ViNo를 개발하면서 필요했던 Clova Speech를 어떻게 사용하는지 자세하게 알아보려고 한다.
1. 로그인 및 이용신청
Clova Speech는 Naver Cloud에서 지원하는 AI Service로 네이버 계정을 통해 로그인을 진행할 수 있다.
- 로그인을 진행하고 Clova Speech 이용신청을 한다.
해당 링크를 클릭하면 위 사진과 같은 페이지가 나오고 우측 상단 로그인을 진행한 후 이용 신청하기를 눌러 Clova Speech를 콘솔에 등록할 수 있다.
-
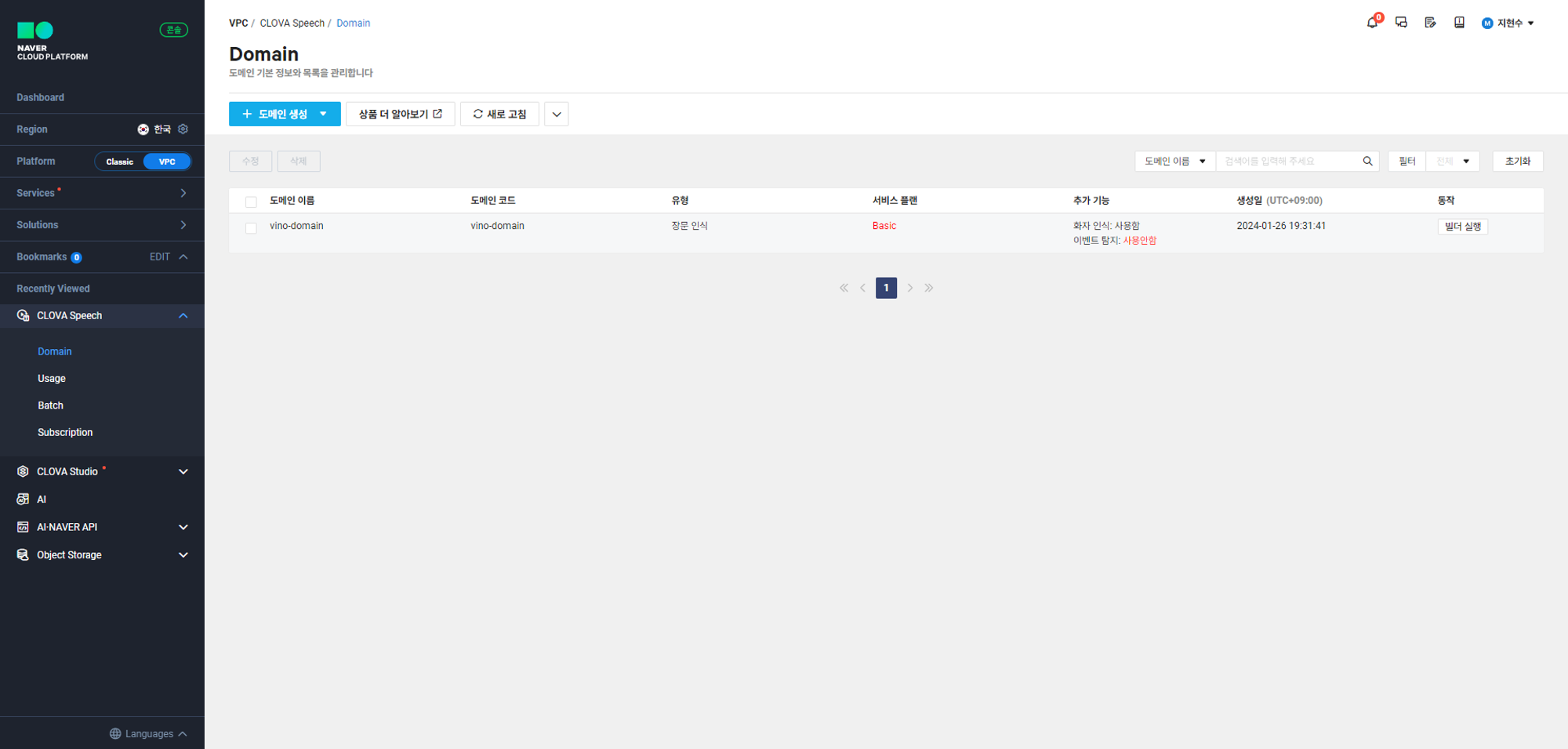
정상적으로 Clova Speech를 이용 신청 하였다면 콘솔 탭에 들어갔을 때 이와 같이 Clova Speech가 Recently Viewed에 등록되어 있어야 한다.
-
Clova Speech는 장문 인식과 단문 인식 기능을 지원하는데 이 글에서는 장문 인식 도메인 생성 과정을 다루려고 한다.
-
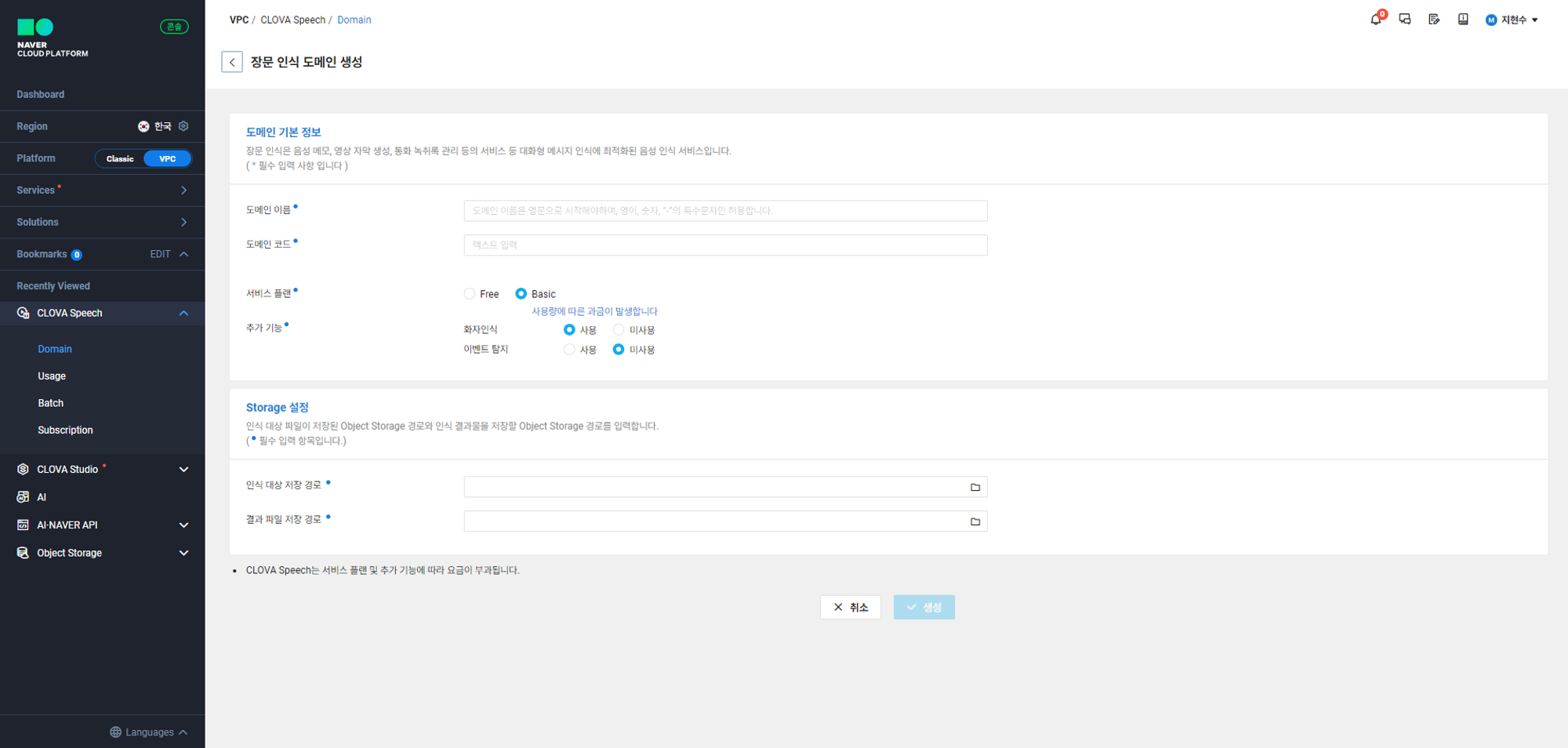
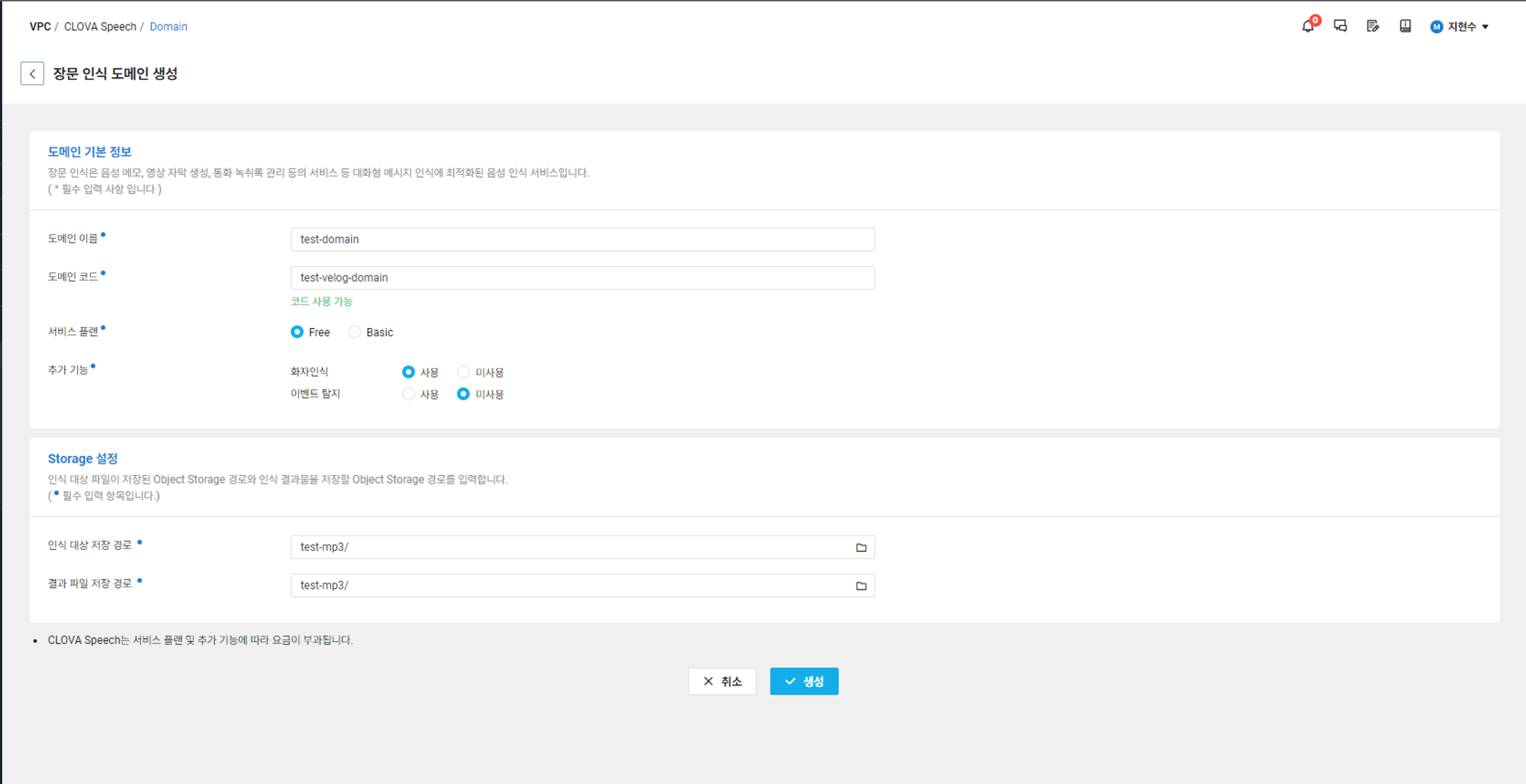
위 사진과 같이 장문 인식 도메인 생성을 클릭하면 모든 항목이 필수 입력 항목으로 지정되어 있다
Storage 설정에 인식 대상 저장 경로와 결과 파일 저장 경로의 항목이 있는데
인식 대상 저장 경로는 Clova Speech에게 인식 시킬 음성파일을 저장하는 공간이다.
결과 파일 저장 경로는 Clova Speech가 인식한 음성파일의 스크립트를 저장할 공간이다.
이 공간은 컴퓨터의 로컬 저장소가 아니라 nCloud에서 지원하는 Object Storage에 버킷을 만들어야 한다.
2. Object Storage 이용신청
Clova Speech를 사용하기 위해서는 Object Storage를 이용하여야 한다.
Clova Speech와 동일하게 이용 신청을 진행하고 콘솔탭에 가면 아래 사진과 같이 Object Storage 탭이 생성이 되었을 것이다.

필자는 이미 사용했기 때문에 두가지의 버킷이 존재하는것을 알 수 있다.
인식 대상 저장 경로와 결과 파일 저장 경로를 동일하게 설정할 수 있지만 효율적인 관리를 위해 두가지로 나누었고 버킷 생성하는 부분을 다뤄보겠다.
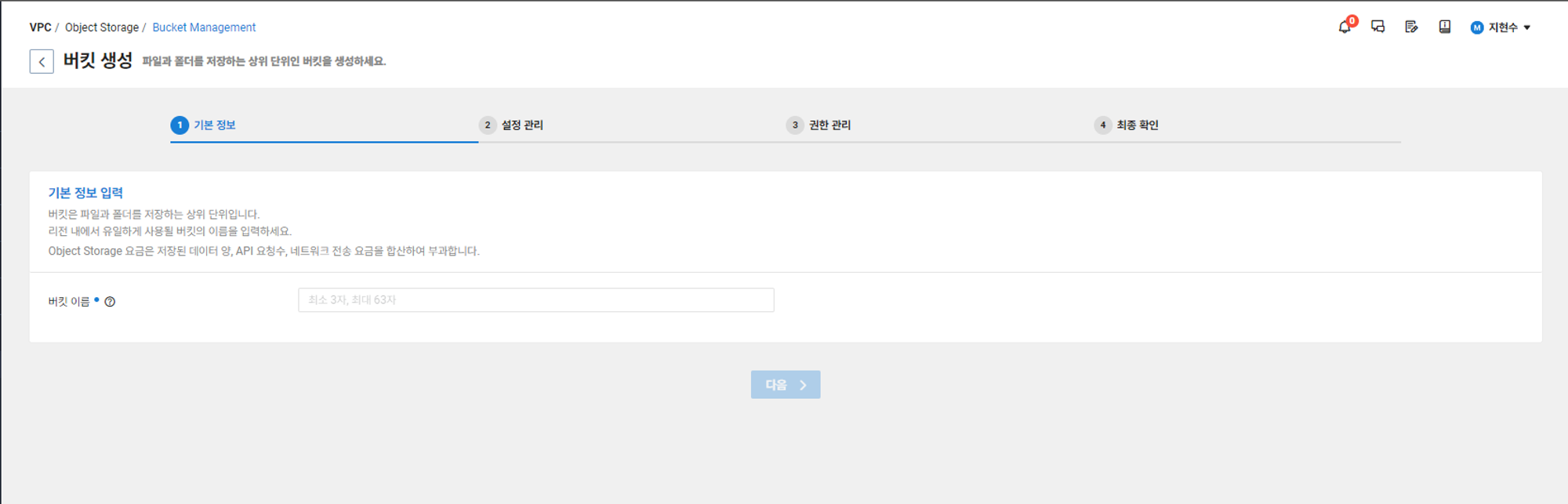
1) 버킷 생성을 누르면 버킷을 만드는 창으로 이동하게 되는데 본인이 설정하고 싶은 이름을 적고 다음을 누른다. 필자는 'Test-mp3'로 이름을 정하겠다.
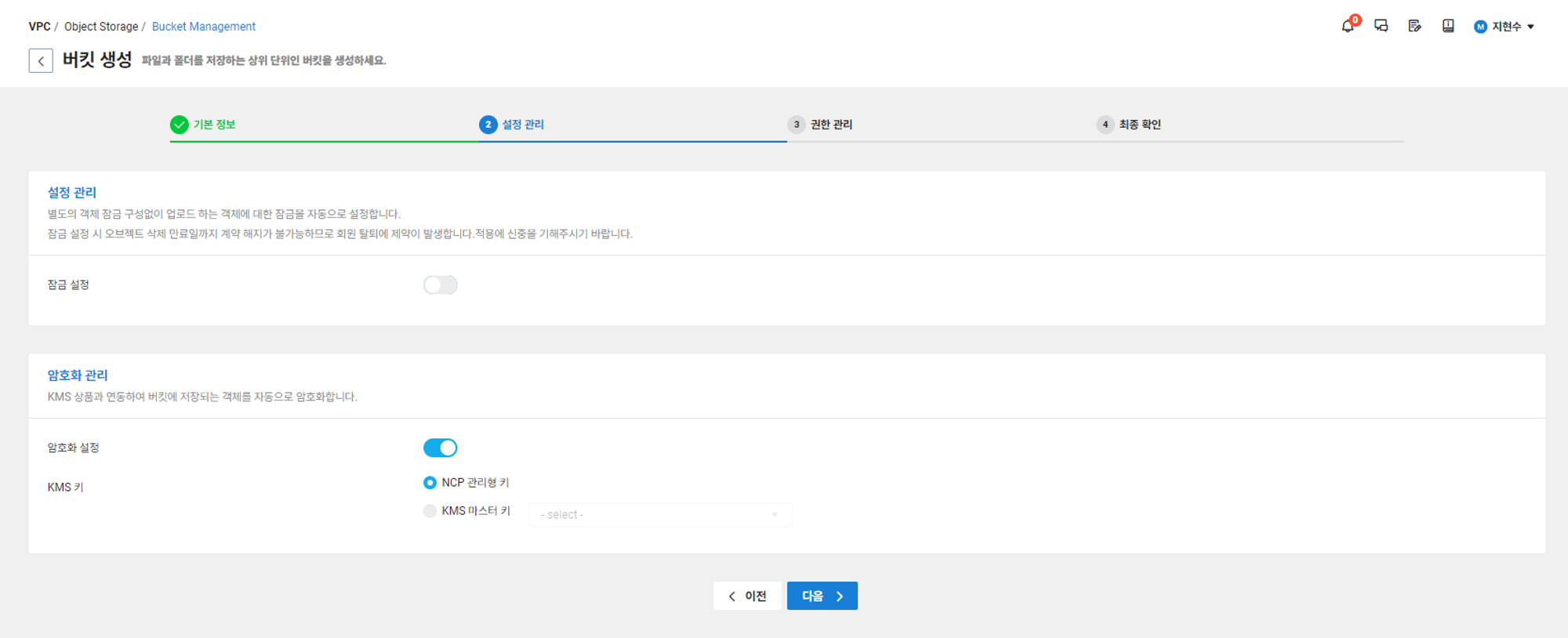
2) 설정관리의 잠금 설정은 사진에 보이는 설명과 같이 별도의 고객센터 문의가 필요로 하다. 따라서 암호화 관리 -> 암호화 설정 -> NCP 관리형 키를 선택하고 다음으로 넘어가자.
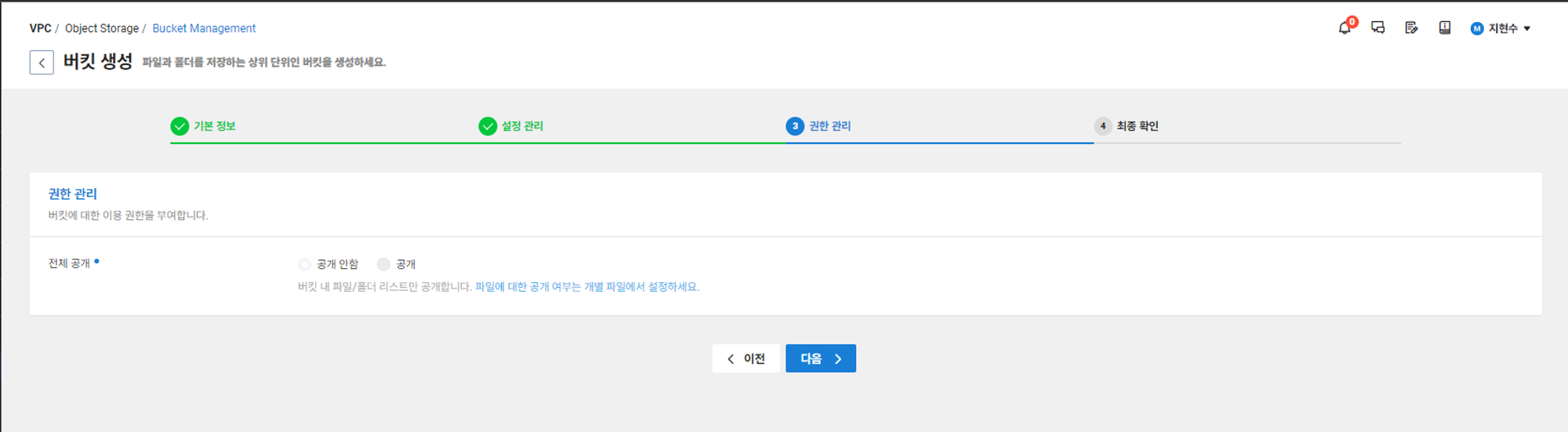
3) 권한 관리 탭에서는 기본적으로 공개 안함으로 설정이 되어있어 다음으로 바로 넘어가도 된다.
만약 따로 공개하고 싶은 파일이 있으면 버킷 생성 후 버킷에 들어있는 파일의 개별 권한 설정을 해주면 된다.
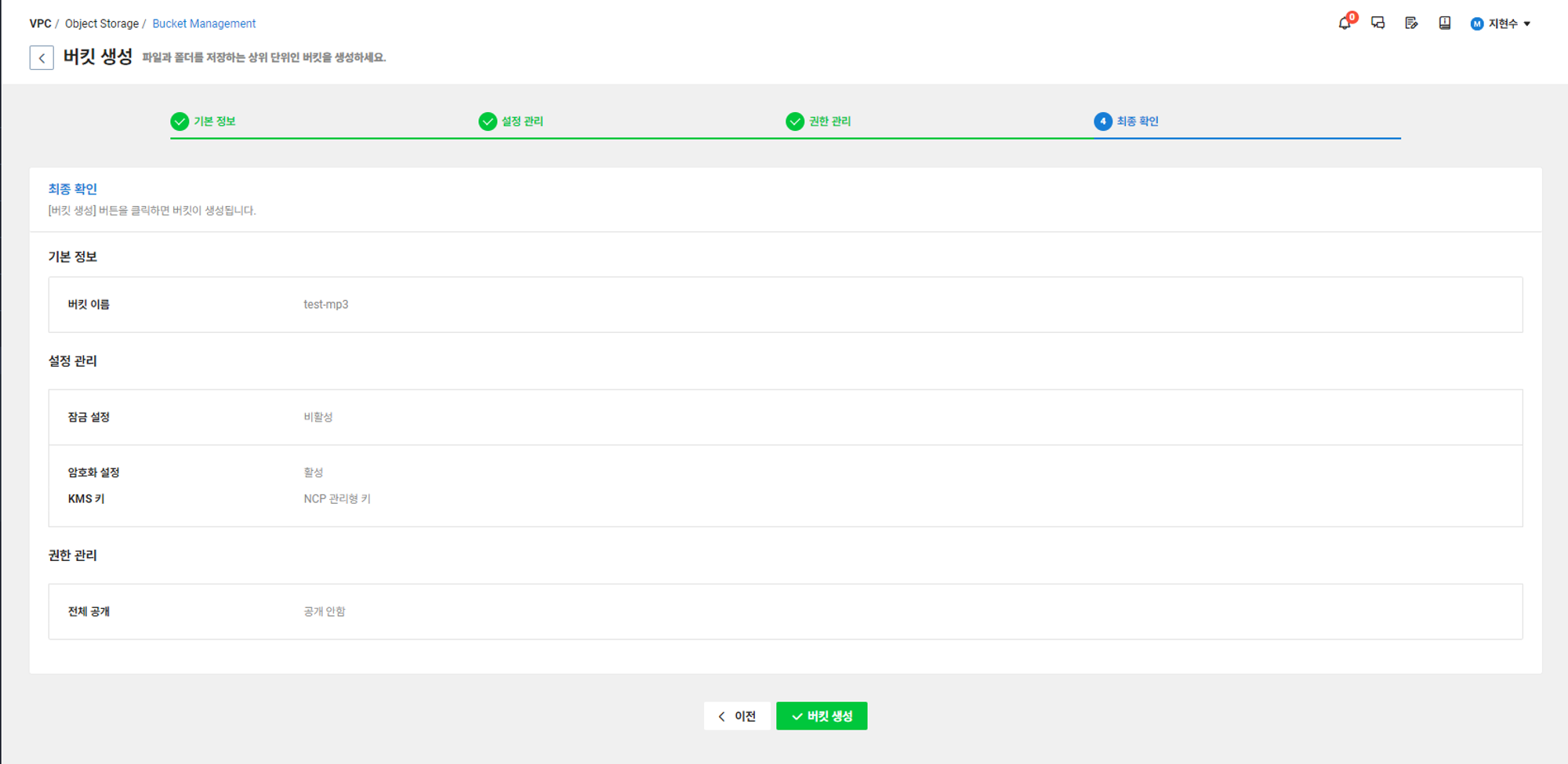
4) 최종확인을 마친 후 버킷 생성을 진행한다.
3. Clova Speech 사용하기
ncloud 콘솔 탭에 Clova Speech를 클릭하고 Domain 생성을 누르게 되면 위 사진과 같이 나오게 되는데 몇가지 설명을 하려고 한다.
1) 서비스 플랜
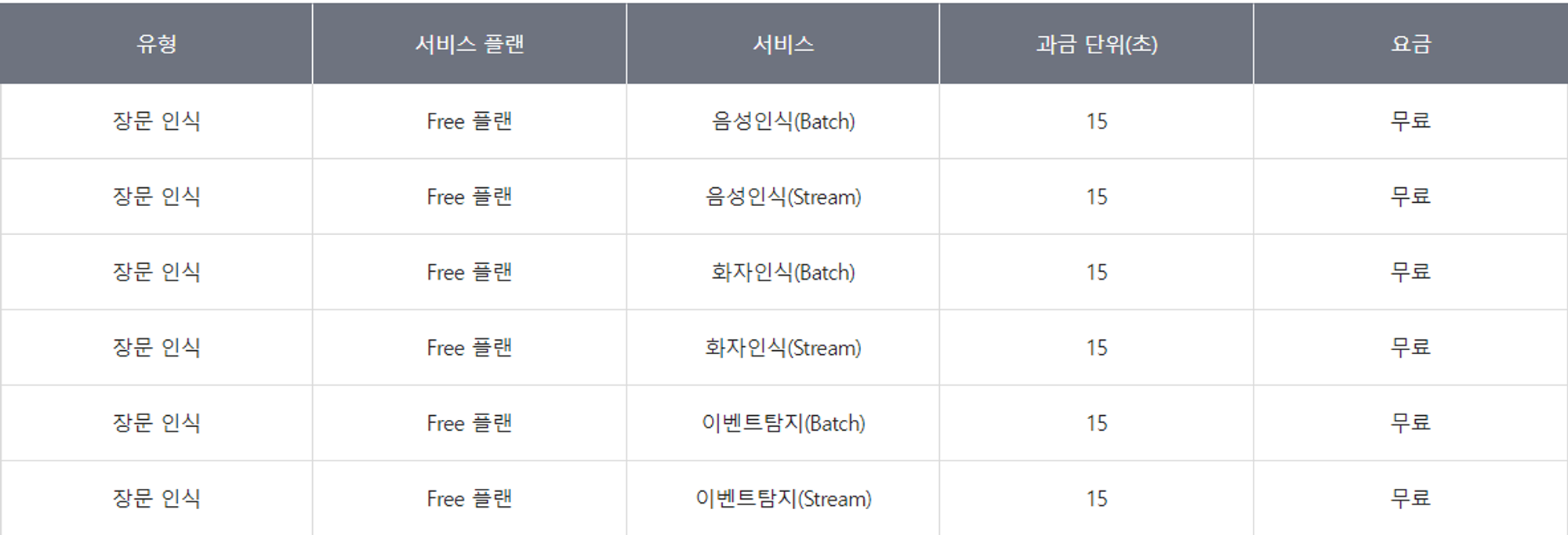
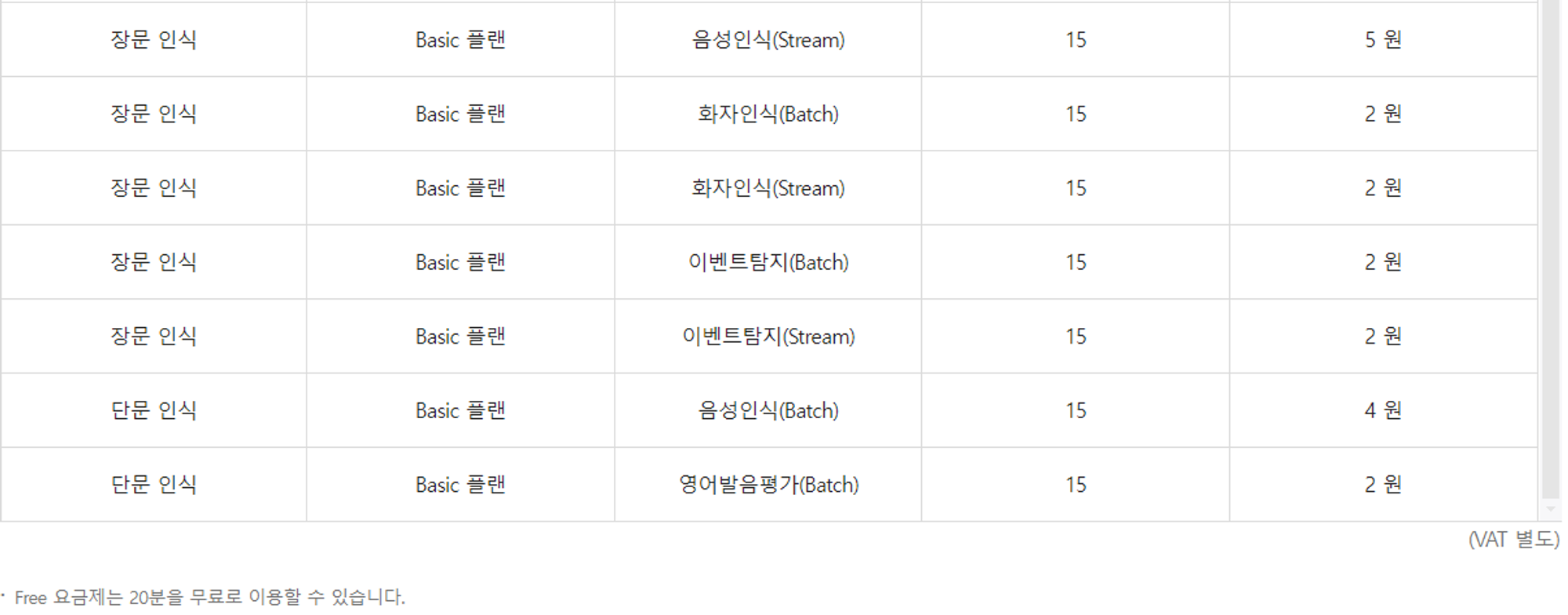
- Free플랜 이용시 20분 이하의 음성파일 경우 무료로 사용이 가능하다.
- Basic플랜 이용시 음성인식, 화자인식, 이벤트 탐지의 각각의 기능을 이용할 때마다 요금표와 같이 과금이 발생한다.
필요성에 맞게 Clova Speech 도메인 생성을 할 때 고르면 될 것이다.
2) 음성인식, 화자인식, 이벤트 탐지

- 사진 설명과 같이 음성인식은 Clova Speech를 이용했을 때 필수로 사용되는 기능이고, 화자인식은 선택이 가능하다.
- 화자인식의 예를 들어보면 음성파일에는 여러 사람의 음성이 존재하는데 그 음성을 기준으로 화자를 구분한 음성인식 스크립트를 제공해준다. 단방향성 인터뷰의 음성파일 혹은 강의 녹음 음성파일은 화자인식이 필요 없지만 면접 혹은 사회자와 인터뷰어가 같이 소통하는 음성파일일 경우에는 화자인식이 필요하다 할 수 있다.
- 이벤트 탐지는 음성에서 추출된 BGM이나 음악등을 텍스트로 표현해준다 예를들어 음성파일에 박수 소리가 들리면 (박수) 와 같이 스크립트 파일에 포함시켜준다.
3) 빌더 실행
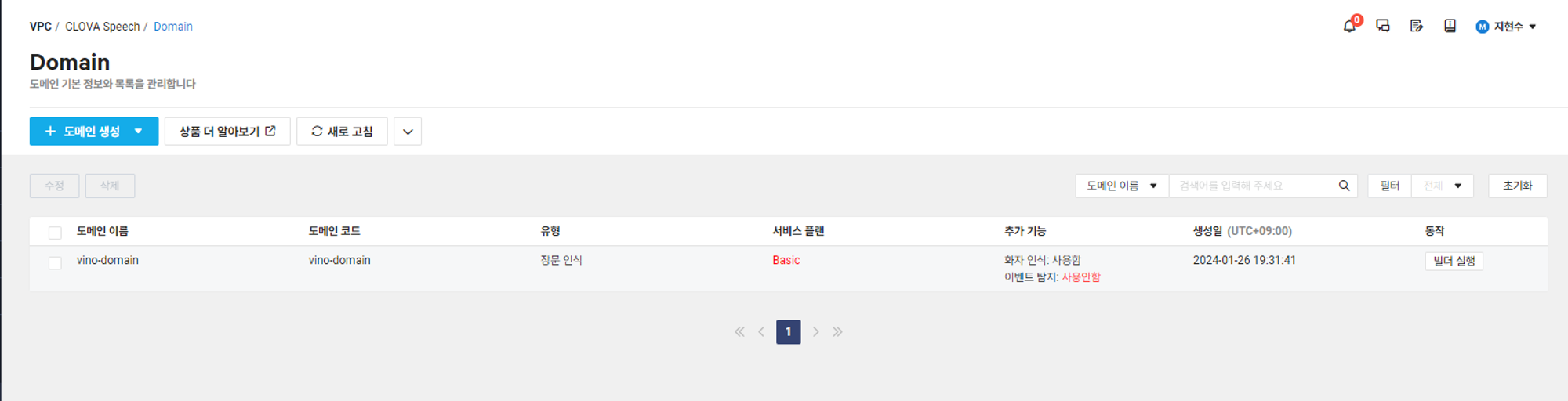
원하는 기능들을 선택하고 Clova Speech 도메인을 생성 하였으면 위 사진에서 빌더 실행을 눌러보자.
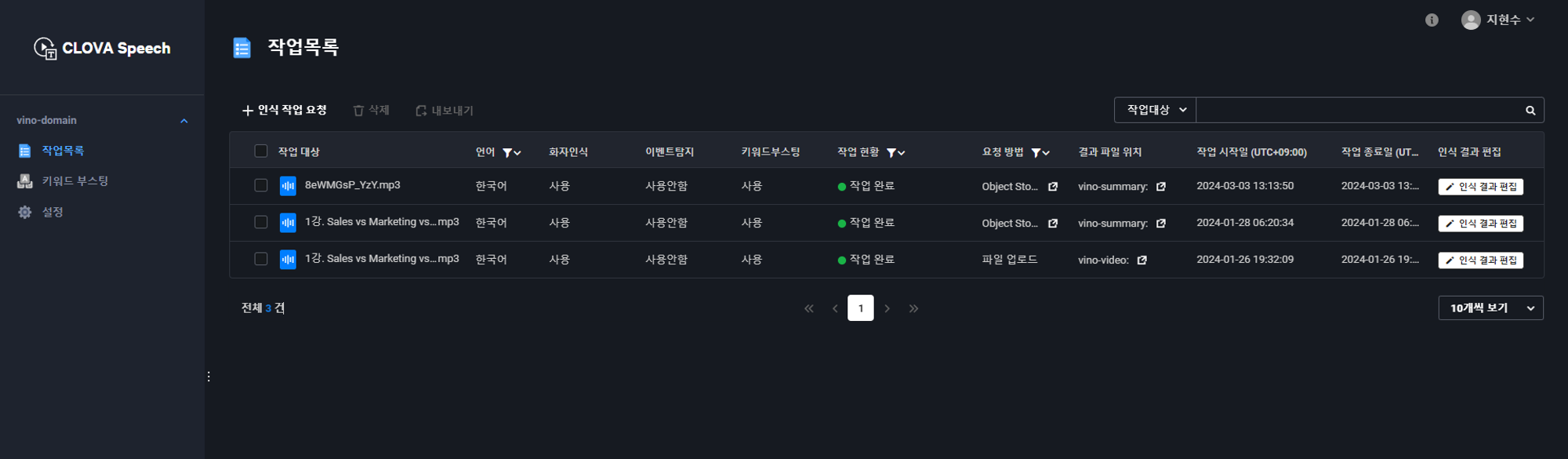
빌더 실행을 눌렀을 때의 페이지다 영상 인식 작업 요청을 하게 되면
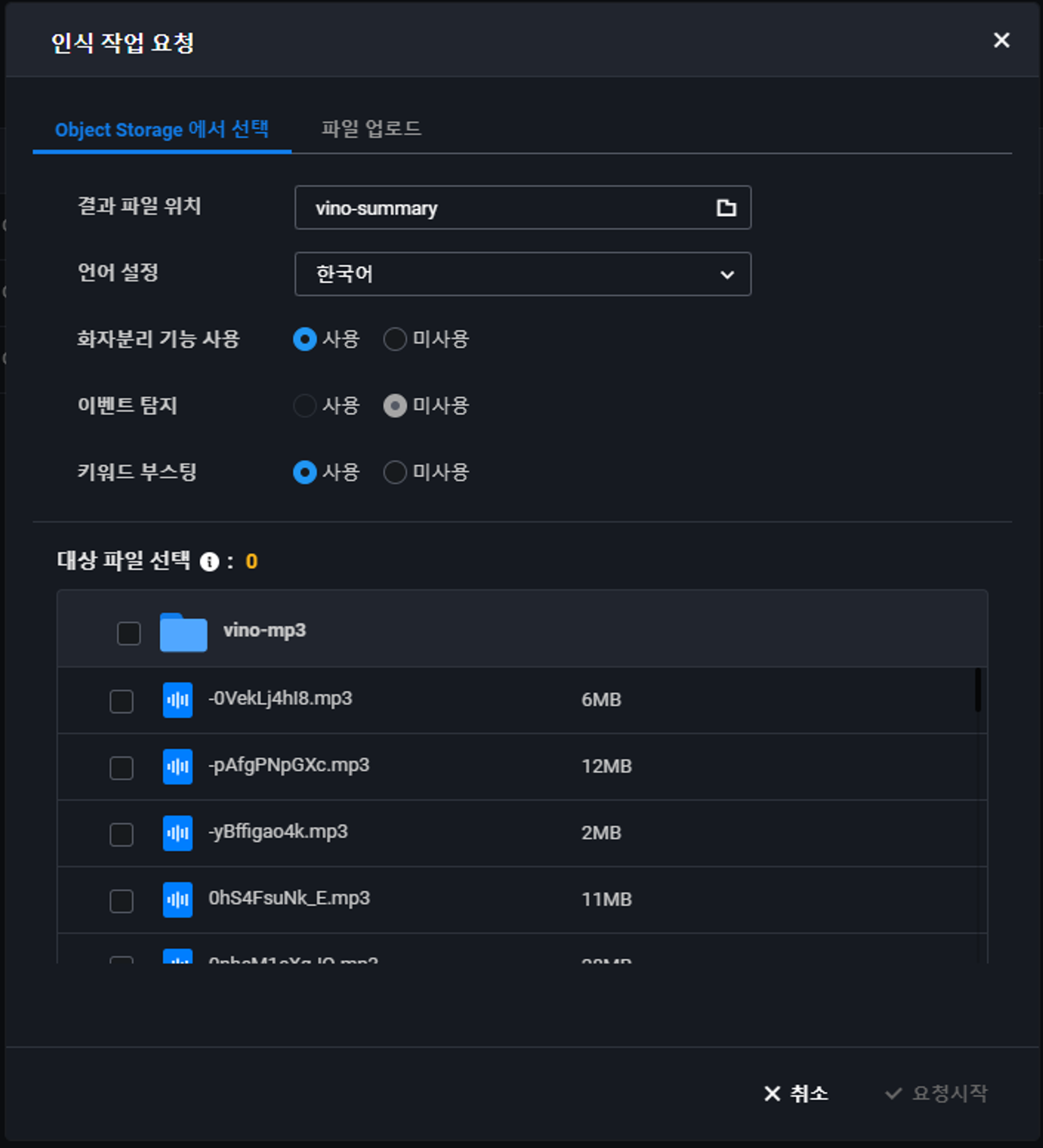
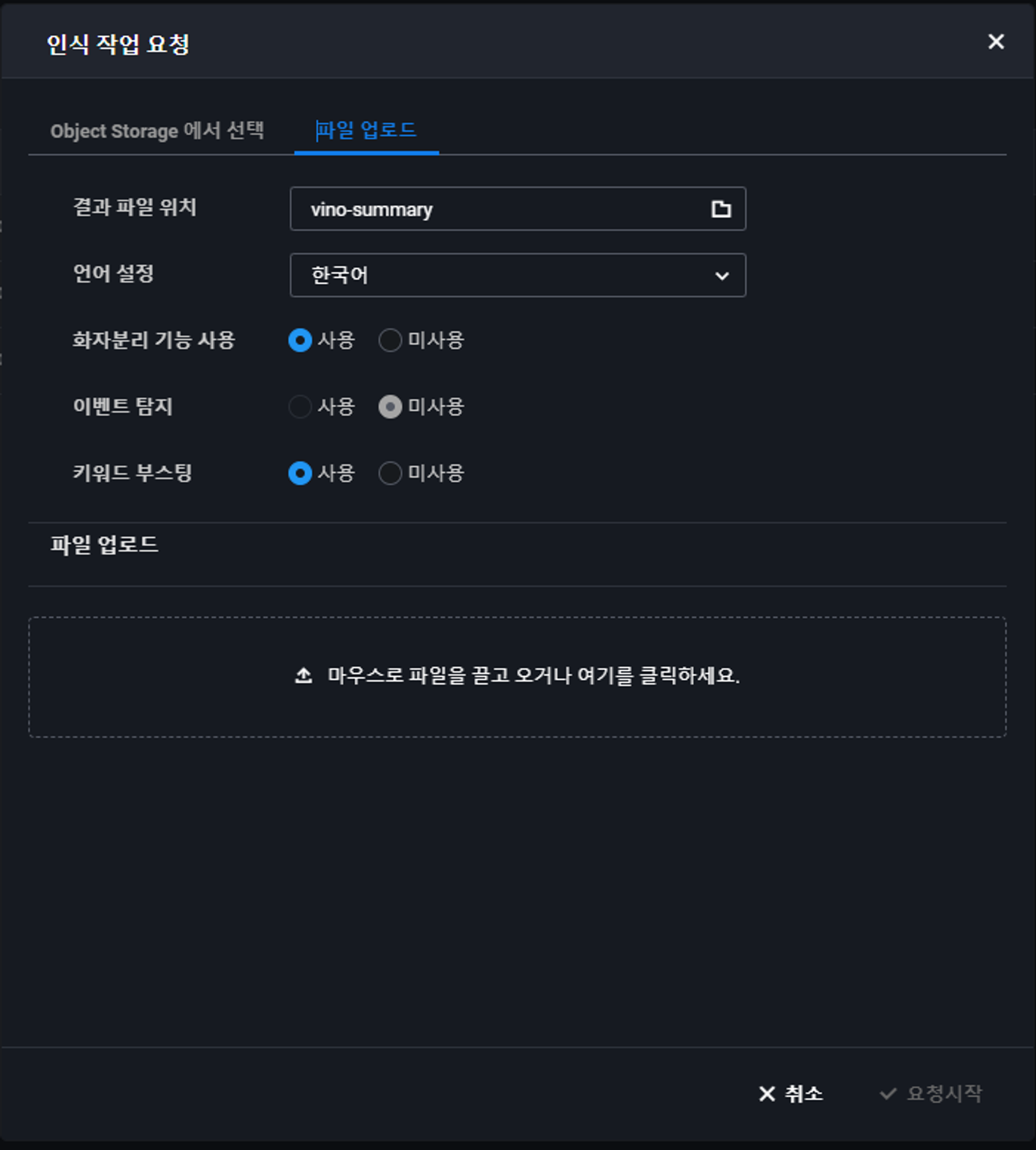
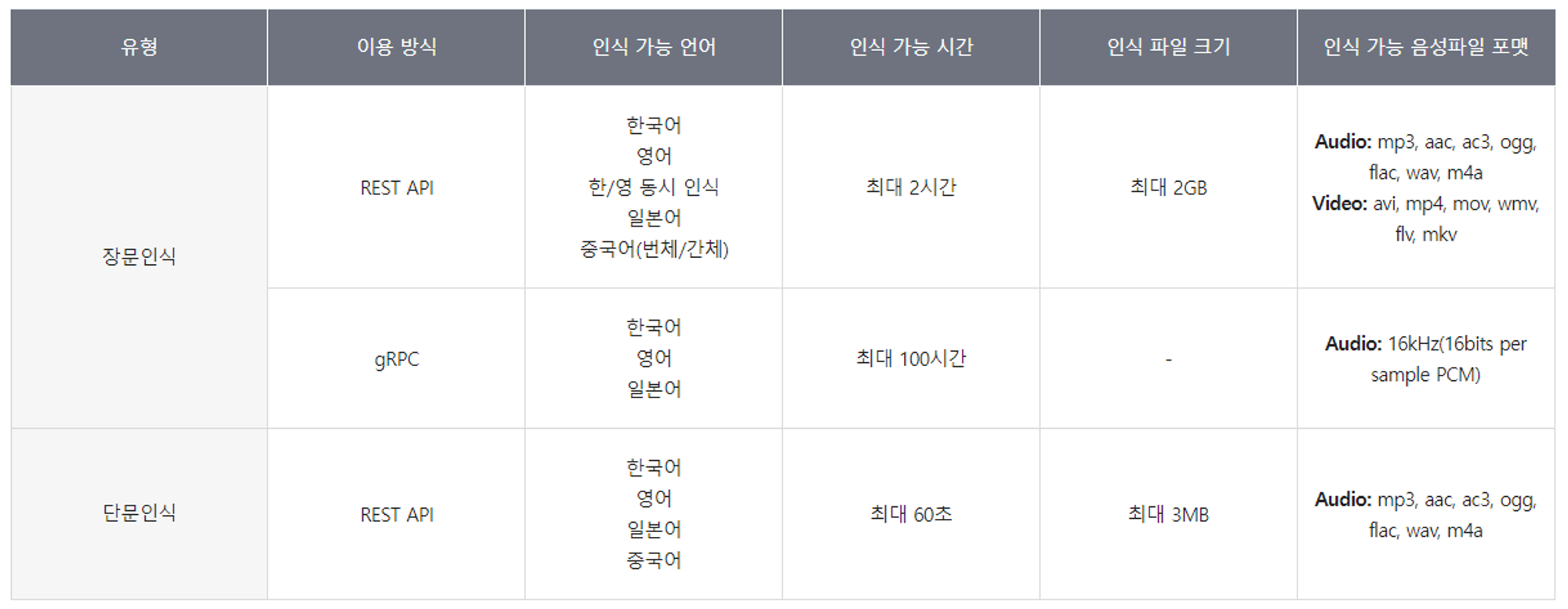
각각 원하는 방식(Object Storage에서 업로드, Local Storage에서 업로드)가 가능하다. Clova Speech는 아래 사진과 같은 파일만 업로드 및 빌드가 가능하기 때문에 참고 바란다.
음석인식을 진행하고 싶은 영상이나 음성파일이 준비가 되었다면 업로드 후 요청 시작을 눌러보자.

요청 시작을 누른 후 10~20초 정도 기다리면 인식 결과 편집 버튼이 활성화 되게 된다. 이 글에서 인식한 음성은 아래 유튜브 영상이다.
영상 길이는 9분정도이며 영상 길이가 크게 늘지 않는 이상 30초 이내면 변환이 완료된다.
이제 인식 결과 편집을 눌러보자.
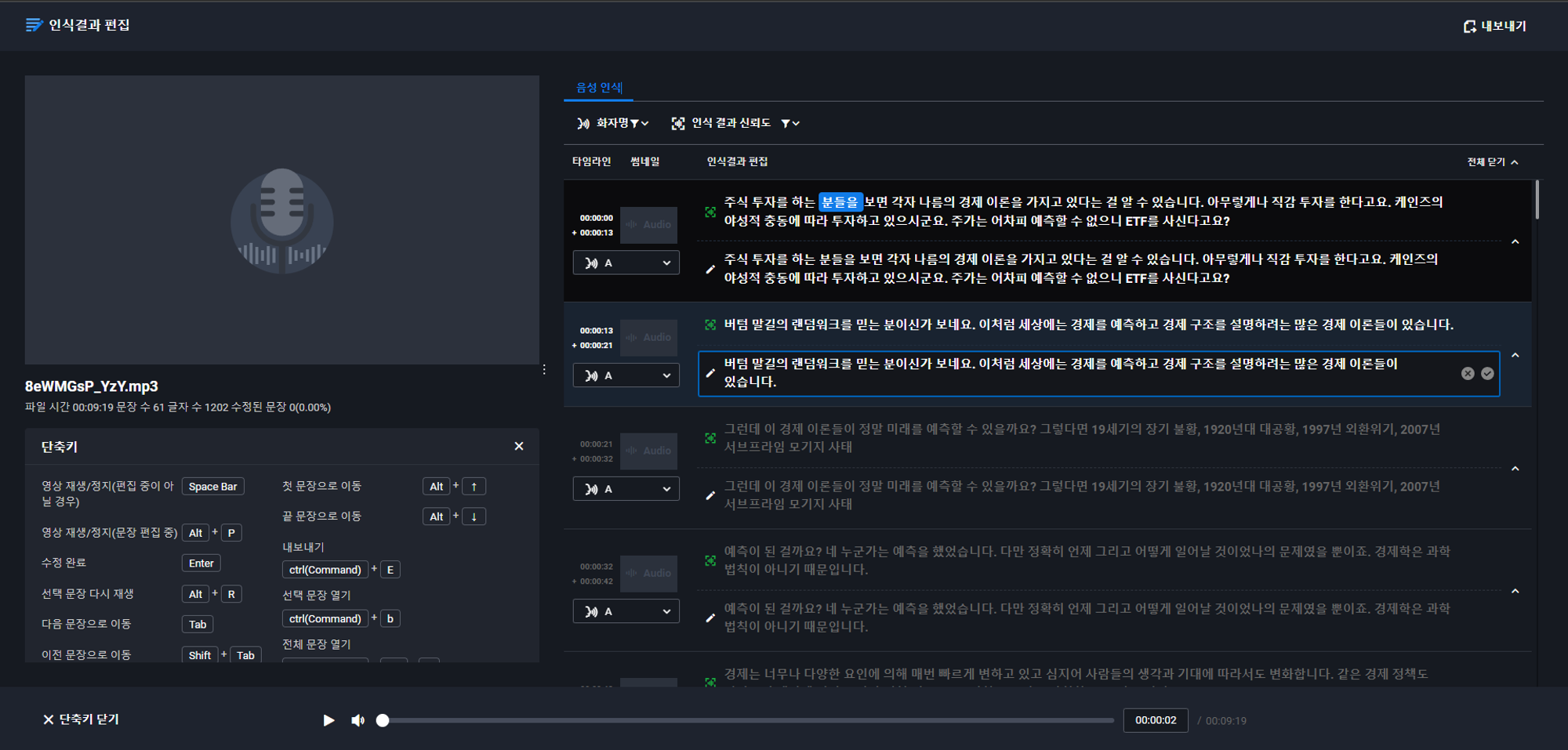
영상일 경우에는 왼쪽에 영상이 표시가 되고 썸네일도 정상적으로 출력이 될 것이다. 하지만 MP3 음성 파일을 음성인식 시켰기 때문에 표시되지 않는 것이다.
이 음성인식 결과를 내보내기 할 수 있는데 우측 상단에 내보내기를 클릭하면 아래 사진 같이 나오게 된다.
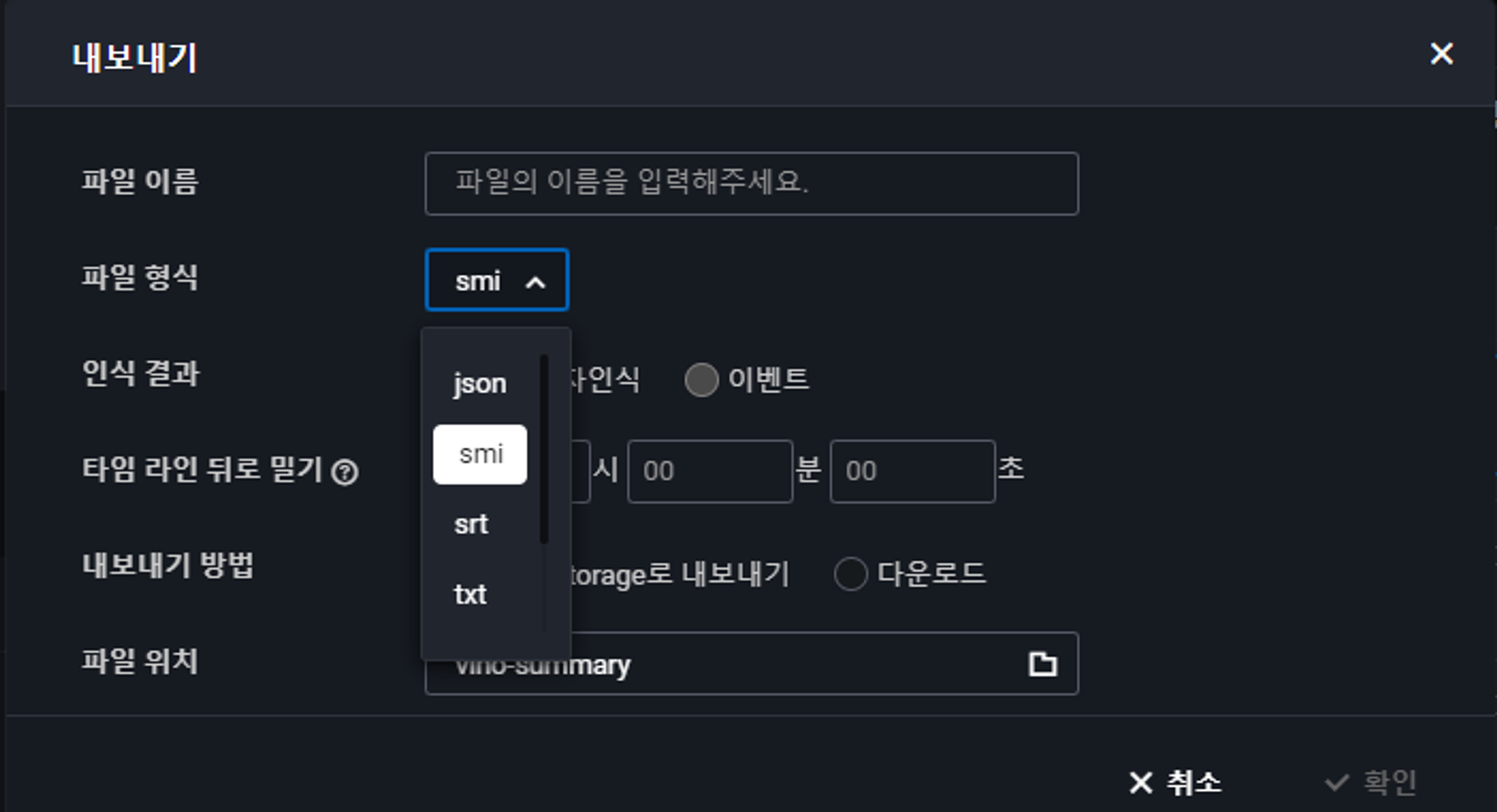
- 내보내기 할 때에 여러 파일 형식을 선택할 수 있다. (Json, smi, srt, txt, csv, xsl)
- 내보낼 장소도 선택이 가능한데 Object Storage와 Local Storage에 다운로드도 가능하다.
간단하게 웹사이트에서 Clova Speech를 이용 신청하고 실행해보는 것 까지 진행 해봤다.
아래부터는 개발자가 이 Clova speech를 API 형태로 어떻게 호출하는지 Node.js를 사용하여 알아보도록 하겠다.
4. Node.js에서 Clova Speech API 사용하기
Clova Speech를 Node.js에서 사용하려면 Clova Speech에 사용할 음성 및 영상파일을 Object Storage에 업로드 후 호출할 수 있다. 따라서 Object Storage에서 파일을 업로드하고 업로드 된 파일을 Clova Speech를 호출해서 결과 값을 받아오는 것 까지 해볼 것이다.
시작하기에 앞서 node.js에서
node.js에서 object storage API를 사용하려면 먼저 S3 sdk를 설치해줘야한다. 아래 코드를 npm을 통해 설치하자.
npm install --save aws-sdk@2.348.0
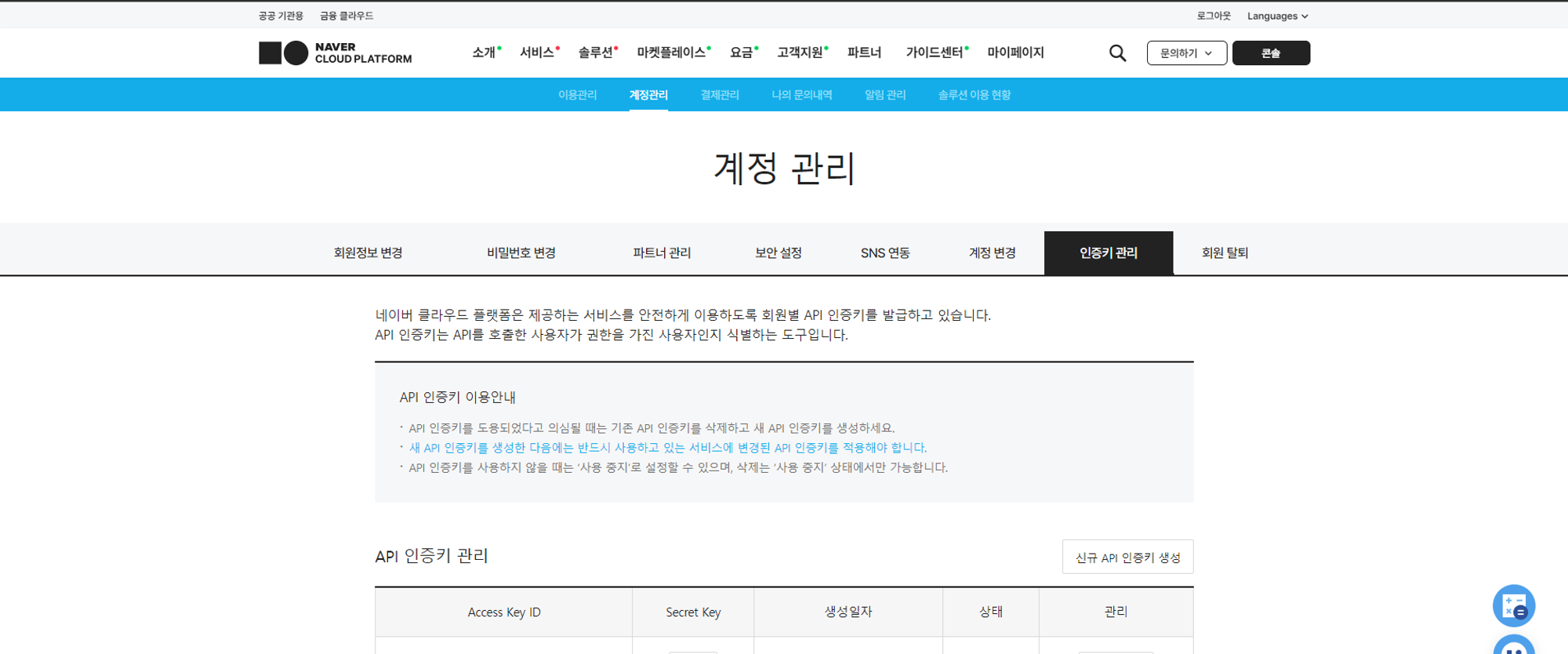
또 API를 사용하기 위해서는 accessKeyId와 secretAccessKey가 필요한데 아래 사진을 보면 ncloud platform 사이트에 접속해서 마이페이지 -> 계정관리 -> 인증키 관리에서 볼 수 있다.
1) Object Storage 파일 업로드
import AWS from 'aws-sdk';
import fs from 'fs';
import path from 'path';
// Naver Cloud Object Storage 설정
const endpoint = new AWS.Endpoint('<https://kr.object.ncloudstorage.com>');
const region = 'kr-standard';
const bucketName = process.env.OBJECT_STORAGE_BUCKET_NAME;
const s3 = new AWS.S3({
endpoint,
region,
credentials: {
accessKeyId: process.env.OBJECT_STORAGE_ACCESS_KEY,
secretAccessKey: process.env.OBJECT_STORAGE_SECRET_KEY
}
});
// 로컬 파일을 S3에 업로드
export const uploadFileToStorage = async (filePath) => {
const fileContent = fs.readFileSync(filePath);
const fileName = path.basename(filePath);
const params = {
Bucket: process.env.OBJECT_STORAGE_BUCKET_NAME,
Key: fileName,
ACL: 'public-read',
Body: fileContent
};
try {
const { Location } = await s3.upload(params).promise();
// 업로드 성공 후 로컬 파일 삭제
fs.unlink(filePath, (err) => {
if (err) console.error('Error deleting local file:', err);
else console.log('Local file deleted successfully');
});
return Location; // S3에 업로드된 파일의 URL 반환
} catch (error) {
console.error('Error in uploading file to S3:', error);
throw error;
}
};
맨 위 코드를 살펴보면 기본적으로 Naver Cloud Object Storage를 먼저 기본설정해줘야한다.
Endpoint와 region 그리고 업로드 할 bucket Name을 꼭 지정해줘야한다.
아래 링크는 Object Storage API 이용가이드 이다
Object Storage API 이용 가이드
2) Clova Speech API 호출
파일을 업로드 하고 나면 이제 clova speech를 호출 할 수 있게 되는데 object storage와 마찬가지로 API KEY가 필요하다
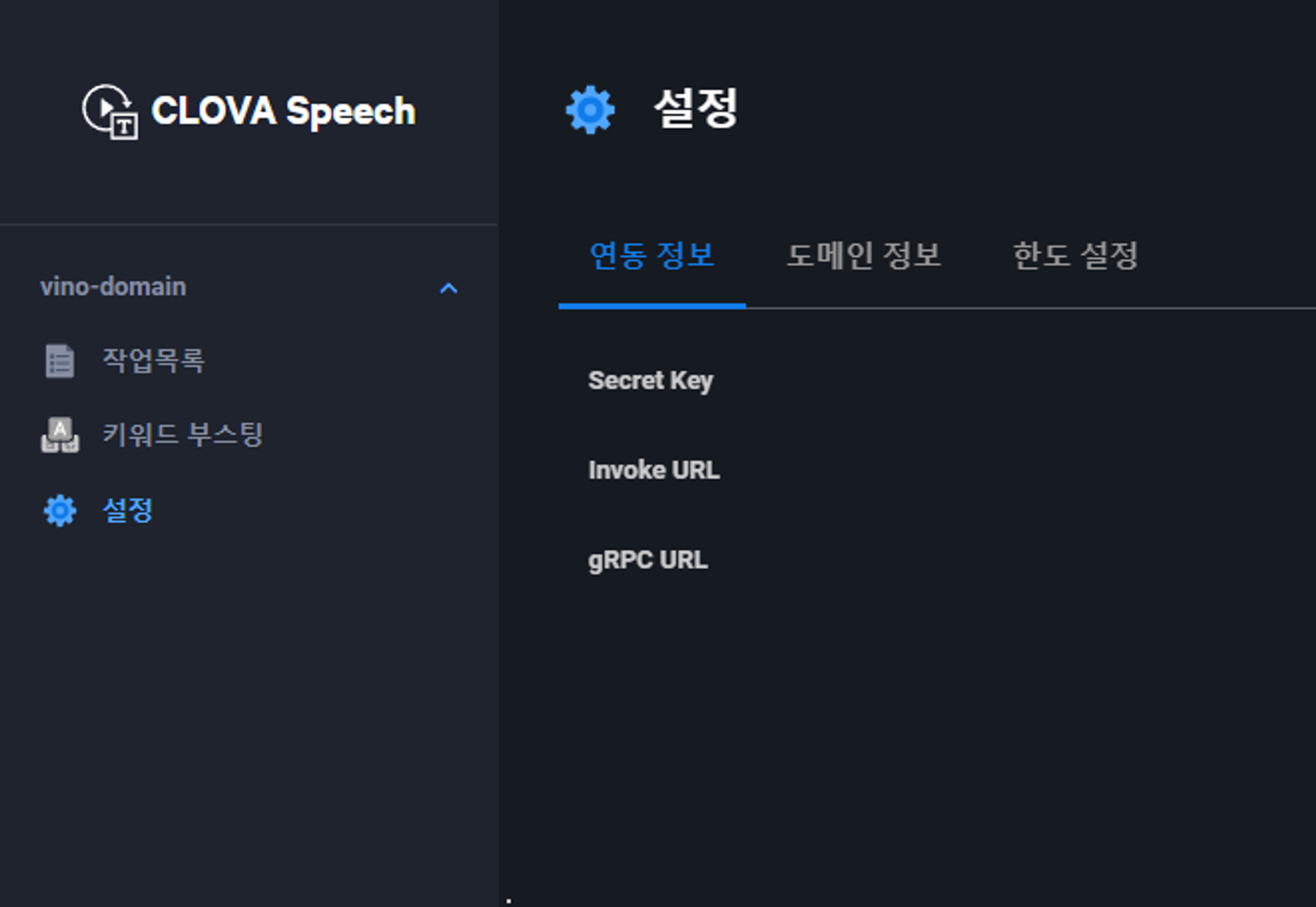
ncloude 콘솔에 접속해서 Clova Speech를 빌드 실행하면 왼쪽에 설정탭이 있다.
필요한 정보는 Secret Key와 invoke URL이므로 잘 적어두도록 하자.
import axios from 'axios';
import dotenv from 'dotenv';
dotenv.config();
const CLOVA_SPEECH_API_KEY = process.env.CLOVA_SPEECH_API_KEY;
const CLOVA_SPEECH_INVOKE_URL = process.env.CLOVA_SPEECH_INVOKE_URL;
//const CLOVA_SPEECH_CALLBACK_URL = 결과를 받을 Domain 주소;
export const recognizeFromObjectStorage = async (objectStorageDataKey, language = 'ko-KR') => {
const requestBody = {
dataKey: objectStorageDataKey, // 인식을 원하는 파일의 ObjectStorage 경로에 접근하기 위한 Key
language,
completion: 'async',
resultToObs: true, // 결과를 Object Storage에 저장할지 여부
noiseFiltering: true, // 노이즈 필터링 적용 여부
wordAlignment: true, // 단어 정렬 정보 포함 여부
fullText: true, // 전체 인식 결과 텍스트를 출력할지 여부
};
try {
const response = await axios.post(`${CLOVA_SPEECH_INVOKE_URL}/recognizer/object-storage`, requestBody, {
headers: {
'X-CLOVASPEECH-API-KEY': CLOVA_SPEECH_API_KEY,
'Content-Type': 'application/json'
}
});
console.log("스크립트화된 데이터",response.data);
return response.data;
} catch (error) {
console.error('Error in recognizing from object storage:', error);
throw error;
}
};
해당코드를 사용하여 Clova Speech를 호출할 수 있는데 옵션에서 CallbackURL도 지정할 수 있다. CallbackURL을 지정하게 되면 API호출이 완료되고 결과값을 원하는 URL로 요청받을 수 있다.
아래 링크는 Clova Speech 이용 가이드이다.
Clova Speech API 이용 가이드
3) Clova Speech 결과 값 가져오기
//Clova Speech 결과 파일 읽기(Json)
export const readFileFromObjectStorage = async (bucketName, objectKey) => {
const params = {
Bucket: bucketName,
Key: objectKey
};
try {
const data = await s3.getObject(params).promise();
return JSON.parse(data.Body.toString('utf-8'));
} catch (error) {
console.error('Error in reading file from storage:', error);
throw error;
}
};
위에 코드를 사용했다면 Clova Speech를 호출한 결과가 JSON 형태로 Object Storage에 저장이 되었을 것이다. 따라서 Object Storage에 저장된 음성인식 결과 값을 가져와서 아래 코드와 같이 사용하면 된다.
const jsonData = await readFileFromObjectStorage(process.env.OBJECT_STORAGE_BUCKET_SUMMARY_NAME, scriptFileName);
