레벨로그는 해당 레벨 동안 배운 내용에 대해서 크루 및 코치분들로부터 질문을 받고, 거기에 대한 답변을 하는 말하기 방식으로 20분의 질의응답 시간을 가지고, 10분간의 피드백 시간을 가진다.
이러한 과정을 통해서 본인의 메타인지를 돕는다.
레벨4 시작 이틀 후인 9월 1일 날 레벨3 팀프로젝트 기간동안 내가 배우고, 학습한 내용에 대해서 인터뷰를 진행하였다.
개인적으로 이번 인터뷰가 실제 기술면접과 가장 유사하지 않을까? 하는 생각이 들었으며, 아직 한 번도 회사 기술 면접에 대한 경험이 없는 나에게 있어 앞으로 어떻게 면접을 준비해야할지 갈피를 잡는데 의미있는 경험이 되지 않았나 하는 생각이 든다.
레벨로그 작성
동적 쿼리 작성하기
Querydsl 사용 이유
지금까지 미션하면서는 쿼리가 조건에 따라 동적으로 변화하는 것이 아니라 고정된 정적인 쿼리를 날리는 경우 밖에 접해보지 못했다.
그래서 조건에 따라서 쿼리문 자체가 변경되어야 하는 동적 쿼리를 어떻게 잘 작성할 수 있을까 고민하는 과정에서 Querydsl을 알게 되었고, BooleanExpression을 이용해서 조건이 없는 경우 해당 BooleanExpression 을 이용하여 where절에 조건을 생성하지 않는 Querydsl을 알게 되었고, 이렇게 되면 많은 분기문이 필요 없을 것이라고 기대하여 querydsl을 사용해보았습니다.
Querydsl 준비
querydsl은 @Entity가 붙은 클래스들을 탐색하고 JPAAnnotationProcessor를 사용해 Q클래스 라는 것을 생성한다.
따라서 Study, StudyTag, Tag 라고 하는 도메인 클래스를 만들고 @Entity 어노테이션을 붙여 해당 클래스를 JPA가 관리하도록 등록해주었다.
그리고 우리는 이 Q클래스라는 것을 통해서 쿼리문을 작성하게 된다. 이와 관련된 querydsl 의존성 설정을 해주었고, 생성된 Q클래스를 어디에 저장할지에 대한 디렉토리 위치도 지정해주었다.
Querydsl로 쿼리 작성
우선 제목과 카테고리별 태그를 통해서 조회해오는 과정을 간단하게 설명드리면 우선 querydsl의 경우 where절에 나열하는 BooleanExpression 사이에는 AND 조건으로 where절이 처리되게 됩니다. 따라서 스터디 제목으로 검색하는 부분은 별도의 메소드로 우선적으로 작성해주었고, 카테고리별 태그는 가장먼저 카테고리별로 태그를 분리하고 분리된 카테고리들을 돌면서 각 카테고리 안에서 OR 조건으로 동일한 tag를 가지는 스터디들을 찾고 이를 LIst에 저장해두었습니다. 이 때, 쿼리가 한 번 동작하게 됩니다. 그리고 카테고리를 돌면서 일치하지 않는 원소가 있으면 삭제해나가는식으로 카테고리 사이에서의 AND 조건을 유지해주었습니다.
그런데, 이와 같은 과저에서 카테고리별로 쿼리가 한 번 나가기 때문에 전체 쿼리 수를 계산해보면, 카테고리수가 n개라 할 때 총 n+1 개의 쿼리가 나가는 것을 확인할 수 있었습니다.
Querydsl 을 사용하며 느낀점
우선 장점은 앞서 처음에 querydsl을 적용한 동기와 같이 BooleanExpression을 사용하고, 없으면 해당 조건을 무시하기 때문에 분기문 자체가 필요하지 않았다는 점이 가장 큰 장점이었습니다. 그런데 뿐만 아니라 querydsl의 타입 안정성, 즉 쿼리를 문자열로 작성하는 것이 아니라 자바 코드로, 즉 Q클래스로 작성함으로써 컴파일 시점에 에러를 방지할 수 있다는 장점을 얻을 수 있었습니다. 또한 단순히 문자열을 쭉 써내려가는 것에 비해서 가독성이 좋다는 것을 알 수 있었습니다.
하지만 이번에 querydsl을 적용하고 보니 하나의 쿼리를 날리는데에 100줄이 넘는 코드를 작성해야하는 문제가 있었습니다. 물론 querydsl과 별개로 본인이 쿼리를 조금 더 단순하게 날리지 못해서 발생한 문제였겠다는 생각도 하고 있습니다. 왜냐하면 해당 코드를 순수 SQL 로 변경해서 동적 쿼리를 날리도록 구성해보았는데, 이 때에도 비슷한 양의 코드가 필요했습니다. 따라서 이는 querydsl의 단점은 아닌 것 같습니다.
또한 프로젝트 초반이어서 들었던 비용이라고는 생각하지만 패키지 구조 변경 등에 의해 매번 querydsl을 새롭게 빌드해주어야하는 문제도 있었습니다. (또는 새로운 도메인 추가)
마지막으로 가장 큰 문제점이라고 느낀 것은 다대다 관계에서 중간에 생기는 연관관계 객체였습니다.
DB 테이블과 JPA Entity 매핑 방식에 대한 고민
고민이 들었던 이유
저희가 JPA를 사용한 이유는 ORM 때문이었다고 생각합니다. 말 그대로 객체는 객체대로 설계하고, 테이블은 테이블대로 설계를 해서 이 사이를 매핑하는 용도였다고 생각합니다. 그런데 Study 와 Member 사이 다대다 관계를 일대다, 다대일로 풀기 위해 생긴 StudyMember 클래스, 그리고 Study와 Tag 사이의 다대다 관계를 마찬가지로 풀기 위해 생긴 StudyTag 클래스 들을 보며 이것이 과연 객체지향적으로 설계하고 있는걸까? 단순히 DB 구조가 study, study_member, member 구조 이기 때문에 객체 구조도 테이블을 따라 설계한 것 아닐까? 라는 생각이 들어 고민을 시작했었습니다.
문제점
문제점 또한 존재했습니다. 가장 먼저 스터디와 멤버 사이에 다대다 관계가 생긴 이유는 스터디와 참여자 라는 개념이었습니다. 따라서 이와 관련된 비즈니스 로직을 Study 쪽에서 처리해주고 싶었습니다. 하지만 주요 비즈니스 로직을 StudyMember에서 처리해주고 있었습니다.
그래서 주요 비즈니스 로직을 Study 쪽으로 두면서 동시에 StudyMember 라는 객체를 제거하고 Participant 라고 하는 객체를 두고 싶어졌습니다.
그런데 Study 와 Participant관계는 일대다 관계이고 단방향이기 때문에 생기는 문제점이 있었습니다.
일대다 단방향 관계를 풀 때 우선 @JoinColumn 을 명시하지 않으면 JPA에서 연결 테이블을 중간에 두고 연관관계를 관리하는 조인 테이블을 생성하는 문제가 있습니다.
그래서 @JoinColumn 을 사용할 수 있는데요, 다른 테이블, 즉 Participant 쪽에 memberId 가 있기 때문에 연관관계를 처리하기 위한 UPDATE 쿼리가 추가적으로 필요하다는 문제점이 있었습니다.
또한 처음에 StudyMember 에 데이터를 넣을 때 현재 어느 study에 속하지는 모르기 때문에 null값이 들어가게 되는데, 이 또한 문제가 발생할 수도 있지 않을까하는 막연한 불안감도 있었습니다.
그래서 저희는 값 타입 컬력션을 이용해서 해당 문제를 해결해보았습니다.
CollectionTable에 study_member 테이블을 지정해주고, Participant 에 대한 List를 가지도록 하는 것입니다. 하지만 이렇게 해서 생기는 Embeddable 한 클래스는 PK를 가질 수 없습니다. 따라서 Long타입 값, 즉 memberId를 가지는 클래스를 두었습니다.
이렇게 되면 Study 쪽 생명주기에 Participant가 묶이게 되고, 새롭게 추가되는 참여자는 Study의 상태가 변경된 것으로 판단하여 적절한 update 쿼리가 날아가게 됩니다.
하지만 여기서 또 생기는 문제는 값 타입 컬렉션에 변경 사항이 발생하면 값 타입 컬렉션이 매핑된 테이블의 연관된 모든 데이터를 삭제하고, 현재 값 타입 컬렉션 객체에 있는 모든 값을 DB에 다시 저장한다는 것입니다. 왜냐하면 값 타입 컬렉션에 보관된 값은 다른 테이블에 저장되어 있고, 여기에 변경이 발생하면 원본 데이터를 찾을 수 없기 때문입니다.
그래서 구체적인 이유는 기억이 잘 나지 않는데, nullable 과 함께 Set 자료구조를 활용함으로써 해당 문제는 해결해줄 수 있었습니다.
Jenkins 없이 CI/CD 환경 구성
이렇게 한 이유
우리팀은 Jenkins를 사용하지 않고, Github Actions와 파이썬 소켓 프로그램을 간단하게 작성하여 CI/CD 환경을 구축하였다.
우리팀원 모두 Jenkins에 대한 경험이 없었고, 스프린트 1에 생각보다 우리가 제공하려는 우리 서비스의 가치를 많이 드러내지 못해 이번에는 기능 구현에 집중하자는 의견이었다. 따라서 Jenkins를 학습하고 이를 적용하는데 많은 비용을 투자하지 못하는 상황이었다.
구성 내용
따라서 우리는 develop 브랜치로 push할 때 Github Actions를 위한 workflow의 job에서 우리 서버의 URL 과 8081 포트 번호로 curl 요청을 보내도록 하였습니다.
이렇게 되면 develop 브랜치로 push 될 때, 우리 인스턴스로 curl 요청을 보내게 됩니다. 그리고 우리 인스턴스에서는 curl 요청을 8081포트로 요청을 받게 되고 해당 요청이 GET 요청이면서 우리가 설정한 경로로 요청이 오는 경우 ./deploy.sh 쉘 프로그램을 수행하도록 하였습니다.
결론적으로 우리는 GithubActions와 백그라운드로 돌고 있는 파이썬 소켓 프로그램 그리고 쉘 스크립트를 통해서 CI/CD 환경을 구축하였습니다.
물론 이렇게 구성하는 것이 완벽한 것은 아닙니다. 물론 GET 요청으로 제한해두고, 저희가 지정한 포트 그리고 경로로 오는 요청만 받도록 구성했지만 의도적으로 이를 알아내서 계속해서 요청을 보내 서버를 다운시킬 수도 있습니다.
하지만 이를 보완하기 위해 Authorizatio 헤더를 추가한 요청만 받도록 구성할 수도 있고, 경로를 단순하게 deploy와 같이 구성하는 것이 아니라 저희가 암호화한 값을 사용하도록 설정해놓을 수도 있을 것입니다.
(실질적으로 저희는 공격자가 없기 때문에 이를 지금 바로 도입해야한다는 필요성을 크게는 못느껴서 위와같이 구성해두지는 않은 상태입니다.)
단점
여기서 느낀 단점 또한 있었는데요, Jenkins를 사용하면 빌드에 대한 모니터링이 가능한 것으로 알고 있습니다. 하지만 저희가 구성한 CD 환경은 GithubActions 가 돌아갔던 history를 통해서 서버가 요청을 받았는지 유무는 확인할 수 있지만, 실질적으로 쉘 프로그램까지 정상적으로 돌아갔는지는 확인할 수 없다는 것입니다.
Swagger vs Spring Rest Docs
저는 Swagger 를 사용하고 싶었습니다. Swagger의 단점으로 많이 언급되는 것이 프로덕션 코드에 Swagger 관련 설정 코드가 필요하다는 것이었습니다. 하지만 프로덕션 코드에 퍼지게 되는 ApiOperation과 같은 어노테이션을 사용하지 않고, 최소한의 Swagger 설정만 Config파일로 가지게 되면 나중에 문서화와 관련된 정책이 변경되게 되면 해당 파일 하나만 제거해주면 되기 때문에 괜찮을 것 같다고 판단하였습니다.
그리고 Spring Rest Docs 를 사용해보지 않아서 이런 생각을 한 것이지만 실제 비즈니스 로직을 테스트하는 테스트와 별도로 문서 작성을 위한 테스트가 필요하다고 생각하였습니다. 그리고 이렇게 되면 테스트가 통과해야 문서가 만들어진다라고 하는 것의 장점이 무색해지지 않나 하는 생각이 있었기 때문입니다.
그런데 실제로 인수테스트에서 활용하고 있는 RestAssured의 filter 메소드를 활용해서 문서화가 가능하다는 것을 직접 사용하면서 느낄 수 있었고, 이렇게 되면 실제로 사용자 시나리오에 관한 테스트가 통과할 때 문서화가 되므로 앞서 언급한 장점을 누릴 수 있게 된다는 것을 알 수 있었습니다.
하지만 단점도 있었습니다. 화면에 출력하기 위한 index.adoc 파일을 신경써서 API 가 추가될 때마다 수정해주어야한다는 것이 조금은 번거롭게 느껴지기도 했으며, 실제로 누락하는 경우도 있었습니다.
이외에도 HTTPS, JPA Auditing, Spring Scheduler, Refresh Token, 테스트 코드 리팩 토링 경험을 작성하였다.
더 자세한 내용은 다음 노션 링크를 통해서 확인할 수 있다.
레벨 회고 (레벨3) - BE 4기 디우
질문 내용
첫 질문부터 말리고 들어가서 시간이 어떻게 흘러가는지, 내가 어떻게 답변하고 있는지 모르게 시간이 지나갔다.
(옵저버로서 나의 인터뷰에 대한 피드백을 주면서 동시에 내가 받은 질문을 정리해준 쿤 에게 고마움을 표한다.)
질문은 대부분 구구 코치님께서 질문을 해주셨다. 인증&인가 그리고 엔티티와 DB 테이블 매핑 이외에는 모두 구구 코치가 질문해주셨고, 앞선 2개의 질문에 대해서도 첫 질문 이후 꼬리 질문은 모두 구구 코치가 질문해주셨다.
확실히 질문의 깊이(?)가 다르다는 것을 느꼈다.
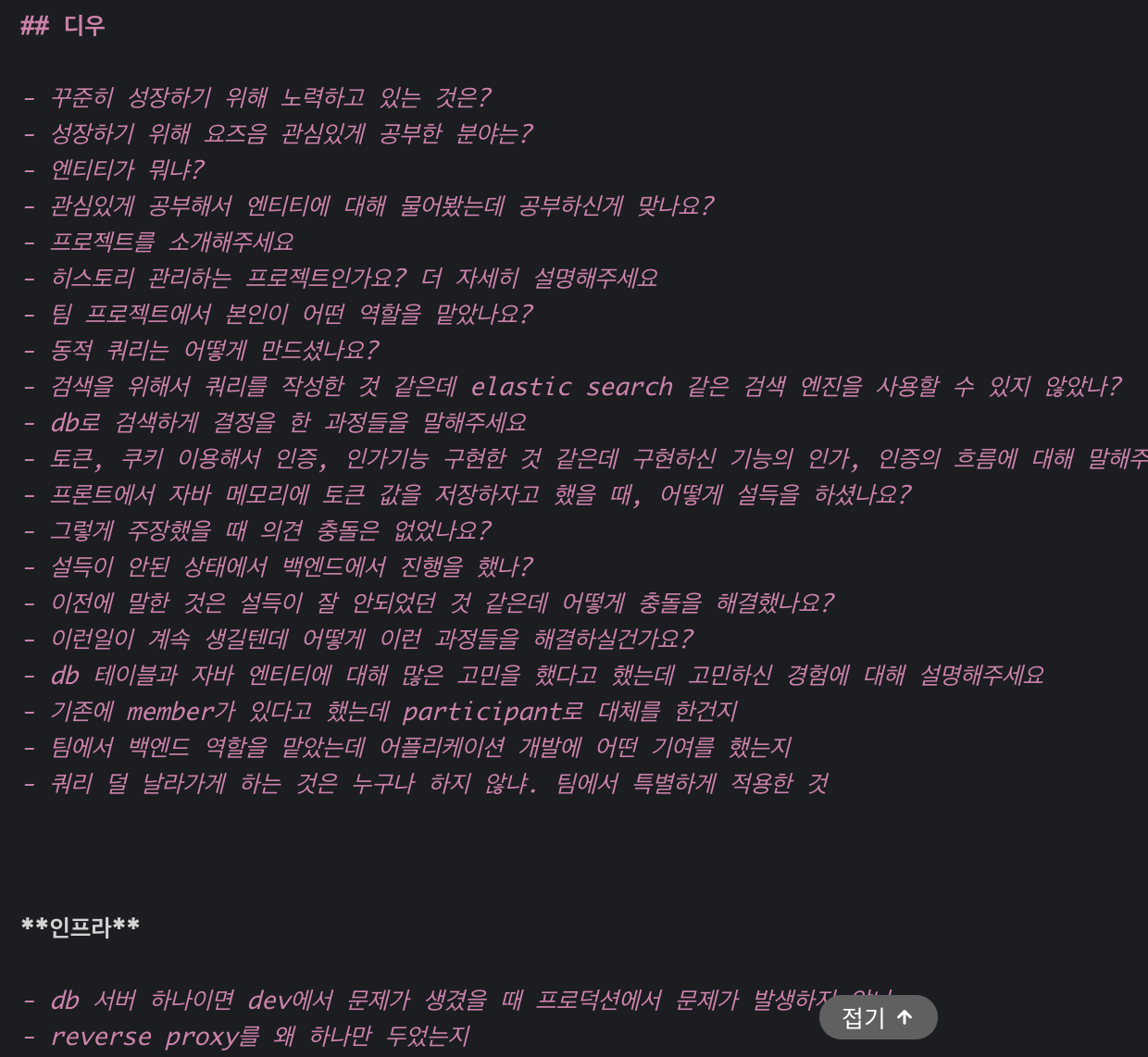
간단하게 각 질문을 받았을 때의 나의 생각이나 다시 질문을 받으면 이렇게 답변할 수 있을 것 같다. 혹은 앞으로는 이렇게 답변하도록 해야겠다 라는 생각들 혹은 반성이 담긴 나의 마음가짐을 몇몇 질문에 대해서 기록해두려고 한다.
Q. 자기소개 간단하게 해주세요.
한 번도 나의 소개에 대해서 고민해본 적이 없는 것 같다. 그래서 첫 질문부터 당황했다.
이전에 유튜브에서 본 것으로 기억하는데, 일본의 한 소설가가 정해진 시간동안만 글을 쓰고 이외에는 글쓰기에 대해서 고민하거나 이로 인해 스트레스 받지 않음으로써 꾸준하게 글을 쓸 수 있었다는 이야기를 들은 적이 있다.
위 이야기를 듣고 나서, 나도 개발자로서 살아가면서 매일매일 너무 개발에만 시간을 투자하거나 개발을 하고 있지 않을때도 이에 대해서 고민하고 생각하면서 스트레스 받음으로써 쉽게 번아웃이 오는 개발자가 아닌 꾸준하게 성장해 나갈 수 있는 개발자가 되어야겠다는 생각을 한 적이 있었다.
따라서 이와같이 답변하였다.
하지만, 정작 이렇게 하기 위해서 내가 특별하게 노력하고 있는 것은 없었고, 이어지는 질문에 대해서도 제대로된 답변을 하지 못했다.
Q. 꾸준히 성장하기 위해 노력하고 있는 것은?
Q. 성장하기 위해 요즘 관심있게 공부한 분야는?
DB 테이블과 엔티티간의 매핑에 대해서 많은 고민을 하였다고 답변하였다. 실제로도 해당 부분에 대해서 팀원들과도 가장 많은 시간을 들이면서 고민하고 본인의 생각을 정리하는 시간을 가졌기 때문이다. 하지만 정작 엔티티가 무엇인지에 대해서는 제대로 개념을 정리하지 못했었고, 이어지는 질문에 대해서 제대로된 답변을 하지 못했다.
Q. 엔티티가 무엇인가요?
Q. 관심있게 공부해서 엔티티에 대해 물어봤는데 제대로 공부하신게 맞나요?
Q. 프로젝트를 소개해주세요.
Q. 히스토리 관리하는 프로젝트인가요? 더 자세히 설명해주세요.
Q. 팀 프로젝트에서 본인이 어떤 역할을 맡았나요?
이 질문을 받았을 때에도 제대로 답변을 하지 못했다. 차라리 질문이 '팀 프로젝트에서 어떤 기능을 구현하셧나요?' 와 같았다면 내가 구현한 기능에 대해서 제대로 답변할 수 있었을 것 같다. '역할'이라고 하니 내가 팀 프로젝트에서 특별하게 무엇인가 한 것을 묻는 것 같은 느낌을 받았다.
실제로 우리팀에서는 '사용자 스토리' 기반으로 기능을 구현해나갔고, 이 때 해당 스토리와 관련해서는 DB 설계나 객체 설계 및 구현을 모두 도맡아하였다. 즉, 팀원 모두가 골고루 섞여서 개발하였기 때문에 처음에는 해당 질문에 대해서 제대로 답변을 하지 못했다. 하지만 나중에 다시 어떤 부분을 구현하였는가? 되물어주셔서 제대로 된 답변을 할 수 있었다.
Q. 동적 쿼리는 어떻게 만드셨나요?
Q. 검색을 위해서 쿼리를 작성한 것 같은데 elastic search 같은 검색 엔진을 사용할 수 있지 않았나요?
Elastic Search 에 대해서 처음 들어서 또 당황했다. 굉장히 압박감이 드는 질문들이 이어졌다고 생각한다. 실제로 인터뷰 이후 구구 코치님께서 신입이 Elastic Search 를 아는 것은 말이 안된다고 일부로 압박 질문을 하셨다고 말씀해주셨다.
Q. DB로 검색하게 결정을 한 과정들을 말해주세요.
Q. 토큰, 쿠키 이용해서 인증과 인가기능을 구현한 것 같은데 구현하신 기능의 인가&인증의 흐름에 대해 말해주세요.
Q. 프론트에서 메모리에 토큰 값을 저장하자고 했을 때, 어떻게 설득을 하셨나요?
Q. 그렇게 주장했을 때 의견 충돌은 없었나요?
Q. 설득이 안 된 상태에서 백엔드에서 진행을 한 것인가요?
Q. 이전에 말한 것은 설득이 잘 안되었던 것 같은데 어떻게 충돌을 해결했나요?
Q. 이런일이 계속 생길텐데 어떻게 이런 과정들을 해결하실건가요?
앞선 질문 5개가 모두 인증 인가 방식을 구현하면서 프런트와 백엔드에서 의견 충돌이 있었고, 이를 어떻게 해결했는가에 대한 질문이다. 해당 과정을 우리는 쿠키에 저장하는 방식으로 의견 충돌을 해결하였다.
즉, 프론트에서 원하는 보안적인 측면과 백엔드에서 원하는 Access와 Refresh 모토큰 모두를 이용한 refresh 요청 처리 두 측면을 모두 가져갈 수 있는 방법이었기 때문이다.
즉, A와 B가 있을 때 A를 선택한 이유와 B를 선택한 이유 모두를 해결해줄 수 있는 방법이었기 때문이다. 즉, 제 3안 방안이 답이 된 케이스였다.
하지만 인터뷰에서는 이러한 내용이 잘 전달되지 않았고, 그래서 계속해서 꼬리질문이 이어졌다고 생각한다.
Q. DB 테이블과 자바 엔티티에 대해 많은 고민을 했다고 했는데 고민하신 경험에 대해 설명해주세요.
Q. 기존에 member 가 있다고 했는데 participant로 대체를 한건가요?
Q. 팀에서 백엔드 역할을 맡았는데 애플리케이션 개발에 어떤 기여를 하셨나요?
Q. 쿼리 최적화는 백엔드 개발자라면 누구나 다 하는 작업이라고 생각합니다. 팀에서 특별하게 적용한 것이 있을까요?
이후에는 팀 프로젝트를 하며 구성한 인프라 구조를 그림으로 그린 이후에 질의응답 시간을 가졌다.
아래 서버쪽 인프라 구조에 더해서 프런트쪽 인프라 구조를 함께 그렸다.
프론트 쪽 인프라 구조에 대해서 정확하게 모르고 있다는 것을 깨달을 수 있었고, 프런트 쪽은 NGINX 를 올린 정적 리소스를 반환하는 서버 한 대로 구성되어 있고 여기서 백엔드 쪽으로 요청을 보내고 있다고 알고 있기 때문에 이러한 부분을 아래 그림에서 더해 그려냈다.
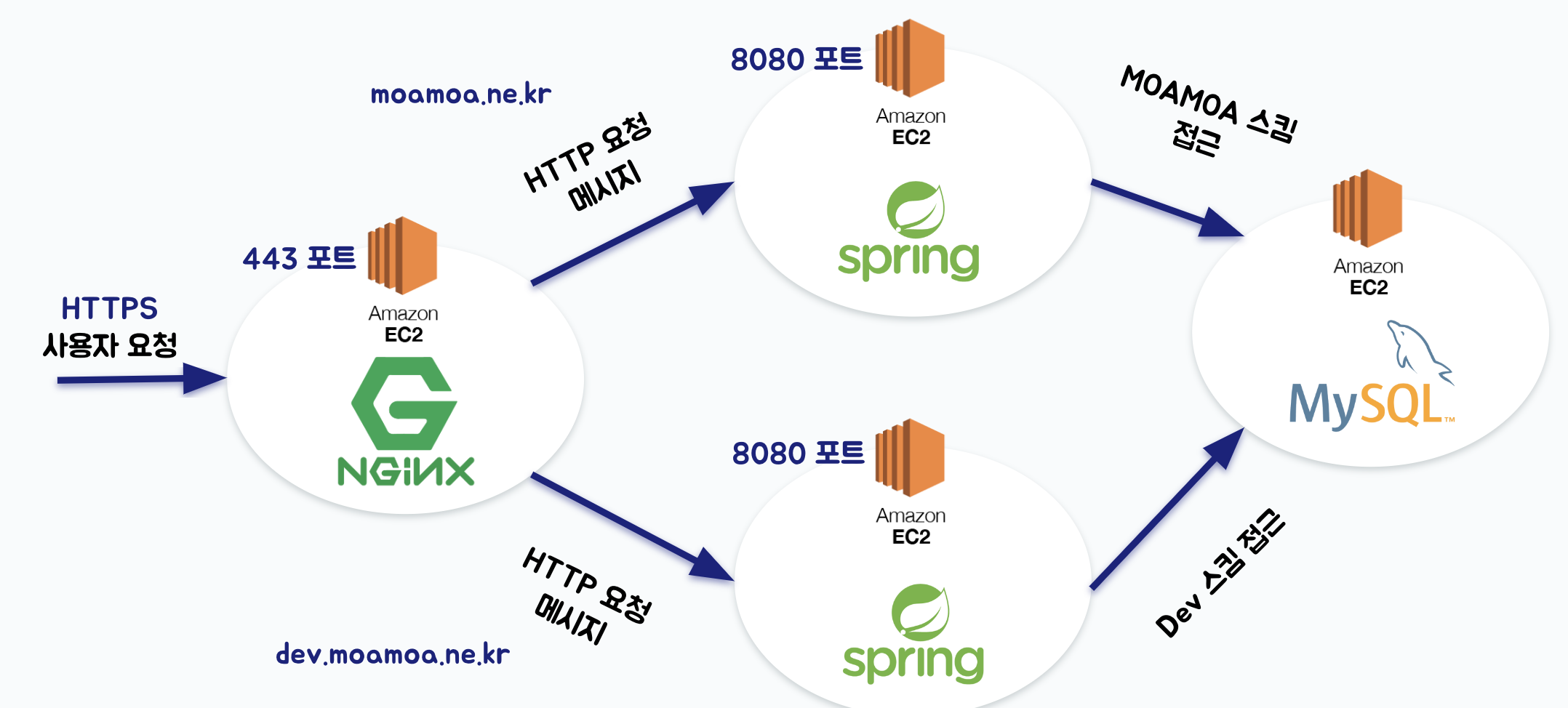
Q. DB 서버가 하나이면 dev에서 문제가 생겼을 때 프로덕션쪽에 문제가 발생할 수 있지 않을까요?
고민해보지 못한 부분이었다. 팀프로젝트를 하면서 내가 놓친 부분은 다른 팀원이 고민해서 의견을 제시하는 등 항상 고민하면서 팀 프로젝트를 진행하고 있다고 생각하고 있었는데, 반성하게 되는 부분이었다. 특히 인프라 구조에 있어서는 큰 고민을 하지 못했던 것 같다. 질문을 받은 내용처럼 실제로 dev쪽에 문제가 있어서 DB가 다운되면 운영 서버에도 영향을 미치게 될 것이고, 이 둘은 분리하는 것이 적절하다.
Q. reverse proxy를 왜 하나만 두었나요?
느낀점 및 피드백
회고
이전 레벨1, 그리고 레벨2 인터뷰에서도 동일한 피드백을 받았던 것으로 기억이 나는데, 답변이 길다는 피드백이다. 따라서 이럴 때는 두괄식으로 말하는 연습을 하면 좋겠다는 피드백을 계속해서 받았었는데 크게 고쳐지지 않았다는 생각이 든다.
그래서 왜 이렇게 답변이 장황해질까? 하는 그 원인에 대해서 고민을 해보았다.
고민을 하고 보니, 레벨로그를 준비하면서 해당 주제들에 대한 답변(?) 을 미리 작성하게 된다. 그리고 실제로 인터뷰 답변을 하면서 레벨로그를 준비하며 작성한 내용을 그대로 답변하려고 한다.
레벨로그를 준비하며 작성한 내용은 굉장히 길고 모든 내용을 포함하고 있다. 그리고 이를 그대로 답변하려다 보니 답변이 굉장히 장황해지는 것이다. 따라서 대충 키워드가 일치한다고 모든 내용을 말하려기 보다는 질문의 요지를 듣고, 그에 대해서만 답변을 하려고 해야 겠다는 생각이 들었다.
또한 코치님께서 프로젝트에 대해서 설명을 할 때 다른 사람들이 우리 서비스를 이미 알고 있다는 전제하에 설명을 이어간다는 느낌을 받았다고 피드백을 주셨는데, 100% 공감하는 내용이다. 특히 DB 테이블과 엔티티 매핑에 대해서 설명을 할 때 이미 우리 서비스의 구조에 대해서 이해하고 있다고 생각을 하고 설명을 이어갔던 것 같다. 이러한 부분들에 있어서 조금 더 쉬운 예제를 들고 설명을 한다든가 하는 방식으로 개선이 필요할 것 같다.
피드백에서의 내용과 마찬가지로 학습적인 측면에서는 어떤 개념이나 정의에 대해서 정리하는 시간이 필요할 것 같다는 생각이 들었고, 특히 이번 레벨3는 팀 프로젝트였고, 찐한 협업이 목표였기 때문에 그 과정에서 느낀점들이나 갈등 상황 들에 대해서 한 번 더 정리가 필요하다고 느낄 수 있었다.
크루 피드백
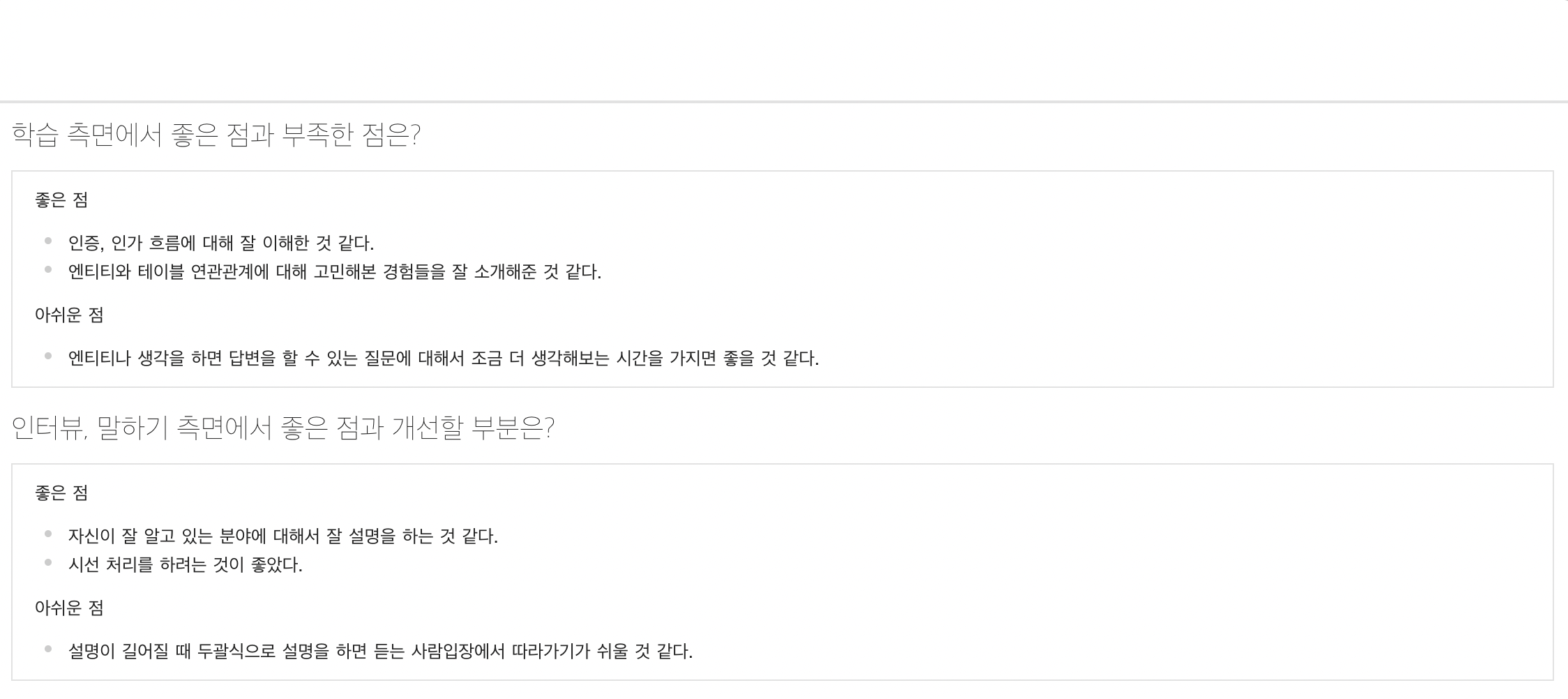
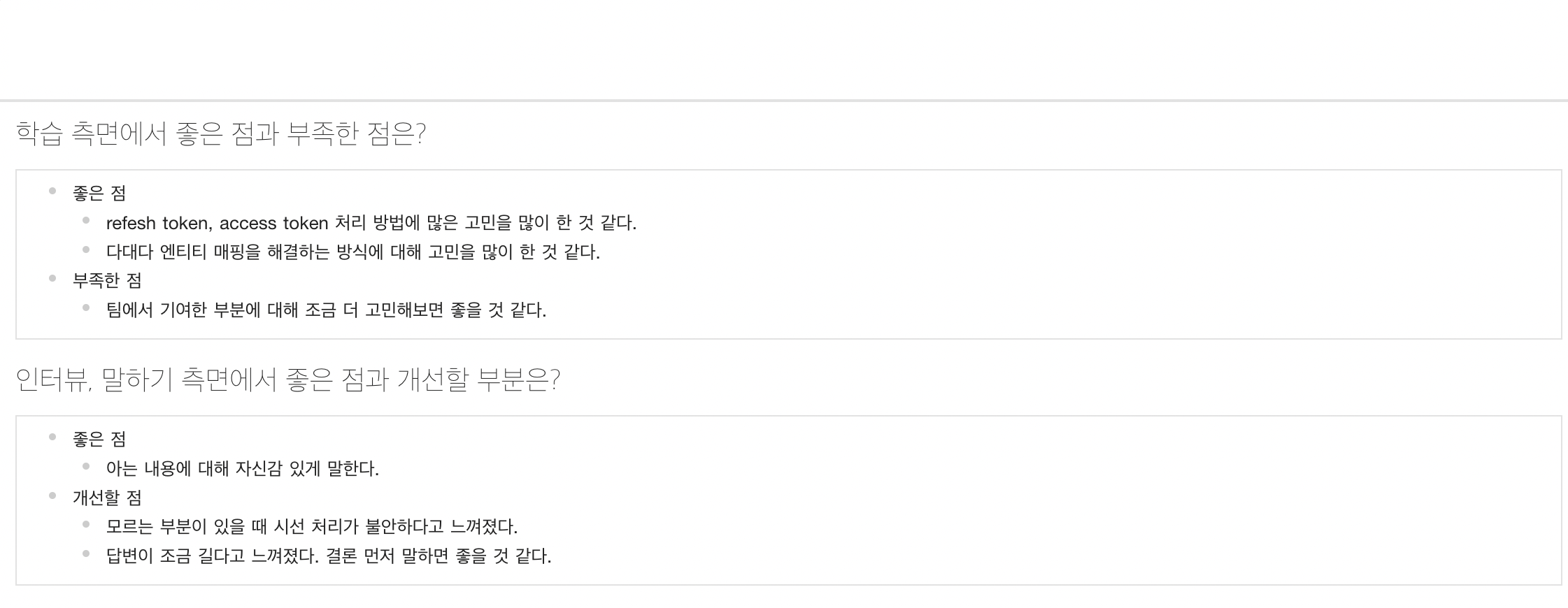
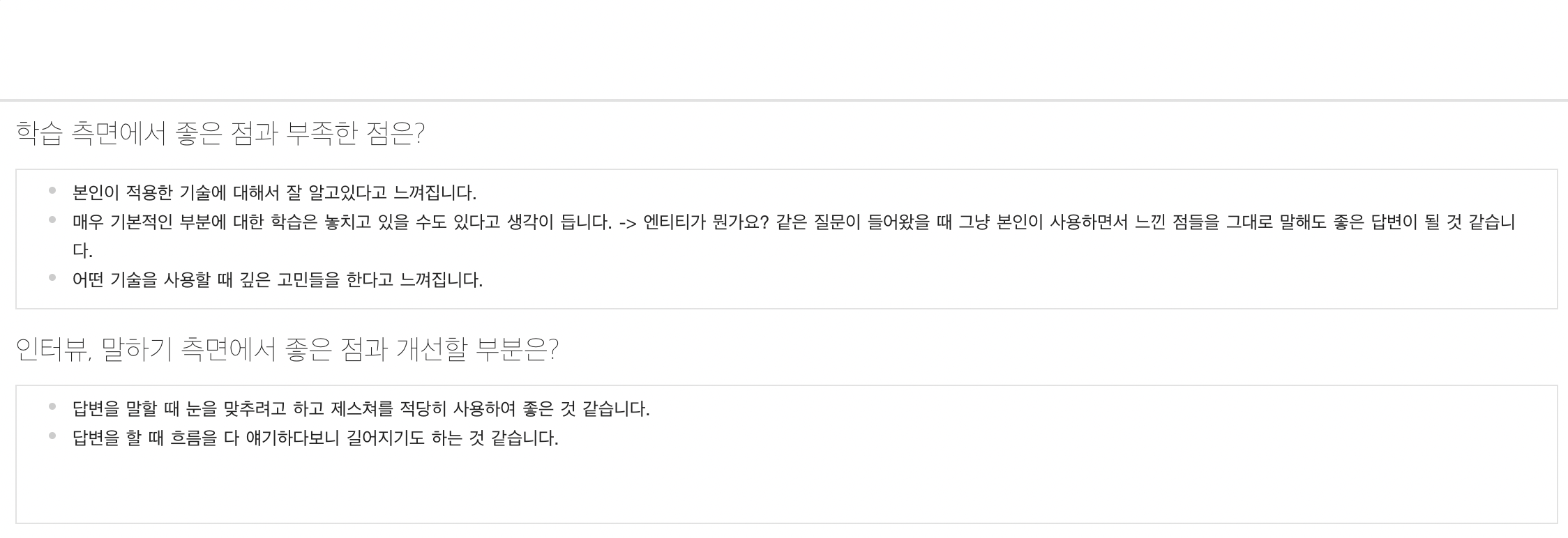
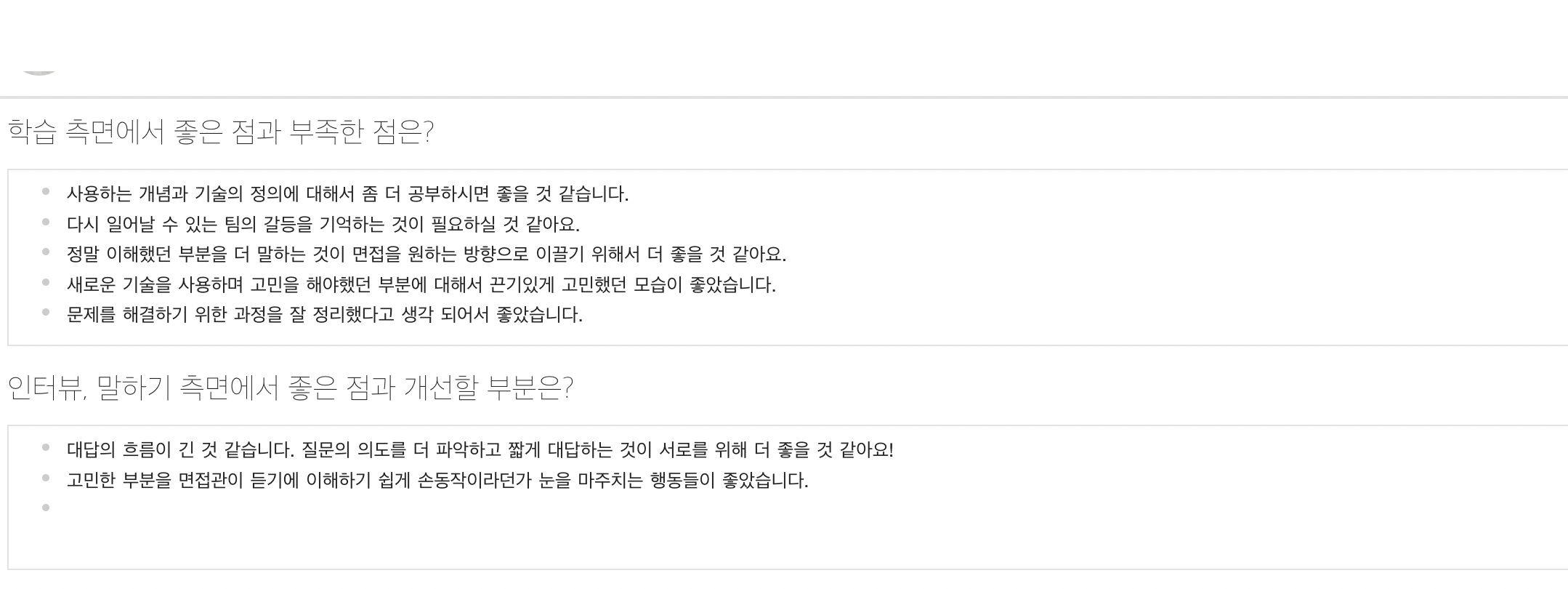
익명 크루 5
팀 프로젝트에서 많은 부분을 고민하고 공부한 것이 느껴진다. 다만, 팀 프로젝트에서 어떤 역할을 맡았는가? 하는 질문을 받았을 때, 특별하게 무언가를 하지 않았더라도 자신감을 가지고 답변을 해도 좋을 것 같다는 생각을 하였습니다. 또한 답변이 길어지다 보니 장황해지는 느낌을 받았고, 두괄식으로 말을 해주었으면 어땠을까? 하는 생각이 들었습니다.
