단일 책임 원칙
"객체를 객체로써 존재하게 하는 이유는 책임(responsibility)인데, 단일 책임 원칙(Single responsibility principle, SRP)는 이 책임과 관련된 원칙이다.
단일 책임 원칙은 다음과 같은 단 한 문장으로 정의할 수 있다.
클래스는 단 한 개의 책임을 가져야 한다.
근데 여기서 의문이 생긴다. 책임은 뭘까? "우리의 코드에서 책임이 무엇이다"라고 한 마디로 명확하게 정의할 수 있을까? 이 질문을 받고 명확하게 말할 수 있는 사람이 많지 않을 것이라고 생각한다.
단일 책임 원칙(SRP)에서 "클래스는 단 한 개의 책임을 가져야 한다." 라고 말하는 이유를 우선 알아보자.
"클래스가 만약 여러 책임을 갖게 되면 그 클래스는 각 책임마다 변경되는 이유가 발생하기 때문에 하나의 클래스에는 하나의 책임만을 가져야한다." 라고 이야기하는 것이 바로 SRP이다.
이러한 관점에서 책임(의 단위)이란 변화되는 부분(이유)과 관련이 있다. 각각의 책임은 서로 다른 이유로 변경되고, 서로 다른 비율로 변경되는 특징이 있으므로 결국 책임이란 변경과 관련된 것이라고 생각할 수 있다.
SRP를 위반할 때 발생할 수 있는 문제
콘솔 입력창으로부터 사용자가 입력한 데이터를 받고, 이를 정수타입으로 변경하여 콘솔 창에 출력해주는 클래스가 있다고 가정하자.
public class IntegerPrinter {
private static final Scanner scanner = new Scanner(System.in);
public int printInteger() {
String data = readString();
Integer number = Integer.parseInt(data);
System.out.println("number: " + number);
}
private String readString() {
return scanner.nextLine();
}
}
위 클래스를 잘 사용하고 있다가 도중에 사용자로부터 일일이 입력받는 것이 번거롭다고 생각되었고, csv등 파일로부터 입력을 받기로 변경되었다고 하자. 그러면 readString() 메소드가 변경되게 될 것이며, 심지어 BufferedReader의 readLine() 을 사용하지 않고, FileReader의 read() 를 사용하기로 했다면 printInteger() 메소드 또한 변경되어야 한다.
그러면 이번에는 반대로 출력을 단순이 콘솔창이 아닌 GUI를 통해서 출력하겠다고 변경한다고 생각해보자. 그러면 역시 printInteger() 메소드는 변경되어야 한다.
이러한 코드 변경이 발생하는 이유는 위의 "IntegerPrinter" 라는 클래스는 데이터를 읽어오는 책임과 읽은 데이터를 보여주는 책임 두 가지 책임이 한 클래스안에 존재하고 있기 때문이다.
이는 결국 연쇄적인 코드 변경의 이유로 이어지게 되고, "IntegerPrinter"가 여러가지 이유로 변경될 수 있다는 것을 의미하게 된다.
개방 패쇄 원칙
개방 폐쇄 원칙(Open-closed principle)은 다음과 같다.
확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
처음 OCP를 접했을 때, '확장에는 열려 있으면서 변경에는 닫혀 있다고? 이게 가능한가?' 라는 생각이 들었던 것이 기억난다.
OCP를 처음 접한 사람이라면 똑같이 모순되는 말 아닌가? 하는 생각이 들 수 있다고 생각한다. 그럼 천천히 OCP를 알아보자.
확장에는 열려 있고, 변경에는 닫혀 있다. 라는 말을 풀어 설명하면 기능을 변경하거나 확장할 수는 있으면서 그 기능을 사용하는 코드는 수정하지 않는다. 이다.
우리는 "추상화"를 통한 "다형성"을 가지고 이러한 OCP를 지킬 수 있게 된다.
다음의 클래스 다이어그램을 보자.
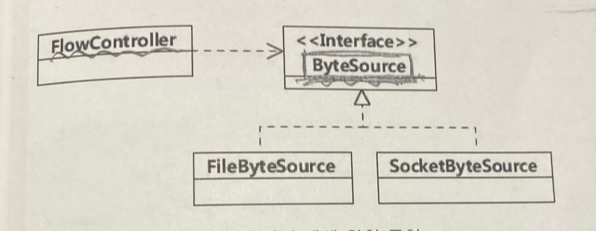
[출처: 개발자가 반드시 정복해야할 객체지향과 디자인패턴, 최범균, p. 111]
FlowController라고 하는 흐름을 제어하는 클래스에서 ByteSource라고 하는 추상화된 인터페이스에 의존하고 있다. (FlowController는 ByteSource를 구현(implements)하는 Concrete Class가 무엇인지에는 관심이 없다.)
이 때, 만약 메모리에서 byte를 읽어 오는 기능을 추가해야한다고 해보자. 그러면 우리는 ByteSource 인터페이스를 구현하는 구상 클래스를 추가하는 방법으로 해당 요구사항을 만족하도록 확장할 수 있다. 그런데 이 때 FlowController는 변경될 필요가 없게 된다.(기존 코드는 변경되지 않는다.)
즉, OCP원칙과 같이 확장에는 열려 있고, 변경에는 닫혀 있는 구조가 된 것이다.
이게 가능했던 이유는 확장되는 부분(변화되는 부분), 즉 Byte를 읽어오는 부분을 추상화 하였기 때문이다. 즉, FlowController 입장에서는 Byte를 읽어온다는 사실에만 집중하고 "어떻게" 읽어올지에 대해서는 무관하므로 OCP를 지킬 수 있는 것이다.
OCP가 깨질 때의 주요 증상
다운 캐스팅을 한다.
public enum Result {
BLACKJACK(1.5, (
(player, dealer) -> player.isBlackJack())
),
WIN(1.0, (
(player, dealer) -> ((player.isBlackJackScore() && dealer.isBlackJackScore()) || (dealer.isBust())
|| (!player.isBust() && !dealer.isBust() && player.getScore() > dealer.getScore())))
),
LOSS(-1.0, (
(player, dealer) -> ((!player.isBust() && !dealer.isBust())
&& (player.getScore() < dealer.getScore())))
);
private final Double rate;
private final BiPredicate<User, User> biPredicate;
Result(Double rate, BiPredicate<User, User> biPredicate) {
this.rate = rate;
this.biPredicate = biPredicate;
}
public static Map<String, Integer> calculateRevenue(List<User> players, User dealer) {
Map<String, Integer> revenue = new LinkedHashMap<>();
Map<String, Integer> playerRevenue = calculatePlayerRevenue(players, dealer);
revenue.put(dealer.getName(), calculateDealerRevenue(playerRevenue));
revenue.putAll(playerRevenue);
return revenue;
}
private static LinkedHashMap<String, Integer> calculatePlayerRevenue(List<User> players, User dealer) {
return players.stream()
.collect(toMap(
player -> player.getName(), player -> (Player) player.getRevenue(findResult(player, dealer).getRate()),
(e1, e2) -> e1,
LinkedHashMap::new)
);
}
private static Result findResult(User player, User dealer) {
return Arrays.stream(values())
.filter(value -> value.biPredicate.test(player, dealer))
.findAny()
.orElseThrow(() -> new IllegalArgumentException("결과를 찾을 수 없습니다."));
}
private static int calculateDealerRevenue(Map<String, Integer> playerRevenue) {
return - (playerRevenue.values()
.stream()
.mapToInt(value -> value).sum());
}
public Double getRate() {
return rate;
}
}위의 코드를 보면 calculatePlayerRevenue 메소드 부분에서 인자로 받은 List<User> players 에 대해서 다운캐스팅을 해주는 부분이 있다.
심지어는 "instanceof"를 통해서 해당 타입인지 검사도 해주고 있지 않다.
즉, 특정 타입인 경우를 검사하고 그에 대한 처리를 해주고 있는데 이는 좋은 코드일까? 만약 Player, Dealer 이외에 다른 클래스가 User를 상속하는 구조가 되고 그 클래스를 위한 별도 처리를 해주어야한다면 코드는 더욱 복잡해지고 OCP 또한 지키지 못하는 코드가 된다. 더 나아가서는 메소드 자체를 위와 같이 만들었는데 각각의 구현체를 안받고 로직을 수행하는 것이 이상하게 보일 수도 있다. (이미 파라미터 자체가 특정 타입에 종속적인데 User라고 한다고 무조건 좋을까? 와 같은 고민을 해볼 수도 있다.)
비슷한 if-else 구문이 존재한다.
if-else 구문이 존재한다는 것은 어떤 조건을 검사하고 그에 해당하는 로직을 수행한다는 것이다.
그럼 만약 새로운 요구사항에 따라 새로운 조건을 추가로 검사해야한다고 하면 그 코드는 변경되지 않고 확장될 수 있을까? 필연하게 변경이 요구되어야만이 확장이 가능하게 된다. 따라서 비슷한 if-else 구문이 존재한다면 개선할 여지가 없는지 고민해보아야 한다.
결론적으로 코드에 대한 요구사항이 변경되게 되면 변화와 관련된 구현을 추상화해서 OCP를 지키면서 수정할 수 있는지 확인하고 고민하는 습관을 갖자!
리스코프 치환 원칙
리스코프 치환 원칙은 개방 폐쇄 원칙(OCP)을 받쳐 주는 다형성에 관한 원칙을 제공한다.
리스코프 치환 원칙(Liskov substitution principle, LSP)는 다음과 같이 정의한다.
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
간단한 예시를 통해서 LSP 를 느껴보자!!
(예시는 "개발자가 반드시 정복해야할 객체지향과 디자인패턴, 최범균, p. 118" 을 참고하였다.)
public void someMethod(SuperClass super) {
super.someMethod();
}해당 메소드에 SuperClass 를 상속하는 하위 클래스인 SubClass 를 전달해도 someMethod()가 정상적으로 동작해야 한다.
만약 LSP가 제대로 지켜지지 않으면 '다형성'에 기반한 OCP 역시 지켜지지 않기 때문에, LSP을 지키는 것은 매우 중요하다.
LSP를 어기는 경우: 직사각형-정사각형
LSP를 이야기할 때 자주 사용되는 "직사각형-정사각형 문제"를 들어 LSP를 지키지 않을 때의 문제를 이야기해보려한다.
[출처: 개발자가 반드시 정복해야할 객체지향과 디자인 패턴, 최범균, p.119]
public class Rectangle {
private int width;
private int height;
//높이가 길이보다 작으면 높이를 10만큼 늘려준다.
public void increaseHeight() {
if (height < width) {
height = height + 10;
}
}
public void setHeight(int height) {
this.height = height;
}
public void setWidth(int width) {
this.width = width;
}
public int getHeight() {
return this.height;
}
public int getWidth() {
return this.width;
}
}public class Square extends Rectangle {
@Override
public void setWidth(int value) {
super.setWidth(value);
super.setHeight(value);
}
@Override
public void setHeight(int value) {
super.setWidth(value);
super.setHeight(value);
}
}얼핏보면 상속을 제대로 사용한 것이라고 보인다.
그런데 다음의 테스트 코드를 보자.
public class LSPTest {
@DisplayName("직사각형 테스트 코드")
@Test
public void testLSP() {
Rectangle rectangle = new Rectangle();
testMethod(rectangle);
assertThat(rectangle.getHeight()).isEqualTo(15);
}
@DisplayName("정사각형 테스트 코드")
@Test
public void testSquare() {
Square square = new Square();
testMethod(square);
assertThat(square.getHeight()).isEqualTo(15);
}
private void testMethod(Rectangle rectangle) {
rectangle.setWidth(10);
rectangle.setHeight(5);
rectangle.increaseHeight();
}
}LSP에 따르면 "상위 타입의 객체를 하위 타입의 객체로 치환해도 동일한 동작"을 해야한다. 하지만 위 테스트 코드를 실행하면 다음과 같은 결과가 나오게 되며, 상위타입의 객체를 하위 타입의 객체로 치환하였음에도 불구하고 동일한 동작을 보이지 않고 있다.

이런 경우 LSP가 지켜지지 않은 경우라고 이야기할 수 있다.
결국, increaseHeight() 메소드에 Square 인지를 instanceof 를 통해 확인하는 코드가 추가되어 별도의 처리를 해주어야한다.
그런데 만약 이렇게 된다면 더이상 increaseHeight() 메소드는 Rectangle의 확장에 열려 있지 않게 된다. 결론적으로 LSP와 함께 OCP 또한 지켜지지 않는 코드인 것이다.
이를 해결하기 위해, "직사각형-정사각형" 문제는 상속관계인 것 처럼 보일지라도 이 둘을 상속관계로 묶을 수 없으며 각각을 별개의 타입으로 구현해주는 것이 적절하다.
LSP를 어기는 경우: 값의 범위
이 문제는 "상위 타입에서 지정한 리턴 값의 범위에 해당하지 않는 값을 리턴"하는 것이다.
자바의 "java.io" 패키지에서 제공하는 "BuffredInputStream" 클래스의 read() 메소드를 보면 다음과 같다.

read 메소드의 설명을 보면 "the next byte of data, or -1 if the end of the stream is reached" 라고 설명되어 있다. 즉, 데이터의 다음 바이트 또는 스트림의 끝에 도달한 경우 -1을 반환한다.
그런데 "BufferedInputStream" 클래스는 final 선언이 되어 있지 않으므로 이를 상속해서 우리만의 InputStream을 만들 수 있다. 그런데 이 때 read() 메소드를 오버라이딩하여 데이터가 없는 경우 "0"이라는 값을 반환하도록 구현했다고 해보자.
그럼 BuffredInputStream을 대신해서 하위 타입의 객체인 우리가 만든 InputStream 객체로 치환해도 동일한 동작을 할까?
예시로 다음과 같은 코드는 어떻게 될까?
while((len = customInputStream.read(data)) != -1) {
...
}-1을 반환하지 않으므로 무한루프를 돌게될 것이다.
기능의 명세와 확장
리스코프 치환 원칙은 "기능의 명세"에 대한 내용이다.
앞선 직사각형-정사각형 문제에서 Rectangle 클래스의 setHeight() 메소드는 다음과 같은 "기능의 명세"를 제공하고 있다.
- 파라미터로 전달받은 값을 height 값으로 설정한다.
- 이 때, width의 값은 변경되지 않는다.
하지만 Rectangle 클래스를 상속하는 Square의 setHeight()는 width 값까지 함께 변경하므로 예상하는 것과는 다르게 동작한다.
기능의 명세와 관련해서 흔히 발생하는 위반 사례는 다음과 같다.
- 명세에서 벗어난 값을 리턴한다. (BufferedInputStream)
- 명세에서 벗어난 예외를 발생시킨다.
- 명세에서 벗어난 기능을 수행한다. (직사각형-정사각형)
LSP -> OCP
리스코프 치환 원칙은 또한 확장에 관한 것이다. LSP를 어기면 OCP 또한 어기게 된다.
어떤 가게에서 상품에 쿠폰을 사용하여 가격을 할인해주는 정책을 펼친다. 따라서 우리는 다음과 같이 Coupon 클래스를 구현하고 item을 매개변수로 받아 item 가격에 할인율을 적용하여 할인 금액을 계산해주는 책임을 두기로 하였다.
public class Coupon {
public int calculateDiscountAmount(Item item) {
return item.getPrice() * discountRate;
}
}그런데 모든 상품이 아닌 특정 상품들에 대해서는 할인을 해주지 않기로 하였다고 하자. 그리고 그러한 상품들은 Item을 상속하는 NoDiscountItem 을 구현하였다고 하자.
그렇다면 Coupon 클래스의 calculateDiscountAmount() 는 어떻게 변경되어야 할까?
다음과 같이 "instanceof"를 사용하여 item 의 실제 타입이 NoDiscountItem 인지를 확인해주어야 할 것이다.
public class Coupon {
public int calculateDiscountAmount(Item item) {
if (item instanceof NoDiscountItem) {
return 0;
}
return item.getPrice() * discountRate;
}
}그런데 과연 calculateDiscountAmount()가 Item의 구체적인 타입에 대해서 알 필요가 있을까?
그리고 이렇게 "instanceof" 를 사용하고 있다는 것은 하위타입이 상위타입을 제대로 대체하고 있지 못하고 있는 것이고, LSP를 지키지 못한 경우이다.
타입을 확인하는 기능(ex. instanceof)을 사용하는 것은 전형적인 LSP를 위반할 때 발생하는 증상이다.
만약에 향후에 특정 아이템이 아닌 신규 아이템에 대해서 한 달간만 할인하는 정책도 추가된다면 어떻게 될까? 해당 기간이 끝나면 NoDiscountItem과 마찬가지로 할인을 하지 않아야할 것이며, 이에 따른 조건이 추가되어 주어야할 것이다.
즉, Item의 할인 가능 여부는 변경되는 부분이며 이에 대한 메소드를 Item 클래스에 추가함으로써 LSP를 지키도록 개선해볼 수 있다.
public class Item {
...
public boolean isDiscountAvailable() {
return false;
}
...
}public class Coupon {
public int calculateDiscountAmount(Item item) {
if(item.isDiscountAvailable()) {
return item.getPrice() * discountRate;
}
return 0;
}
}이제 Coupon의 코드를 변경하지 않으면서 새로운 할인 정책에 따른 Item들을 추가할 수 있고, 그에 따라 isDiscountAvailable() 메소드만 오버라이딩해주면 된다. 즉, LSP도 지키고 그에 따라 OCP도 지킬 수 있게 된 것이다.
인터페이스 분리 원칙
인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다.
(이 원칙의 정의는 "클라이언트는 자신이 사용하는 메소드에만 의존해야한다."로 되어있음)
SRP 에서도 보았듯이 하나의 타입에 여러 기능이 섞여 있을 경우 한 기능의 변화로 인해 다른 기능이 영향을 받을 가능성이 높아진다. 그리고 이는 인터페이스에도 마찬가지 이다.
클라이언트 입장에서 사용하는 기능만 제공하도록 인터페이스를 분리함으로써 한 기능에 대한 변경의 여파를 최소화할 수 있다.
예를 들어서 여러 클라이언트가 하나의 인터페이스를 공유한다고 생각하면, 즉 각 클라이언트에 필요한 기능을 하나의 명세(인터페이스)로 나타내었다면 각각의 클라이언트 변경이 인터페이스에 영향을 주게 되고 또 인터페이스의 변경은 다른 클라이언트들의 변경을 초래하게 될 수 있다. 즉, 다음 그림과 같게 된다.
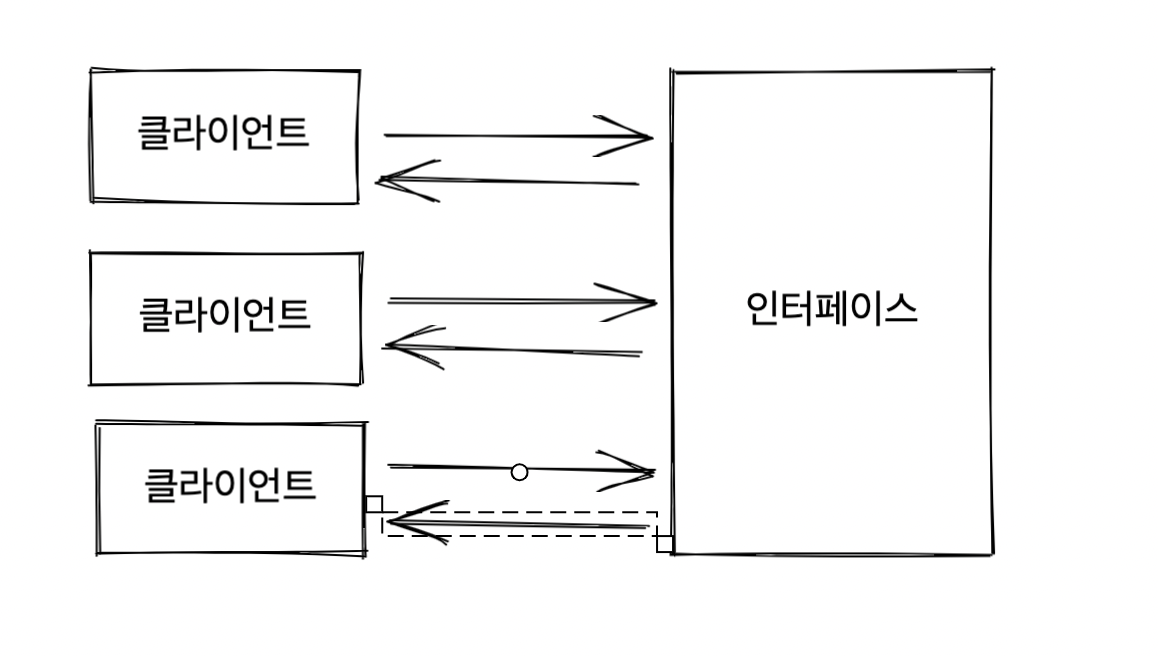
하지만 클라이언트를 기준으로 인터페이스를 분리함으로써 특정 클라이언트로부터 발생하는 변경의 여파가 다른 인터페이스에 영향을 주지 않고 결국 다른 클라이언트에도 미치는 영향을 줄일 수 있게 된다.
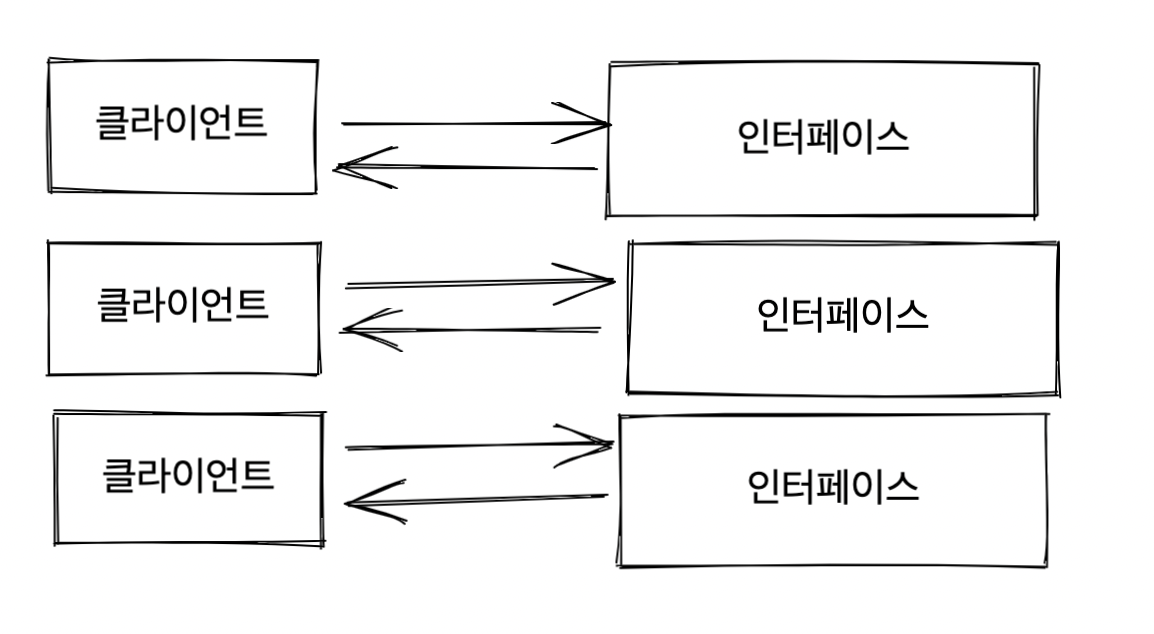
의존 역전 원칙
의존 역전 원칙(Dependency inversion principle, DIP)는 다음과 같이 정의한다.
고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다. 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야한다.
정의에서 언급하는 고수준 모듈과 저수준 모듈은 다음과 같이 정의할 수 있다.
- 고수준 모듈 : 어떤 의미 있는 단일 기능을 제공하는 모듈이라고 정의
- 저수준 모듈 : 고수준 모듈의 기능을 구현하기 위해 필요한 하위 기능의 실제 구현으로 정의
고수준 모듈이 저수준 모듈에 의존할 때의 문제
- 고수준 모듈은 상대적으로 상위 수준에서 프로그램을 다룬다면 저수준 모듈은 각 개별요소(상세)가 "어떻게" 구현될지에 대해서 다룬다.
- 요구사항이 안정화되고 나면 상위 수준에서 프로그램이 변경되기 보다는 상세 수준에서의 변경이 발생할 가능성이 높아진다.
앞서 OCP에서 보인 예제를 다시보자. 만약 FlowController가 고수준 모듈인 "ByteSource"가 아닌 FileByteSource나 SocketByteSource와 같은 저수준 모듈에 의존하게 되면 어떻게 될까?
저수준 모듈로 MemoryByteSource와 같이 메모리로부터 Byte 데이터를 읽는 클래스가 추가된다면 FlowController 또한 변경되어야될 것이다. 이러한 상황은 프로그램의 변경을 어렵게 만들고, 우리의 목표는 "저수준 모듈이 변경되더라도 고수준 모듈이 변경되지 않는 것"인데 이를 이룰 수 없게 된다.
우리는 FileByteSource, SocketByteSource를 추상화한 ByteSource에 FlowController가 의존하게 함으로써 고수준 모듈의 변경없이 저수준 모듈을 변경할 수 있게 된다.
의존 역전 원칙(DIP)은 LSP와 OCP를 따르는 설계를 만들어 주는 기반이 되는 것이다.
소스 코드 의존과 런타임 의존
의존 역전 원칙은 런타임의 의존이 아닌 소스 코드의 의존을 역전시킴으로써 변경의 유연함을 확보할 수 있도록 만들어주는 원칙이다.
이 말이 무슨 말인지 설명하기 위해 앞선 예시를 다시 가져오도록 하겠다.
DIP를 지키는 경우, 소스코드 상에서 FlowController는 FileByteSource나 SocketByteSource와 같은 저수준 모듈에 의존하지 않고, 고수준 모듈인 ByteSource에 의존하고 있다. 즉, 소스코드 상에서의 의존은 역전이 되어있다. 하지만 런타임에서의 의존을 보면 고수준 모듈의 객체(FlowController)에서 저수준 모듈의 객체(FileByteSource 또는 SocketByteSource)
따라서 소스코드 상에서의 의존과 런타임에서의 의존을 구분할 수 있어야 한다.
의존 역전 원칙과 패키지
의존 역전 원칙은 개방 폐쇄 원칙을 클래스 수준뿐만 아니라 패키지 수준까지 확장시켜 주는 디딤돌이다.
의존 역전 원칙은 타입의 소유도 역전시킨다. 의존 역전 원칙을 적용하기 전, 데이터 읽기 타입은 FileDataReader를 소유한 패키지가 소유하고 있다.
의존 역전 원칙을 적용함으로써 데이터 읽기 기능을 위한 타입을 고수준 모듈이 소유하게 된다. 그리고 이는 타입의 소유 역전은 각 패키지를 독립적으로 배포할 수 있도록 만들어 준다.
