
어플리케이션은 DB를 사용하여 데이터를 보관 및 관리한다. 왜 DB를 사용해야 할까? 당연히 데이터를 영구적으로 보관하고 싶기 때문이다. DB가 없다면 어플리케이션이 종료되면 그 동안 생성되었던 모든 데이터는 사라진다.
데이터를 DB에 보관하여 오랫동안 저장되게 하는 것을 영속성(Persistence)라고 한다.
이는 앞으로 자주 등장할 단어이다. 좀 더 심오한 뜻이 있을 것도 같지만 영속성은 데이터가 휘발되게 하지 않고, 오랫동안 존재하도록 하는 것 이라고 이해하면 될 것이다.
그렇다면 우리는 데이터의 영속성을 위해 우리의 어플리케이션에 DB를 연결시켜주어야한다!
만약 당신이 Oracle을 연결해서 사용하고 있다고 가정해보자 근데 세상에 주식이 떨어져서 OracleDB를 지속할 돈이 부족하다. 그래서 당신은 MySQL로 DB를 바꾸려한다.
이런 이런 세상에 너무나 번거롭다. 연결에 관한 모든 것을 당신은 바꿔야한다. 앞으로 또 이런 일이 있을 때 당신은 이짓을 또하고 싶진 않을테다.
이를 위해 JAVA생태계에선 JPA를 사용한다. JPA를 제대로 이해하기 위한 개념, 기술들을 몇개의 글로 나누어 정리할 생각이다. 이번 글은 이해를 위한 몇가지 개념들과 JDBC에대해서 알아보겠다.
데이터베이스 커넥터
소프트웨어의 데이터를 보관하려면 DB와 연결 및 통신을 할 수 있어야 한다. 이를 가능케하는 것이 데이터베이스 커넥터이다.
데이터베이스 커넥터는 어플리케이션에서 작성한 SQL쿼리를 DB로 전달함으로써 데이터를 저장 및 관리하게 해준다.
데이터베이스 커넥터는 크게 두가지 요소로 구성되는데 드라이버(Driver)와 클라이언트 라이브러리(Client Library)이다.
드라이버(Driver)
드라이버는 DB와 실제로 통신하며, SQL문을 전송하고 결과를 받아오는 역할이다. 각 DB마다 통신규약이 다르기 때문에 DB마다 다른 드라이버를 사용한다.
클라이언트 라이브러리(Client Library)
드라이버는 저수준에서 DB와 연결되어 통신하기 때문에 개발자가 이를 직접 이를 다루기엔 복잡하다.
클라이언트 라이브러리는 이를 추상화하여 개발자가 쉽게 DB와 상호작용할 수 있게하는 고수준 API를 제공한다. 즉, 클라이언트 라이브러리는 드라이버를 추상화한 계층이다.
우리는 이를 이용해서 쉽게 DB와 연결할 수 있다.
그런데 보통 어플리케이션 특히 웹에서는 수많은 요청으로 인해 데이터가 수시로 바뀐다. 그렇다면 우리는 이 DB와의 연결을 어떻게 관리해야 좋을까?
- 계속 연결을 지속한다
- 데이터가 필요할 때마다 연결을 하고 작업이 끝나면 연결을 끊는다.
둘 다 뭔가 낭비가 심해보인다. 그렇다면 어떻게 하면 효율적으로 연결(Connection)을 관리할 수 있을까.
바로 커넥션 풀링(Connection Pooling)을 사용하는 것 이다.
커넥션 풀링(Connection Pooling)
Pool이 무엇인가. 수영장, 연못… 무언가 담겨있는 것정도로 이해가 되지 않는가?
우리는 약수터를 생각해보자. 어르신들이 약수터에 물마실라고 바가지를 들고다니는가? 바가지는 약수터에 둥둥 떠 있고, 약숫물이 필요할때만 사용하고 다시 띄어놓는다.
그렇다 커넥션 풀링도 비슷하다.
즉, 연결들을 미리 생성해두고 연결이 필요할 때마다 이를 할당해서 사용 후 반환하여 재사용이 가능케 하는 방식이다.
이 방식은 연결 생성 및 폐기에 따른 메모리 손해(오버헤드)를 줄여주고, 만약 폭발적인 연결수가 필요한 상황에서 모든 연결을 생성하면 자원고갈이 일어 날 수 있지만 커넥션 풀링은 그냥 좀 기다리면 된다. (콘서트 예매 대기열이 바로 이런 상황이다.)
JDBC(Java Database Connectivity)
글 시작에서 제시한 상황이 기억나는가.
어플리케이션에 이미 연결한 DB를 다른 DB로 바꿔야하는데, DB들은 접속방식과 SQL문법이 각자 다르다. 너무 피곤한 작업일 것 이다.
이를 극복할 수 있도록 하는 것이 JDBC이다.
JDBC는 다양한 DB들과의 연결을 일관된 방식으로 처리할 수 있는 표준 인터페이스(API)를 제공한다.
위에서 설병한 클라이언트 라이브러리 자바판이라고 생각해도 될 것 같다.
JDBC는 각 DBMS에 맞는 JDBC드라이버를 통해 DB와 연결하기 때문에 DB를 바꿔야 한다면 이 JDBC드라이버만 갈아끼우면 된다. 이러한 특성은 여러 DB을 동시에 연결하여 사용할 수 있게도 한다.
아니; 그럼 연결방식은 드라이버를 바꾸면 된다쳐도 SQL은 어떻게 바뀌어 적용되는거임?
니 말이 맞음. 못바꿈. SQL이 다 비슷비슷해서 운좋으면 그냥 써도 되는 SQL문이 있을 수 있겠지만 다른게 있으면 님이 바꿔야함;; 그래서 JPA가 있는거임 기다리셈
JDBC실습
JPA모른다고 DB연결 못하는 거 아니다. 추후에 불편한 상황이 생길 수 있지만 JDBC만으로도 충분히 DB와 통신하여 데이터를 관리할 수 있다. 이번엔 JDBC를 사용해서 앞선 개념들을 코드로 확인해보자.
@Slf4j
public class JdbcConnection {
//연결 정보를 상수로 저장해 놓는다.
public static class MysqlDbConnectionConstant {
public static final String URL = "jdbc:mysql://localhost:3306/jdbc_exam";
public static final String USERNAME = "dev_bae";
public static final String PASSWORD = "mypassword";
}
public static Connection getConnection() throws SQLException {
//DriverManager로 Connection객체를 생성 후 연결한다.
Connection conn = DriverManager.getConnection(
MysqlDbConnectionConstant.URL,
MysqlDbConnectionConstant.USERNAME,
MysqlDbConnectionConstant.PASSWORD
);
log.info("Connection = {}", conn);
return conn;
}
}@Data
@RequiredArgsConstructor
@AllArgsConstructor
public class Member {
private int id;
private String username;
private String password;
}@Slf4j
public class JdbcExample {
@Test
@DisplayName("JDBC Insert")
void insert() throws Exception {
// 새로운 Member객체를 생성한다. 이 정보가 DB에 들어가게 된다.
Member member1 = getMember("bae","very_hard_password");
Member member2 = getMember("admin","super_password");
// DB에 전송할 SQL문을 작성한다. 따로 메소드로 빼서 사용하면 더 편하다.
String sql = "INSERT INTO users (username, password) values ('%s', '%s')"
.formatted(member1.getUsername(), member1.getPassword());
String sql2 = "INSERT INTO users (username, password) values ('%s', '%s')"
.formatted(member2.getUsername(), member2.getPassword());
//Connection객체를 생성, DB와 연결한다.
Connection conn = JdbcConnection.getConnection();
//Statement: SQL을 실제로 실행하는 객체이다
//사실 이는 보안상 이슈가 있다. 이는 아래에서 다루도록 하겠다.
Statement stmt = conn.createStatement();
//exeuteUpdate를 통해 SQL을 실행한다. exeuteUpdate는 변경된 row수가 반환된다.
int rowsAffected = stmt.executeUpdate(sql);
log.info("rowsAffected = {}", rowsAffected);
int rowsAffected2 = stmt.executeUpdate(sql2);
log.info("rowsAffected2 = {}", rowsAffected2);
}
private static Member getMember(String username, String password) {
return new Member(0,username,password);
}
}설레는 마음으로 실행시켜보면

log와 함께 정상적으로 실행된다.
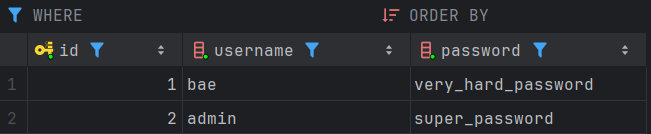
DB에도 제대로 INSERT된 걸 확인할 수 있다.
Statement는 위험하다 : SQL Injection
사실 Statement 아주 위험한 취약점을 가지고 있다. 바로 SQL Injection에 아주 무기력하다.
Statement는 입력값을 직접 SQL에 삽입하기 때문인데 코드로 보는 것이 이해가 빠를 것이다.
@Test
@DisplayName("SQL Injection")
void injectTest() throws Exception {
Member hacker = getMember("admin","' or '' = '");
String sql = "SELECT * FROM users WHERE username = '%s' AND password = '%s'".
formatted(hacker.getUsername(), hacker.getPassword());
Connection conn = JdbcConnection.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
log.info("rs.getString(username) = {}", rs.getString("username"));
log.info("rs.getString(password) = {}", rs.getString("password"));
}
}
}위 코드의 결과를 예상해보자.
username에는 admin이 입력되었고 password에는 이상한 문자열이 삽입되있다. 상식적으로 아무런 결과값을 반환하면 안된다.
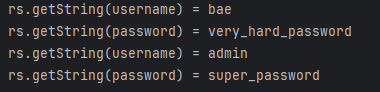
어머나 세상에 테이블에 존재하는 모든 계정 정보가 반환되었다.
왜 이런 일이 생기는 걸까? 위의 입력값을 삽입한 SQL문을 보자.
SELECT * FROM users WHERE username = 'admin' AND password = '' or '' = ''SQL에서 AND 보다 OR의 우선순위가 낮음을 인지하고 이를 보기 좋게 변형하면
( (username = 'admin' AND password = '') OR ('' = '') )이렇게 된다. 이러면 앞의 AND문이 거짓이라도 위의 '' = '' 가 무조건 참이기에 이 SQL문은 테이블의 모든 행을 가져와 버린다.
정보보안학을 전공한 나로써 용서가 되지 않는다. 이를 어떻게 해결할 수 있을까?
바로 PreparedStatement 을 사용하는 것 이다.
PreparedStatement
PreparedStatement 는 입력값을 자동으로 이스케이프 처리해주기 때문에 SQL Injection을 방어할 수 있다.
PreparedStatement 은 SQL문안에 ?을 삽입하여 파라미터를 설정할 수 있다.
"SELECT * FROM users WHERE username = ? AND password = ?";?에 값을 집어넣으려면 setString() 등을 사용한다.
두개의 매개변수를 갖는데 첫번째 매개변수는 ?의 위치 (1부터 시작)
두번째 배개변수에는 집어넣을 값을 넣는다.
@Test
@DisplayName("PreparedStatement")
void preparedStmt() throws Exception {
Member hacker = getMember("admin","' or '' = '");
String sql = "SELECT * FROM users WHERE username = ? AND password = ?";
Connection conn = JdbcConnection.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, hacker.getUsername());
pstmt.setString(2, hacker.getPassword());
ResultSet rs = pstmt.executeQuery();
if (rs.next()) {
log.info("rs.getString(username) = {}", rs.getString("username"));
log.info("rs.getString(password) = {}", rs.getString("password"));
}else{
log.info("rs.getString(username) = null");
}
}
아까와 달리 아무런 값을 불러오지 못한다.
위와 같이 SQL Injection방지하고, 심지어 성능도 좋으니(쿼리캐시) 무조건 prepareStatement을 사용하는 걸 많이들 추천한다.
Connection Pooling(HikariDataSource)
위와 같이 연결이 필요할때 연결을 생성하고 폐기하는 식은 비효율적이므로 Connection Pooling을 사용한다고 위에서 설명했다. 이번엔 이를 어떻게 사용하는지를 코드로 알아보자
@Test
@DisplayName("히카리풀에서 멀티쓰레드가 연결 요청하는 테스트")
void hikari_multiThread() throws Exception {
//히카리데이터소스 생성
HikariDataSource hikari = new HikariDataSource();
//커넥션풀의 최대 커넥션 수 설정
hikari.setMaximumPoolSize(2);
//접속 정보 설정
hikari.setJdbcUrl(JdbcConnection.MysqlDbConnectionConstant.URL);
hikari.setUsername(JdbcConnection.MysqlDbConnectionConstant.USERNAME);
hikari.setPassword(JdbcConnection.MysqlDbConnectionConstant.PASSWORD);
String sql = "insert into users (username, password) values(?,?)";
//각 쓰레드가 실행할 함수 - 히카리풀에서 커넥션을 불러오고 로그, SQL실행 후 반납 로그
BiConsumer<String, String> multiConn = (user, password) -> {
try{
Connection conn = hikari.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
log.info("{} conn 획득 = {}", Thread.currentThread().getName(), conn);
ps.setString(1, user);
ps.setString(2, password);
ps.executeUpdate();
Thread.sleep(3000);
ps.close();
conn.close();
log.info("{} conn 반환 = {}", Thread.currentThread().getName(), conn);
} catch (Exception e) {
throw new RuntimeException(e);
}
};
Thread thread1 = new Thread(() -> multiConn.accept("test1", "test1_password"),"Thread-1");
Thread thread2 = new Thread(() -> multiConn.accept("test2", "test2_password"),"Thread-2");
Thread thread3 = new Thread(() -> multiConn.accept("test3", "test3_password"),"Thread-3");
thread1.start();
thread2.start();
thread3.start();
//로그 확인을 위해 스레드 종료를 기다림..
thread1.join();
thread2.join();
thread3.join();
}HikariDataSource은 HikariCP라는 커넥션 풀을 사용하는 객체이다.
이를 이용해 커넥션을 생성해놓고 커넥션이 필요할 때마다 꺼내 사용하고 작업이 끝나면 이를 커넥션풀에 다시 반납한다.
위 코드는 최대 2개의 커넥션을 가지게 설정되었고, 이를 3개의 쓰레드로 동시에 사용해보면 아래와 같은 로그를 확인 할 수 있다.

로그의 com.mysql.cj.jdbc.ConnectionImpl@1f9f798c 부분을 보면 쓰레드2가 46db63cf연결을 반환한 뒤 쓰레드 3이 같은 46db63cf을 재사용하는 것을 확인 할 수 있다.
HikariProxyConnection은 다 다른데? 이건 뭐임?
HikariProxyConnection은 연결 즉 ConnectionImpl을 감싸는 프록시임.
님이 dataSource.getConnection()하면 HikariProxyConnection이게 반환되는 거임.
근데 이 프록시커넥션은 요청마다 새롭게 생성됨. 그래서 저 로그에서 프록시는 다 다른객체임.
사실close를 하는데 끊어지는게 아니고 반납한다는게 이상하지 않음??
사실은 너가 연결을 컨트롤하는게아니고 저 프록시가 해줌. 임마는 너가close()를 하면 는 커넥션을 끊는게 아니고 커넥션 풀로 다시 반환하는걸 하는게 이 녀석임.
그 외에도 너가 이미 닫힌 커넥션을 사용하는 폐급짓을 막아주고 커넥션 사용 시간을 측정, 어떤 스레드가 어떤 커넥션을 얼마나 썼는지 등을 하는 아주 휼룡한 커넥션의 비서임.
getGeneratedKeys / ResultSet
이번엔 getGeneratedKeys과 ResultSet을 코드로 간단하게 알아보겠다.
DB와 연결해서 테이블의 로우를 새로 INSERT했다고 생각해보자. 근데 테이블의 id에 auto_increment이 설정되어있다면 이 id값을 어떻게 가져 올 수 있을까?
이때 사용가능한 것이 getGeneratedKeys 이다.
- getGeneratedKeys
@Test @DisplayName("getGeneratedKeysTest") void getGeneratedKeysTest() throws Exception { String spl = "INSERT INTO users (username, password) values(?,?)"; try( Connection connection = hikari.getConnection(); //getGeneratedKeys을 사용하려면 ****Statement.RETURN_GENERATED_KEYS을 입력해야 한다. PreparedStatement pstmt = connection.prepareStatement(spl, Statement.RETURN_GENERATED_KEYS)){ pstmt.setString(1,"ilikeJDBC"); pstmt.setString(2,"imaLiar"); //executeUpdate는 SQL이 반영된 row수만 반환한다. pstmt.executeUpdate(); //getGeneratedKeys를 통해 마지막 id값을 가져온다. ResultSet rs = pstmt.getGeneratedKeys(); while (rs.next()){ //DB가 생성한 키 값만 담은 ResultSet리턴하므로 칼럼인덱스를 이용해 꺼낸다. int findByColIdx = rs.getInt(1); log.info("findByColIdx = {}", findByColIdx); } }catch(SQLException e){ throw new RuntimeException(e); }
왜
rs.getInt("id")는 안됨?
JDBC의 getGeneratedKeys()에 “DB가 생성한 키 값만” 담은 ResultSet을 리턴함. 즉 칼럼명이 없는 표를 주면 어떻게 접근할꺼임? 인덱스로 접근할 수밖에 없음.
ResultSet은 쿼리 실행 후 반환된 결과 행(Row)들을 저장한다. next()을 통해 다음 행으로 이동한다.
- ResultSet
@Test @DisplayName("ResultSetTest") void resultSetTest() throws Exception { String spl = "SELECT * FROM users"; try( Connection connection = hikari.getConnection(); PreparedStatement pstmt = connection.prepareStatement(spl, Statement.RETURN_GENERATED_KEYS)){ //실행 결과를 표형식으로 가져온다. ResultSet resultSet = pstmt.executeQuery(); //next로 행이동, 행이없으면 false를 반환한다. while (resultSet.next()){ String id = resultSet.getString("id"); String username = resultSet.getString("username"); log.info("id = {}", id); log.info("username = {}", username); } }catch(SQLException e){ throw new RuntimeException(e); } }
근데 왜 아까부터 close()안함 폐급임?
try-with-resources임. 예외가 발생하든 안하든 사용한 자원을 자동으로 닫아줌. 처음봐서 한번 써봤음.
트랜잭션
그대는 트랜잭션을 아는가. 대충 안다고 생각하고 설명하겠다. 트랜잭션에는 원자성이라는 특징이 존재한다.
원자성이랑 한 트랜젝션을 수행하면 이는 실행이 완전히 되거나 아예 실행이 안되야한다는 걸 뜻한다.
void logic() {
int result = repository.a(request);
repository.b(result);
}대충 이런 로직이 서비스단에 있다고 생각해보자 이 로직은 하나의 트랜잭션으로 묶어야한다.
그런데 a()만 성공하고 b()늘 실패한다면 a()결과만 반영되고 b()의 결과는 반영되지 못한다.
트랜잭션의 원자성을 맞족하지 못하게 된다.
그러므로 중간에 예외가 발생하면 logic의 모든 로직을 롤백해야한다.
그런데 repository에서 각 함수를 다른 Connection으로 수행하면 이를 만족하기 어렵다.
즉 하나의 로직에서는 하나의 Connection이 사용되어야 트랜잭션의 원자성을 만족할 수 있다.
지금까지는 dataSource.getConnection();이런식으로 커넥션을 꺼내왔으므로 작업마다 다른 커넥션이 사용됐다. 그렇다면 어떻게 하면 좋을까
이를 순수 JDBC로 해결하려면 DataSource단위로 오토커밋을 끄고(dataSource.setAutoCommit(false); : 이것도 hikari만 된다.)
모든 작업이 끝나면 commit하는 방법이 있을 거 같다.. 하지만 우리에겐 스프링이 있다.
스프링이 제공하는 DataSourceUtils과 PlatformTransactionManager 이용해서 안전하고 편하게 트랜잭션을 적용할 수 있다.
- DataSourceUtils
private Connection getConnection(){ return DataSourceUtils.getConnection(hikari); }DataSourceUtils.getConnection()을 사용하면 현재 트랜잭션이 있으면 이미 사용했던 커넥션을 반환한다. 아니면 새로운 커넥션을 반환한다. 즉, 한 트랜잭션 안에서 하나의 커넥션을 사용할 수 있도록 한다.private void close(Connection conn, Statement stmt, ResultSet rs){ JdbcUtils.closeResultSet(rs); JdbcUtils.closeStatement(stmt); DataSourceUtils.releaseConnection(conn, hikari); }DataSourceUtils.releaseConnection()도 위의 논리와 같이 재사용을 위해 커넥션을 재우는게(idle) 아니라 트랜잭션 안이라면 이를 보류한다.
JdbcUtils.closeStatement(stmt)는stmt.close()는 뭔 차이임?
JdbcUtils.closeStatement()내부적으로 이렇게 생김public static void closeStatement(@Nullable Statement stmt) { if (stmt != null) { try { stmt.close(); } catch (SQLException ex) { logger.trace("Could not close JDBC Statement", ex); } catch (Throwable ex) { logger.trace("Unexpected exception on closing JDBC Statement", ex); } } }그냥 stmt가 null이어도 짜증나는 NPE 안터지고 무시하고 중간에 예외생기면 그냥 삼켜버리고(안 던짐) 로그남기는 기능 가지고 있음.
- PlatformTransactionManager
위와같이 사용할 수 있는데 하나씩 뜯어서 알아보자TransactionStatus transaction = platformTransactionManager.getTransaction( new DefaultTransactionDefinition() );platformTransactionManager는 스프링에서 제공하는 트랜잭션 관리자 인터페이스이다. 이 녀석이 실제로 트랜잭션을 시작, 커밋, 롤백하는 주인공이다.
getTransaction는 트랜잭션이 지금 있는지 판단후 트랜잭션을 시작한다. 기존 트랜잭션이 있으면 기존 트랜잭션을 사용한다. 이 메소드의 결과로 TransactionStatus 를 반환한다.DefaultTransactionDefinition은 트랜잭션의 정책을 정의한다. 항목으로는 PropagationBehavior, IsolationLevel, Timeout, ReadOnly이 있다. 아무 설정을 안하면 기본정책이 적용된다.TransactionStatus는 현재 트랜잭션의 상태를 나타내고 제어할 수 있는 스프링의 트랜젝션 핸들러다. 주요 기능으로는 isNewTransaction(), isCompleted(), setRollbackOnly(), isRollbackOnly()등이 있다.
위를 통합하여 사용하면 트랜잭션이 실제로 적용되는지 테스트해봅시다.
repository에 DataSourceUtils적용되있으나 코드로는 서비스만 보도록 하자.(너무 길다.)
레포지토리에는 save()와 update()가 구현되어 있다.
public void transactional(Member member, boolean exception) {
TransactionStatus transaction = platformTransactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
Member saved = repository.save(member);
if(exception){
throw new SQLException();
}
String newPassword = "Updated";
repository.update(saved, newPassword);
platformTransactionManager.commit(transaction);
log.info("커밋되었습니다.");
} catch (SQLException e) {
log.info("롤백됩니다.");
platformTransactionManager.rollback(transaction);
}
}위 코드에서 exception이 false로 들어온다면 정상적으로 save와 update가 적용 될 것 이다.
하지만 save()를 수행하고 중간에 예외가 발생한다면 어떻게 될까. 트랜잭션을 적용하지 않았다면 save만 적용이 되고 update는 적용이 되지않아 원자성을 만족할 수 없다.
@Test
@DisplayName("transaction_test")
void transactional() throws Exception {
Member member = new Member(null, "TransacionTest", "Original");
boolean exception = true;
service.transactional(member,exception);
}실제로 위 코드처럼 중간에 예외를 터트려보면

롤백된다는 로그가 찍히고
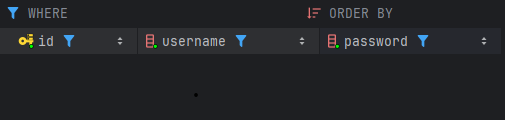
실제로 DB상으로도 save()도 적용이 안되고 롤백되어 버린걸 확인 할 수 있다.
