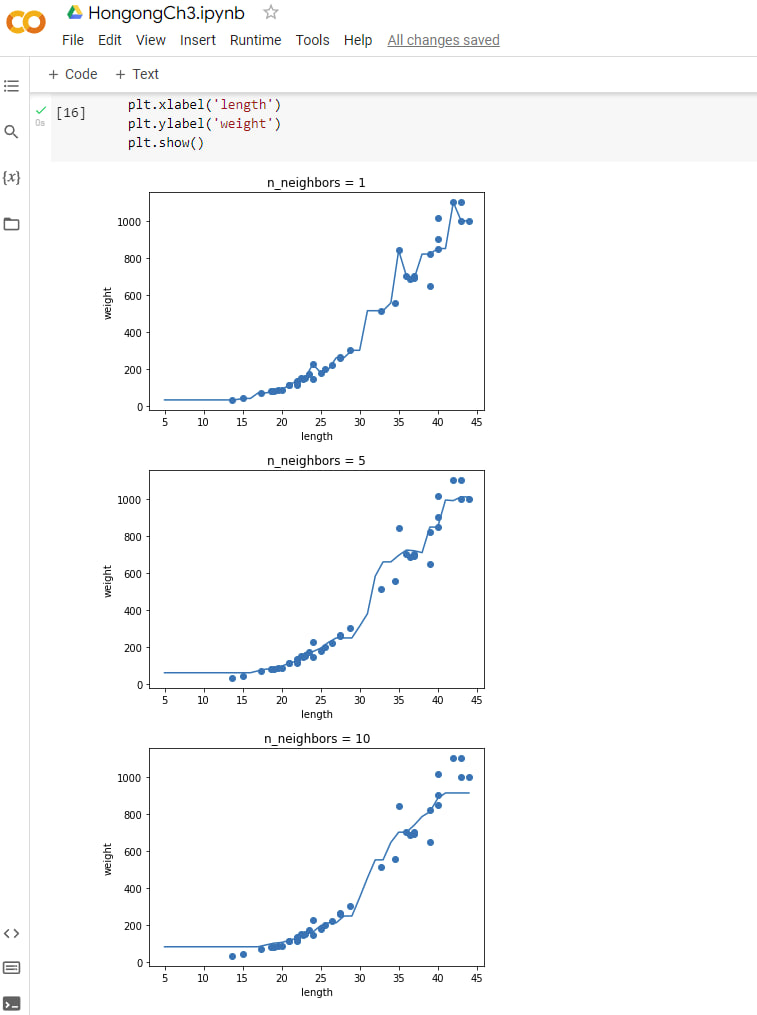
선택 미션: 모델 파라미터 설명하기
모델 파라미터: 선형 회귀가 찾은 가중치처럼 머신러닝 모델이 특성에서 학습한 파라미터
(예) 선형 회귀 모델이 찾은 방정식의 계수 (coefficient), 절편 (intercept)

LinearRegression: scikit-learn의 선형 회귀 클래스
다항 회귀 polinomial regression 모델을 훈련할 수 있는 클래스
train_poly = np.column_stack((train_input 2, train_input))
test_poly = np.column_stack((test_input 2, test_input))
lr = LinearRegression()
lr.fit(trainpoly, train_target)
print(lr.predict([[502, 50]]))
print(lr.coef, lr.intercept_)
릿지: 규제가 있는 선형 회귀 모델, 계수를 작게 만들어 과대적합을 완화시킴
라쏘: 규제가 있는 선형 회귀 모델. 릿지와 달리 계수 값을 0으로 만들 수 있다.
하이퍼 파라미터: 머신러닝 알고리즘이 학습하지 않는 파라미터. 사람이 사전에 지정.
(예) 릿지와 라쏘의 규제 강도 alpha 파라미터
핵심 패키지와 함수 pandas read_csv()
사이킷런 변환기: 특성을 만들거나 전처리 하기 위한 다양한 클래스
(예) PolynomialFeatures 클래스, 규제를 적용하기 전에 정규화하는 변환기 StandardScaler
PolynomialFeatures 다항 특성: 주어진 특성을 조합하여 새로운 특성을 만듬
interaction only=True : 거듭제곱 항은 제외되고 특성 간의 곱셈 항만 추가, 기본값=False
include bias=False: 절편을 위한 특성을 추가 않음. 기본값=True
🙋♂️Q&A: 박해선 저자님의 github
💻유튜브 강의: 👉전체 강의 목록
