우아한 테크 코스 레벨1 데일리미팅 조에서 호호 크루가 진행하는 객체지향과 디자인 패턴 스터디에 참여하게 되었다. 앞으로 약 7주간 각 챕터 별로 스터디 준비를 위해 공부한 내용을 블로그에 글로 정리하려고 한다.
객체 지향과 절차 지향
절차 지향
-
소프트웨어 구현이란 결국
소프트웨어를 구성하는 데이터와 데이터를 조작하는 코드를 작성하는 일이다.
즉,데이터와데이터를 조작하는 코드로 구성되는데 우리는 이 데이터를 조작하는 코드를함수혹은프로시저와 같은 형태로 만든다. -
절차 지향이란
프로시저(procedure)로 프로그램을 구성하는 기법이다.
(새롭게 알게 된 사실이었다. 절차 지향이란 코드를 절차적으로(순서대로) 작성하는 프로그래밍 기법이라고 생각했었다. 학교에서 절차지향과 객체지향을 비교하며 설명하시는 교수님들 중에서도 이렇게 설명하시는 분들이 계셨던 것으로 기억한다. 하지만 이는 procedure 를 번역하는 과정에서절차라는 말을 사용하게 되었을 뿐 절차 지향이란프로시저 지향을 의미한다.) -
각각의 프로시저는 다른 프로시저를 사용할 수도 있으며 각각의 프로시저가 동일한 데이터를 처리할 수도 있다.
-
절차 지향 프로그래밍은 여러 개의 프로시저들이 데이터를 공유하는 방식으로 만들어지기 때문에, 자연스럽게
데이터를 중심으로 구현하게 된다.
하지만 이는 프로그램 규모가 커질수록 데이터의 종류 및 그 수가 늘어나기 때문에 다음과 같은 문제가 발생한다.
->데이터 타입이나 의미를 변경해야 할 때, 함께 수정해야 하는 프로시저가 증가한다.
->같은 데이터를 프로시저들이 서로 다른 의미로 사용하는 경우가 발생한다.
객체 지향
-
데이터 및 데이터와 관련된 프로시저를객체라고 부른다.
(객체 지향 기법을 적용한 프로그램은객체들의 네트워크로 구성된다.) -
객체는
자신만의 기능을 제공하며, 각 객체들은 서로 연결되어다른 객체가 제공하는 기능을 사용할 수 있다. 또한 객체는다른 객체에 기능을 제공하기 위해 프로시저를 사용하는데다른 객체에 속한 데이터에는 접근할 수 없다.
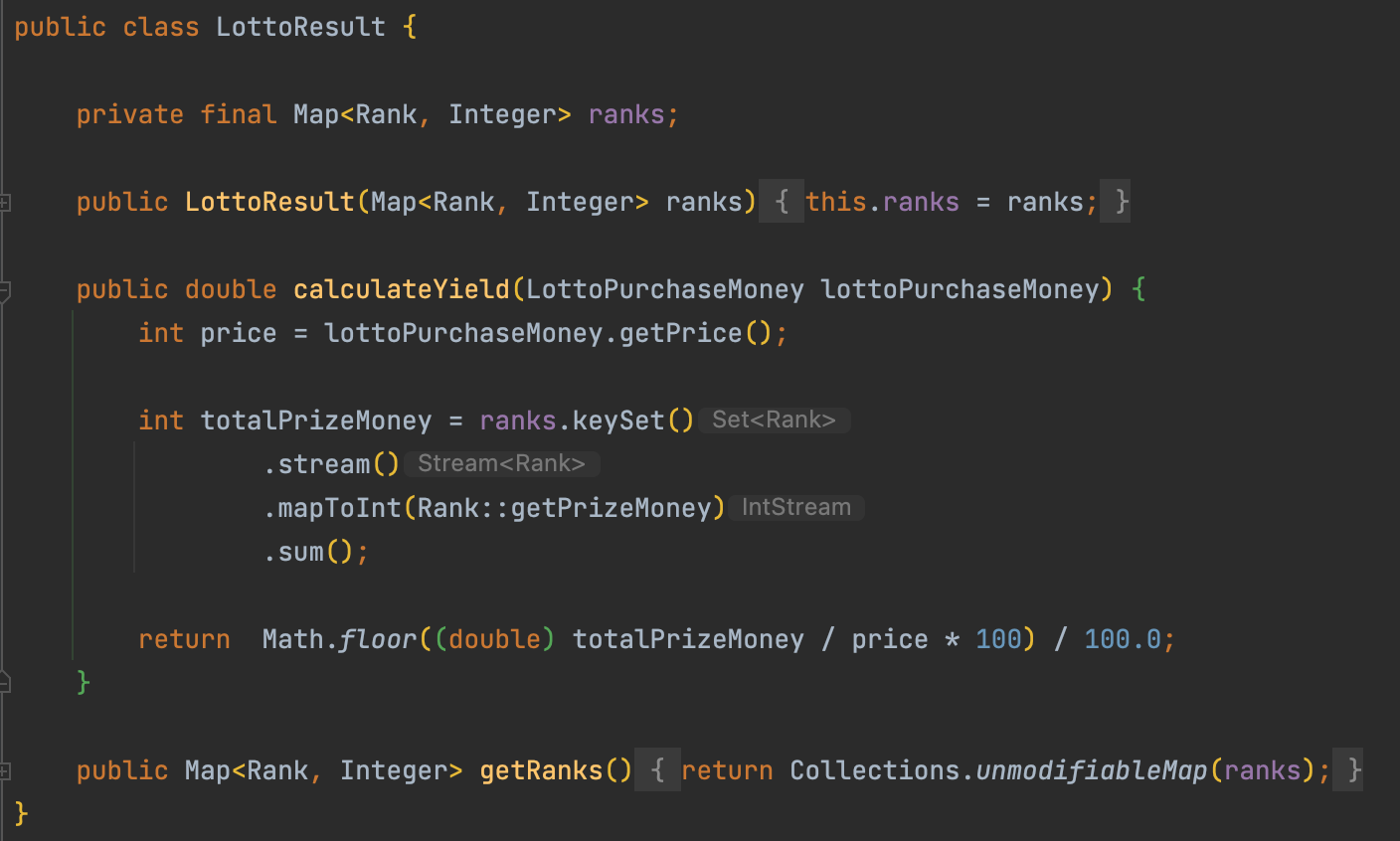
위 코드를 보면 매개변수로 받게 되는 다른 객체인
LottoPurchaseMoney가 제공하는 기능인getPrice()라는 기능을 사용하고 있으며LottoResult객체를 사용하는 외부에calculateYield()라는 기능을 제공하고 있다. 또한ranks라는 데이터를private선언을 통해서 다른 객체에서 접근하지 못하게 막고 있다. -
객체 지향적인 코드에서는 객체의 데이터가 변경되더라도 해당 객체로만 변화가 집중되고, 다른 객체에 영향을 주지 않기 때문에, 요구 사항의 변화가 발생했을 때 절차 지향 방식보다 쉽게 변경할 수 있다.
-
객체지향은 최초에는 비용이 많이 들어갈 수 있지만, 수정이 쉽고 유연함을 제공하여 변화된 요구사항을 빠르게 반영할 수 있다는 장점이 있다.
객체
객체의 핵심은 기능을 제공하는 것
-
객체를 정의할 때는
기능에 초점을 맞춘다. (데이터 X)
반대로 절차지향은 데이터를 중심으로 구현한다. -
예를 들어 로또 프로그램을 구현한다고 하면 로또 구매와 관련된 기능, 당첨 번호를 생성하는 기능(자동), 당첨 결과 및 통계를 내주는 기능과 같이 그 기능에 초점을 맞추지 그 내부에서 로또 번호를 어떤 데이터 타입으로 관리할지는 중요하지 않다.
인터페이스와 클래스
-
객체는 기능(operation)으로 정의된다. 객체가 제공하는 기능을 사용할려면 그 기능의 사용법을 알아야 한다. 이를
인터페이스라고 한다. 즉객체가 제공하는 모든 오퍼레이션 집합이 인터페이스이다.
(인터페이스: 객체를 사용하기 위한 일종의 명세나 규칙) -
기능(operation)의 사용법은
시그니처(Signature)로 구성되며 다음과 같다.- 기능 실벽 이름
- 파라미터 및 파라미터 타입
- 기능 실행 결과 값
시그니처를 자바의 Interface 에서 찾으면 다음과 같다.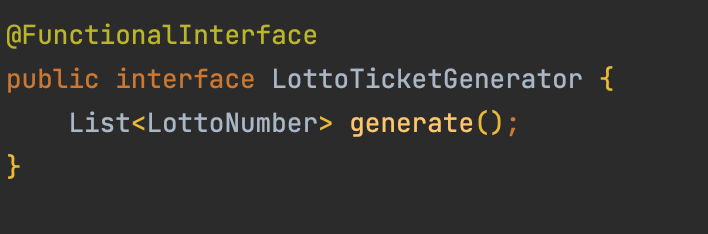
여기서기능 식별 이름은generate에 해당하며파라미터 및 파라미터 타입은 여기서는()로 없다. 마지막으로기능 실행 결과 값은List<LottoNumber>에 해당한다.
- 인터페이스는 객체가 제공하는 기능에 대한 명세서일 뿐 실제 객체가 기능을
어떻게구현하여 제공하는지에 대한 내용은 포함하지 않는다.
메시지
객체지향은 기능을 제공한느 여러 객체들이 모여 완성되므로 객체들간의 메시지 를 통해서 데이터를 조작해가며 어플리케이션을 구성한다.
메시지란
오퍼레이션의 실행을 요청하는 것이다.
코드를 통해서 확인해 보자!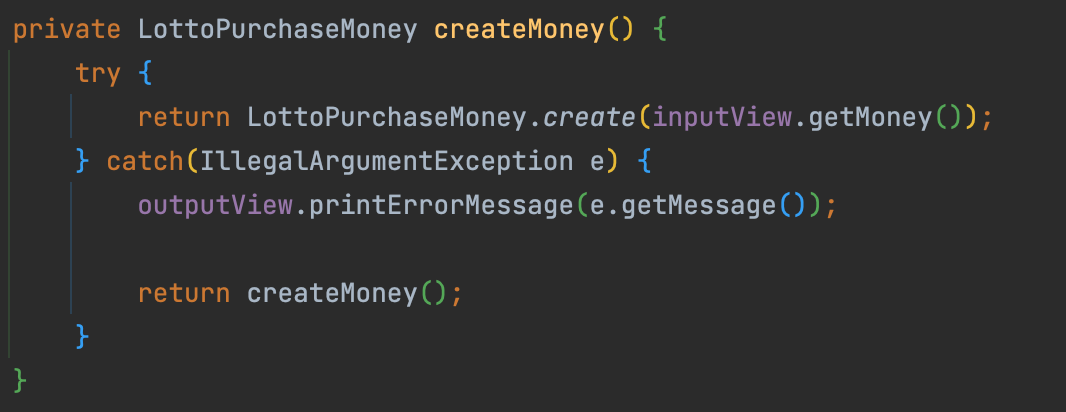
위의 코드에서 try{} 구문 안쪽만 살펴보자.
inputView.getMoney() 는 인스턴스 변수 inputView 가 참조하고 있는 객체에 getMoney() 라는 메시지를 보내서 기능(operation)의 실행을 요청하고 있는 것이다.
객체의 책임과 크기
객체가 제공하는 기능으로 정의된다는 것은 객체마다 자신의 책임(responsibility) 를 가진다는 것이다.
-> 앞서 보인 LottoResult 라는 객체는 calculateYield, 즉 통계를 계산하라는 책임을 가진다고 볼 수 있는 것이다.
-
한 객체가 갖는 책임을 정의한 것이 바로
타입/인터페이스이다.
(앞서 보인LottoTicketGenerator가 이를 구현하는Concrete Class의 책임을 정의한 것이라고 볼 수 있다.) -
객체마다 서로 다른 책임을 지는데, 이런 책임 할당이 바로 결정되는 것은 아니며 다음 예시와 같은 기능 목록을 정리한 이후 객체들에게 분배하며 객체를 구성하게 된다.

-
이 때, 객체의 구성은 사람에 따라 다르게 구성할 수 있다. 즉 더 나은 구성은 있을 수 있어도 정답이 존재하는 것은 아니다. 이 때, 더 나은 구조로 나아가기 위해서는
객체가 갖는 책임의 크기는 작게하는 것이 좋다. -
한 객체가 너무 많은 기능을 가지게 되면 기능(operation)들이 데이터를 공유하는 방식으로 구성된다는 것이고 이는 곧
데이터를 중심으로 개발하는절차 지향개발 방식과 동일하게 되기 때문에기능 변경의 어려움을 겪게 될 수 있다. -
이와 관련된 원칙이
SRP(Single Responsibility Prinsiple)이며객체는 단 한개의 책임만을 가져야한다.는 원칙이다. 이로 인해 변경해야 할 때 변경해야할 부분이 한 곳으로 집중 될 수 있고, 변경의 유연함을 얻을 수 있다.
(이와 관련해서는 향후 SOLID 원칙을 공부하며 다시 자세하게 정리해보겠다.)
의존
하나의 객체만으로 프로그램을 구성하는 것은 불가능 하다. 따라서 서로 다른 객체가 제공하는 기능을 사용하게 되는데 이를 의존한다 라고 표현한다.
의존(dependency) 을 실제 코드에서 보게 되면 한 객체에서 다른 객체를 생성(new) 혹은 다른 객체의 메소드를 호출 그리고 매개 변수를 통해 전달받는 경우를 포함한다.
그렇다면 다음과 같은 코드에서 LottoResult 의 경우 어떤 객체들에 의존하고 있을까??
public class LottoController {
private final OutputView outpuView;
...
private LottoTickets createLottoTickets(LottoPurchaseMoney lottoPurchaseMoney) {
LottoMachine lottoMachine = new LottoMachine();
LottoTickets lottoTickets = lottoMachine.purchase(lottoPurchaseMoney);
LottoTicketsDto lottoTicketsDto = new LottoTicketsDto(lottoTickets);
outputView.printTotalCount(lottoTickets.totalCount());
outputView.printLottoTicketsInfo(lottoTicketsDto);
return lottoTickets;
}
}우선 `createLottoTickets()` 에서 매개변수로 전달받는 `LottoPurchaseMoney` 에 의존하고 있다.
다음으로 `LottoMachine` 객체를 `new` 를 통해 생성하고 있으므로 해당 객체에도 의존하고 있다.
또한 outputView 참조변수가 참조하고 있는 객체의 메소드를 호출하고 있으므로 `OutputView` 객체에도 의존하고 있다.
이외에도 `LottoTickets`, `LottoTicketsDto` 등의 객체에도 의존하고 있다고 볼 수 있다.이렇게 다른 객체에 의존한다는 것은 의존하는 타입에 변경이 발생할 때 의존하고 있는 객체도 변경될 가능성이 높다는 것을 의미한다. 위의 코드에서는 outputView.printTotalCount() 의 타입, 즉 매개변수에 변화가 생기면 해당 코드 또한 변경이 필요하게 된다.
그리고 이러한 의존은 전파되는 특징이 있다. 따라서 의존이 순환하게 되는 경우에는 다른 방법이 없는지, 내가 제대로 설계한 것이 맞는지를 한 번 의심해보고 개선해볼 필요가 있다. 이와 관련해서 순환 의존이 발생하지 않도록 하는 원칙 중의 하나로 DIP(Dependency inversion principle) 이라고 하는 의존 역전 원칙이 존재한다.
캡슐화
캡슐화를 통해서 한 곳의 변화가 다른 곳에 미치는 영향을 최소화할 수 있다.
본인은 캡슐화를 다음과 같다고 정의하고 있다.
- 내부 구현 변경에 유연함을 주는 기법
- 객체가 내부적으로 기능을 어떻게 구현하는지 감추는 것
이는 데이터를 중심으로 프로그래밍 하지 말아라! 라는 말과도 연계되는 개념이라고 생각한다. 데이터를 꺼내서(get) 이를 가지고 코드를 구현하는 것이 아니라 해당 데이터를 관리하는 객체에 메시지를 보내서 결과를 얻어와라.
책에서 이야기해주는 예시를 활용해보겠다.
만약 어떤 회원의 서비스 만료 날짜 여부에 따라 서비스를 달리하는 프로그램이 있다고 생각해보자. 그리고 다음 두 코드를 보자.
if (member.getExpiryDate() != null && member.getExpiryDate().getDate() < System.currentTimeMillis()) {
// 만료 처리
}if (member.isExpired()) {
//만료 처리
}위 두 코드의 차이점은 무엇일까?
우선 첫번째 코드는 member 참조 변수가 참조하는 객체의 데이터를 꺼내와서 if구문이 있는 곳에서 로직을 처리하고 있다.
반면 두번째 코드에서는 member 참조 변수가 참조하는 객체에게 isExpired() 라고 메시지를 보내서 처리를 수행하고 있다.
지금 현재에는 어떤 코드가 더 좋고 나쁜지 감이 안올 수도 있다. 하지만 만약 만료에 대한 요구사항이 변경되었다고 해보자. Member 에서 만료 처리를 할 때 여성에게 30일 정도의 기간을 더 주도록 수정했다고 가정해보자. 그렇다고 하면 첫번째 코드에서는 if문을 가진 곳에서 모든 변경을 감당해야한다. 하지만 만약 두번째 코드와 같이 구현하였다고 하면 Member 의 isExpired() 메소드 내부만을 요구사항을 따르도록 수정해주면된다. 즉 isExpired() 메소드를 활용하는 곳에서는 변경할 사항이 없게 되고 Member 쪽으로 수정사항이 집중되게 되는 것이다. 그리고 이것이 자연스럽다!
- 캡슐화는 내부 구현이 변경되더라도 기능을 사용하는 곳(의존하는 곳)의 영향을 최소화할 수 있다. 즉 내부 구현 변경에 유연함을 얻게 되는 것이다.
캡슐화를 위한 두 개의 규칙
- Tell, Don't Ask
(데이터에 대해 묻지 않고, 기능 실행) - 데미테르의 법칙
(Tell, Don't Ask를 위한 규칙)
Tell, Don't Ask
이는 말 그대로 데이터를 물어보지 않고, 긴으을 실행해 달라고 하는 것이다. 즉 Getter를 사용해서 데이터를 직접 가져와 처리하는 것이 아니라 기능을 실행해달라고 요청(명령)을 내리는 것이다. 데이터를 가져오게 되면 기능 보다는 데이터를 중심으로 코드를 작성하게 된다.
데미테르의 법칙
이는 앞서 언급한 Tell, Don't Ask 규칙을 잘 따르기 위한 규칙이라고 불 수 있으며 다음과 같은 규칙으로 정의된다.
- 메소드에서 생성한 객체의 메소드만 호출
- 파라미터로 받은 객체의 메소드만 호출
- 필드로 참조하는 객체의 메소드만 호출
public void processSome(Member member) {
if (member.getDate().getTime() < ...) {
...
}
}위와 같은 코드는 데미테르의 법칙을 어긴 것이다.
매개변수로 받은 member이외에 getDate()가 반환하는 객체의 메소드를 호출하고 있기 때문이다.
처음으로 독서 스터디에 참여해보는 것이라 내가 하고 있는게 잘 하고 있는 것인지 의문이 들기는 한다. 최대한 책의 예시 코드 보다는 내가 지금 진행하고 있는 미션들에서 예시를 찾아가며 연관지어 생각하고 공부하려고 노력했다.
더 나은 스터디를 위해서 다른 스터디 팀원 분들의 많은 피드백을 기대합니다..!!
