
REST란?
REST는 Representational State Transfer의 약자로 표현적 상태 전송이라고 번역할 수 있으나
자원 표현을 통한 상태 전달이라고 설명하는 것이 이해가 쉬울 것 같습니다.
그럼 한 단어씩 뜯어서 본격적으로 REST를 알아보기 전에 대충 감을 잡아 봅시다.
-
자원(Resource)
자원은 상태의 주체가 되는 데이터입니다.
예를 들어 회원정보를 수정하고 싶다면 회원정보가 자원이 됩니다.
자원은 URI로 식별됩니다.
https://csi/user/4567 -
표현(Representation)
회원정보에는 다양한 정보들이 있을 수 있습니다. 예를들어 ID, email, 나이 등
이를 조작하려 할 때 자원의 현재 상태나 의도된 상태에 대한 값들과 무엇을 수행할지에 대한 표현을 Representation이라고 합니다.
JSON, XML등의 형식으로 http 메시지 본문(Payload)에 담겨 전송됩니다.
PUT /users/123 HTTP/1.1 Content-Type: application/json { "email": "user@example.com", "age": 25 } -
상태 전달(State Transfer)
클라이언트가 서버의 자원상태를 요청(Request)하면 서버는 그에 대한 응답(Response)를 하여 자원의 상태를 전달합니다.(CRUD)
자원 상태를 전달할 때 위에서 설명한 표현을 통해 특정 형태로 전송합니다.
즉, REST는 자원을 URI로 구분하여 해당 자원의 상태를 주고받는 것을 의미합니다.
여기서 중요한 점은 REST은 상태전달의 목적에 따라 HTTP 메소드를 통해 상태전달이 이루어집니다.
예를들어 34번 게시글을 보고싶다면 GET방식으로
http://posts.com/post/34 라는 URI에 요청을 보내면
서버는 이에 해당하는 페이지로 응답해서 그 게시글을 볼 수 있게 되는 것 입니다.
REST 아키텍처
REST 설계 원칙
위의 설명은 REST를 정말 간략히 설명한 것입니다.
REST를 처음 제안한 Roy Fielding은 REST API가 만족해야할 아키텍처 제약 조건이라고도 하는 6가지의 설계원칙을 소개했습니다.
클라이언트-서버 구조(Client-Server)
클라이언트와 서버 구조의 핵심 원리는 역할의 분리(Separation of Concerns)입니다. 말이 어려워 보이지만 우리는 이미 이 구조를 사용하고 있습니다.
자원을 요청하는 클라이언트와 자원이 있는 서버로 나눈 구조를 따라야 합니다.즉, 서버에서는 비즈니스 로직 처리 및 저장을 책임지고, 클라이언트에서는 요청한 자원을 화면에 나타내는 역할을 책임 집니다.
이 구조를 통해서 사용자 인터페이스의 다양한 플랫폼 간 이식성이 향상되고, 서버 구성요소의 단순화를 통해 확장성 또한 향상될 수 있습니다.
추가로 구성요소들의 의존성이 줄어들어 독립적으로 발전할 수 있게 됩니다.
(프론트와 백엔드가 너무나도 독립적으로 발전해버렸다..)

무상태(Stateless)
무상태란 서버가 클라이언트의 상태를 고려하지 않는 것을 의미합니다. 클라이언트가 서버에 보내는 요청에는 이를 이해하기 위한 모든 정보를 포함되어야 합니다. 즉, 서버는 클라이언트의 컨텍스트(ex. 쿠키, 세션)를 저장해선 안됩니다.
클라이언트가 이전 요청과 동일한 요청을 보냈다고 해도 서버는 이를 별개의 요청으로 판단하고 하나하나 처리만 하면 됩니다. 즉, 이전 요청이 다음 요청의 처리에 연관 되면 안됩니다.
무상태를 통해 3가지의 이점이 생깁니다.
- 가시성(Visibility) 향상 : 하나의 요청만으로 요청 전체의 의미 파악이 가능
- 신뢰성(Reliability) 향상 : 부분적인 오류 발생 시 쉬운 복구
- 확장성(Scalability) 향상 : 요청간 상태를 저장, 관리 하지 않기 때문에 서버는 빠르게 자원을 해제할 수 있고, 구현이 간단해 집니다.
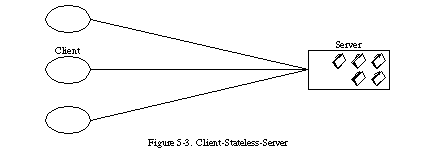
무상태의 단점(trade-off)도 있습니다.
한 요청은 그 요청에 필요한 모든 정보를 가지고 있기 때문에 요청마다 반복적인 데이터(오버헤드)를 포함하여 성능이 저하 될 수 있습니다.
또 일관성 유지가 어렵습니다. 서버가 사용자의 상태를 모르므로, 항상 같은 경험을 제공하기 어려울 수 있습니다.
⇒ 클라이언트의 버전이 서로 다르다면, 각 버전마다 어떻게 동작할지 서버 알 수 없게 되기에(의존적 향상 : 어플리케이션의 동작을 클라이언트의 버전에 의존)
캐시(Cache)
서버의 응답 데이터가 암시적 또는 명시적으로 ‘캐시가능’ 또는 ‘불가능’으로 표시되어야 합니다. 캐시가능한 응답이라면 클라이언트의 캐시는 같은 요청에 대해 해당 데이터를 재사용할 수 있는 권한을 가지게 됩니다.
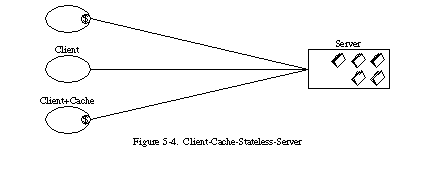
캐시는 반복되는 요청을 줄이거나 생략함으로 서버의 부담이 줄어 대량의 요청을 효율적으로 처리할수 있다.
이는 네트워크 효율성을 높여 응답 지연 시간(latency)을 줄일 수 있습니다.
단, 오래된 캐시가 서버의 최신 데이터와 다르다면 신뢰성을 저하 시킬 수 있습니다.
일관된 인터페이스(Uniform interface)
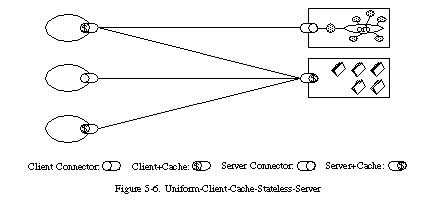
REST라는 아키텍처 스타일이 다른 네트워크 방식과 가장 뚜렷하게 다른 점은, 구성 요소들(예: 클라이언트와 서버)이 서로 소통할 때 '통일된 인터페이스'를 사용한다는 점입니다.
모든 기계가 동일한 콘센트를 쓰게 해서, 플러그를 바꿀 필요 없이 꽂기만 하면 되게 만든 것과 같습니다.
즉, 특정 상황에만 맞게 만드는 게 아니라 모든 구성 요소가 일관된 방식으로 소통할 수록 하여야 합니다. 이러한 원칙을 일반화(generality)라고 합니다.
일관된 인터페이스을 위한 조건들은 따로 존재하므로 이에 대한 설명은 아래에서 추가로 설명하겠습니다.
계층화(Layered System)
계층화는 각 구성요가 자신과 직접 상호작용하는 계층 외에는 볼 수 없도록(관심 없음) 제한 하는 것을 뜻합니다. 이를 통해 전체 시스템의 복잡도를 줄이고, 각 시스템의 독립성을 높입니다.
따라서 계층화 구조에서는 클라이언트가 대상 서버에 직접 연결되었는지, 중간 서버를 통새 연결되었는지 알 수 없습니다.
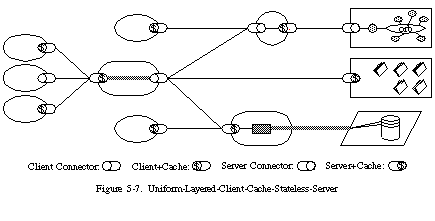
계층화는 여러 목적에서 유용합니다.
- 본 서버는 순수 비지니스 로직만을 수행하고, 중간 서버들이 다른 부가적인 기능(보안, 암호화, 로드밸런싱 등)을 수행하도록 하여 구조의 유연성을 기대할 수 있습니다.
- 중간계층을 통해 연결하므로 보안성을 향상 할 수 있습니다.
- 여러 중간 서버를 두어 로드밸런싱을 수행하여 확장성을 향상 시킬 수 있습니다. (갑작스럽게 트래픽이 증가해도 대응이 가능)
- 계층 구조는 중간 서버를 들려서 통신하기 때문에 오버헤드와 지연이 생겨, 성능의 저하가 생길 수 있습니다. 이를 중간계층의 캐시기능을 통해 상쇄가 가능합니다.
Code-On-Demand(Optional)
COD는 클라이언트가 서버로부터 코드를 받아서 클라이언트에서 실행하는 것을 의미합니다.
이를 통해 클라이언트에 미리 구현해두어야할 기능이 줄어들기 때문에 클라이언트의 구현이 간단해지고, 배포 이후에 기능을 다운로드할 수 있기에 시스템의 확장성이 향상됩니다.
하지만 COD는 시스템의 가시성을 감소시키기 때문에(클라이언트에서 실행되는 코드이기 때문에 이를 실행하지 않는 외부에선 이해하기 어렵다.) 선택적 제약(Optional)으로 간주됩니다.
일관된 인터페이스의 조건
자원에 대한 식별(Identification of resources)
REST에서 자원이란(resourse) 이름을 가질 수 있는 모든 정보입니다. 즉, 특정 시점의 어떤 객체 그 자체가 아니라, 시간에 따라 바뀔 수도 있는 개체 (문서, 날씨, 이미지 etc)들에 대한 개념적 매핑이라고 말 할 수 있습니다.
리소스는 특정 시점의 결과물이 아니라, 그 뒤에 있는 개념이기 때문에 이를 나타내는 변하지 않는 식별자가 필요합니다.
즉 자원의 값이 변하여도 변하지 않는 일관적인 식별자URI가 중요합니다.
좋은 식별자를 통해 우리는 어떠한 객체 그 자체가 아니라 변화가 가능한 개념에 접근 할 수 있게 됩니다.
표현을 통한 리소스의 조작(Manipulation of resources through representations)
REST의 구성요소들은 리소스에 대해 어떠한 행동(조작)을 할 때, 리소스의 현재 상태나 의도된 상태에 대한 표현(representation)을 사용하여 리소스를 조작합니다.
이 표현에는 리소스의 상태에 대한 값과 무엇을 수행할 지에 대한 표현(http method)도 포함되어 있습니다.
즉, 표현을 통해 리소스를 조작하여야지 이를 URI을 통해 조작한다면 일관된 인터페이스가 불가 합니다.
아래와 같이 표현에 자원을 조작할 때 필요한 모든 정보가 담겨 전달 되게 해야한다.
PUT /users/123 HTTP/1.1
Content-Type: application/json
{
"userID" : 123
"email": "new@example.com",
}상태와 동작을 URI로 표현시키면 ❌
/updateUserEmail?userId=123&email=new@example.com자기 서술적 메세지(Self-descriptive message)
자기 서술적 메세지는 이를 이해하는데 필요한 모든 정보를 포함하는 메세지입니다.
이는 무상태(Stateless)와 관련이 있습니다. 앞서 설명했듯이 서버는 클라이언트의 상태에 관심이 없기 때문에 요청마다 그 요청을 설명하는데 필요한 모든 정보를 포함하여 요청해야합니다. 이는 응답도 마찬가지 입니다. (클라이언트도 서버안의 컨텍스트를 모른다.)
자기 서술적 메세지는 일반적으로 다음의 요소들을 포함하고 있다.
- HTTP 메서드 : 동작을 명확하게 표현 (GET, POST, PUT 등)
- URI : 대상이 되는 리소스를 나타낸다.
- 헤더 :
Content-Type,Accept,Authorization등 메세지의 형식, 요구, 제약을 설명 - 본문: 리소스의 상태나 입력 값(JSON, XML형태)
그렇다면 아래는 자기 서술적인 메세지 일까요?
HTTP/1.1 200 OK
Date: Sat, 06 Apr 2025 10:15:00 GMT
Content-Type: application/json
Cache-Control: no-store
{
"id": 123,
"name": "Jane Doe",
"email": "new.email@example.com",
"createdAt": "2022-01-01T10:00:00Z",
"updatedAt": "2025-04-06T10:15:00Z"
}놀랍게도 아니랍니다.
왜냐? 이 응답 메시지는 id , name email 의 값만을 알려주고 있고, id , name email이 정확이 무엇을 뜻하는 지에 대한 정보는 제공하지 않고 있습니다.
id는 사용자 id일수도 있고, 주문번호일 수도 있고
name은 실명인지 닉네임인지
email은 로그인용인지 알림 수신용인지
정확하게 제시하고 있지 않기에 이 응답 메시지는 Self-descriptive하지 않습니다.
그렇다면 Self-descriptive해지려면 어떻게 해야할까?
-
API 명세 문서화(OpenAPI / Swagger 등)
API의 구조, 동작, 데이터 타입 등을 명세화하여 문서화
User: type: object required: - id - name - email properties: id: type: integer description: 사용자 고유 식별자(로그인시 사용) name: type: string description: 사용자의 실명 email: type: string format: email description: 알림 수신용 이메일 주소이런 API 명세 문서를 클라이언트측과 서버측이 공유하여 사용하면 양측이 메세지에 대한 정확한 이해를 할 수 있다.
-
JSON Sechema링크
헤더에
Link를 사용하여 JSON Sechema같은 명세를 링크할 수 있습니다.Link: <https://api.example.com/schema/users.json>; rel="describedby"; type="application/schema+json"이 링크를 통해 클라이언트는응답에 있는 리소스의 명세를 파악할 수 있습니다.
리소스 명세를 링크할때 HAL을 이용할 수도 있는데(좀 더 일반적인 것 같다.), HAL을 이후에 알아볼 HATEOAE에서 자세히 다루겠지만 지금은 링크를 통해 다음에 무엇을 할 수 있는지를 알려주는 것이라고만 이해해봅시다.
이 HAL을 이용해 데이터의 구조와 의미를 설명하는 JSON Schema(OpenAPI와 비슷)를 링크할 수 있습니다.
"describedby": { "href": "https://api.example.com/schemas/user.json", "type": "application/schema+json" }이 부분에서 나는 의문이 있었다. 아니 왜 하필 JSON Schema를 연결하는가 OpenAPI는 왜 안되는가?
⇒ 이는 OpenAPI는 전체 API의 명세를 담고 있어서 지나치게 복잡하기 때문입니다.
JSON Schema는 하나의 리소스 단위로 스키마 문서를 쪼개서 배포할 수 있기 때문에 응답에 포함되어 있는 리소스의 명세만 링크가 가능합니다!
Hypermedia as the engine of application state(HATEOAS)
이걸 뭐라고 번역을 할까 고민하다가 하이퍼미디어 기반 애플리케이션 상태 제어쯤이면 괜찮지 않을까 한다..너무 길어서 이하 HATEOAS라고 하겠습니다.
HATEOAS란 클라이언트 어플리케이션이 서버로 부터 받는 하이퍼미디어 표현(links, form등)을 통해 상태 전이되어야 함을 의미합니다.
HATEOAS를 통해 클라이언트는 표현에 포함된 링크를 통해 다음 동작을 이해하고 진행할 수 있습니다. 즉 서버는 클라이언트가 어떤 상태에 있고, 어디로 이동(상태전이)가 가능한지를 하이퍼미디어 형태로 안내합니다.
위에 자기서술적메세지에서 잠깐 나온 HAL은 HATEOAS을 가능케하기위해 응답 메시지에서 하이퍼링크를 구조화해서 표현하는 JSON기반 포맷입니다.
{
"id": "123",
"name": "Alex",
"email": "alex@example.com",
"_links": {
"self": {
"href": "/users/123"
},
"update": {
"href": "/users/123",
"method": "PUT"
},
"delete": {
"href": "/users/123",
"method": "DELETE"
},
"friends": {
"href": "/users/123/friends"
}
}
}위와 같이 HAL은 _links키워드를 통해 현재 리소스에 관련된 링크들을 나열합니다.
이를 통해 클라이언트는 응답메시지를 통해 현재상태를 알 수 있고, 다음 할 수 있는 행동(상태)을 파악하고 동작 할 수 있습니다.
이러한 HATEOAS이 중요한 이유는 서버가 바뀌어도 클라이언트는 이를 몰라도 된다는 것입니다.
예를들어 특정 동작에 대한 URI가 바뀌었다고 생각해봅시다.
HATEOAS가 만족되지 않는 API를 이용한다면 클라이언트는 URI가 바뀔때마다 이를 파악하고 클라이언트의 코드를 수정해야 합니다.
하지만 HATEOAS가 만족된다면 클라이언트는 서버가 준 링크만 따라가면 되므로 문제가 없습니다.
이러한 이점은 새기능 추가, 다양한 클라이언트의 상황에서도 마찬가지로 적용됩니다.
그래 그래서 이걸 다 지켜?
- CMIS : REST 바이딩이 있습니다! Roy Fielding : ㅋㅋㅋREST바이딩이래 그거 REST아님 (실제로 한말 : “This so-called REST binding is not REST at all.”)
- 마소 : API 스타일 가이드 보러오세요! Roy Fielding : 응 아니야 걍 HTTP임; (“It's not REST. It's just HTTP.”)
- 그 외 (Google APIs, 트위터 등) : RESTful호소자(대부분 RPC)
이 글에서 계속 알아봤듯이 REST를 지켜 RESTful한 API를 구현하는 것은 쉬운 것이 아닙니다. 실제로 Roy아저씨도 이걸 느꼈는지 REST 원칙을 엄격하게 적용하는 것이 항상 최선은 아니며, 시스템의 전체를 통제할 수 있는 상황이라면 REST를 따지는 것이 시간 낭비일 수 있다고 언급한 바 있습니다.
그래서 우리도 RESTful에 너무 집착하지 말고 개발하는 시스템에 적합하고 이득이 될만한 부분을 차용하여 적용하는 것이 적합하다고 생각합니다.
마치며
사실 이글에 REST에 대한 간략한 개념을 정리할 예정이었습니다. 하지만 알아보면 알아볼 수록 블로그들마다 설명하는 것이 추상적이고 URI에 규칙? 같은걸 소개하고 있었다. 혼란스러워하다가 그냥 REST만든 사람의 설명을 보는게 정확할 거 같아서 Roy아저씨의 REST논문을 토대로 이 글을 작성하게 되었다.(물론 번역기를 십분 활용했다.) 영문으로 된 아주 긴 논문을 이해하는 것은 역시 생각보다 힘들었지만 이곳에 답이 있었다. RESTful하다는 것은 어떠한 정형화된 법칙을 따라야하는 것이 아니라 제시된 여러 제약사항(개념이라고 하고싶다)을 만족하는 것임을 알게 된거 같다.
이번 경험을 통해서 학습을 할때 특히 어떠한 개념을 학습할때는 공식문서가 느리지만 제일 빠른 길인 것 같다. 가장 정확하다는 확신이 서고, 의심이 생기지 않는다. 블로그같은 것을 통해 학습을 할땐 이게 맞는 말인지 항상 의심하고 다른거 찾아보다가 의심하고… 오히려 시간이 낭비되는거 같다.
데브코스 강사님이 항상 공식문서와 친해지라고 한 이유를 알 것 같다. 앞으론 영 읽는게 힘들지만 공식문서를 먼저 찾아야 겠다. 추가호 학습 과정에서 새롭게 알게된 OpenAPI(Swagger)를 학습을 해봐야 겠다.
참조
REST-API란[hjkim]
REST API에 대하여 (feat. 로이 필딩 논문)[여행하는 개발자 해서미]
Architectural Styles and the Design of Network-based Software Architectures[Roy Thomas Fielding]
Untangled(Roy Fielding 블로그
