1 단계 - 경로 조회 기능
리뷰어: 또링
고민한 내용
또링..!! 기존의 StationDao 의 findByIds() 를 사용해서 IN 절을 활용하여 한 번의 쿼리로 Station들을 조회하려고 하였는데요! 그러다보니 경로의 순서가 유지되지 않는 문제가 발생하더라구요..그래서 문제를 해결할 방법을 찾아보았더니 ORDER BY FIELD가 있어서 적용해보았는데, Syntax 에러가 나더라구요..
참고 블로그1 참고 블로그2
그래서 지금 현재는 반복을 이용해서 단건쿼리를 날리는 식으로 순서를 유지하게끔 해주었는데, 혹시 보다 좋은 방법이 있을까요...??😢
피드백 내용
Q. 메서드명에 이름으로 역을 생성한다는 의미를 담아보면 어떨까요? 지금의 이름으로는 역을 생성하는지 알기 어렵네요 🥲
private Long extractIdByStationName(String name) {A. 해당 부분에서 고민이 많았던 거 같아요...처음에는 extractStationIdFromName 이라는 이름을 부여하였었습니다.
그런데
- 지하철역 이름(name)을 통해서 StationRequest 를 만들고, 요청을 보낸 이후 ExtractableResponse 를 만든다.
- 해당 응답에서 id값을 추출한다.
이렇게 2가지 책임을 가지기 때문에 해당 메소드가 하는 일을 메소드 이름을 통해서 얻기가 어려웠다고 생각이 듭니다.
두 책임은 엄연히 다른 책임이고, makeStationResponse 와 extractStationId 두 가지 메소드로 분리하여 메소드 이름을 통해서 그 의미를 보다 명확히 알 수 있도록 해보았습니다.
하지만 이 두 메소드는 항상 같이 활용되었었고, 이를 분리하여서 얻는 별도의 장점이 없었습니다..
그래서 이 메소드를 가져다 사용하는 입장에서 꼭 알아야 하는 정보가 무엇인지 고민해보니, 사용하는 입장에서는 역 이름을 준다.(input), 해당 역의 id 값을 갖는다.(output) 이라는 정보가 중요하지 않을까 하는 생각이 들어 위와 같은 네이밍을 선택하였습니다.
그래서 다시 원래의 메소드 네이밍과 비슷하게 돌아오게 되었는데요..
내부 구현이 '어떻게' 되는지는 추상화하고 '역 이름을 주면 그 역에 대한 Id를 추출해주는구나' 만 사용하는 입장에서 알 수 있으면 되지 않을까요...??라고 조심스럽게 생각해봅니다..혹시 제가 놓치고 있는 부분 있다면...피드백 주시면 너무 감사할 것 같습니다!!😃
음...🤔 만약 또링이 말씀해주신대로 역을 생성한다는 의미를 담는다고 하면 extractIdAtStationByName? 정도 생각해볼 수 있는 것 같은데, 어떻게 생각하시나요!! (영어가 약해서..😅)
Q. DisplayName에 테스트의 given, when, then을 담아보면 어떨까요? 중복된 이름으로 노선을 생성했을 때 어떤 결과가 나와야하는지 써있었으면 좋을 것 같아요. 🙂
@Test
@DisplayName("기존에 존재하는 노선 이름으로 노선을 생성한다.")A. "기존에 존재하는 노선 이름으로 노선을 생성하면 생성에 실패한다." 와 같이 수정해보았습니다! (이외에 다른 부분들도 구체적이지 않다고 생각되는 부분에 대해서 함께 수정해보았습니다.)
확실히 테스트의 의도를 파악할 수 있는 것 같아요!! (기존에는 결과가 어떻게 되는지가 불명확하네요..생성할 수 있다는 것 같기도 하고..)
테스트 코드를 짜면서 항상 DisplayName을 어떻게 하면 좋을까? 가 고민이었고, 마땅히 좋은 방법이 떠오르지 않으면 간단하게 작성하고 넘어갔던 것 같은데요, 이럴 때 given, when, then 을 활용해보는 것도 좋은 방법이 될 것 같아요! DisplayName만 봐도 테스트 의도를 파악할 수 있고요!!
좋은 방법이라고 생각되어 앞으로 미션에서도 적용해보려고 합니다😁
Q. 데이터를 세팅하는 부분이 길어지면서 테스트 가독성이 떨어지는데, 중복되는 부분을 메서드로 추출해보면 어떨까요?
// given
final Long upStationId = extractIdByStationName("지하철역");
final Long downStationId = extractIdByStationName("새로운지하철역");
final LineRequest params = new LineRequest("신분당선", "bg-red-600", upStationId, downStationId, 10);
ExtractableResponse<Response> param = AcceptanceFixture.post(params, "/lines");
final String savedId = param.header("Location").split("/")[2];A. 저도 테스트를 위해 준비하는 부분이 테스트하려는 부분 보다 커지다보니 테스트 코드가 복잡해 보이고 가독성이 좋지 않다고 생각합니다..! 해당 부분 이외의 부분들에 대해서도 어떻게 하면 조금 더 가독성이 좋아질 수 있을지를 고민해보겠습니다.
현재는 SectionAcceptanceTest 와 같이 어떤 메소드로 추출하기 힘든 경우(multiple variable이 반환되며 이것이 이후 코드에서 모두 사용되는 경우)에는 어떤식으로 테스트 세팅 하는 부분을 조금 더 가독성 있게 해줄 수 있을지 좋은 방법은 떠오르지 않고, 최대한 네이밍에 신경쓰는게 최선인 것 같습니다...🥲
혹시 다른 좋은 방법이 있다면 힌트를 주시면 너무나 감사할 것 같습니다!!😄
공통되는 부분을 다음과 같이 추출하여 보았습니다.
private String getSavedIdFromInitLine() {
final Long upStationId = extractIdByStationName("지하철역");
final Long downStationId = extractIdByStationName("새로운지하철역");
final LineRequest params = new LineRequest("신분당선", "bg-red-600", upStationId, downStationId, 10);
final ExtractableResponse<Response> param = AcceptanceFixture.post(params, "/lines");
return param.header("Location").split("/")[2];
}확실히 각 테스트에서 given절이 깔끔해져서 어떤 테스트를 하려고 하는지를 파악하기 쉬워졌습니다.😃
하지만 createLine() 부분이나 createLineWithDuplicateName 과 같은 부분들도 충분히 빼낼 수 있지만, 이는 테스트를 위한 준비 라기 보다 테스트 하려는 부분에 포함된다고 생각되어 별도로 추출하지 않았습니다..!!
SectionAcceptanceTest부분의 가독성이 좋지 못하다고 생각을 해서 어떻게 가독성을 높일까 고민하였었습니다. 특히 네이밍을 교대역Id 이런식으로 한글 변수를 사용해서 가독성을 높일까 고민해보았고,
dynamicTest 라는 개념도 주변 크루에게 배워서 사용해볼까 하였습니다. 그런데 제가 원하듯이 독립적으로 테스트를 수행할 수는 없고, 초기 세팅 데이터를 가지고 순서대로 쭉 실행되는 형태이더라구요..(깊이있게 공부해보진 못해서 독립적으로 하는 방법이 있는지는 모르겠습니다.ㅎㅎ....)
그래서 고민하던 와중 제가 given과 when 절을 혼동하였다는 것을 발견하였습니다. 내가 테스트하려고 하는 것은 기존 역을 환승역으로 사용하면서 구간을 등록하는 것이었기 때문에 crossSectionTest에서 신사역, 양재역을 등록하는 부분이 when 절에 와야하더라구요! 이렇게 수정해보았습니다😁
Q. 다른 테스트처럼 정말 데이터에 변경이 가해졌는지 확인해보면 좋을 것 같아요. 조회해서 없는 걸 확인해보면 어떨까요?
ExtractableResponse<Response> response = AcceptanceFixture.delete("/lines/" + savedId);
// then
assertThat(response.statusCode()).isEqualTo(HttpStatus.NO_CONTENT.value());A. /lines/{id} DELETE METHOD 로 요청을 보내고 응답이 제대로 와서, NO_CONTENT 응답코드를 받는지를 확인함을 통해서도 삭제가 제대로 되었는지 확인할 수 있다고 판단하였는데요!! 혹시 조회 요청을 통해서 한 번 더 확인함으로써 얻는 이점이 어떤 것이 있을지 궁금합니다..!!🤔
Q. 요금에 대한 테스트도 있으면 좋을 것 같아요 :)
public class PathAcceptanceTest extends AcceptanceTest {A. @ParameterizedTest, @ValueSource 를 이용하여 구간별 요금에 대한 테스트를 진행하도록 FareTest를 수정하였고, 이를 Path에 대한 인수테스트에도 추가해주었습니다.😃
@DisplayName("10km ~ 50km 는 5km 마다 100원이 추가되므로 11~15km는 초과운임이 부과되어 1350원 이다.")
@ParameterizedTest
@ValueSource(ints = {11, 12, 13, 14, 15})
public void checkBoundaryTen(int distance) {
// given
final Fare fare = new Fare(distance);
// when
final int result = fare.calculate();
// then
assertThat(result).isEqualTo(1350);
}Q. 하나의 메서드가 여러 일을 하고 있어요!
private void validateArgument(String name, String color) {
if (name.isBlank() || color.isBlank()) {
throw new IllegalArgumentException("노선의 이름 혹은 색이 공백일 수 없습니다.");
}
if (name.length() > 255 || color.length() > 20) {
throw new IllegalArgumentException("노선의 이름이 255자 보다 크거나, 색이 20자 보다 큽니다.");
}
}A. 공백에 대한 검증 및 길이에 대한 검증을 해주고 있고, 또 name에 대해서 color에 대해서 모두 진행해주고 있어요..만약 해당 메소드가 실패하여 예외가 발생한다면 4가지 경우의 수가 있을 수 있겠네요..(메시지를 통해서 2가지로 분리는 되지만..)
LineColor라는 VO를 추가하여 Color에 대한 검증 책임을 갖도록 하여 Name과 Color에 대한 검증을 확실히 분리해주었습니다! 또한 validateBlank, validateLength 두 가지 메소드로 분리해주었습니다!😁
Q. Line은 name과 color가 같으면 같은 객체인가요? 그럼 여기서 id가 가지는 의미는 무엇인가요? 🤔
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Line)) {
return false;
}
Line line = (Line) o;
return Objects.equals(name, line.name) && Objects.equals(color, line.color);
}
@Override
public int hashCode() {
return Objects.hash(name, color);
}A. 색상에 대한 요구사항이 명시되어 있지는 않지만 추가 기능: 지하철역 생성 시 이미 등록된 이름으로 요청한다면 에러를 응답 라는 내용을 바탕으로, "name과 color" 가 중복되면 안된다. 라는 요구사항이라고 생각하고 비즈니스 로직을 작성하였습니다.
따라서 name과 color가 같으면 같은 Line이라고 생각하였습니다.
하지만 노선의 이름과 색깔 모두 중복이 가능하도록 비즈니스 로직이 변경된다면 당연히 이름과 색깔 만으로 두 객체가 동등하다고 판단하면 안된다고 생각합니다..!
즉, 만약 이름과 색깔 모두 중복이 가능하게 요구사항이 변경된다면 식별자인 id로 두 객체를 판별해야할 것 같아요!
유일한 식별자인 id가 1인 "a, a" 가 있고, 10인 "a, a"가 있으면 이 둘은 같은 같은 도메인인가?라고 질문했을 때 '아니오'라고 대답할 수 있을 것 같습니다. 또한 만약 정말 이름과 색상이 같은지를 비교한다 라고 하면 꼭 equals()가 아닌 별도의 메소드(sameName, sameColor)를 통해서 수행할 수 있지 않을까?하는 생각이 들더라구요..!!
해당 부분에 대해서 크루들과 많이 이야기해보고 고민해보았었는데, 결론적으로 제가 비즈니스 로직에서 유일한 식별자인 id를 통해서 동등성을 비교하는게 적절하다고 결론내었습니다!
(익명의 크루 및 코치와의 대화 요약: "id를 DB랑 연관짓지말고, 유일한 식별자인 id필드를 가진 도메인 객체라고 생각을 했을 때, name과 color가 달라진다고 이 둘이 다른 객체인가?" -> "같은 객체이다"
ex) 디우 -> 동규 로 이름을 바꾸면 다른 사람인가? '나'라는 사람의 유일한 식별자인 주민등록번호는 같으므로 동일한 사람이다.)
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Line line = (Line) o;
return Objects.equals(id, line.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}Q. 중복되는 URI는 @RequestMapping을 통해 제거해주세요 :)
@PostMapping("/lines")A. 음,,,저는 아직 @RequestMapping을 클래스에 걸어주어서 중복되는 URI를 제거해주는 방법이 좋은가에 대해서는 의문이 들어요..🤔
우선 저는 하나의 컨트롤러에서 이렇게 @RequestMapping으로 URI를 제거해준다고 하면 모든 컨트롤러에서 일관성을 위해 이와 같은 방법을 사용해야한다고 생각하는데요!
예를 들어서 SectionController도 @RequestMapping을 통해서 공통되는 URI를 제거해준다고 하면 다음과 같이 될 텐데..
@RestController
@RequestMapping("/lines/{lineId}/sections")
public class SectionController {
private final SectionService sectionService;
public SectionController(SectionService sectionService) {
this.sectionService = sectionService;
}
@PostMapping
public ResponseEntity<Void> createSection(@PathVariable Long lineId, @RequestBody SectionRequest request) {
sectionService.save(lineId, request);
return ResponseEntity.ok().build();
}
....
}@PostMapping 만 있고 value가 없으면 PathVariable이 무엇인지(URI의 어느 부분에서 오는 것인지를 보고 싶을 때) RequestMapping 된 곳을 다시 보아야 할 것 같아요..(Class가 커지면 class 선언부로 올라가서 확인해야하구요..)
그럴 일은 거의 없겠지만 URI가 길어지고 PathVariable이 여러개라면 더더욱 파악하기가 쉽지 않을 것 같다는 생각이 듭니다..! 또링은 저의 생각에 대해서 어떻게 생각하시는지 조심스럽게 여쭈어 봅니다..!!😅
Q. 이 객체는 요금에 대한 객체인가요, 거리에 대한 객체인가요?
public class Fare {
public static final int BASIC_FARE = 1250;
public static final int ADDITIONAL_FARE = 100;
private static final int SECOND_ADDITIONAL_FARE = 800;
private static final int BASIC_DISTANCE = 10;
private static final int SURCHARGE_BOUNDARY = 50;
private static final int FIRST_CHARGING_UNIT = 5;
private static final int SECOND_CHARGING_UNIT = 8;
private final int distance;A. 저는 우선 '거리'를 근거로해서 '요금'을 책정하는 class를 정의한다는 관점에서 Fare가 distance 필드를 가지고 있는데요!
🤔고민을 해보니 distance를 필드로 가질 이유가 없는 거 같더라구요! (calculate 메소드 내부에서만 사용되기 때문에) 그리고 다음 미션 진행을 조금 고려해보니 생성자에서 전략을 받도록 할 수도 있겠다. 이런 막연한 생각이 들어요.
그리고 distance를 필드로 가졌던 이유는 만약 기본생성자만을 가지는 Fare라면 calculate를 static 메소드로 둔 Util 클래스와 뭐가 다르지? 라는 생각이 들어서였습니다. (이렇게 되면 요구사항 추가에 따라 age 필드도 가질 수 있겠다고 생각합니다.😃)
Q. URI를 보면 Line이 Section을 가질 것 같은데, 그렇지 않군요! 객체 설계를 어떻게 하셨는지(어떤 과정으로 하셨는지) 공유해주실 수 있을까요~? 🙂
import java.util.Objects;
public class Line {A. "Section 스스로가 어느 Line에 속하는지를 안다!" 라고 생각해도 괜찮을 것 같아요!
가장 큰 이유는 스키마 인데요, 일대다 관계라 스킴에서 Line이 Section의 PK를 FK로 가지고 있습니다!(그래서 Section이 LineId를 가지는 것은 불가피해 보여요..제가 잘 모르는 거일 수도...😅) 따라서 만약 Line 또한 Sections을 가지고 있다면, 물론 Section에선 Line 자체가 아닌 LineId를 아는 것이지만 양방향 연관관계가 형성된다고 생각합니다..!
그래서 현재와 같은 객체 설계를 하였던 것 같아요..!
2 단계 - 요금 정책 추가
리뷰어: 또링
고민한 내용
Fake 객체 제거
이번 2단계를 진행하면서 가장 크게 바뀐 점은 Fake 객체의 제거인 것 같습니다.
2단계 미션을 진행하면서 Station, Section, Line 3개의 테이블 조회가 필요하다 생각되었고, 쿼리도 조금 복잡해지는 느낌을 받았습니다. 그러다보니 Fake 객체 자체에 대한 의심이 들기 시작했습니다.
(실제로 JdbcDAO는 정상 동작을 하는데, FakeDAO 의 논리적인 오류로 Test가 제대로 동작하지 않았는데요..JdbcDAO 쪽만 바라보고 있다 뒤늦게 FakeDAO를 수정한 경험을 하였습니다.🥲)
그러다보니 쿼리를 직접 날려서 DB에서 데이터를 가져오는 JdbcDAO와 List로 데이터를 들고 있는 FakeDAO가 논리적으로 동일한 동작을 하는지 FakeDAO 자체에 대한 검증이 필요하게 되었습니다. 하지만 계속해서 메소드가 늘어나고 늘어나는 메소드들이 단순하지 않다보니 쉽지 않다는 결론을 내리게 되었습니다.
따라서 Fake 객체를 제거하고, Service에서 @SpringBootTest를 이용해 JdbcDAO에 대한 의존성을 주입받을 수 있도록 하고, 실제 DB 테이블을 이용하여 테스트를 진행하도록 해주었습니다.(@Sql("/truncate.sql")을 이용해 테이블의 row를 초기화해줄 수 있도록 하였습니다.🙂)
또링 : 좋습니다! 말씀하신 것처럼 실제 코드와 다르기 때문에 Fake 객체는 정말 필요한 경우에만 사용하는 게 좋아요. 👍
나 : 감사합니다!! 개인적으로 궁금해졌는데, 저는 이번에 불편함을 느끼고 Fake 객체를 제거하였습니다!
그런데 정말 필요한 경우에만 사용하는 게 좋아요.라고 해주셔서요..저도 스스로 고민해보겠지만..또링이 말씀해주신 정말 필요한 경우는 언제인지 궁금합니다...😅
또링 : 음.. 저는 주로 외부와 연결된 부분을 fake 객체로 만들어 사용하고 있어요. 예를 들어 매일 교통공사 서버에서 지하철 노선에 관한 정보를 가져와 DB에 업데이트 해주는 기능이 생겼고, 그에 대한 테스트를 작성한다고 합시다. 교통공사 서버를 실제로 찌르기는 비용이 많이 들고 값을 보장할 수 없으니 fake 객체를 만들어 원하는 상황을 만든 후 그 값을 이용하여 테스트를 하는게 편하겠죠? 이렇게 외부에 대해 의존성을 끊어내면서, 원하는 시나리오로 테스트를 하고 싶을 때 사용하고 있어요ㅎㅎ 사실 이 부분은 말씀해주신 것처럼 테스트를 작성하면서 계속해서 고민해보면 더 좋을 것 같네요 ☺️
요구사항 변경에 따른 생성자
다음으로 조금 고민되는 부분은 요구사항 변경에 따른 생성자입니다. 예를 들어 Line에서 extraFare 필드가 추가되면서 실제 프로덕션 코드에서는 더 이상 (name, color)만을 필요로 하는 생성자는 불필요하게 되었고, 그러다보니 해당 생성자를 호출하는 코드가 이전 테스트 코드에 밖에 존재하지 않게 되었습니다.
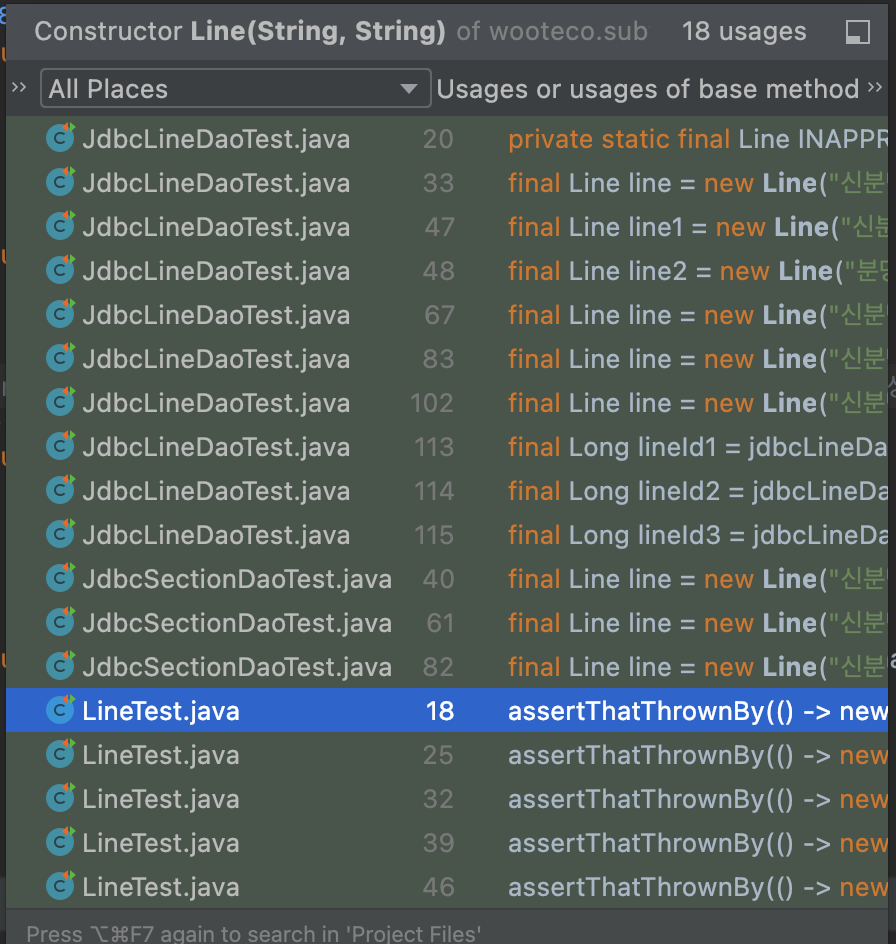
이렇게 요구사항이 늘어나고 변경되면서 이전 코드들이 불필요해지는 경우에는, 그냥 두는게 나을지 아님 제거를 해주는게 깔끔할지..조금 고민이 들었습니다. (지금은 변경해야할 테스트 코드가 18군데이지만 100군데로 늘어났다고 하면 쉽지 않은 작업이 될 것 같아서...) 혹시 또링은 이부분에 대해서 어떻게 생각하시나요???
또링 : 저는 더 이상 사용하지 않는 코드는 무조건 제거해요. 그때그때 제거 안하면.. 나중에 어떤 코드가 사용되는지, 어떤 이유로 남아있는 건지, 정말 삭제해도 되는지 혼란스러워하다가 점점 쌓이게 되기 때문이에요 ㅎㅎ (경험담 🤣)
변경해야할 곳이 많다면 IDE의 도움을 받는 방법도 있습니다!
변경하고자 하는 메서드에서 refactor - change signature 를 누른 뒤,
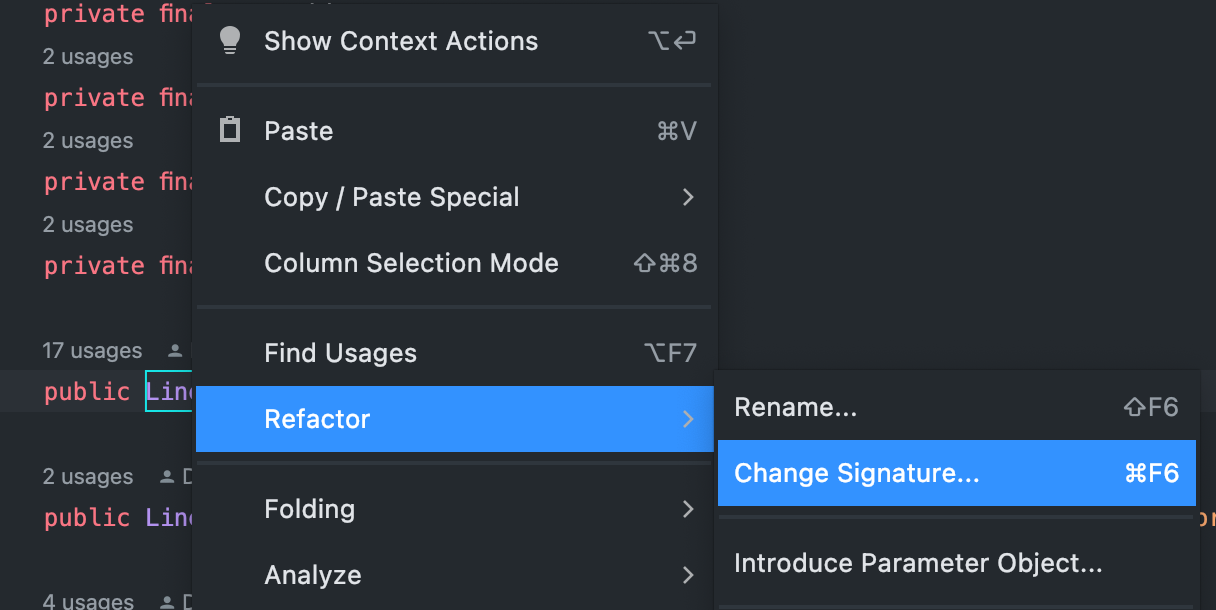
여기서 필드를 추가하면서 기본값 설정하면 됩니다 😁
나 : 저도 사용하지 않는 코드를 제거하는 것에 동의합니다!! change signature는 정말 꿀팁이네요!! 감사합니다.🙏
저도 나름대로 어떻게 개선할까 고민하다가 스터디에서 빌더 패턴이야기가 나와서 오찌의 빌더패턴
이를 고려해보고 있었습니다! 심지어 lombok을 쓰면 편리하게 어노테이션 하나로 해결할 수 있어서 좋다고 생각하는데요, 아무래도 필수 필드에 대한 보장을 해줄 수 없어서 망설여지더라구요..
혹시 또링은 @Builder 에 대해서 어떻게 생각하시는지 궁금합니다..또 실무에서도 많이 사용하는지 궁금합니다ㅠ.ㅠ (만약 실무에서 많이 사용한다면..어떻게 필수 필드에 대해서 보장해주는지도 궁금해요ㅠ.ㅠ)
또링 : 많은 고민을 하셨네요 👍 말씀하신 것처럼 빌더패턴을 이용하면 생성자 변경에 유연하게 대처할 수 있지만, 컴파일에러가 발생하지 않기 때문에 필수값이 누락되어도 사전에 인지할 수 없는 단점이 있습니다.
저는 개인적으로 실무에서@Builder를 많이 사용하고 있어요. 필수값에 대해서는 생성자를 생성해 @builder를 붙인 후 생성자 내부에서 값을 검증하는 방식으로 사용하고 있습니다.
@Builder
public Line(String name, String color, int extraFare) {
Assert.hasText(name, "이름이 없습니다.");
this.(null, name, color, extraFare);
}추가로 빌더패턴 관련해서 읽어보면 좋은 글도 남겨요! 다음 미션 진행하면서 한 번 읽어보세요😃
https://johngrib.github.io/wiki/pattern/builder/
DB 조회
이번 미션을 진행하면서 비즈니스 로직 작성보다는 어떻게 DB 테이블에서 필요한 데이터를 가져올지에 대해 조금 초점을 맞춰서 고민해보았던 것 같습니다! 특히 station 정보들을 통해서 Line을 조회하려고하다보니 #175 (comment) 에 대해서도 조금 더 고민해 본 것 같아요..! 현재는 최대한 기존 구조에서 크게 변경없이 IN 절을 활용하여 총 2번의 쿼리로 원하는 결과를 구하도록 했습니다!!
피드백 내용
Q. ✍🏻 지난 대화 이어서! #175 (comment)
많은 고민을 하셨었군요. 고민의 흐름이 좋네요. 👍 저도 메서드 이름은 내부 구현은 추상화하고 메서드가 하는 행위에 대해서 나타내는 것이 좋다고 생각해요. 하지만 현재 extractIdByStationName()을 보면 이름을 통해 아이디를 가져온다는 것은 알 수 있지만, 해당 역을 조회하는지 생성하는지 알 수 없어 모호하게 느껴져요. 그래서 createStationByName()정도면 좋지 않을까 생각했습니다. (extractId를 굳이 뺀 이유는 보통의 create API는 생성 후 리소스 아이디를 반환하기 때문에 뺐습니다.) 디우도 아시겠지만 네이밍은 정말 취향의 영역이라 원하시는대로 반영해도 좋을 것 같아요! 디우 생각 공유해줘서 고마워요~ 😃
@DisplayName("새로운 노선 요청이 오면 노선을 등록한다.")
void createLine() {
// given
final Long upStationId = extractIdByStationName("지하철역");A. 말씀해주신대로 해당 역을 조회하는지 생성하는지 알 수 없네요..🥲
보통의 create API는 생성 후 리소스 아이디를 반환하기 때문에 와 같은 내용을 몰라서 extractId 라는 부분을 명시하려고 했던 것 같아요!!
명시적으로 id를 추출한다 라는 내용을 메소드명에 포함하지 않고, 암묵적으로 create API는 생성 후 리소스 아이디 반환 통용되는 내용이라면 createStationByName 이 보다 적절할 것 같네요!!😃 반영해보도록 하겠습니다~_~
private Long createStationByName(String name) {
final StationRequest stationRequest = new StationRequest(name);
final ExtractableResponse<Response> stationResponse = AcceptanceFixture.post(stationRequest, "/stations");
return stationResponse.jsonPath()
.getObject(".", StationResponse.class)
.getId();
}또링 : 모든 생성 API가 그렇다기 보다는 현재 프로그램의 Line 생성 API에서도 리소스 위치를 반환해주고 있고, 보통 생성하는 메서드가 어떤 값을 반환하고 있다면 그 값은 아이디일 확률이 높다!였습니다. 😃 더 정확하게 표현하자면 extractIdOfCreatedStationByName 과 같은... 이름이 되겠지만.. 가독성도 떨어지고 굳이 이렇게까지 자세히 알필요는 없다고 생각해서 createStationByName을 말씀드렸어요 ㅎㅎ 충분히 잘 이해하셨겠지만, 혹시 생성하는 API는 무조건 id를 반환한다라고 오해하실까봐 설명 덧붙입니다 :)
Q. ✍🏻 지난 대화 이어서! #175 (comment)
그런 이유로 status만 비교하셨군요! 그럼 여기서 질문 하나 드릴게요 🙂 디우가 생각하는 인수테스트란 어떤 테스트인가요? 또 어떤 것을 검증하는 게 좋다고 생각하시나요?
assertThat(response.statusCode()).isEqualTo(HttpStatus.NO_CONTENT.value());A. 인수 테스트란 시나리오(사용자 스토리) 기반으로 기능을 테스트하는 것이라고 생각합니다.
이를 통해서 얻는 가장 큰 장점은 배포 없이 기능 동작을 빠르게 확인하고 피드백 받을 수 있는 것이라고 생각합니다.
(만약 인수테스트가 없다면 실제로 해당 시나리오를(지금의 예에서는 지하철 노선도 미션 웹 페이지에서) 직접 해보아야 합니다.)
조금 더 덧붙이자면, 단위 테스트, 통합 테스트, 인수 테스트 등등 테스트의 종류는 다양하고 이를 나누는 기준은 무엇을 검증하려고 하는지에 따라서 나뉜다고 생각하는데, 인수 테스트는 사용자 스토리(시나리오)를 검증 하려는 테스트라고 생각합니다. 따라서 deleteById의 경우에는 다음과 같은 시나리오가 될 것 같습니다.
- 노선 삭제
- 사용자가 '미리' 저장해 놓은노선정보가 존재한다. (존재하지 않으면 삭제할 수 없다.)
- 삭제할 노선의 id값을 통해서 삭제 요청을 한다. (정확히 사용자는 어떤 id의 존재는 모르고, 버튼등을 통해서 요청을 보내게 된다.)
- 삭제가 정상적으로 이루어지면 화면을 통해서 노선이 삭제된 것을 확인할 수 있다.
실제 웹 페이지를 통해서 보면 다음과 같을 것 같습니다.
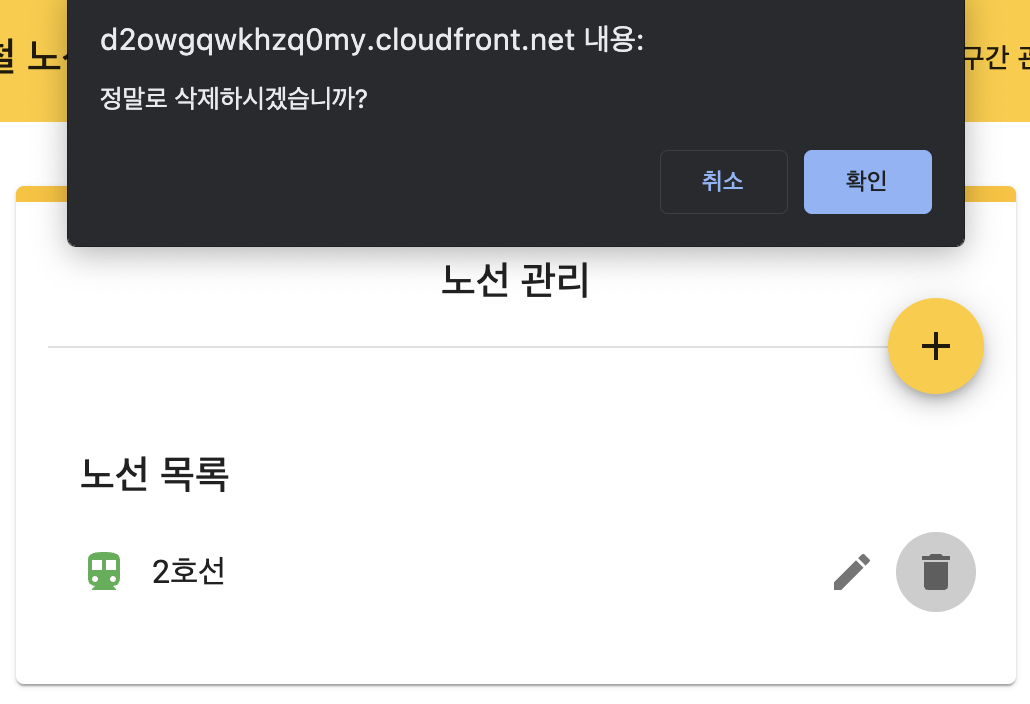

즉, 사용자는 delete 요청 이후에 get 요청을 통해서 "/lines"로 요청을 하면서 노선 목록을 조회함을 통해서 삭제가 정상적으로 처리됐음을 확인하게 되겠네요!!
이러한 관점이라면 또링이 말씀해주신 것과 같이 NO_CONTENT 확인 이후에 GET을 통해서 조회하여 노선이 정말 존재하지 않는지 확인해보는 것이 보다 좋은 인수테스트가 될 수 있을 것 같다고 생각합니다!! 개선해보겠습니다~_~
추가적으로 StationAcceptanceTest 의 지하철역을 제거하는 deleteStation 에서도 같은 맥락으로 delete 이후에 데이터 변경 내용을 확인하는 코드를 추가해보도록 하겠습니다!
또링 : 좋습니다 👍 추가로 말씀드리면 isEmpty보다는 해당 아이디가 존재하지 않음을 검증하는 것이 더 정확할 것 같아요.
assertThat(extractIds(getResponse)).doesNotContain(Long.valueOf(savedId)); @Test
@DisplayName("기존 노선을 삭제할 수 있다.")
void deleteById() {
// given
final String savedId = getSavedIdFromInitLine();
// when
final ExtractableResponse<Response> response = AcceptanceFixture.delete("/lines/" + savedId);
final ExtractableResponse<Response> getResponse = AcceptanceFixture.get("/lines");
// then
assertThat(response.statusCode()).isEqualTo(HttpStatus.NO_CONTENT.value());
assertThat(getResponse.statusCode()).isEqualTo(HttpStatus.OK.value());
assertThat(extractIds(getResponse)).doesNotContain(Long.valueOf(savedId));
}Q. ✍🏻 지난 대화 이어서! #175 (comment)
@ParameterizedTest를 이용한 꼼꼼한 테스트 좋네요 👍
하지만 다른 테스트 메서드들과 중복인 것 같아요. @CsvSource를 이용해서 중복을 제거해보면 어떨까요?
추가로, 경계값만 테스트해도 충분해보여요!
@DisplayName("10km ~ 50km 는 5km 마다 100원이 추가되므로 11~15km는 초과운임이 부과되어 1350원 이다.")
@ParameterizedTest
@ValueSource(ints = {11, 12, 13, 14, 15})
public void checkBoundaryTen(int distance) {A. @ValueSource 를 이용하여 리터럴 값의 배열에 대한 접근을 제공할 수 있고 이를 이용해 @ParameterizedTest를 진행할 수 있다는 것은 알았는데,
입력값에 따라 결과값이 다른 경우에 대해서 어떻게 테스트할지를 잘 몰랐어서..이와 같은 코드를 작성하였던 것 같습니다!!
그런데, 또링이 말씀해주신 @CsvSource를 이용하면 입력값에 따라 결과값이 다른 경우를 적절히 테스트 할 수 있네요!! (CSV(Comma Separated Values), 콤마를 기준으로 분리해서 읽는다.)
이전에 한 번 본것같은데 주의깊게 보지 않았어서...적절하게 잘 활용하지 못한 것 같습니다..!! 개선해보면서 확실히 익혀두도록 하겠습니다😁
추가적으로 경계값만 테스트해도 충분하다는 말씀에 동의하며 이 부분도 반영하도록 하겠습니다!😃
class FareTest {
private static final int NO_DISCOUNT_AGE = 20;
private static final int EXTRA_COST = 500;
@DisplayName("기본운임(10km 이내)는 1250원이고, 10km ~ 50km 는 5km 마다 100원이 추가되며, 50km 초과시에는 8km 마다 100원이 추가된다.")
@ParameterizedTest
@CsvSource(value = {"10, 1250", "11,1350", "15,1350", "16,1450", "20,1450", "51,2150", "58,2150", "59, 2250"})
public void checkAdditionalFareByDistance(int distance, int expectedFare) {
// given
final Fare fare = new Fare(distance);
// when
final int result = fare.calculate();
// then
assertThat(result).isEqualTo(expectedFare);
}
@DisplayName("추가 요금이 있는 노선을 이용 할 경우 측정된 요금에 추가된다.")
@Test
public void testAdditionalFareWithLine() {
// given
final Fare fare = new Fare(10, EXTRA_COST, NO_DISCOUNT_AGE);
// when
final int result = fare.calculate();
// then
assertThat(result).isEqualTo(1250 + EXTRA_COST);
}
@DisplayName("어린이는 350원을 공제한 금액의 50%를 할인받고, 청소년은 350원을 공제한 금액의 20%를 할인 받는다.")
@ParameterizedTest
@CsvSource(value = {"10, 0, 6, 800", "10, 0, 13, 1070"})
public void childrenFare(int distance, int extraCost, int age, int expectedFare) {
// given
final Fare fare = new Fare(distance, extraCost, age);
// when
final int result = fare.calculate();
// then
assertThat(result).isEqualTo(expectedFare);
}
}FareTest와 함께 PathAcceptanceTest도 경계값만 테스트해도 충분하다고 생각되어 수정해보았습니다!
@DisplayName("10km ~ 50km 사이는 5km 마다 100원이 추가되고, 50km 초과인 경우 8km 마다 100원이 추가된다.")
@ParameterizedTest
@CsvSource(value = {"11, 20, 1350", "15, 20, 1350", "51, 20, 2150", "58, 20, 2150", "59, 21, 2250"})
public void testAdditionalFare(int distance, int age, int expectedFare) {
// given
final Long sourceStationId = extractStationIdFromName("교대역");
final Long targetStationId = extractStationIdFromName("역삼역");
requestLineWithExtraFare("2호선", sourceStationId, targetStationId, distance, DEFAULT_FARE);
// when
final ExtractableResponse<Response> response = AcceptanceFixture.get(
"/paths?source=" + sourceStationId + "&target=" + targetStationId + "&age=" + age);
// then
assertThat(response.statusCode()).isEqualTo(HttpStatus.OK.value());
final PathResponse pathResponse = response.jsonPath().getObject(".", PathResponse.class);
assertThat(pathResponse.getFare()).isEqualTo(expectedFare);
}Q. ✍🏻 지난 대화 이어서! #175 (comment)
@RequestMapping을 통해 중복 URI를 제거함으로써 얻는 이점은.. 정말 중복 제거라고 생각해요 ㅎㅎ 도메인 용어가 변경되어서 lines -> subway-lines로 변경된다고 했을 때 변경 포인트가 줄어 보다 편하지 않을까요? 또, 해당 컨트롤러에 API를 추가할 때마다 무조건 prefix가 생기니 이 API가 이 Controller에 있는게 맞는걸까?라는 고민도 한 번 더 해볼 수 있구요. (URI의 Prefix가 lines로 시작하는게 어색하다면 다른 컨트롤러로 이동하는게 맞겠죠?)
말씀해주신 @Pathvariable의 경우에는.. 우선 저는 저렇게 사용하고 있지 않아요 ㅎㅎ @RequestMapping을 통해 중복된 모든 URI를 묶는다기 보다는 앞에 붙는 대표 도메인 하나를 묶는다 정도로 이해해주시면 될 거 같아요. 😀
@PostMapping("/lines/{lineId}/sections")A. lines -> subway-lines로 변경된다고 했을 때 변경 포인트가 줄어 보다 편하지 않을까요? 라는 말씀에 동의합니다!! 또한 추가할 때에도 말씀해주신대로 무조건 prefix가 생기니 적절한 Controller에 추가할 수 있도록 도울 수 있을 것 같구요!!
특히 모든 URI를 묶는다기 보다는 앞에 붙는 대표 도메인 하나를 묶는다 정도로 이해해주시면 될 거 같아요. 라는 말씀에 적극 동의합니다!!😃
저도 해당 코멘트를 달고 나서 계속 고민해보았는데, URI의 어느 부분에서 오는 것인지를 자주 확인할 일이 있을까🤔 라는 생각이 들었습니다. 그런데 처음과는 다르게 그렇지 않다라는 생각이 들더라구요..또 말씀해주신 것과 같이 적절한 Controller에 해당 API가 있다면, @RequestMapping으로 묶인 pathVariable이 있어도 그렇게 자주 올려다볼 필요는 없을 것 같다는 생각이 들더라구요.
(예를 들어서 이전 코멘트의 예시의 경우, 어느 line에 속하는 sections 라는 것은 도메인의 제약(?)사항이므로 @PathVariable Long lineId 를 고민할 이유가 없었습니다. 구간이라는 도메인은 어떤 라인에는 속해야하기 때문에 "2호선에 ㅁㅁ역 부터 ㅁㅁ역까지의 구간을 추가한다." 이므로)
그래서 또링이 제안주셨던 것 처럼 @RequestMapping 을 이용해서 대표 도메인을 묶어보려고 합니다!!
또링의 생각이 궁금했는데, 말씀해주셔서 감사합니다ㅎ.ㅎ🙏
@RestController
@RequestMapping("/lines/{lineId}/sections")
public class SectionController {
private final SectionService sectionService;
public SectionController(SectionService sectionService) {
this.sectionService = sectionService;
}
@PostMapping
public ResponseEntity<Void> createSection(@PathVariable Long lineId, @RequestBody @Valid SectionRequest request) {
sectionService.save(lineId, request);
return ResponseEntity.ok().build();
}
...
}Q. 도메인에서 특정 라이브러리에 직접 의존해도 괜찮을까요? 🤔
A. 저도 분리하는게 좋다고 생각합니다!!😁 코멘트를 받기 이전에도 여러가지 시도해보다가 PathStrategy 인터페이스(path, weight, edge 제공)를 하나 두고, 이에 대한 구현체로 jgrapht를 이용하여 최단경로의 path, weight, edge 를 제공하도록 하였습니다. 그리고 PathStrategy를 주입받아서 다음과 같이 필요한 필드를 초기화하도록 해주었습니다.
이렇게 되면 기존 Path를 사용하던 곳에서 수정할 필요도 없어지더라구요..그런데 Strategy의 인터페이스와 Path의 인터페이스가 동일하여 "Path implements PathStrategy" 가 되어야하나..뭐가 다른거지..하는 생각이 들어서요...더 좋은 방법이 없을까 고민하고 있습니다...(그래서 commit을 안해놨었습니다..ㅠ.ㅠ)
혹시 조금만 힌트를 제공해주실 수 있을까요??🥺
매트와 이야기해보았는데요..!! 기존에 Service에서 new를 통해서 생성하게 되면 변경이 있을 때 Service를 결국 고쳐야하고 OCP를 지키지 못하는 것 아니냐..하는 이야기를 하였고, @Component 를 통해서 빈으로 등록하여 스프링의 이점을 적극 활용해보라는 말에 공감하여, 수정을 진행해보았습니다..!!
그러한 과정에서 로직도 기존 네이밍인 Generator에 맞게끔 Path 도메인을 생성해 반환해주도록 변경하다 보니, 이전 코드보다 훨씬 마음에 드는 코드가 되었습니다..!!😁
이번에 도메인에서 외부 라이브러리 의존성을 끊어내는 경험을 통해서 많은 것을 고민하고 배워갈 수 있는 것 같아요~_~
public class Path {
private final List<Station> shortestPath;
private final int shortestPathWeight;
private final List<Section> shortestEdge;
public Path(List<Station> path, int pathWeight, List<Section> pathEdge) {
this.shortestPath = path;
this.shortestPathWeight = pathWeight;
this.shortestEdge = pathEdge;
}
public List<Station> getShortestPath() {
return shortestPath;
}
public int getShortestPathWeight() {
return shortestPathWeight;
}
public List<Section> getShortestEdge() {
return shortestEdge;
}
}@Component
public class JgraphtPathGenerator implements PathGenerator {
public JgraphtPathGenerator() {
}
@Override
public Path generatePath(List<Section> sections, Station sourceStation, Station targetStation) {
final WeightedMultigraph<Station, SectionEdge> graph = new WeightedMultigraph<>(SectionEdge.class);
addVertexes(graph, getStationIds(sections));
addEdges(graph, sections);
final DijkstraShortestPath<Station, SectionEdge> dijkstraShortestPath = new DijkstraShortestPath<>(graph);
final GraphPath<Station, SectionEdge> path = dijkstraShortestPath.getPath(sourceStation, targetStation);
return new Path(getShortestPath(path), getShortestPathWeight(path), getShortestEdge(path));
}
...
}AOP에 대해서 공부하다가 proxy라는 개념을 접햇는데요, 만약 Path를 proxy로 두고, JPath를 이용하여 실제 기능을 구현한 객체를 대상 객체로 두어 실제 작업을 위임하는 방식은 어떻게 생각하시나요..???
(프록시가 핵심 기능을 구현하지 않는 대신 여러 객체에 공통으로 적용할 수 있는 기능을 구현한다는 점에서 proxy라고 말해도 될지 모르겠지만...😅)
또링이라면 어떤 방식으로 분리했을지가 궁금해요..!!😁
또링 : AOP도 공부하셨군요 👍 Proxy 개념은 여러 기술에 걸쳐 계속 등장하니 시간 되실 때 지금처럼 학습하고 넘어가는 게 좋습니다!
이 부분에 대해서는 Proxy 패턴에 대해 더 공부해보면 좋을 것 같아요. 어떤 문제를 해결하기 위해 나온 패턴인지 살펴보시면 지금 질문주신 상황에 적절할지에 대한 답이 될 것 같습니다. 혹시 계속 물음표가 떠다닌다면 DM 주셔도 좋구요 😃
나 : 질문드렸던 이유는 해결하려는 상황에 딱 드러맞는 적절한 패턴은 아니라고 생각이 들어서 적용해도 될지에 대한 의문이 남아서였어요..🥲
말씀 주셨던 것 처럼 Proxy 패턴에 대해서 공부하면서 함께 그 목적을 고려해봐야할 것 같습니다..!!
경로 조회 동안 좋은 리뷰 주셔서 감사합니다!!ㅎ.ㅎ
추가 피드백 by 구구
final List<Long> lineIds = getLineIds(sections);
final String inSql = String.join(",", Collections.nCopies(lineIds.size(), "?"));
final String sql = String.format("SELECT * FROM line WHERE id IN (%s)", inSql);A. 블로그에 쓰여있는 7가지 이유로만 보았을 때에는 왜 모든 경우에서 SELECT * 을 쓰면 안되는지, SELECT *이 더 나은 경우는 없을까 하는 궁금증에 찾아가 질문을 드렸는데요..
우선 가독성 측면에서도 각 절(select, from, where)을 나누거나, 컬럼을 나눠줌으로써 충분히 가독성을 챙길 수 있다는 말씀에 동의하며, 만약 특정 컬럼이 삭제되거나 추가되는 등에 변경이 일어났을 때 그것을 캐치하기 힘들기 때문에 SELECT *을 지양하는 것으로 이해하고, 적용하였습니다!😃
Deprecated 메서드를 사용하셨네요. 다른 메서드를 사용해보시기 바랍니다.

A. deprecated 메소드를 왜 사용하면 안될까..를 찾아보았는데요, 우선 deprecated란 "중요도가 떨어져 더 이상 사용되지 않고 앞으로는 사라지게 될" 이라는 뜻으로 버전업되면서 사라질 수 있는 메소드이고 그런 메소드에 @deprecated 를 걸어준다는 것을 확인하였습니다.
그럼에도 불구하고 메소드를 지원하는 이유는 하위 호환성 때문이라고 생각합니다. 하지만 언젠가 결국 버전업되면서 해당 메소드를 제거하게 될 수 있고, 그렇게 되면 제가 사용한 jdbcTemplate.query() 메소드는 컴파일 에러가 발생하고 수정을 요구하게 됩니다. 이러한 이유로 구구가 다른 메소드 사용을 권유하신 것이라고 생각합니다.😁
다행히 NamedParameterJdbcTemplate을 통해서 해당 IN쿼리의 parameter를 Map으로 넘겨서 해결해줄 수 있었습니다. 처음에는 위와 같이 deprecated되는 메소드를 활용하는 DAO Class에서 NamedParameterJdbcTemplate만 추가하여 해결하려고 하였는데요..일관성을 위해 모든 DAO에서 이를 사용하도록 수정하였습니다.🙂
요금 정책이 복잡해질수록 상수가 많아지겠네요. 상수 대신 enum을 써보면 어떨까요?
private static final int BASIC_FARE = 1250;
private static final int ADDITIONAL_FARE = 100;
private static final int SECOND_ADDITIONAL_FARE = 800;
private static final int BASIC_DISTANCE = 10;
private static final int SURCHARGE_BOUNDARY = 50;
private static final int FIRST_CHARGING_UNIT = 5;A. Age를 분리했던 것과 같이 distance에 대한 부분도 열거형으로 분리해낼 수 있을 것이라고 생각하여 분리하였습니다.
또한 Distance열거형에서 거리에 따른 요금을 계산하도록 구현하였습니다.
Fare에서는 Distance를 이용하여 거리에 따른 요금 계산 금액을 가지고 노선에 따른 추가 요금을 더해주고(extraFare), Age에 따른 할인을 진행하도록 해주도록 하였습니다!!
public enum Distance {
BASIC(distance -> distance <= 10, 0, 0),
NORMAL(distance -> 10 < distance && distance <= 50, 5, 0),
FAR(distance -> 50 <= distance, 8, 800);
...
}int가 아닌 Integer를 써야 하는 이유가 있나요?
private final Integer distance;A. 생성시에 distance가 null이 될 수 있는 경우가 없으므로 primitive type을 사용하는게 적절하다고 생각합니다. 특히 distance만 Wrapper 클래스이고, 다른 필드는 모두 primitive type인데, 함께 연산에서 많이 사용되기 때문에 인지하지 못하는 오토 박싱과 언박싱이 이루어질 것 같다는 생각을 합니다.😅 수정하도록 하겠습니다!
null을 반환하지 마세요.
클라이언트는 null에 대한 처리를 해야 되서 코드 복잡도를 높입니다.
.orElse(null);A. 내용은 숙지하고 있었는데..Sections 작성하면서 제대로 지키지 못했었네요..반성합니다...
삭제하려는 역 기준으로 previousSection의 존재유무, laterSection의 존재유무에 따라서 구간을 제거해주고 있어 Optional<Section>으로 바로 반환 받았을 때, removeFirstOrLastSection 와 removeMiddleSection에 Optional을 파라미터로 넘기는 문제가 있었고, 참고 글 을 참고하여 Optional을 받아 method의 parameter로 넘기지 않고, boolean값으로 반환을 받고, stationId를 넘기도록 하여 null을 제거하였습니다.😁
private boolean hasPreviousSection(Station station) {
return sections.stream()
.anyMatch(section -> section.isSameDownStation(station));
}
private boolean hasLaterSection(Station station) {
return sections.stream()
.anyMatch(section -> section.isSameUpStation(station));
}왜 스프링 빈으로 만드셨나요?
@Component
public class JgraphtPathGenerator implements PathGenerator {
...
}A. PathServece 의 findPath 메소드에서 JgraphtPathGenerator가 Path 생성을 위해서 필요하였고, 그 때마다 new를 통해 생성하여야 했습니다. 해당 메소드가 호출될 때마다 객체를 생성하기 보다는 빈으로 등록하여 singleton으로 관리하는게 요청마다 객체를 생성하는 것보다 좋다고 생각되어 빈으로 만들었습니다..!
문제 없을까요?
@Component
public class JgraphtPathGenerator implements PathGenerator {
private final WeightedMultigraph<Long, SectionEdge> graph;A. 싱글톤으로 관리되는 빈이 상태를 가지기 때문에 적절하지 못하다고 생각합니다! generatePath() 메소드 호출 시 생성하도록 수정하였습니다😅
@Component
public class JgraphtPathGenerator implements PathGenerator {
public JgraphtPathGenerator() {
}
@Override
public Path generatePath(List<Section> sections, Station sourceStation, Station targetStation) {
final WeightedMultigraph<Station, SectionEdge> graph = new WeightedMultigraph<>(SectionEdge.class);
addVertexes(graph, getStationIds(sections));
addEdges(graph, sections);
final DijkstraShortestPath<Station, SectionEdge> dijkstraShortestPath = new DijkstraShortestPath<>(graph);
final GraphPath<Station, SectionEdge> path = dijkstraShortestPath.getPath(sourceStation, targetStation);
return new Path(getShortestPath(path), getShortestPathWeight(path), getShortestEdge(path));
}Long 타입이 뭘 의미하는건가요? Section 클래스에 Line, Station의 아이디가 아닌 객체를 연결하도록 개선해보세요.
public class Path {
private final List<Long> shortestPath;A. 필드로 객체를 가지도록 수정해보았습니다.
확실히 질문주셔던 것과 같이 Long 타입을 사용하는 것이 아닌 직접 객체를 참조하기 때문에 의미를 파악하기 훨씬 수월해짐을 느꼈습니다. 또한 의미가 불분명한 id(Long) 만을 사용할 때와 달리 직접 객체를 사용하니 변수명 이외에도 의미를 파악할 수 있었고, 특히 테스트 코드에서 이전에 1L, 2L 을 사용할 때에 비해서 객체를 사용하니 "역을 삭제한다", "구간을 등록한다" 등 테스트 코드에 의미가 부여되어 확실히 하나의 문서 역할을 할 수 있게 된 것 같아 좋았습니다...!!
하지만 이번 수정을 진행하면서 굉장히 많은 부분을 수정해야하는 불편함이 느꼈습니다. 이래서 변경에 유연한 코드를 작성하려고 노력하는 것 같습니다.😅 (처음에 어떻게 설계할지 결정하는 것이 얼마나 중요한지도 느낄 수 있었던 것 같습니다..) 많은 교훈을 느끼는 리팩토링이었습니다..!🙂
