우아한테크코스 레벨2 기간에 학습한 Spring JDBC 강의 내용을 정리한다.
우리는 SpringMVC를 통해서 요청과 응답을 할 수 있고, Spring JDBC를 통해서 DB와 데이터를 주고받으며, Spring Core를 통해서 객체를 관리하고 스프링 기본 로직을 사용할 수 있다.
이렇게 Spring은 각각이 모듈로 분리되어 있으며, 이러한 각 모듈은 서로 의존성을 가질 수 있다.
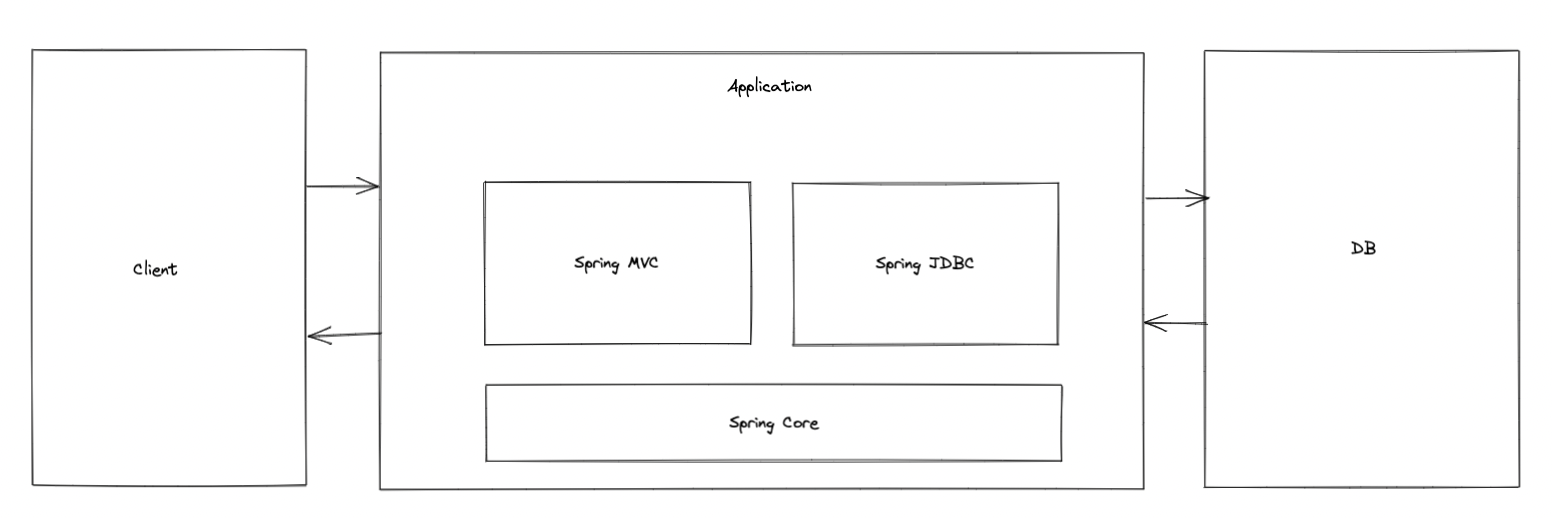
Spring MVC
-> 요청에 따라 수행할 로직을 분기한다.
-> 요청 시 포함된 정보를 매핑한다.
-> 응답의 형태에 따라서 다양한 형식으로 데이터를 보내준다.
이러한 Spring MVC의 동작원리에 대한 그림은 아래와 같다. (구체적인 내용은 다른 포스팅에서 다루도록 하겠다.)
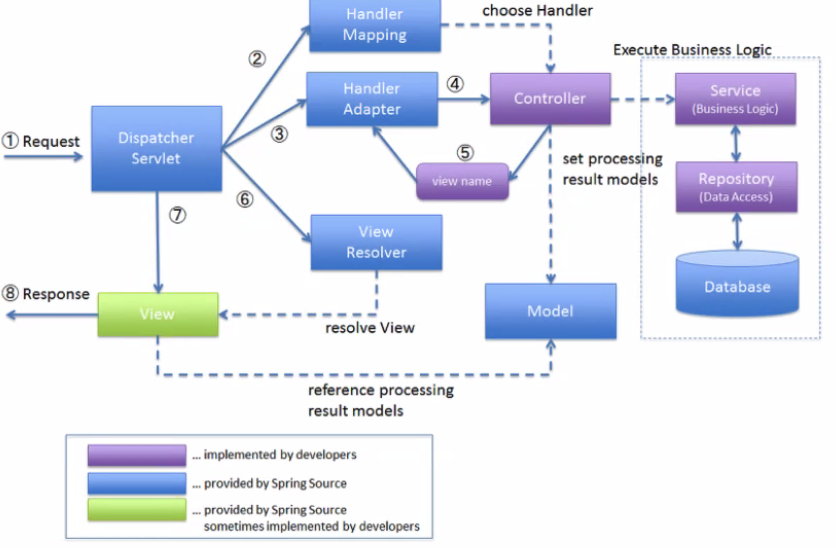
출처: 부스트코스(https://www.edwith.org/boostcourse-web/lecture/16762/)
질문 타임
Q. 실제로도 URL를 같은 메소드로 매핑해놓고 Content-Type만 구분해서 분리하는 경우도 많은가요?
A. 어떤 서비스를 운영하느냐에 따라 달라질 수 있다. 일반적인 웹 서비스를 구현할 때는 드문 경우이지만 실제로 이렇게 사용하는 곳이 있을 수도 있다.
A. 실제로 많이 사용되는 것은 아니지만 이론적으로 Content negotiation이라는 키워드로 찾아보면 추가적인 학습을 해볼 수 있다.
Spring JDBC
JDBC란?
JDBC는 데이터베이스에 접속할 수 있도록 도와주는 자바 API라고 할 수 있다.
JDBC는 인터페이스로 그에 대한 구현체인 Driver에 대해서, 즉 어떤 DBMS이냐에 따라서 Application 코드에 대한 변경은 필요가 없게 된다. (하지만 DBMS에 따라 서로 다른 방언(dialect)에 대한 차이는 극복하지 못한다. 왜냐하면 결국 Application 코드에서 쿼리문을 직접 문자열로 작성해야하기 때문이다.) 하지만 JDBC를 사용함에도 이에 필요한 코드가 많고 중복도 많이 발생한다.
(커넥션을 맺고, 자원을 반납하고 등..)
이러한 반복적인 작업에 편리함을 제공하기 위해 Spring에서 제공하는 기능이 바로 JdbcTemplate이다.
Spring JDBC란?
Spring JDBC는 JDBC의 저수준 처리를 스프링 프레임워크에 위임함으로써, Connection 연결, Statement 준비, 실행 및 종료, 그리고 Result 처리 등을 개발자가 직접하지 않게 편리함을 제공하는 것이다.
즉, Spring JDBC를 사용하면 내가 해야 할 일은 연결 설정, 쿼리 설정, 파라미터 넣기 등만 해주면 되며 커넥션을 열고, 자원을 반납하는 작업 그리고 transaction을 핸들링하는 모든 작업들을 Spring이 해준다.
스프링 공식 사이트를 참고하여 Spring JDBC가 하는 일을 알아보자.
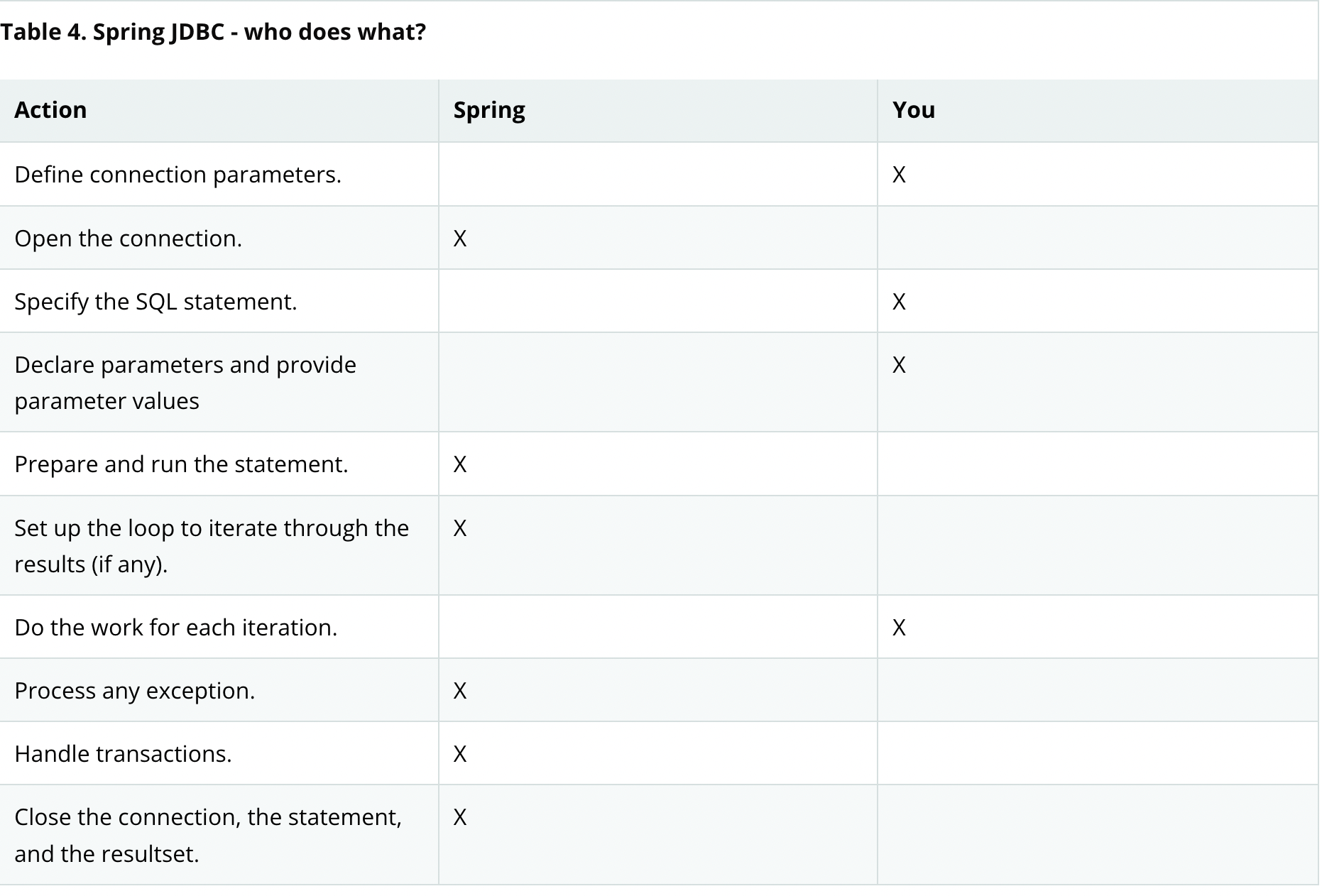
위 그림을 참고하여 Spring JDBC가 하는 일을 나열해보면 다음과 같다.
- Connection 열기와 닫기
- Statement 준비와 닫기
- Statement 실행
- ResultSet Loop 처리
따라서 Spring JDBC를 이용하면 개발자는 datasource를 설정하고 쿼리문을 작성하며 결과를 처리하는 것에만 신경을 써주면 된다.
Spring Framework에서 제공하는 Spring JDBC 접근 방법으로는 JDBCTemaplet 이외에도 다음과 같은 것을 제공한다.
- JdbcTemplate
- 전형적인 Spring JDBC 접근 방법이다.
- 쿼리를 직접 작성하는 방법을 제공하므로 많은 작업과 시간을 절약할 수 있다.
- NamedParameterJdbcTemplate
- JdbcTemplate에서는 데이터를 넣을 부분에
?를 이용하여 처리를 하므로 인자 위치에 대한 순서가 강제되어 가독성을 떨어트리는데 이 문제를 해결하기 위해?대신 변수명을 이용하여 처리하는 Spring JDBC 접근 방법이다.
- JdbcTemplate에서는 데이터를 넣을 부분에
- SimpleJdbcTemplate
- SimpleJdbcInsert
- 간단하게 데이터를 저장하기 위해 만들어진 구현체이다.
- SimpleJdbcTemplate은 datasource와 함께 테이블명과 키에 대한 내용을 추가하여 생성하여 준다.
JdbcTemplate은 뭐지?
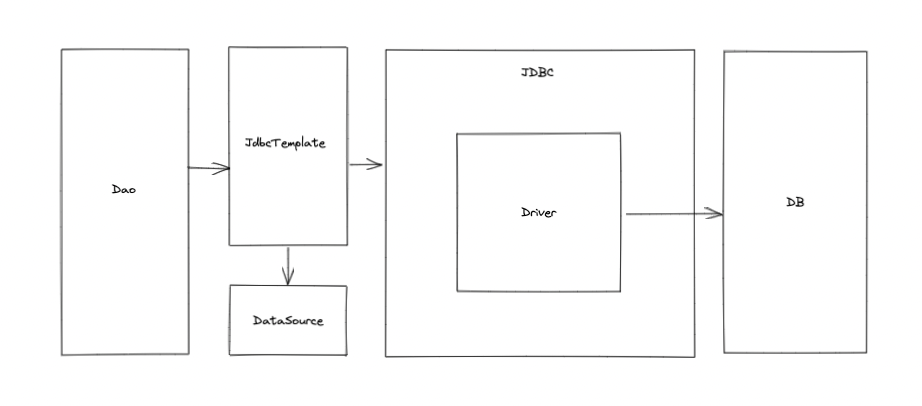
위 그림을 통해서도 알 수 있다시피 JdbcTemplate은 Spring JDBC 접근 방법 중 하나로, 내부적으로는 JDBC API를 사용한다.
스프링 공식 사이트를 참고하여 JdbcTemplate이 무엇인지 조금 더 자세히 알아보자.

스프링 공식 사이트 의 내용을 간략히 정리해보면, JdbcTemplate은 JDBC 코어 패키지의 중앙 클래스로, 리소스 생성 및 해제를 처리하는 등 JDBC 워크 플로우의 기본 작업을 수행한다고 한다.
또한 Sql 쿼리를 실행하고, statement와 프로시저 콜을 업데이트하고, ResultSet 인스턴스에 대해 반복 작업을 수행하고 반환된 매개 변수 값을 추출하며, JDBC 예외를 포착하여 패키지에 정의된 일반적이고 보다 유용한 예외 계층으로 변환한다고 한다.
JdbcTemplate과 NamedParameterJdbcTemplate, SimpleJdbcInsert 의 사용 예시 코드를 보며 정리하면 다음과 같다.
JdbcTemplate 예시 코드
@Repository
public class JdbcLineDao implements LineDao {
private static final RowMapper<Line> LINE_ROW_MAPPER = (resultSet, rowNum) -> new Line(
resultSet.getLong("id"),
resultSet.getString("name"),
resultSet.getString("color")
);
private final JdbcTemplate jdbcTemplate;
public JdbcLineDao(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public Line save(Line line) {
String sql = "INSERT INTO line (name, color) VALUES(?, ?)";
final KeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(connection -> {
final PreparedStatement statement = connection.prepareStatement(sql, new String[]{"id"});
statement.setString(1, line.getName());
statement.setString(2, line.getColor());
return statement;
}, keyHolder);
final long id = keyHolder.getKey().longValue();
return new Line(id, line.getName(), line.getColor());
}
@Override
public Optional<Line> findById(Long id) {
String sql = "SELECT * FROM line WHERE id = ?";
try {
final Line line = jdbcTemplate.queryForObject(sql, LINE_ROW_MAPPER, id);
return Optional.ofNullable(line);
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
...
}코드를 보면 알 수 있다시피, 커넥션 연결 및 statement 준비 및 닫기, 실행, ResultSet에 대한 처리에 대한 코드가 없음을 확인할 수 있다.
우리는 단지 쿼리문을 작성하고, 파라미터를 할당해주고 jdbcTemplate을 이용해서 쿼리를 실행하기만 하면 된다.
객체에 대한 매핑도 RowMapper를 이용해서 ResultSet을 사용할 때 보다 편리하게 해줄 수 있다.
NamedParameterJdbcTemplate 예시 코드
@Repository
public class JdbcLineDao implements LineDao {
private static final RowMapper<Line> LINE_ROW_MAPPER = (resultSet, rowNum) -> new Line(
resultSet.getLong("id"),
resultSet.getString("name"),
resultSet.getString("color"),
resultSet.getInt("extraFare")
);
private static final String LINE_TABLE_NAME = "line";
private static final String GENERATE_KEY_COLUMN = "id";
private final NamedParameterJdbcTemplate jdbcTemplate;
private final SimpleJdbcInsert simpleJdbcInsert;
public JdbcLineDao(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = new NamedParameterJdbcTemplate(jdbcTemplate);
this.simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName(LINE_TABLE_NAME)
.usingGeneratedKeyColumns(GENERATE_KEY_COLUMN);
}
@Override
public Optional<Line> findById(Long id) {
String sql = "SELECT id, name, color, extraFare "
+ "FROM line "
+ "WHERE id = :id";
try {
final Line line = jdbcTemplate.queryForObject(sql, Map.of("id", id), LINE_ROW_MAPPER);
return Optional.ofNullable(line);
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
...
}jdbcTemplate을 사용할 때와는 달리 데이터를 넣을 부분인 ? 에 대신해서 변수명(:id)을 사용해 명시해준다.
이를 통해서 가독성을 높일 뿐 아니라 인자 순서에 대한 제약을 극복할 수 있다.
SimpleJdbc 예시 코드
@Repository
public class JdbcLineDao implements LineDao {
private static final RowMapper<Line> LINE_ROW_MAPPER = (resultSet, rowNum) -> new Line(
resultSet.getLong("id"),
resultSet.getString("name"),
resultSet.getString("color"),
resultSet.getInt("extraFare")
);
private static final String LINE_TABLE_NAME = "line";
private static final String GENERATE_KEY_COLUMN = "id";
private final NamedParameterJdbcTemplate jdbcTemplate;
private final SimpleJdbcInsert simpleJdbcInsert;
public JdbcLineDao(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = new NamedParameterJdbcTemplate(jdbcTemplate);
this.simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName(LINE_TABLE_NAME)
.usingGeneratedKeyColumns(GENERATE_KEY_COLUMN);
}
@Override
public Line save(Line line) {
MapSqlParameterSource parameterSource = new MapSqlParameterSource();
parameterSource.addValue("name", line.getName());
parameterSource.addValue("color", line.getColor());
parameterSource.addValue("extraFare", line.getExtraFare());
final Long id = simpleJdbcInsert.executeAndReturnKey(parameterSource).longValue();
return new Line(id, line.getName(), line.getColor());
}앞서 jdbcTemplate을 사용한 예시 코드에서 KeyHolder를 이용하여 update하고 그에 대한 id값을 가져오는 것과 달리, update할 row의 값을 MapSqlParameterSource에 추가해주고 쿼리를 실행해주면 끝이난다. 보다 간단하게 작업이 끝나며, 앞서 언급한 것과 같이 SimpleJdbcInsert를 생성할 때 어떤 테이블의 어떤 컬럼을 GeneratedKey로 사용할지를 명시해준다.
DataSource는 뭐지?
DataSource는 DB와 관련된 커넥션 정보를 담고 있다. 즉 application과 database 간의 커넥션을 맺어주고 커넥션 풀을 생성하여 통신을 가능하게 해주는 역할이라고 볼 수 있다.
DataSource 인터페이스를 보면 datasource는 데이터 연결을 위한 Factory라고 하며, Connection 객체에 대한 생성을 담당하는 역할을 하는 것을 알 수 있다.
즉, DataSource는 DB와의 연결을 위한 Factory로 Connection을 맺어주는 역할을 하며 Connection 객체를 생성한다.
그리고 우리는 AutoConfiguration을 통해서 DataSourcex와 JdbcTemplate을 별도로 등록하지 않고도 사용가능하다. 만약 추가 설정을 하고 싶다면 application.yml 이나 application.properties에서 가능하다.
H2 DB란?
별도의 설치가 필요없는 내장형 DB라서 스프링 샘플 프로젝트나 테스트에서 활용도가 높다.
또한 RDB기반이며, 빠르고 가벼운 데이터베이스이다.
In Memory DB(인 메모리 DB)여서 디스크에 저장할 때보다 빠르지만, 기본적으로 영속성(persistence)을 보장하지 않는다.
H2 DB는 Embedded Mode 와 Server mode를 지원한다. Embedded mode는 Application 서버 실행 종료시 데이터가 모두 휘발되며 Server mode는 Application 서버 종료시에도 지속적으로 해당 데이터를 사용할 수 있다.
Next Step of Spring JDBC
Spring JDBC를 사용하지만, 쿼리를 매번 직접 정의해주는 작업은 매우 번거롭다. 또한 객체와 테이블 설계에는 차이가 존재하기 때문에 불편하다. 따라서 이를 보완해주기 위해 스프링에서는 "Spring Data" 괄년 모듈들을 제공한다.
매우 강력한 점은 "메소드명"만을 통해서도 구현을 완료해줄 수 있다. -> 누가? Spirng Data 모듈이 (구체적으로는 Spring Data JPA)
그리고 이러한 객체와 RDB의 패러다임 불일치를 해결해주어 직접 쿼리를 작성하지 않아도 되게 하고 객체지향적으로 애플리케이션 코드를 작성하게 해주는 것을 ORM 이라고 하며 자바 진영의 표준 ORM은 JPA이다.
