✅ 혼자 공부하는 머신러닝+딥러닝
진도: Chapter 06
기본 미션: k-평균 알고리즘 작동 방식 설명하기
선택 미션: Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기
k-평균 알고리즘은 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만든다. 그다음 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해서 최적의 클러스터를 구성하는 알고리즘
클러스터 중심은 k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값. 센트로이드라 부름. 가장 가까운 클러스트 중심을 샘플의 또 다른 특성으로 사용하거나 새로운 샘플에 대한 예측으로 활용 가능
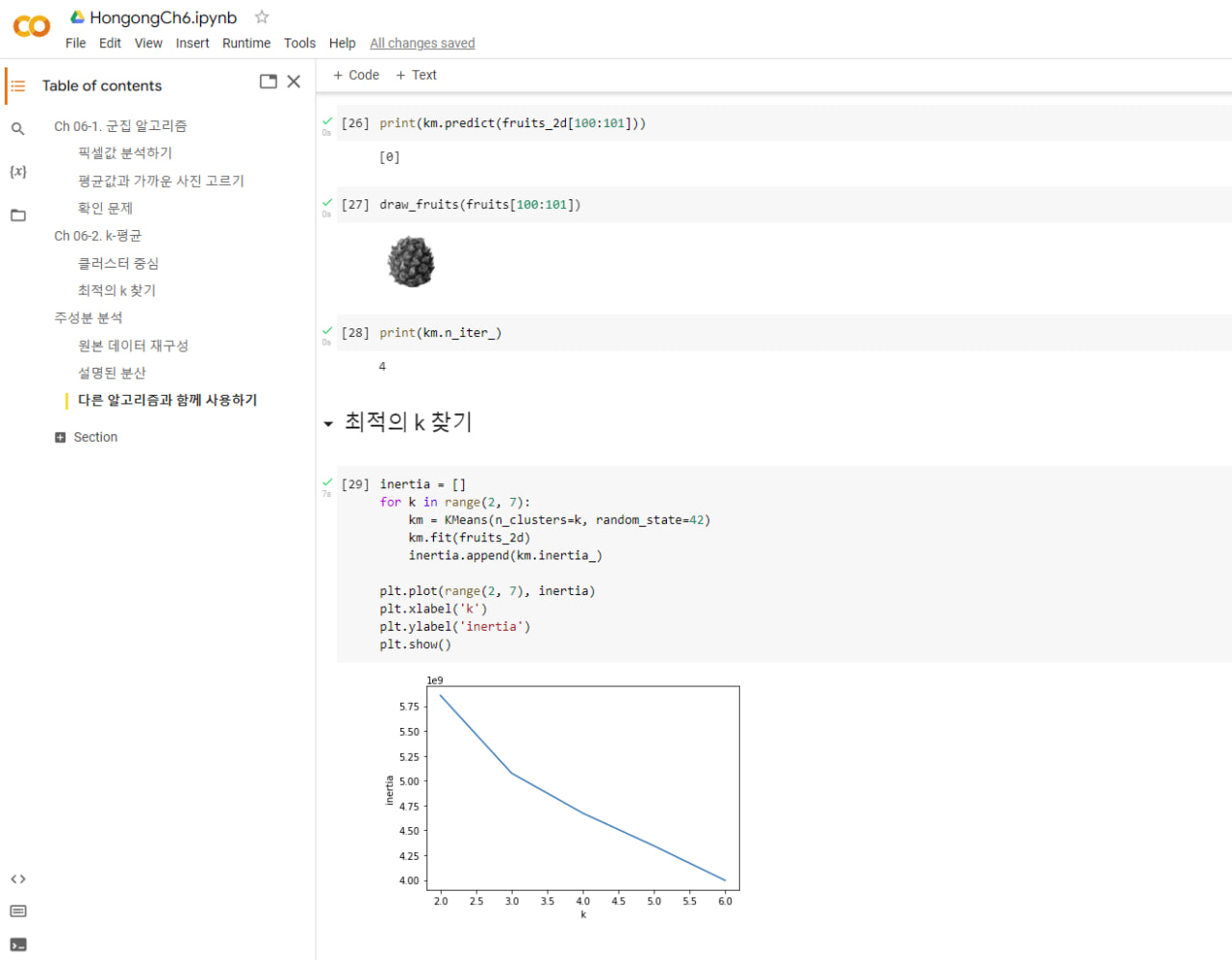
엘보우 방법을 사용해 이너셔의 감소 정도가 꺾이는 최적의 클러스터 개수를 찾는다. 이너셔는 클러스터 중심과 샘플 사이 거리의 제곱 합. 클러스트 개수에 따라 이너셔 감소가 꺾이는 지점이 적절한 클러스터 개수 k가 될 수 있다. 이 그래프의 모양을 따서 엘보우 방법이라 부름.
기본 미션: k-평균 알고리즘 작동 방식 설명하기
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복.
이건 보너스 - 그래프가 멋져서 첨가합니다
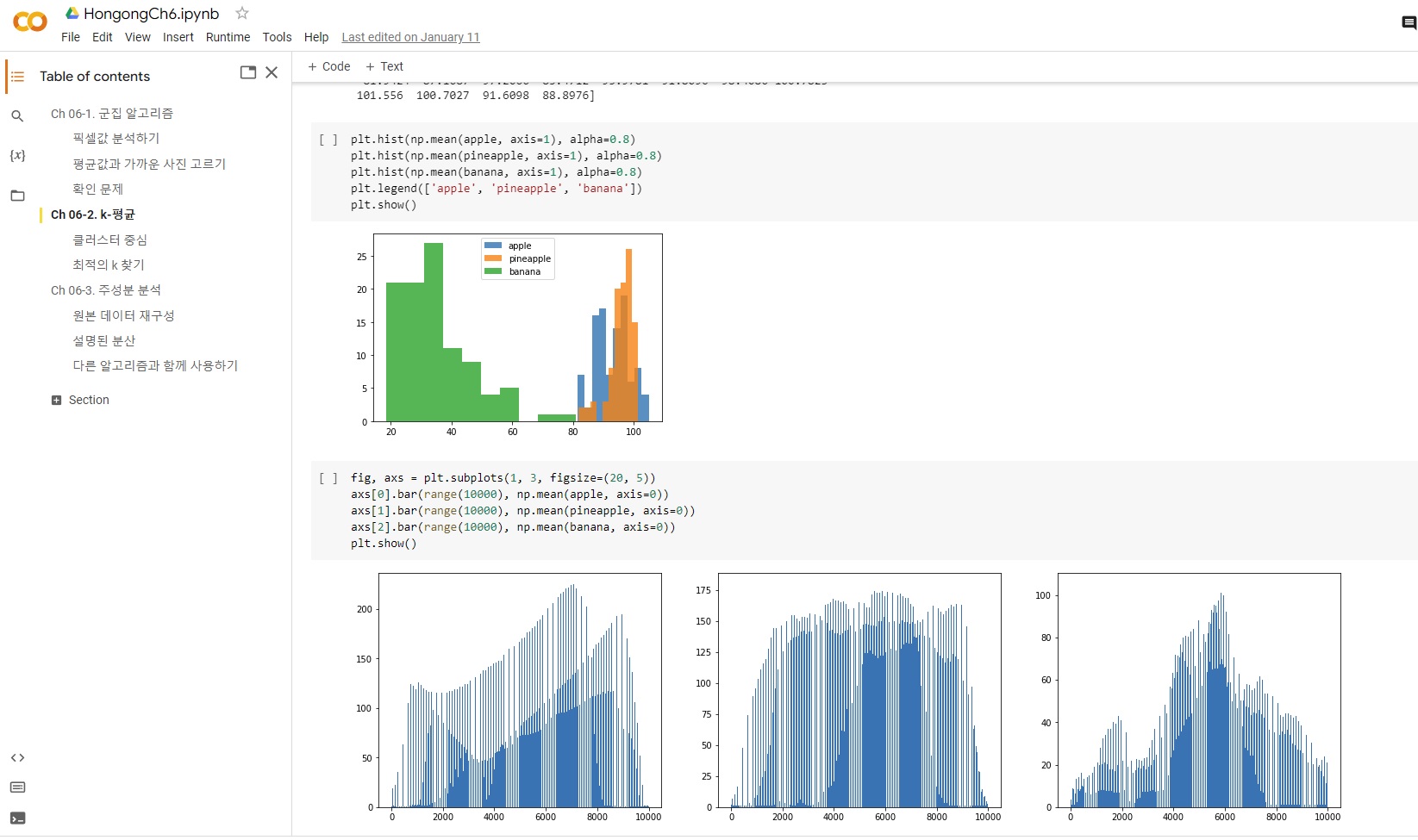
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()
이런 걸 다 만들 줄 알다니
선택 미션: Ch.06-3. 확인 문제 풀고, 풀이 과정 정리하기
(1000, 100) 크기 데이터셋에서 10개의 주성분을 찾아 변환하면 샘플의 개수는 그대로이고 특성 개수만 100에서 10으로 바뀌어 (1000,10)이 된다. 특성의 개수만큼 주성분을 찾을 수 있다.
주성분 분석은 가장 분산이 큰 방향부터 순서대로 찾으므로 첫 번째 주성분의 설명된 분산이 가장 크다.