1. 웹 스크래핑 사전 준비 (파이참설치필요)
네이버에서 영화제목, 랭킹, 평점을 불러온다. pycharm 에서 beautifulsoup4 라이브러리 설치한다. 앞서 requests 라이브러리도 설치했었다.
requests, beautifulsoup4 를 아래와 같이 import 해온다.
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')2. 위 code 의미
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
get 방식으로 해당 주소로 (크롤링할 페이지) 간다는 의미이며 headers 를 포함해야 크롤링을 할 수 있다고 함.
아래 soup = beautifulSoup 을 주석처리 해놓고 print(data) 해보면 response 200 이 나온다. 이게 뭐징?
다시, print(data.text) 하면 페이지의 html 태그들이 그대로 나온다.
페이지의 영화이름, 평점의 html 을 가져 올 거라서 그렇다.
soup = BeautifulSoup(data.text, 'html.parser') 의 의미는 무엇일까?
파싱은 크롤링과 같은 말이라 한다. 검색을 해보니 그 뜻도 어려워서 그냥 뭔가 가져온다는 의미로 일단 받아 들인다. 암튼 html.parser 를 통해서 soup 이라는 것으로 받는다 라는 의미라고 한다.
print(soup) 해보면 아까 html 코드 나오는 거랑 별반 차이 없어보이지만 파이썬 코드에서 soup 을 이용해 원하는 것을 찾을 수 있게 해준다. 마치 구글 크롬 개발자 도구가 검색과 변경을 용이하게 해주는 것처럼..
3. 시작
일단 먼저 뭘 가져올까 보자. 영화 제목만 가져와 보자.
공부하면서 느꼈는데, 구글 개발자 도구를 잘 사용해야 된다고 생각한다. 구글개발자 도구에서 요소를 선택할 포인터를 눌러 놓고 네이버 영화 페이지에서 영화 제목 쪽을 포인터로 가리켜서 눌러 보면 제목 쪽의 태그와 클래스 명이 나온다.
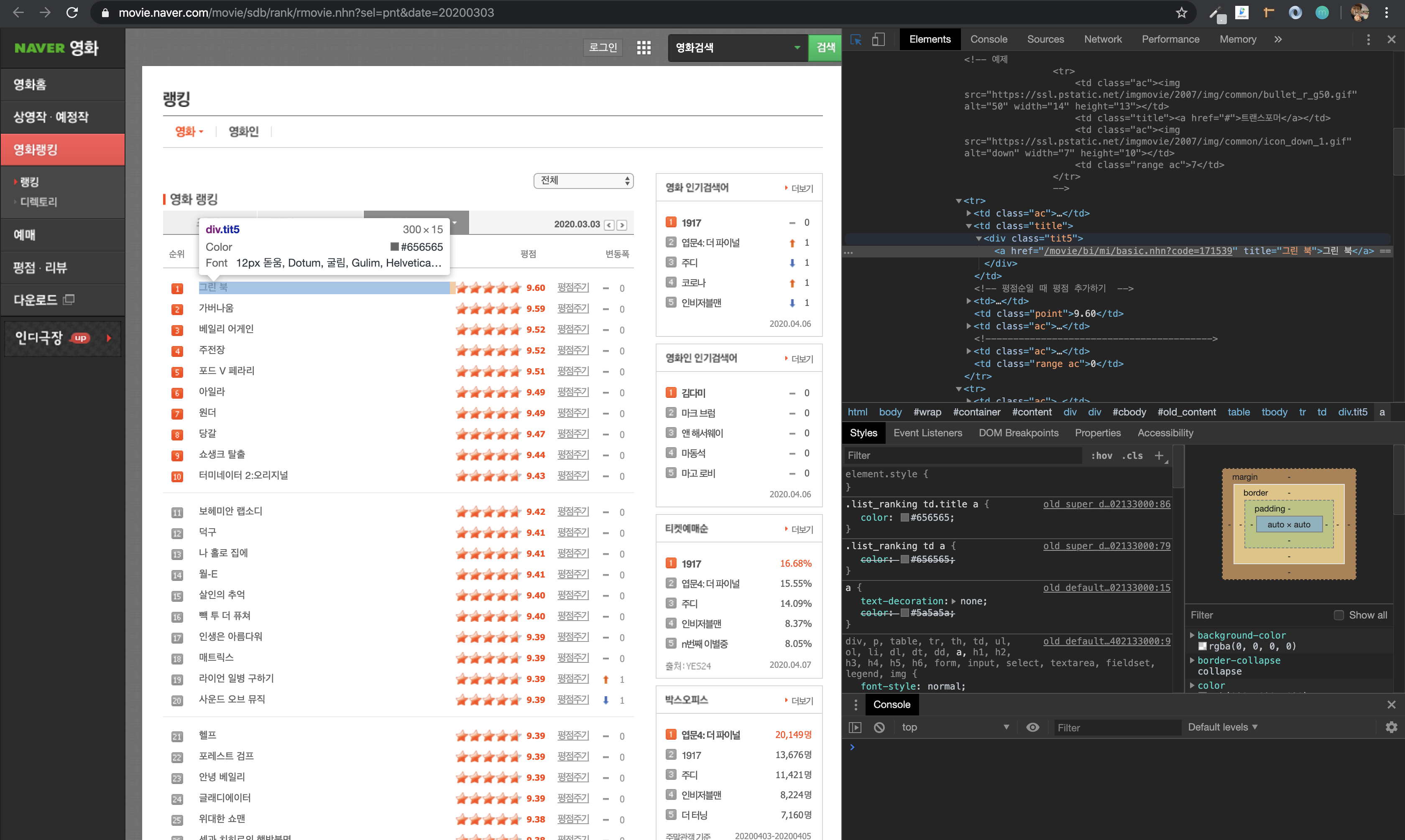
3-1. 영화제목에 연결된 html 코드 div.tit5
음 이제 이거를 어떻게 가져올까? 아까 설치한 라이브러리 soup 을 이용한다.
soup.select('div.tit5')
# soup 이 선택하게 한다. 무엇을? 구글 개발자 도구가 가리킨 영화제목의 태그와 클래스명을!이제 이것을 movie_info 에 넣어주자.
movie_info = soup.select('div.tit5')그리고 movie_info 가 어떻게 나오는지 print 를 해보자. 자바스크립트는 console.log 를 하는 습관을 들이듯 파이썬도 print() 로 확인을 자주 해줘야 한다.
print(movie_info) 하면 나오는 결과는,
[<div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=171539" title="그린 북">그린 북</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=174830" title="가버나움">가버나움</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=144906" title="베일리 어게인">베일리 어게인</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=179518" title="주전장">주전장</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=181710" title="포드 V 페라리">포드 V 페라리</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=169240" title="아일라">아일라</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=151196" title="원더">원더</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=157243" title="당갈">당갈</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=17421" title="쇼생크 탈출">쇼생크 탈출</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=10200" title="터미네이터 2:오리지널">터미네이터 2:오리지널</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=156464" title="보헤미안 랩소디">보헤미안 랩소디</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=154667" title="덕구">덕구</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=10016" title="나 홀로 집에">나 홀로 집에</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=69105" title="월-E">월-E</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=35901" title="살인의 추억">살인의 추억</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=10002" title="빽 투 더 퓨쳐">빽 투 더 퓨쳐</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=22126" title="인생은 아름다워">인생은 아름다워</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=24452" title="매트릭스">매트릭스</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=18988" title="라이언 일병 구하기">라이언 일병 구하기</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=10102" title="사운드 오브 뮤직">사운드 오브 뮤직</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=82432" title="헬프">헬프</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=17159" title="포레스트 검프">포레스트 검프</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=181700" title="안녕 베일리">안녕 베일리</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=29217" title="글래디에이터">글래디에이터</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=106360" title="위대한 쇼맨">위대한 쇼맨</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=32686" title="센과 치히로의 행방불명">센과 치히로의 행방불명</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=66463" title="토이 스토리 3">토이 스토리 3</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=136900" title="어벤져스: 엔드게임">어벤져스: 엔드게임</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=35939" title="클래식">클래식</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=163788" title="알라딘">알라딘</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=92125" title="헌터 킬러">헌터 킬러</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=10048" title="죽은 시인의 사회">죽은 시인의 사회</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=161850" title="아이 캔 스피크">아이 캔 스피크</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=17170" title="레옹">레옹</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=134899" title="동주">동주</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=31796" title="반지의 제왕: 왕의 귀환">반지의 제왕: 왕의 귀환</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=18847" title="타이타닉">타이타닉</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=31162" title="캐스트 어웨이">캐스트 어웨이</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=12482" title="여인의 향기">여인의 향기</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=34324" title="집으로...">집으로...</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=17541" title="굿바이 마이 프랜드">굿바이 마이 프랜드</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=18543" title="서유기 2 - 선리기연">서유기 2 - 선리기연</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=130850" title="주토피아">주토피아</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=189111" title="두 교황">두 교황</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=19079" title="굿 윌 헌팅">굿 윌 헌팅</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=37886" title="클레멘타인">클레멘타인</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=147092" title="히든 피겨스">히든 피겨스</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=73372" title="세 얼간이">세 얼간이</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=14450" title="쉰들러 리스트">쉰들러 리스트</a>
</div>, <div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=76667" title="울지마 톤즈">울지마 톤즈</a>
</div>]3-2. 개발자 도구의 사용
위의 html 이 좀 길긴 하지만, 잘 보면 대괄호 [ ] 로 묶여 있는 배열 이라는 것을 알 수 있다. 반복문 for 를 통해 movie 가 배열에서 순서대로 값을 가져오도록 하자.
for movie in movie_info:
print('*'*60) >>>>> 제목 하나하나 반복을 하면서 구분선을 * 로 표기해준다.
print(movie)
개발자 도구를 가서 보면,
아까 진행한 제목의 한 단위가 되는 태그는 < tr > 이라는 것을 알 수 있고 거슬러 보면 < tbody > 가 있고 제일 상위에 < table > 태그가 클래스명을 가지고 있는 것을 볼 수 있다.
앞서 제목만 가져왔지만, 평점도 가져오고 이것저것 가져올거니까 먼저 통으로 가져오겠다 라는 것이다.
제목 말고도 다른 정보들을 포함시키기 위해서!
이제 개발자 도구를 통해 < tr > 의 경로를 파악할 수 있다는 거다.
그런데 개발자도구에서 입력을 해서 바로 확인하던데 내가 그 부분이 약간 미흡하다.
일단 그러면 경로가,
table.list_ranking > tbody > tr 이라는 것을 알게 되었다.
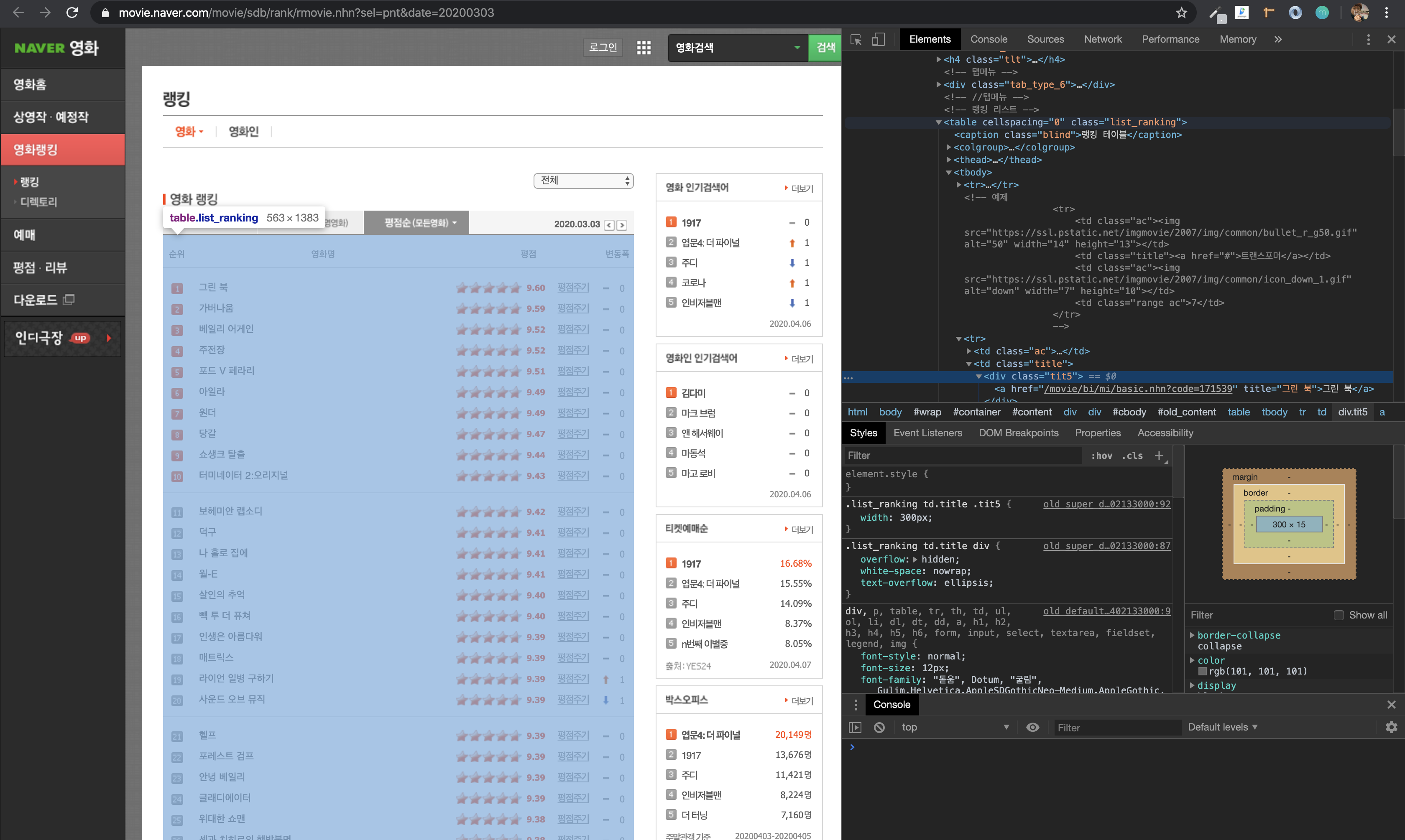
3-3. table 의 정보 가져온 뒤 제목과 평점만 골라빼기
경로를 아까 진행한 soup.select()의 괄호 안에 넣어주고 다시 print!
movie_info = soup.select('table.list_ranking > tbody > tr')
for movie in movie_info:
print('*'*60)
print(movie)오만 가지 태그 html 들이 다 튀어나온다.
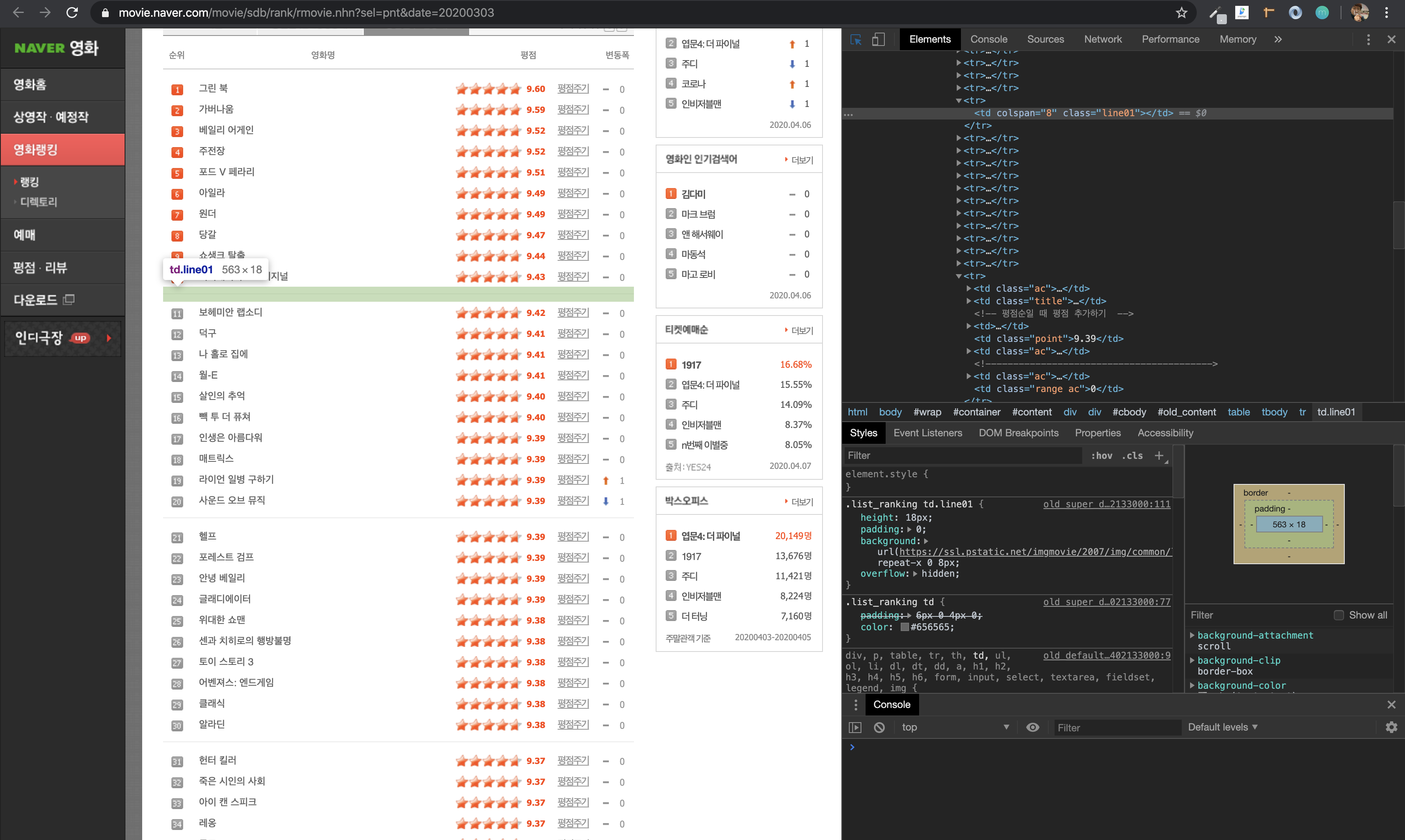
<tr>
<td class="ac"><img alt="02" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r02.gif" width="14"/></td>
<td class="title">
<div class="tit5">
<a href="/movie/bi/mi/basic.nhn?code=174830" title="가버나움">가버나움</a>
</div>
</td>
<!-- 평점순일 때 평점 추가하기 -->
<td><div class="point_type_2"><div class="mask" style="width:95.9000015258789%"><img alt="" height="14" src="https://ssl.pstatic.net/imgmovie/2007/img/common/point_type_2_bg_on.gif" width="79"/></div></div></td>
<td class="point">9.59</td>
<td class="ac"><a class="txt_link" href="/movie/point/af/list.nhn?st=mcode&sword=174830">평점주기</a></td>
<!----------------------------------------->
<td class="ac"><img alt="na" class="arrow" height="10" src="https://ssl.pstatic.net/imgmovie/2007/img/common/icon_na_1.gif" width="7"/></td>
<td class="range ac">0</td>
</tr>여기서 나는 영화 제목하고 평점만 크롤링 해올 것임. 그러면 아까 처럼 제목의 태그.클래스
를 파악해야 겠다!
위를 살펴보면 영화제목은 a 태그에, 평점은 td 태그에 있음을 알 수 있다.
그럼 이 요소를 soup 으로 select 해서 print 해 보면 되겠구나! 다만 print(movie)는 이제 바꾸어야 겠네?
3-4. 제목 요소 가져오기
반복문 안에서 이제 전체 오만 요소가 아닌 제목 요소만 돌게 해주자.
movie.select('a')
# 앞서 정의한 movie 에서 영화제목을 가지고 있는 'a' 태그를 선택하고,
title_el = movie.select('a')
# title_el 로 선언 해준다.
print(title_el)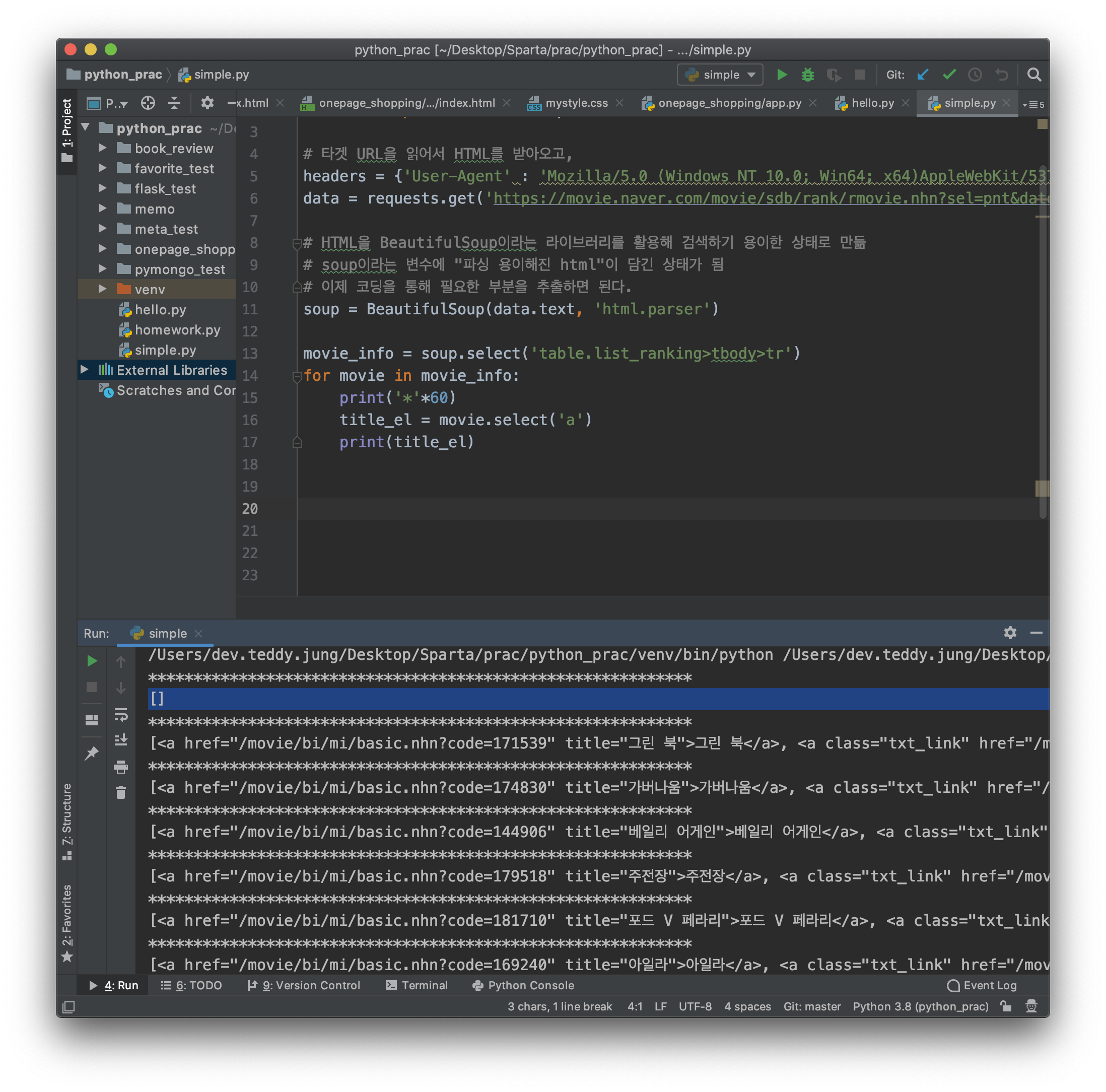
오오 근데 각각의 제목 요소들이 [ ] 배열 형태를 하고 있다는 것을 알 수 있으며, a 태그에 제목 뿐만 아닌 평점 주기도 같이 들어 있는 것을 확인 할 수 있었다.
배열 형태!! 배열!! 그럼 이 title_el 에서 0번째가 내가 얻으려는 영화제목, 1번째가 평점 주기가 되겠징?
그리고 영화 페이지에서 보면 1위부터 10위까지 해놓고 선을 그어 놓는다. 이 부분을 파이참 상태창에서 확인해 보면, [ ] 이렇게 나온다. 이렇게 배열이 비어 있는 아이들은 배열의 길이가 0이다!
if len(title_el) > 0: # len 은 파이썬에서 배열의 길이를 뜻함.
print(title_el)만약 타이틀의 길이가 0 보다 크다면, 즉 0 인 [ ] 애들은 건너띄라는 의미!
오 이렇게 하고 print 하니까 빈칸이 없어졌다.
이제 오로지 영화 제목만 뽑아보자!
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
print('*'*60)
title_el = movie.select('a')
if len(title_el) > 0:
print(title_el[0]) #title_el 의 0번째 영화제목을 프린트해줘!!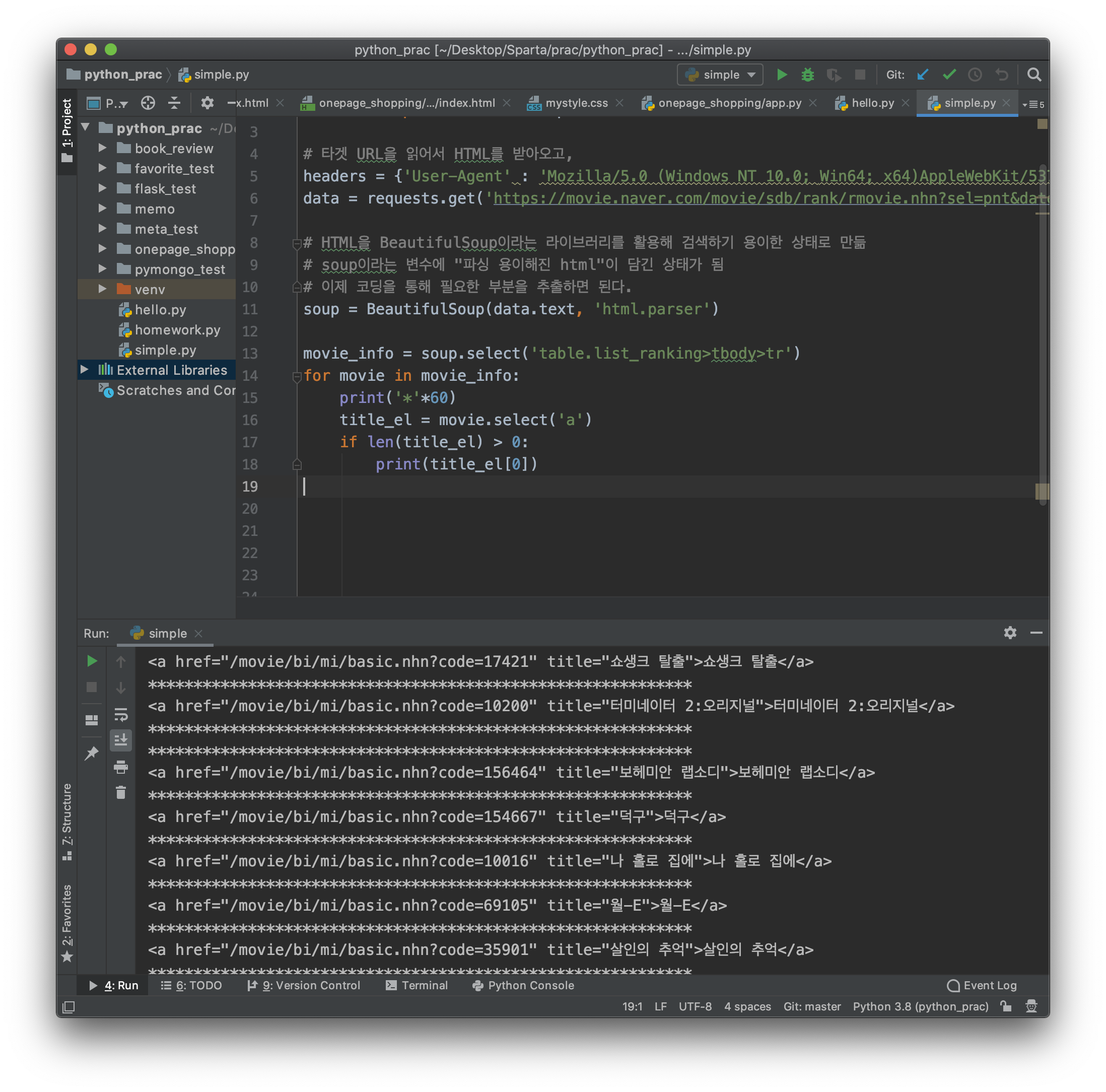
오호~ 좋아좋앙
앗 그런데 a 태그 html 요소들이 보여서 너무 지저분해!! 어우!
저기서 제목 텍스트만 볼 수 없을까?
텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만텍스트만
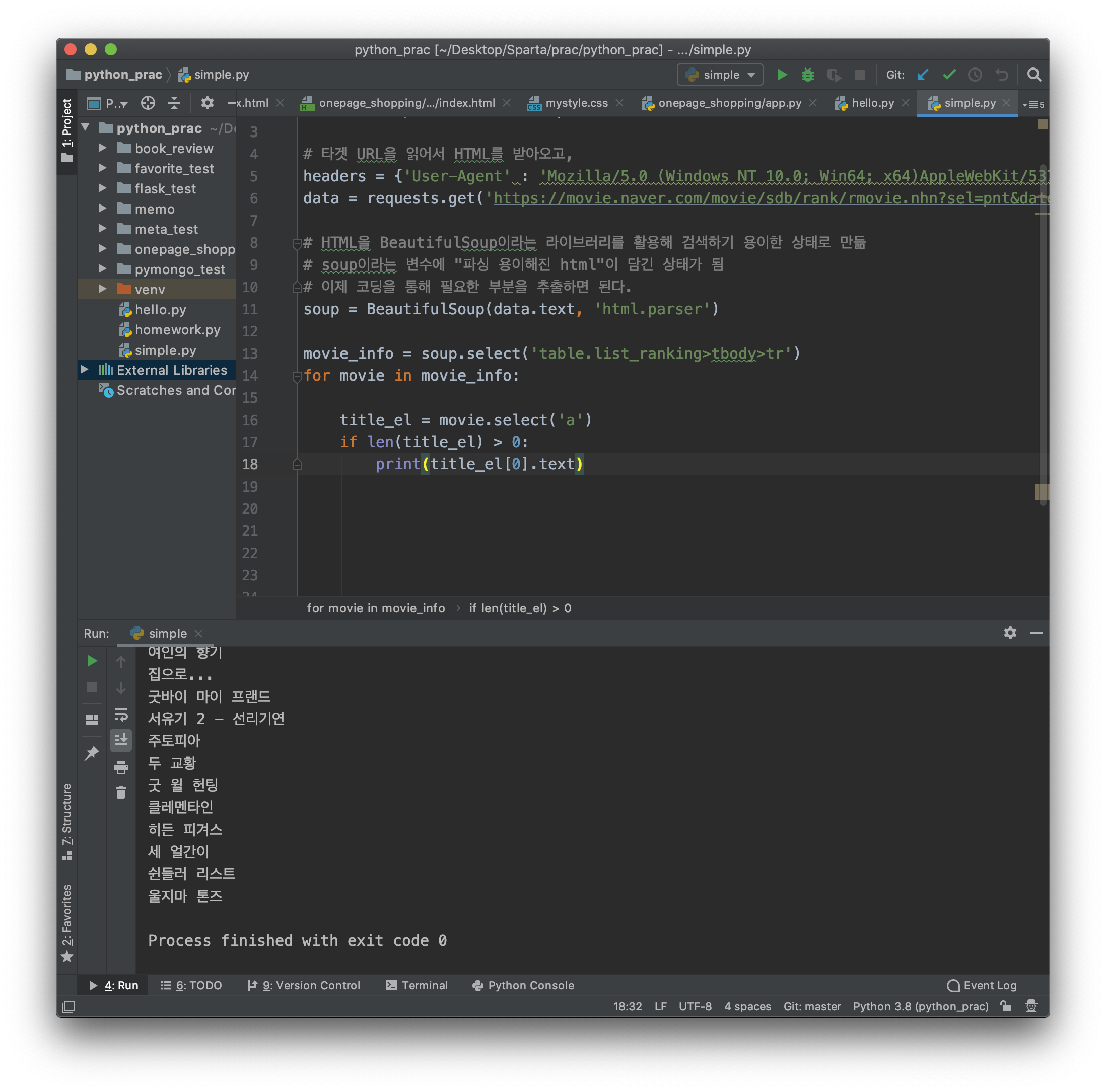
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
print('*'*60)
title_el = movie.select('a')
if len(title_el) > 0:
print(title_el[0].text) #.text 를 통해 텍스트만 콕 찝어준다.그러면 제목이 나오고 이제 구분선은 필요없어 졌으니 print( 별표곱하기60 ) 은 지운다.
3-5. 평점 요소 가져오기
평점은 < td > 에서 class 가 point 인 아이이다.
movie.select('td.point') # 앞서 반복문의 movie 가 선택하게 해 뭘? 평점을!
point_el = movie.select('td.point') # 그것을 point_el 에 선언해 넣어주자!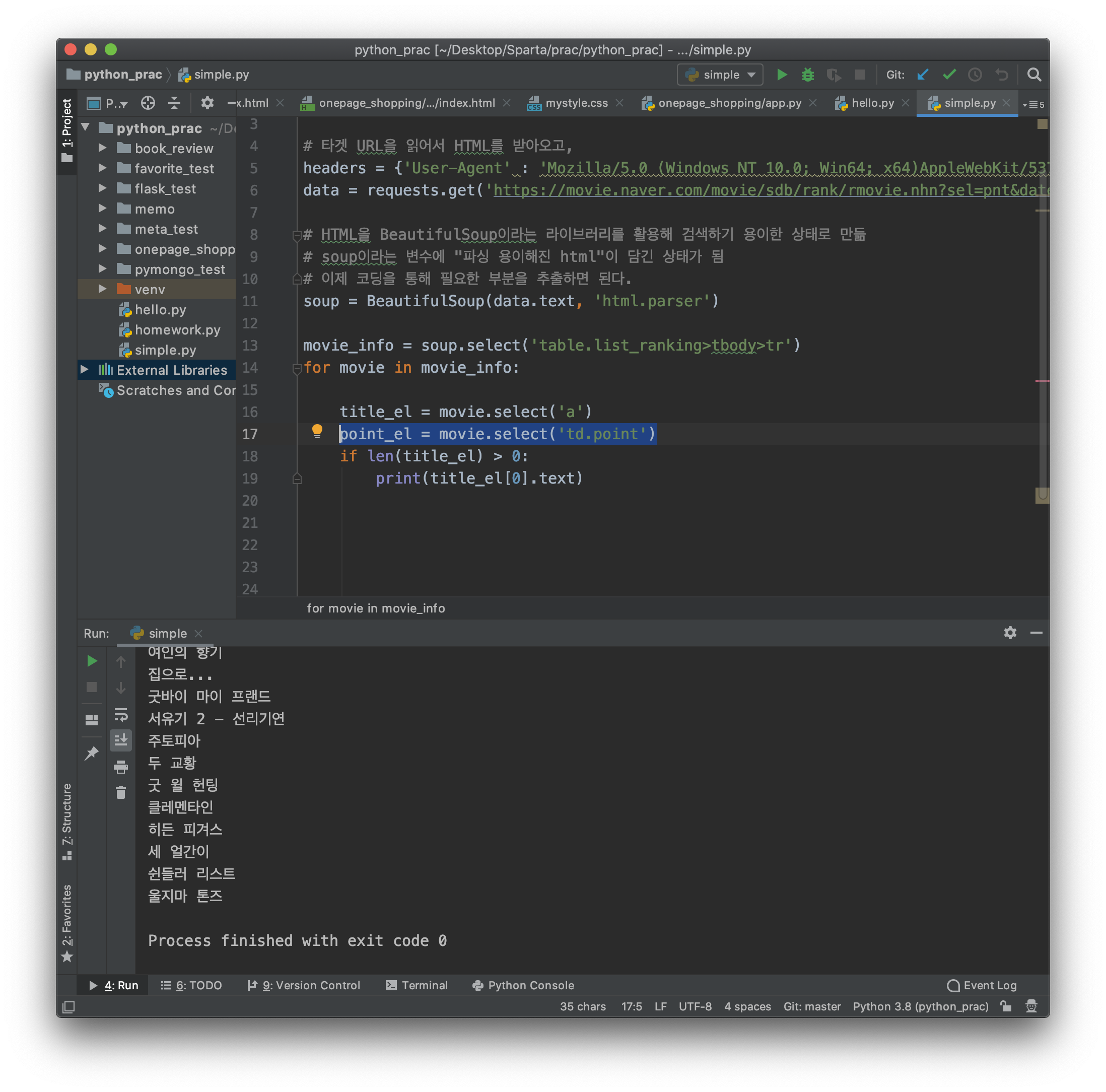
평점도 페이지에서 보면 구분선으로 10개 마다 쳐져 있다. 그말은 아까와 마찬가지로 빈 배열이 있다는 거.
if 문을 만들자.
그리고 배열에서 point_el 의 0번째 평점을 불러오고, 평점 text 만을 가져오자.
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
title_el = movie.select('a')
point_el = movie.select('td.point')
if len(title_el) > 0:
print(title_el[0].text)
if len(point_el) > 0:
print(point_el[0].text)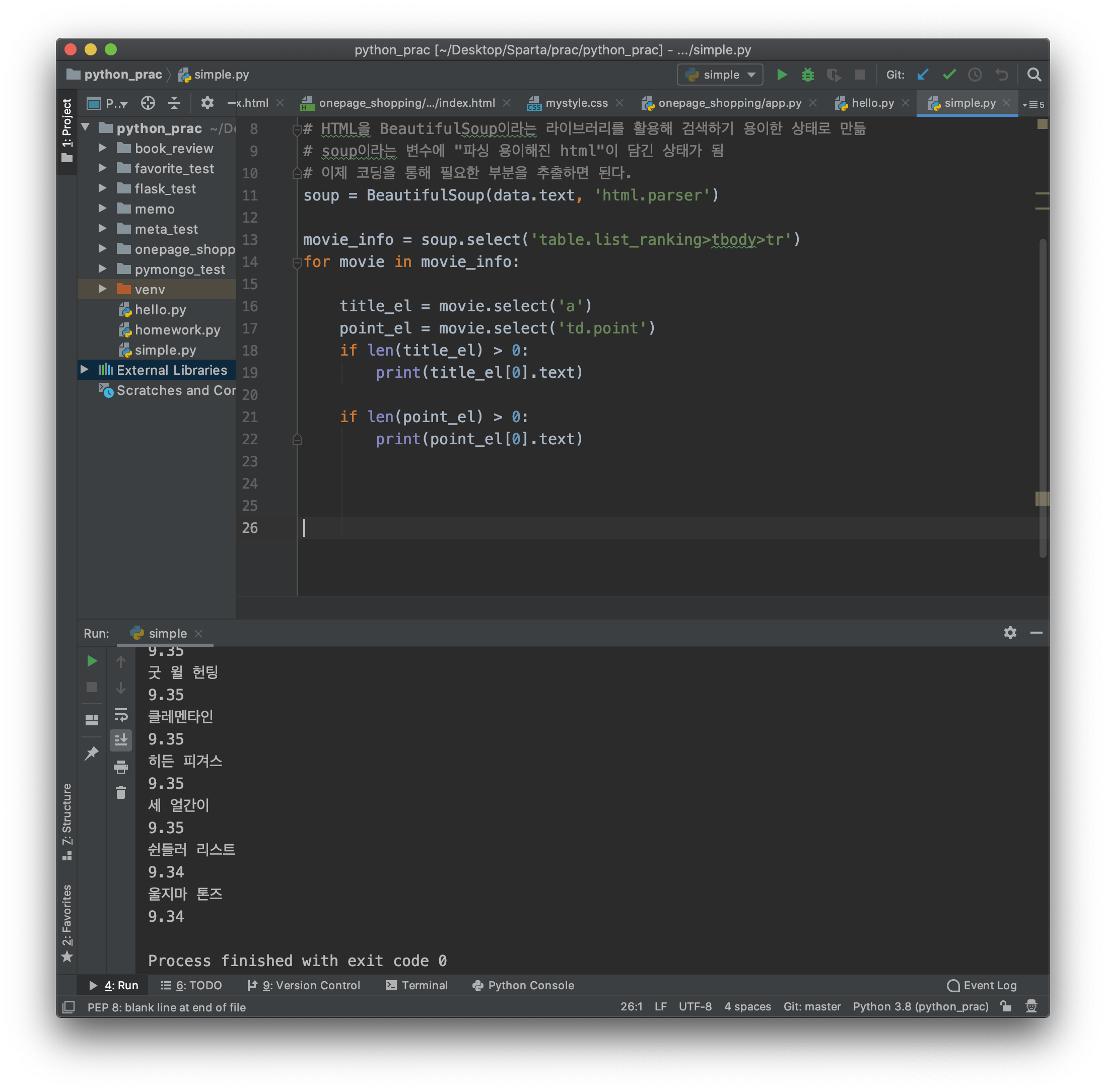
3-6. 중복 제거
if 문이 두번 반복되고 있다. 선은 타이틀이나 포인트에 같이 적용되니까 포인트를 위로 올리고 if 문 하나로 줄일 수 있다.
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
title_el = movie.select('a')
point_el = movie.select('td.point')
if len(title_el) > 0:
print(title_el[0].text)
print(point_el[0].text)정확히 맞는지 모르겠는데 (괄호내인자) 가 길면 보기에 좋아 보이지 않아서 새로 선언한 뒤에 적용한다는 이야기를 들은 것 같다.
그래서,
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
title_el = movie.select('a')
point_el = movie.select('td.point')
if len(title_el) > 0:
title = title_el[0].text ## title 을 새로 정의
print(title)
point = point_el[0].text ## point 를 새로 정의
print(point)한 번 더 줄여서,
movie_info = soup.select('table.list_ranking>tbody>tr')
for movie in movie_info:
title_el = movie.select('a')
point_el = movie.select('td.point')
if len(title_el) > 0:
title = title_el[0].text
point = point_el[0].text
print(title, point)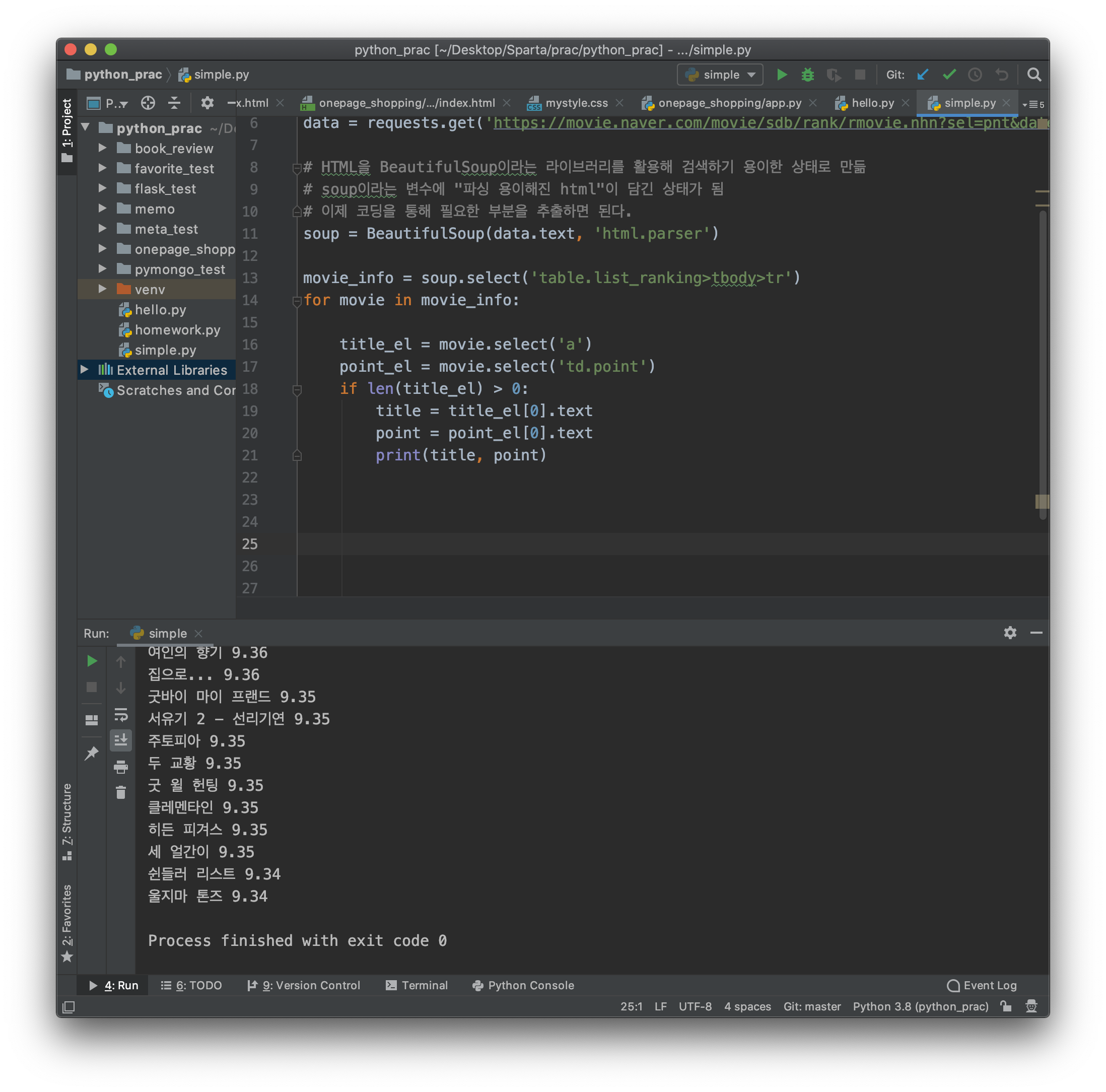
3-7. rank 순위도 함께 표기하기
위와 마찬가지로 스크래핑을 해도 되지만 굳이 그럴 필요가 없어 보인다.
왜냐하면 현재 보이는 대로가 순위이기 때문에 처음으로 인쇄되어 나오는게 1등이다.
rank 라는 변수를 생성해서 0 이라 하고, 이건 기본 값을 정의 하는 거라 for 문 바깥에 작성한다.
rank = 0그리고 True 일 때 (값을 제대로 가져올 때) 작동하는 If 문 내에서 rank = rank + 1 을 해준다.
rank = rank + 1 #### rank += 1 과 같은 의미임.
그러면 반복을 돌면서 첫번째는 1, 두번째는 2 이렇게 매겨지겠네.
그리고 맨 앞에 표시되게 print 에 rank 를 적어준다.
print(rank, title, point)4. 완성