✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 05
기본미션: 교차 검증을 그림으로 설명하기
선택미션: Ch.05(05-3) 앙상블 모델 손코딩 코랩 화면 인증하기
기본미션: 교차 검증을 그림으로 설명하기
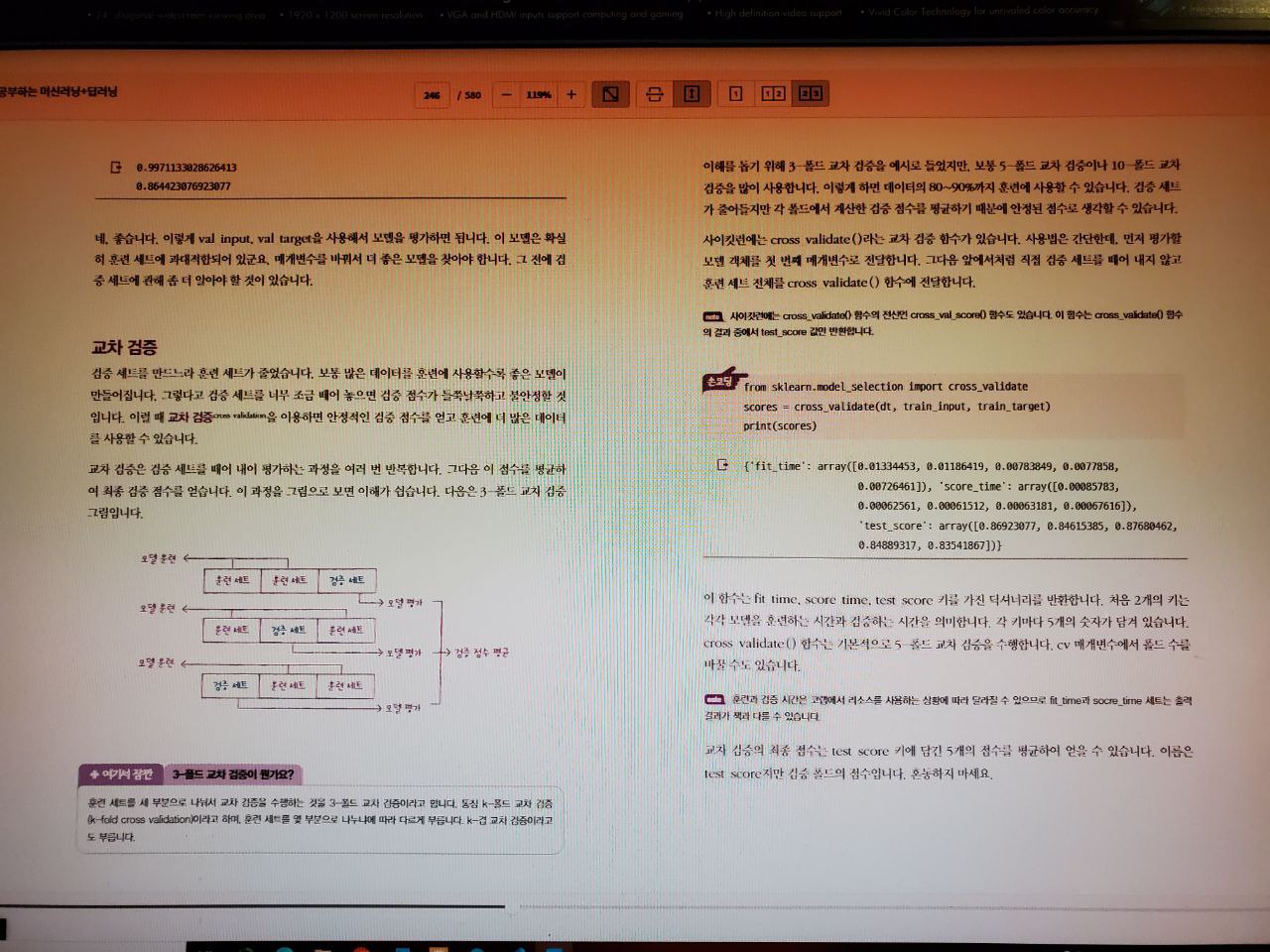
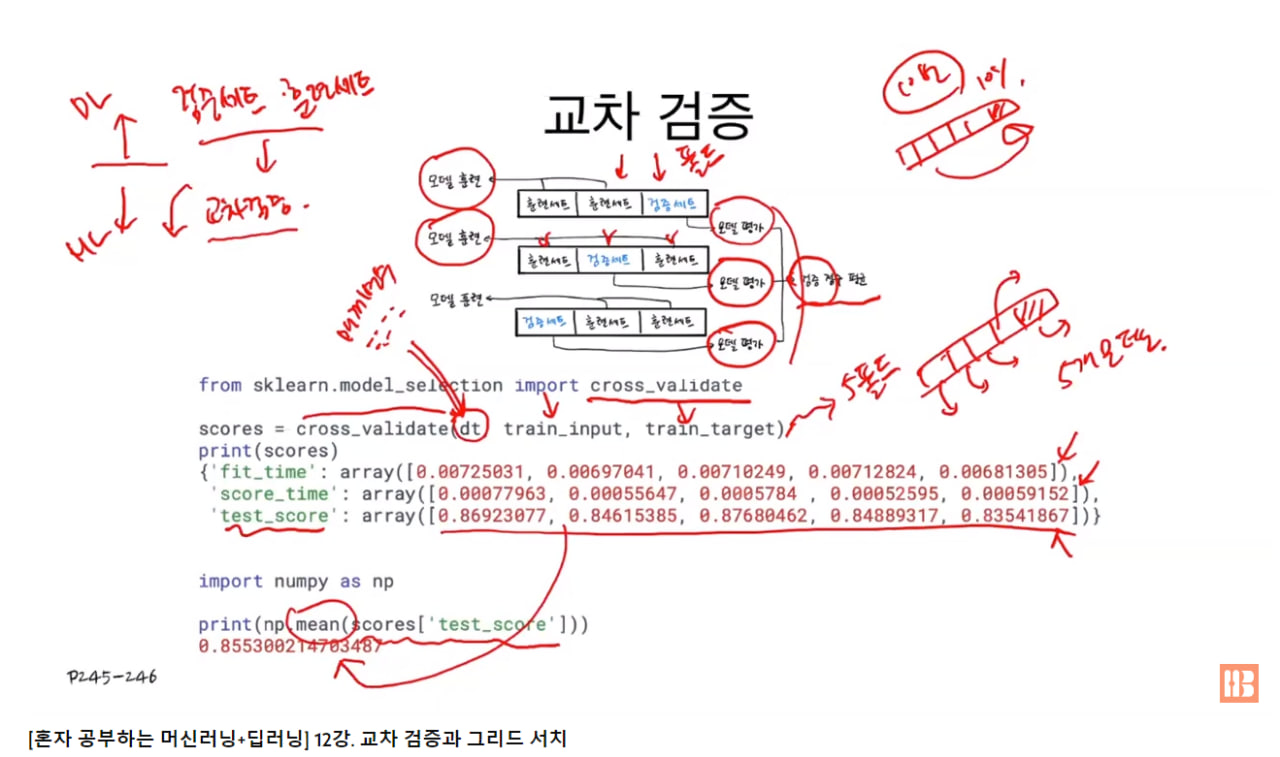
교차 검증은 훈련 세트를 여러 폴드로 나눈 다음 한 폴드가 검증 세트(하이퍼파라미터 튜닝을 위해 모델 평가시, 테스트 세트를 사용하지 않기 위해 훈련 세트에서 떼어 낸 데이터 세트)의 역할을 하고 나머지 폴드에서는 모델을 훈련하는 식으로 모든 폴드에 대해 검증 점수를 얻어 평균하는 방법.
검증 세트를 만드느라 훈련 세트가 주는데 검증 세트를 너무 조금 떼어 놓으면 검증 점수가 들쭉날쭉하고 불안정하니 교차 검증을 이용하여 검증 점수를 얻고 훈련에 더 많은 데이터 사용 가능.
scikit-learn
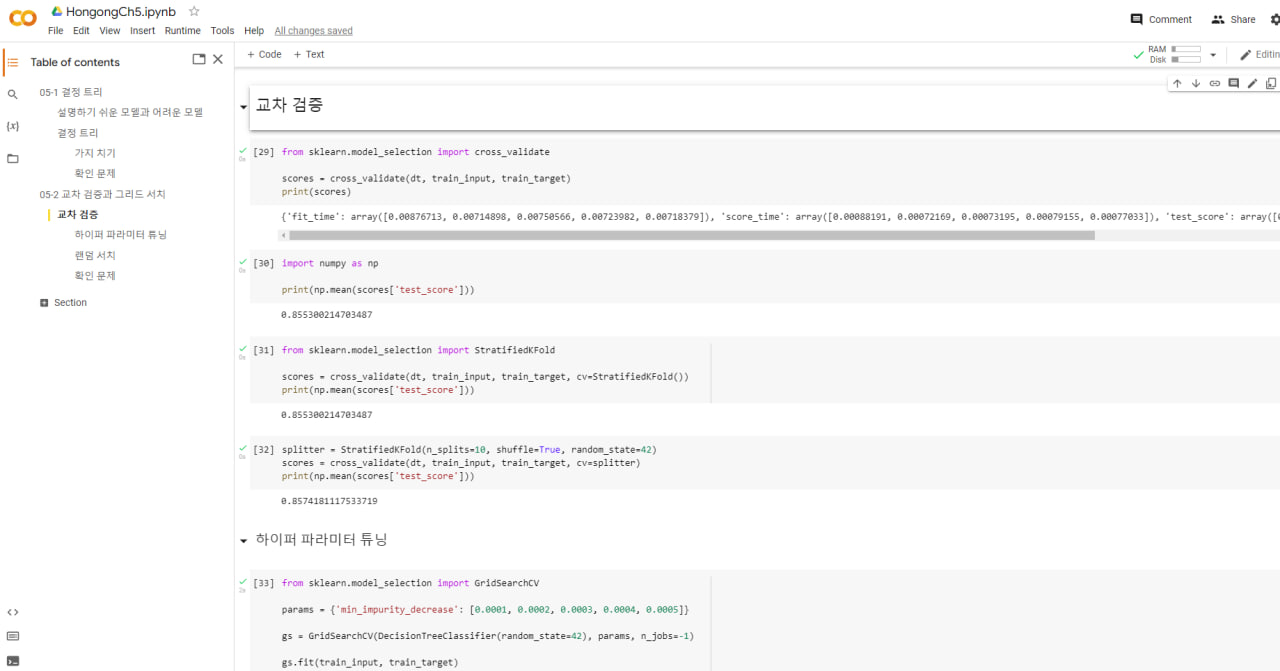
cross_validate()는 교차 검증을 수행하는 함수
첫 번째 매개 변수에 교차 검증을 수행할 모델 객체를 전달. 두 번째와 세 번째 매개변수에 특성과 타깃 데이터를 전달. scoring 매개변수에 검증에 사용할 평가 지표 지정 가능. cv 매개 변수에 교차 검증 폴드 수나 분할기(splitter) 객체 지정 가능. 기본값은 5 (5-fold 교차 검증).
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
회귀일 때는 KFold 클래스를 사용하고 분류일 때는 StratifiedKFold 클래스 사용. n jobs 매개 변수는 교차 검증 수행시 사용할 CPU 코어 수 지정 (기본값 1, 하나의 코어, -1지정이면 시스템에 있는 모든 코어 사용)
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))
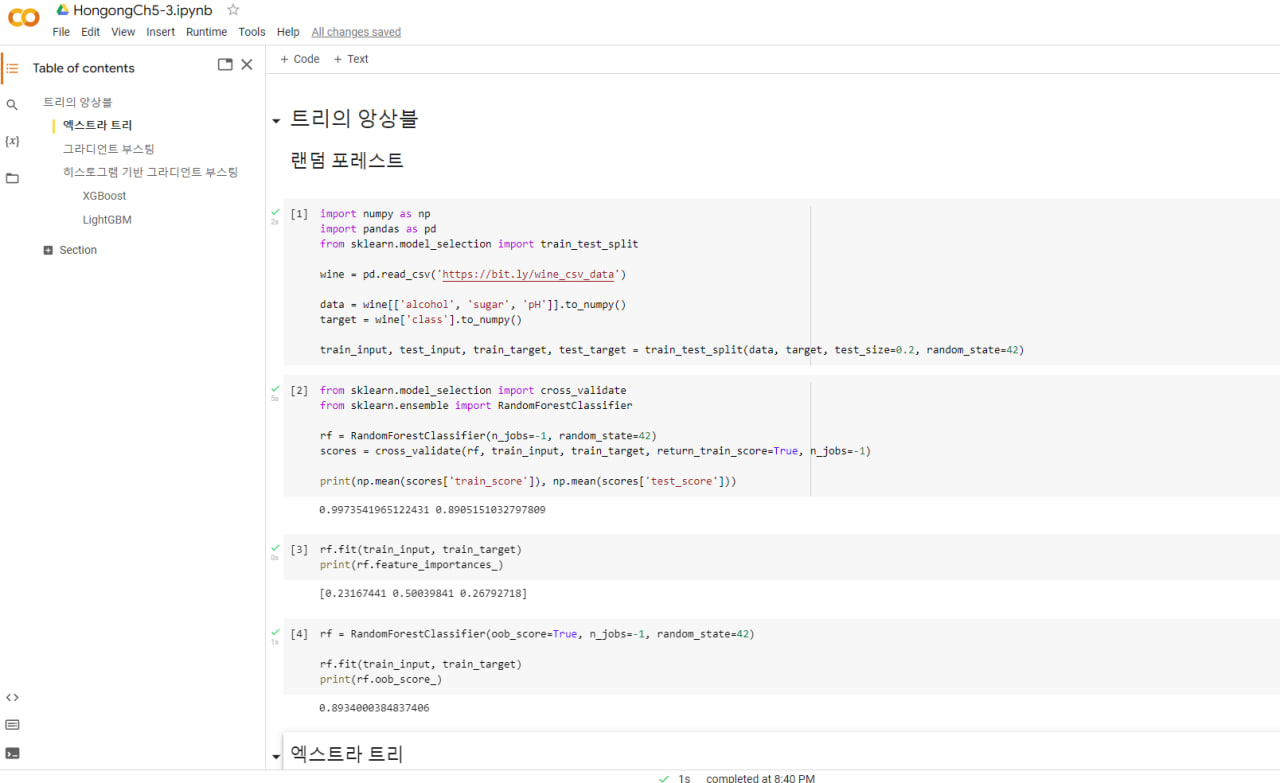
return train score 매개 변수를 True로 지정하면 훈련 세트의 점수도 반환 (기본값 False)
GridSearchCV, RandomizedSearchCV
교차 검증으로 하이퍼파라미터 탐색을 수행. 최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델을 훈련.
책에 나오는 3-폴드 교차 검증 (훈련 세트를 세부분으로 나눠서 교차 검증 수행) 그림
선택미션: Ch.05-3. 앙상블 모델 손코딩 코랩 화면 인증하기
앙상블 학습은 정형 데이터에서 가장 뛰어난 성능을 내는 머신러닝 알고리즘. 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
✅ 사이킷럿
- 랜덤 포레스트: 부트스트랩 샘플 사용하고 랜덤하게 일부 특성을 선택하여 트리를 만듬. 대표 앙상블 학습 알고리즘
- 엑스트라 트리: 결정 트리의 노드를 랜덤하게 분할해 과대적합을 감소시킴. 부트스트랩 샘플 사용하지 않음.
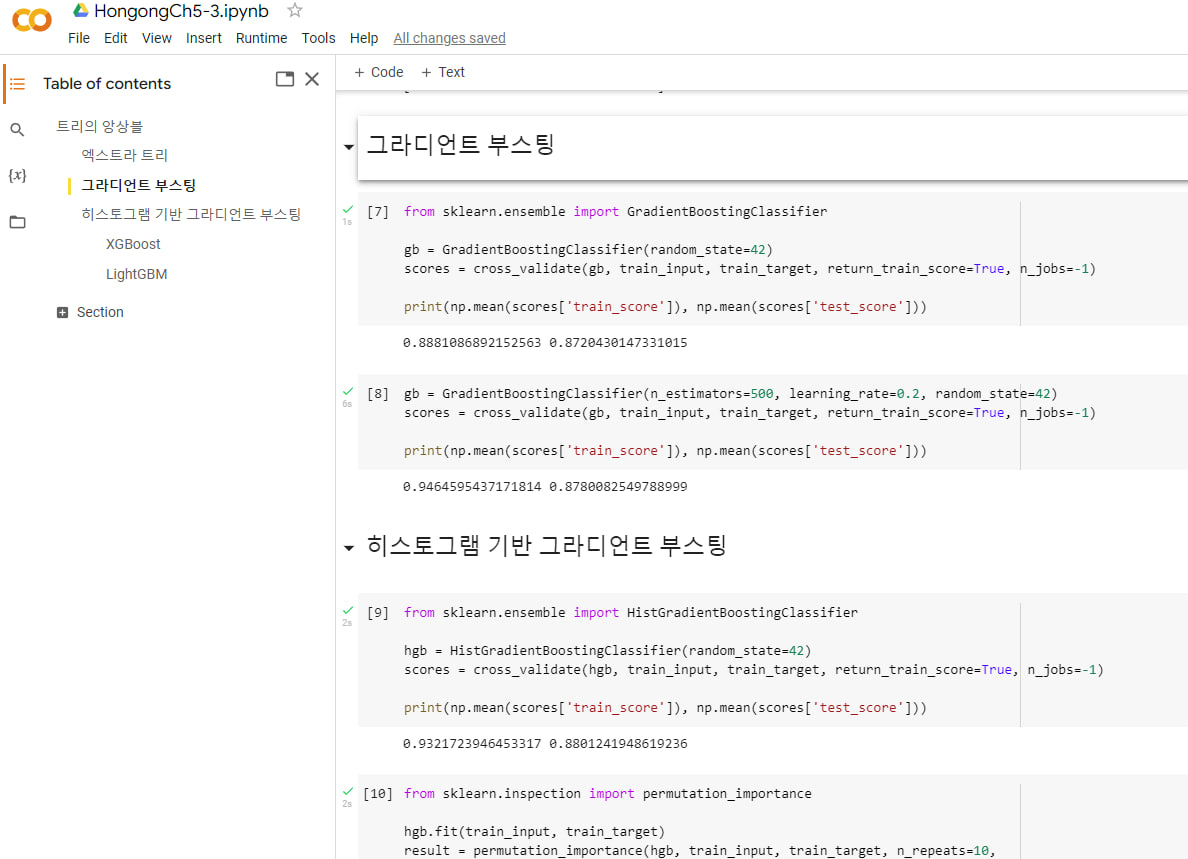
- 그라디언트 부스팅: 이진 트리의 손실을 보완하는 식으로 얕은 결정 트리를 연속하여 추가. 훈련 속도가 조금 느리지만 더 좋은 성능을 기대할 수 있음.
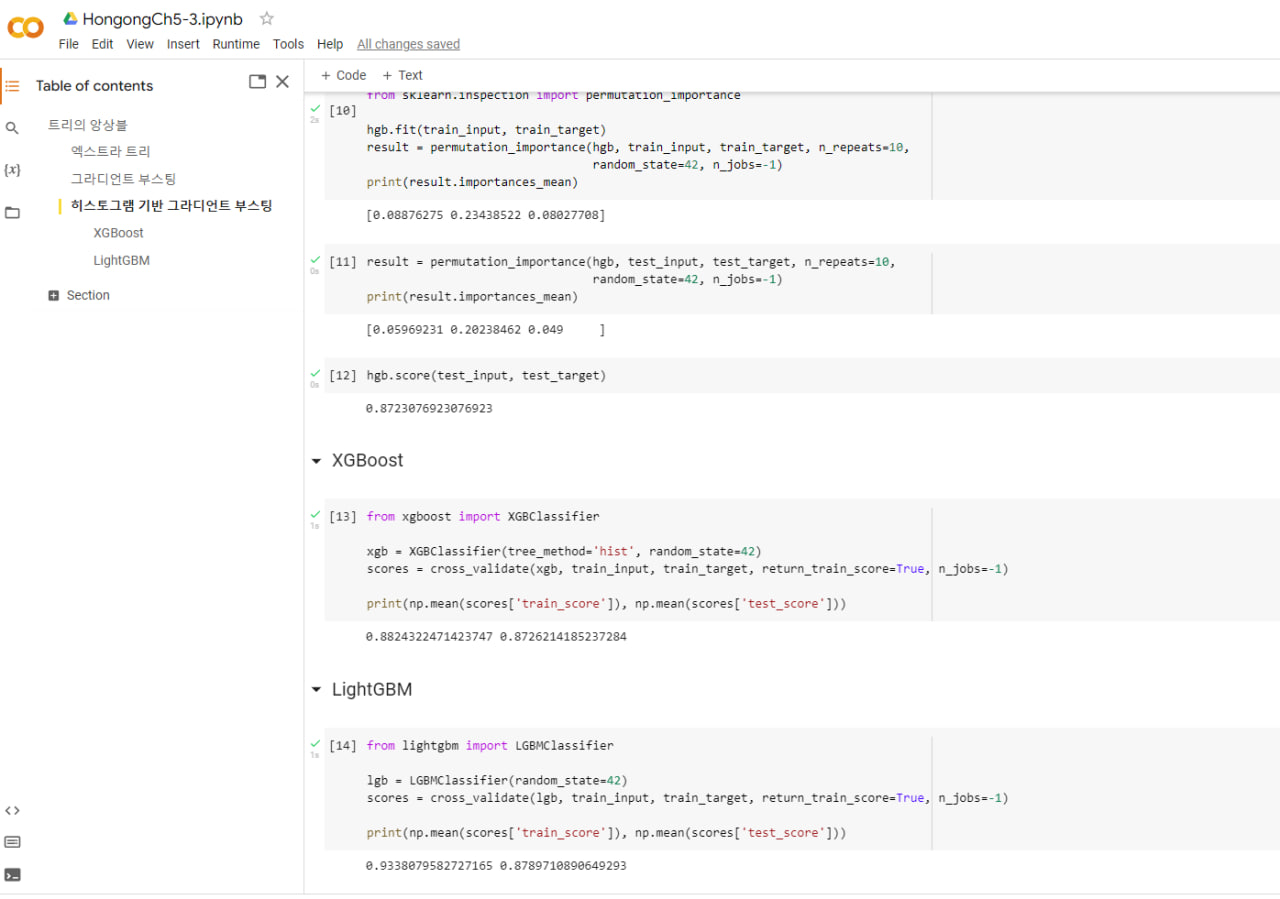
- 히스토그램 기반 그라디언트 부스팅: 그라디언트 부스팅의 속도를 개선. 훈련 데이터를 256개 정수 구간으로 나누어 빠르고 높은 성능을 냄.
✅ 그외 라이브러리 - XGBoost
- LightGBM
핵심 패키지와 함수
- RandomForestClassifier
- ExtraTreesClassifier
- GradientBoostingClassifier
- HistGradientBoostingClassifier
🙋♂️Q&A: 박해선 저자님의 github
💻유튜브 강의: 👉전체 강의 목록
