우아한테크코스를 진행하면서 리팩터링 이라는 말을 굉장히 많이 하고 지내고 있는 것 같다. 심지어는 미션의 한 단계로써 리팩터링 진행하기 와 같은 키워드를 제공하고 있으니 말이다.
그리고 나 또한 리팩터링을 잘 하고 있다고 생각하고 있었다. 하지만 이번에 기존 인증에서 githubId가 아닌 memberId 사용하도록 리팩터링 이라는 이슈를 맡고 해결하는 과정에서 의문이 들게 되었다.
- 하나를 고치면 다른 한쪽이 문제가 되고, 그 문제를 해결하면 다시 다른 곳에서 문제가 발생하는데 리팩터링을
어떻게진행해야 하지? - 나는 이제까지 리팩터링을
어떻게진행하고 있었을까? 어떻게하는 것이 리팩터링을 잘 하는 방법일까?
이번 이슈를 맡으면서 리팩터링을 어떻게 그리고 잘 할 수 있을지에 대한 고민에 빠졌다.
무작정 부딪히면서 하나씩 바꾸려고 하니 테스트가 백몇개씩 깨지고 그 테스트를 통과시키기 위해서는 다시 프로덕션 코드를 고쳐야하고, 변경된 프로덕션에 의해서 다시 테스트가 깨지는 것이 반복되었기 때문이다.
관련된 이슈 및 PR
이슈와 PR 이 두개로 나눠진 이유는 응답을 내려주는 부분을 놓쳐 반영하지 못했기 때문이다...😅
[BE] 기존 인증에서 githubId가 아닌 memberId 사용하도록 리팩터링
[BE] 기존 githubId 사용하던 곳 모두 memberId로 변경
[BE] issue320: 기존 인증에서 githubId 가 아닌 memberId 사용하도록 리팩터링
[BE] issue359: 기존 githubId 사용하던 곳 모두 memberId로 변경
본론으로 넘어가기 이전에 해당 이슈를 발행한 이유를 잠깐 정리하고 가자면 다음과 같다.
우리의 비즈니스 로직에서는 결국 memberId를 통해서 로직을 해결하고 있었지만, 토큰의 payload에 담아서 발생하는 JWT 토큰은 githubId 를 담고 있어 결국 githubId로 memberId를 조회해오는 로직이 추가적으로 필요했다. 하지만 우리의 비즈니스 로직에서 모든 부분을 memberId로 처리하도록 한다면 이와같이 불필요한 DB 조회를 제거할 수 있으므로 리팩터링을 진행하게 되었다.
지금까지의 리팩터링
이 글을 쓰는 시점에서 지금까지의 리팩터링을 어떻게 진행했었는지 되돌아 보았다.
우선 레벨1,2 미션의 경우에는 리뷰어의 리뷰에 기반해서 리팩터링을 진행하였었다. 그리고 리뷰어의 리뷰의 경우 작은 단위로 리뷰를 주시기 때문에 크게 문제되지 않고 리팩터링을 진행해볼 수 있었던 것 같다.
하지만 그럼에도 불구하고 작은 변경이 요구되지만 코드 전체에 걸쳐서 손을 보아야하는 경우도 있었는데, 이러한 경우에는 해당 리뷰를 받고 나서 굉장히 막막한 느낌을 받았었던 것 같다. 심지어는 리팩터링을 진행하다가 너무 많은 코드를 수정해야할 때면 '지금 내가 잘못하고 있는 거 아닌가?' 하고는 다시 롤백을 하고 생각하는 시간을 갖기도 하였다. 하지만 결국 같은 과정을 다시 진행하게 되는 모습을 떠올려볼 수 있다.
그렇다면 비교적 규모가 작았던 미션이 아닌 현재 진행하고 있는 모아모아 프로젝트의 경우에는 어떨까? 비교적 가장 최근에 진행하였던 리팩터링이 있어 관련 PR을 다시 보게 되었다. PR 링크
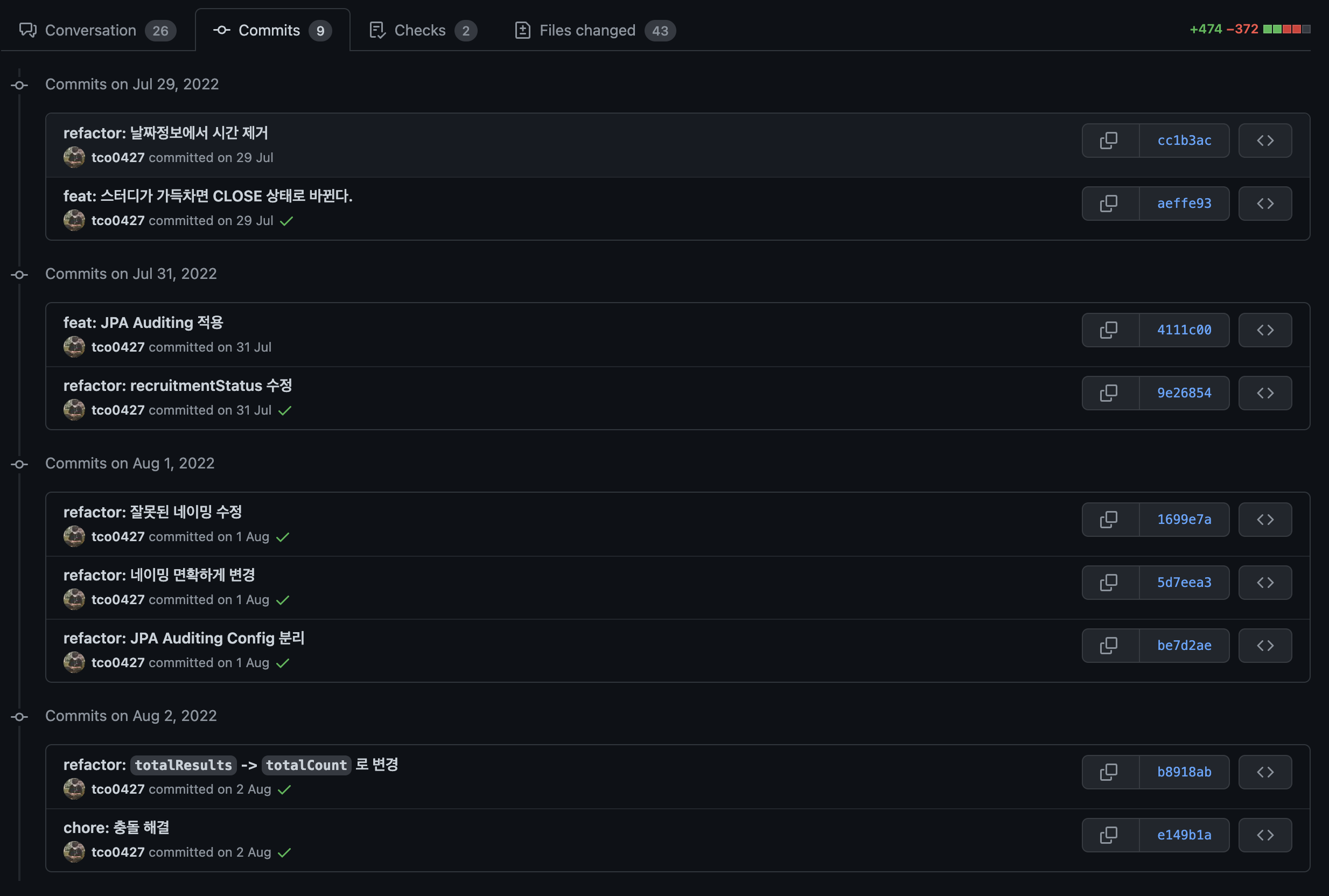
위의 커밋 기록만 보면 점진적으로 리팩터링한 거 아닌가? 하는 생각이 들 수도 있다.
하지만 실질적으로 리팩터링을 진행한 커밋 기록은 feat: 스터디가 가득차면 CLOSE 상태로 바뀐다.과 feat: JPA Auditing 적용 부분이다.
여기서 보이는 날짜정보에서 시간 제거는 테스트코드에서 불필요한 시간 정보를 함께 사용하고 있던 것을 제거해주는 것이었기에 내가 하려고 하는 리팩터링과는 어떻게 보면 무관한 작업이다.

뿐만 아니라 Commits on Aug 1, 2022 이후에 있는 커밋들은 팀원들의 피드백을 반영한 부분으로 어떻게 보면 작업한 내용이라고 볼 수는 없는 사소한 변경 내역들이다.
여기서 JPA Auditing을 적용한 커밋 기록을 보면 아래와 같은 BaseEntity 를 만들고, 모든 코드에서 이를 활용하도록 한 번에 수정하고, 테스트 코드 또한 한 번에 수정해주고 있음을 확인할 수 있다.
@EntityListeners(AuditingEntityListener.class)
@MappedSuperclass
@Getter
public class BaseEntity {
@CreatedDate
@Column(updatable = false, nullable = false)
private Date createdDate;
@LastModifiedDate
@Column(nullable = false)
private Date lastModifiedDate;
}즉, 나의 리팩터링 과정은 새롭게 추가할 기능으로 한 번에 대체하여 프로덕션 코드에 대한 리팩터링을 모두 수행한 이후에 마지막에 테스트가 통과하도록 해주는 과정인 것이다.
이 과정이 리팩터링이 아니라 새로운 기능 구현으로 볼 수도 있을 것 같다. 하지만 요즘 마틴파울러의 리팩터링 1판으로 스터디를 진행하고 있는데, Substitue Algorithm 과 연관해서 생각을 해볼 때 사용자 입장에서는 동일한 기능을 제공받고 있고, 어떻게 보면 createdAt 과 lastModifiedAt 이라는 정보를 "어떻게" 구현할 것인가하는 변경이기 때문에 리팩터링의 일부분으로 볼 수 있다고 생각한다.
이슈에서 겪은 문제
앞선 예시에서 처럼 여차저차해서 한 번의 기능구현을 쭉 이어서 하고 나서 테스트 코드를 통해서 프로덕션 코드가 통과하는지 확인하고, 만약 인터페이스(메소드 시그니쳐)등의 변경으로 인해 테스트 코드도 통과하도록 수정해주어야한다고 하면 이를 수정해주는 과정으로 리팩터링을 성공적으로 수행할 수도 있다. 어떻게 보면 빠르게 기존 코드를 개선하는 방법일 수도 있다.
하지만 만약 프로덕션 코드의 변경 -> 테스트 코드의 수정 -> 프로덕션 코드의 변경 -> 프로덕션 코드의 변경 과 같이 하나의 변경이 서로 다른 많은 변경을 불러일으킨다면 어떻게 할 것인가?
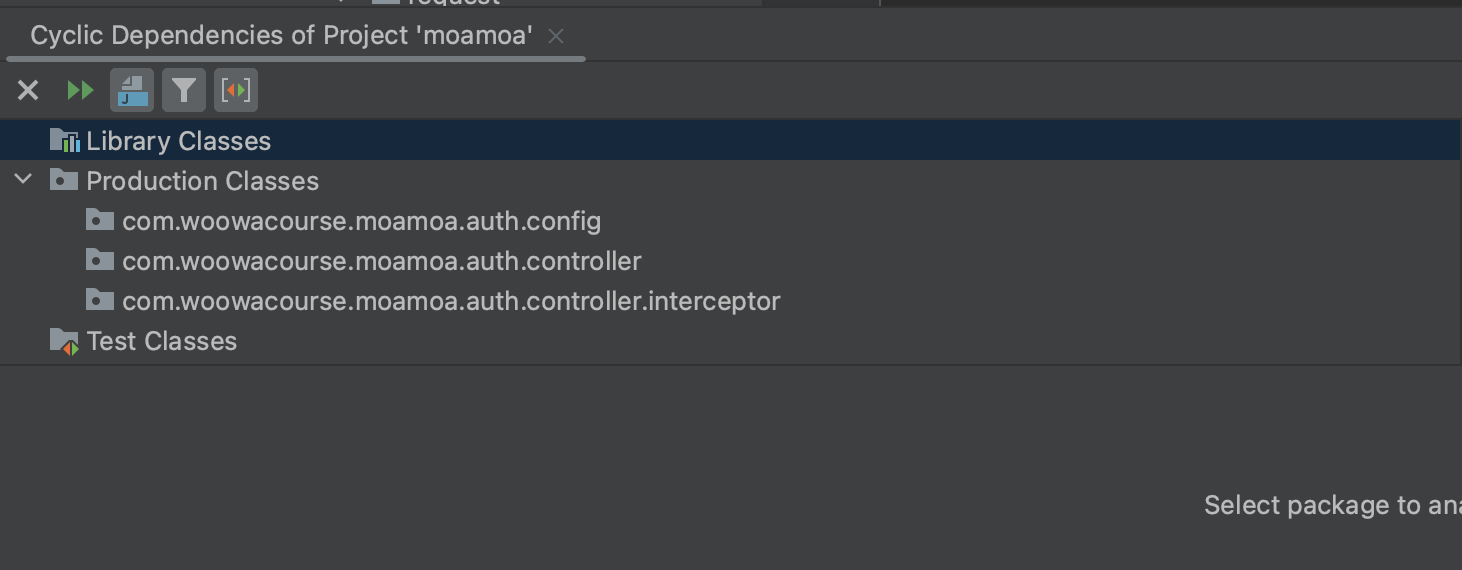
물론 이러한 신호는 리팩터링의 문제가 아니라 구조 개선의 신호일 수도 있다. 어떻게 보면 맞는 말일 수도 있다는 생각이 든다. 왜냐하면 현재 모아모아 프로젝트의 경우, IntelliJ 에서 제공해주는 Cyclic Dependencies 를 보면 com.woowacourse.moamoa.auth 패키지에서 유일하게 순환 구조가 발견되고 있는데, 내가 작업한 부분이 auth쪽 패키지의 변경이 주가 되기 때문이다.
(IntelliJ에서 Code -> Analyze Code -> Cyclic Dependencies 이후 전체 프로젝트를 선택해서 확인해볼 수 있다.)
다시 본론으로 돌아와서 나는 기존의 인증과정에서 githubId를 memberId를 사용할 수 있도록 수정하는 것이었으므로 크게 2가지를 변경해주면 되었다. 우선 토큰의 발급 과정에서 payload에 githubId가 아닌 memberId를 담아서 반환해주도록 구현한다. 그리고 AuthenticatedMemberResolver 에서 githubId를 통해서 memberId 를 가져오던 작업을 제거하고 그대로 토큰의 payload의 담겨있을 memberId를 반환해주도록 구현해주면 되는 것이었다. 그리고 레거시인 AuthenticationArguemntResolver를 제거해주면된다.
(위와 같이 githubId 를 통해서 memberId 를 가져오는 AuthenticatedMemberResolver는 베루스 팀원이 이전에 구현해두었었다.)
그런데 이 두가지를 변경하는 것이 어려웠던 이유는 이전에 내가 하던 방식대로 ArgumentResolver 와 TokenProvider 쪽을 함께 변경하는 경우 테스트 코드의 수정이 쉽지 않았다는 점이다. 심지어는 예를 들어 100개의 테스트가 깨져 95개 정도를 통과시키도록 변경을 마쳤는데, 나머지 5개를 통과시키기 위해서는 프로덕션 코드를 다시금 건드려줘야했고, 이렇게 되면 다시 다른 테스트들이 깨진다는 문제였다. 심지어는 프로덕션 코드를 변경하기도 해야했던 것으로 기억난다. (정확하지는 않다..)
나는 여기서 뭔가 잘못하고 있음을 직감했다. 프로덕션 코드를 잘못 리팩터링했다거나 테스트 코드를 잘못 수정하고 있다고 생각했다. 롤백을 해서 이전 커밋에서 다시 시작해야겠다는 생각과 함께 지금까지 한 것이 너무 아까운데 방법이 있지 않을까? 하는 막연한 생각이 함께 들었다. 하지만 결국 롤백을 할 수 밖에 없었다.
(당시 별도로 기록해두지 않아 어떤 테스트였는지 구체적으로 기억에 남지는 않는다. 다만, 이전에 githubId같은 경우 PK가 아니므로 임의의 값을 줄 수 있었지만, memberId를 사용하므로 PK를 사용하게 되고, 이는 Auth Increment여서 테스트에서 우리가 지정한 1L, 2L 이라는 값이라는 보장이 없다는 점이 한 몫하였었고, Github OAuth 를 통해서 로그인하므로 mocking을 새롭게 해줘야한다는 것 또한 문제였던 것으로 기억한다. 그리고 이러한 변경이 계속해서 발생하므로 리팩터링을 진행하고 있는 나로 하여금 막막함을 느끼게 하였던 것으로 기억한다.)
새롭게 배운 리팩터링 방법
위와 같은 이슈를 겪으며 고통 받고 있는 나를 옆에서 지켜보던 베루스는 나에게 도움을 주었다. 평소에 TDD 와 리팩터링에 관심이 많은 형이었기에 굉장히 도움이 되는 방법을 알려주었다. 생각보다 그 방법은 단순하다고 볼 수 있었는데 작은 단위로 리팩터링을 진행하는 것이었다.
우선 ArgumentResolver와 TokenProvider 쪽을 모두 변경하는 것이 아니라 기존에 AuthenticationPricipal 어노테이션을 통해서 ArgumentResolver를 사용하던 부분을 새롭게 만든 AuthenticatedMember 를 활용하도록 수정을 하고, Service단에서는 기존 githubId가 아닌 그렇게 받은 memberId를 활용하도록 수정하는 것이다. 그렇게 모든 Controller에서 @AuthenticatedMember 를 사용하도록 변경을 마치면 기존의 @AuthenticationPrincipal 을 제거하라는 것이다.
그리고 이 과정도 모든 컨트롤러를 한 번에 다 바꾸는 것이 아니라 ReferenceRoom, Review, Study와 같이 하나씩 갈아끼우는 것이다.
이렇게 ArgumentResolver 쪽 변경을 마친 이후에는 TokenProvider 쪽을 변경하도록 리팩터링을 진행한다. 토큰의 payload에 memberId를 담도록 변경하는 것이다.
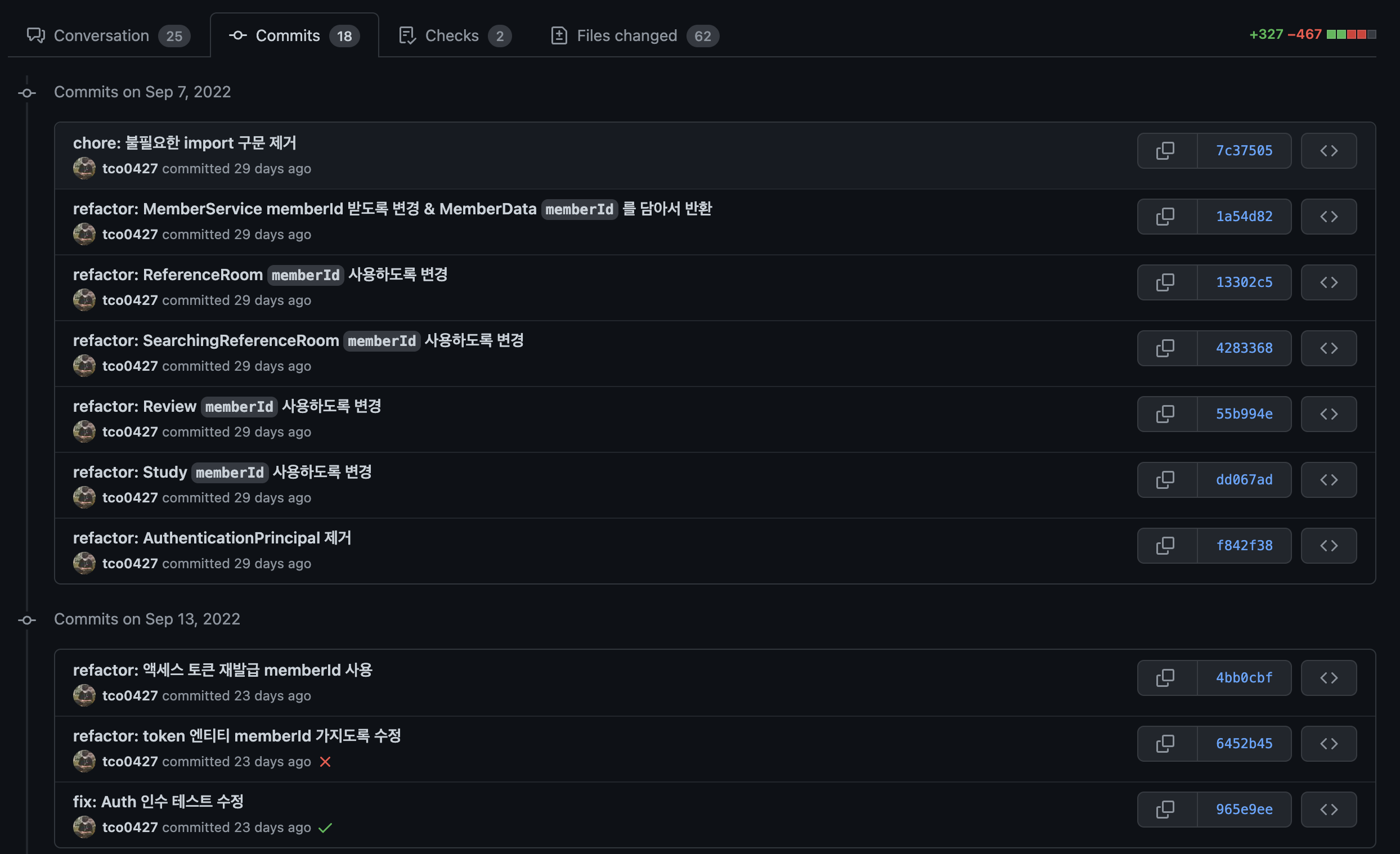
리팩터링 과정은 순조롭게 진행되었고, 결국 원하던대로 다음과 같은 요구사항을 만족시킬 수 있었다.
- AuthenticationPrincipal 어노테이션을 제거하고, AuthenticatedMember 를 사용하도록 한다.
- AuthenticationArgumentResolver 를 제거하고, AuthenticatedMemberResolver 를 사용하도록 한다.
점진적인 리팩터링
점진적인 리팩터링이란 무엇일까? 우선 이전까지 내가 하던 리팩터링 방식은 절대 점진적이라고 할 수 없다. 한 번에 모든 프로덕션 코드를 수정하고, 이후 테스트 코드가 통과하도록 수정을 진행해준다. 심지어 리팩터링 중간 중간에 개선할 코드가 보이면 그 즉시 그 코드를 개선하고 있다. (원래는 개선하려고 했던 부분이 아니었음에도...)
지금에 와서 내가 느낀 점진적인 리팩터링은 우선 작은 단위로 변경을 시도한다. 그리고 그 변경을 마친 이후에 테스트를 돌림으로써 잘 돌아가는지 확인해야한다.
즉, 리팩터링의 시작과 끝에서만 테스트가 통과하는 것이 아니라 리팩터링 중간중간에도 계속해서 프로덕션이 정상적으로 동작해야하는 것이다.
내가 느낀점을 바탕으로 JdbcTemplate 을 리팩터링 해내간 예시를 보자.
(모아모아 프로젝트를 예시로 들기에는 도메인 이해나 관련된 클래스들로 인해서 이해하는데 어려움이 있을 것 같아 다음 예시로 대체하려고한다.)
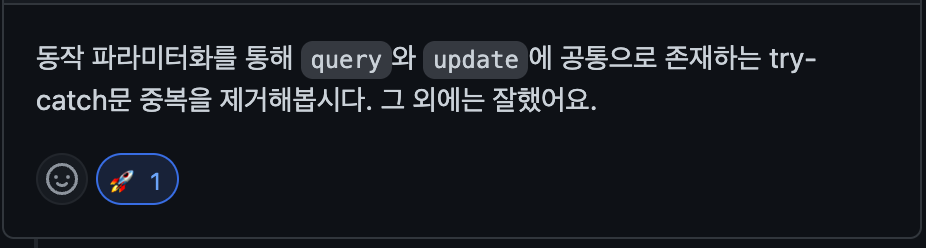
리팩터링의 동기는 다음과 같다. 즉 중복되는 try-catch구문을 동작 파라미터화를 통해서 제거해보는 것이다.
public class JdbcTemplate {
private static final Logger log = LoggerFactory.getLogger(JdbcTemplate.class);
private final DataSource dataSource;
public JdbcTemplate(final DataSource dataSource) {
this.dataSource = dataSource;
}
public <T> List<T> query(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
final ResultSet resultSet = preparedStatement.executeQuery();
final RowMapperResultSetExtractor<T> rowMapperResultSetExtractor = new RowMapperResultSetExtractor<>(rowMapper);
return rowMapperResultSetExtractor.extractData(resultSet);
} catch (SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
public <T> T queryForObject(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final List<T> results = query(sql, rowMapper, args);
return DataAccessUtils.nullableSingleResult(results);
}
public int update(final String sql, @Nullable Object... args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
return preparedStatement.executeUpdate();
} catch(SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
}위의 코드는 리팩터링 전 초기의 코드이고 현재의 코드에서 기존 동작들을 유지한 채 내부 구현만 변경을 진행하게 된다.
여기서 query() 메소드를 활용하는 queryForObject() 는 제외하고 보면 크게 query() 메소드와 update() 메소드가 존재하고 여기서 try-catch 구문이 존재하는 것을 확인해줄 수 있다. 그리고 이 두 메소드는 파라미터를 통해서 구분해내줄 수 있게 된다. 또한 반환형도 List<T>와 int 형으로 차이가 있다.
그럼 여기서 query() 메소드와 update() 메소드의 공통된 부분은 어디일까? 를 먼저 고민해본다. 두 메소드 모두 PreparedStatementSetter.setValu es() 까지 동일하고, 그 이후 로직에서 차이가 있는 것을 확인할 수 있다. 따라서 공통되지 않은 부분을 실행시킬 Executor 인터페이스를 만드는데, 이 때 두 메소드의 반환형이 다르므로 제네릭으로 만들어준다.
그리고 이를 implements 하는 두 이너클래스를 간단하게 구현해주었다. 여기서 Override 하고 있는 execute는 메소드는 공통된 부분을 제외한 부분들이다.
public class JdbcTemplate {
private static final Logger log = LoggerFactory.getLogger(JdbcTemplate.class);
private final DataSource dataSource;
public JdbcTemplate(final DataSource dataSource) {
this.dataSource = dataSource;
}
public <T> List<T> query(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
return new QueryExecutor<>(rowMapper).execute(preparedStatement);
} catch (SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
public <T> T queryForObject(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final List<T> results = query(sql, rowMapper, args);
return DataAccessUtils.nullableSingleResult(results);
}
public int update(final String sql, @Nullable Object... args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
return new UpdateExecutor().execute(preparedStatement);
} catch(SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
interface Executor<T> {
T execute(PreparedStatement preparedStatement) throws SQLException;
}
class QueryExecutor<T> implements Executor<List<T>> {
private RowMapper<T> rowMapper;
public QueryExecutor(final RowMapper<T> rowMapper) {
this.rowMapper = rowMapper;
}
@Override
public List<T> execute(final PreparedStatement preparedStatement) throws SQLException {
final ResultSet resultSet = preparedStatement.executeQuery();
final RowMapperResultSetExtractor<T> rowMapperResultSetExtractor = new RowMapperResultSetExtractor<>(rowMapper);
return rowMapperResultSetExtractor.extractData(resultSet);
}
}
class UpdateExecutor implements Executor<Integer> {
@Override
public Integer execute(final PreparedStatement preparedStatement) throws SQLException {
return preparedStatement.executeUpdate();
}
}
}여기서 테스트를 수행해본다. 당연히 기존 코드에는 영향이 없고, (지금은) 사용하지 않고 있는 새로운 코드가 추가된 것이므로 테스트가 모두 통과할 것이다. (만약 여기서 테스트가 실패한다면 새로운 코드를 추가하는 것 이외에 기존 코드에도 변경이 있다는 것이다.)
이렇게 구현을 진행한 이후에 기존 코드를 새롭게 작성한 코드로 대체하는 작업을 수행한다. 교체를 진행한 코드는 아래와 같다.
public class JdbcTemplate {
private static final Logger log = LoggerFactory.getLogger(JdbcTemplate.class);
private final DataSource dataSource;
public JdbcTemplate(final DataSource dataSource) {
this.dataSource = dataSource;
}
public <T> List<T> query(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final Executor<List<T>> queryExecutor = new QueryExecutor<>(rowMapper);
return executeQuery(sql, queryExecutor, args);
}
public <T> T queryForObject(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final List<T> results = query(sql, rowMapper, args);
return DataAccessUtils.nullableSingleResult(results);
}
public int update(final String sql, @Nullable Object... args) {
final Executor<Integer> queryExecutor = new UpdateExecutor();
return executeQuery(sql, queryExecutor, args);
}
private <T> T executeQuery(final String sql, final Executor<T> queryExecutor, final Object[] args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
return queryExecutor.execute(preparedStatement);
} catch (SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
interface Executor<T> {
T execute(PreparedStatement preparedStatement) throws SQLException;
}
static class QueryExecutor<T> implements Executor<List<T>> {
private RowMapper<T> rowMapper;
public QueryExecutor(final RowMapper<T> rowMapper) {
this.rowMapper = rowMapper;
}
@Override
public List<T> execute(final PreparedStatement preparedStatement) throws SQLException {
final ResultSet resultSet = preparedStatement.executeQuery();
final RowMapperResultSetExtractor<T> rowMapperResultSetExtractor = new RowMapperResultSetExtractor<>(rowMapper);
return rowMapperResultSetExtractor.extractData(resultSet);
}
}
static class UpdateExecutor implements Executor<Integer> {
@Override
public Integer execute(final PreparedStatement preparedStatement) throws SQLException {
return preparedStatement.executeUpdate();
}
}
}위와 같이 교체를 진행한 이후에도 테스트를 진행해본다. 만약 테스트가 통과하지 않는다면 새롭게 구현한 코드가 기존 코드와는 다르게 동작하거나 원하는 결과를 도출하지 못하는 것이므로 다시 처음 단계로 돌아가면 된다. 반대로 제대로 테스트가 통과하고 있다면 리팩터링을 제대로, 즉 기존 코드를 새로운 코드로 적절하게 변경한 것이라는 증거가 된다. (예제 코드에서는 private 메소드로 추출하는 작업이 함께 진행된 모습이다.)
public class JdbcTemplate {
private static final Logger log = LoggerFactory.getLogger(JdbcTemplate.class);
private final DataSource dataSource;
public JdbcTemplate(final DataSource dataSource) {
this.dataSource = dataSource;
}
public <T> List<T> query(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final Executor<List<T>> executor = preparedStatement -> {
final ResultSet resultSet = preparedStatement.executeQuery();
final RowMapperResultSetExtractor<T> rowMapperResultSetExtractor = new RowMapperResultSetExtractor<>(rowMapper);
return rowMapperResultSetExtractor.extractData(resultSet);
};
return executeQuery(sql, executor, args);
}
public <T> T queryForObject(final String sql, final RowMapper<T> rowMapper, @Nullable Object... args) {
final List<T> results = query(sql, rowMapper, args);
return DataAccessUtils.nullableSingleResult(results);
}
public int update(final String sql, @Nullable Object... args) {
return executeQuery(sql, PreparedStatement::executeUpdate, args);
}
private <T> T executeQuery(final String sql, final Executor<T> queryExecutor, final Object[] args) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
PreparedStatementSetter.setValues(preparedStatement, args);
return queryExecutor.execute(preparedStatement);
} catch (SQLException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
}이렇게 우선적으로 테스트가 통과하도록 기존 코드 -> 새로운 코드로 대체가 완료되었다면 코드를 정리하는 절차를 진행한다. 만약 기존 코드를 제거할 필요가 있다면 제거하는 작업도 함께 진행해준다.
느낀점
우아한테크코스가 시작하고 지금까지 적어도 6개월 이상은 리팩터링에 대한 이야기를 하며 지내왔고, 리팩터링이란 단순히 프로덕션 코드를 수정하는 것에 그치지 않는다고 생각하였다. 단순히 변수명을 변경하거나 메소드를 분리하는 정도로 그쳤던 것 같다. 어떻게 보면 책임을 분리해 별도의 클래스로 분리해내거나 하는 등 조금 규모가 큰 리팩터링을 진행하게 되면 이는 리팩터링이라기 보다는 하나의 작업(feat) 이라고 생각했던 것 같기도 하다..😅
그리고 중요한 것은 그러한 리팩터링의 과정 중간 중간 코드가 돌아가도록 확인하지 않는다는 것이다. 즉, 테스트 를 돌려보지 않았다. 그리고 리팩터링 과정 중간 중간 눈에 보이는 개선 가능한 부분은 무분별하게 바로바로 수정해 나가기도 하였다. 결국 나는 작은 단위로 쪼개서 리팩터링을 진행하지 못하고, 큰 단위 큰 단위로만 리팩터링을 진행할 수 있었고, 테스트가 통과하는지 확인하는 것도 리팩터링 과정의 끝에서 단 한 번 수행하였다. 하지만 위의 간단한 예시를 통해서도 알 수 있다시피 리팩터링이 진행되는 중간중간에도 계속해서 테스트를 진행하는 것이 필수이다. 즉, 리팩터링과 테스트는 때어놓을 수 없는 관계이다.

안녕하세요 우아한 테크코스 백엔드 5기를 준비하며 4기 합격자분들 글 읽다가 찾아오게 됐는데요.. 제가 4기 때는 서류 + 코딩 테스트에 떨어져서 올해 파이썬으로 코딩 테스트 위주로 준비했는데, 5기부터는 코딩 테스트가 사라지고 바로 프리코스 4주에 들어가더라고요. 그래서 확인하자마자 자바 문법 익히고 4기 프리코스 문제들을 풀어보고 있는데 느끼는 것이 문제 자체는 난이도가 높지 않은데 요구사항(자바 컨벤션, 깃 컨벤션 등)을 지키기가 상당히 어렵더라고요.. 지금은 그냥 작년 프리코스에 참여하고 있다고 생각하고 1주 차 문제를 풀어보고 있는데 통과하신 분들 소스 보니까 제가 짜는 거랑은 정말 차원이 다르게 객체지향적으로 잘 짜셨더라고요 .. 26일 프리코스 시작까지 약 2주 정도 남았는데 혹시 어떤 식으로 준비하면 좋을지 조언 좀 해주실 수 있나 싶어서 이렇게 댓글 남겨요 ㅠㅠ 우아한 테크코스 5기에 합격해서 선배님이라고 부르고 싶네요 .. ㅠㅠ
p.s 혹시 자소서 첨삭 받으셨다면 유료여도 괜찮으니 저도 좀 알려주실 수 있을까요? 이번에 꼭 합격하고 싶어서요..