소개
간단하고 강력한 AI 개발 도구를 통해 사용자의 코드 작성 및 디버깅 작업 효율성을 대폭 향상시키는 방법을 소개합니다. 이 글에서는 Anthropic의 최신 모델인 Claude 3.7 Sonnet과 이를 기반으로 한 agentic coding 도구인 Claude Code의 주요 기능과 사용 사례를 설명합니다.
Claude 3.7 Sonnet: 하이브리드 추론 모델
Claude 3.7 Sonnet은 오늘날까지 공개된 모델 중 가장 지능적이며, 데이터 처리와 깊이 있는 추론 기능을 하나의 모델에서 동시에 제공하는 최초의 하이브리드 추론 모델입니다.
[tip] Claude 3.7 Sonnet은 짧은 응답과 단계별 사고를 모두 지원하므로 사용자가 요청에 따라 빠른 답변 또는 심도 있는 고민을 선택할 수 있습니다.
통합 추론 및 확장 사고 모드
- 통합 접근 방식:
Claude 3.7 Sonnet은 단일 LLM(large language model) 기능과 추론 능력을 통합하여, 표준 모드와 extended thinking 모드 간의 전환을 자연스럽게 수행할 수 있습니다. - 표준 vs. 확장 사고 모드:
- 표준 모드에서는 Claude 3.7 Sonnet이 Claude 3.5 Sonnet의 업그레이드 버전으로서 빠른 응답을 제공합니다.
- 확장 사고 모드에서는 추가적인 자기 성찰 과정을 통해 수학, 물리, 코딩, 지시사항 준수 등의 복잡한 문제에 대해 보다 정확하고 신뢰할 수 있는 답변을 도출합니다.
- 토큰 기반 사고 예산 조절:
API 사용 시, 사용자는 최대로 사용할 사고 토큰 수(Ntokens, 최대 128K 토큰까지)를 지정할 수 있어 속도와 비용, 응답 품질 간의 균형을 조절할 수 있습니다.
가격 및 API 제공
Claude 3.7 Sonnet은 Free, Pro, Team, Enterprise 플랜 및 다음 플랫폼에서 사용할 수 있습니다.
가격은 입력 토큰 1백만 개당 $3, 출력(사고 포함) 토큰 1백만 개당 $15입니다. 단, 확장 사고 모드는 Free Claude 티어를 제외한 모든 표면에서 사용할 수 있습니다.
성능 및 벤치마크 평가
Claude 3.7 Sonnet은 특히 코딩과 프론트엔드 웹 개발에서 큰 개선을 보였습니다.
코딩 및 개발 작업에 대한 향상
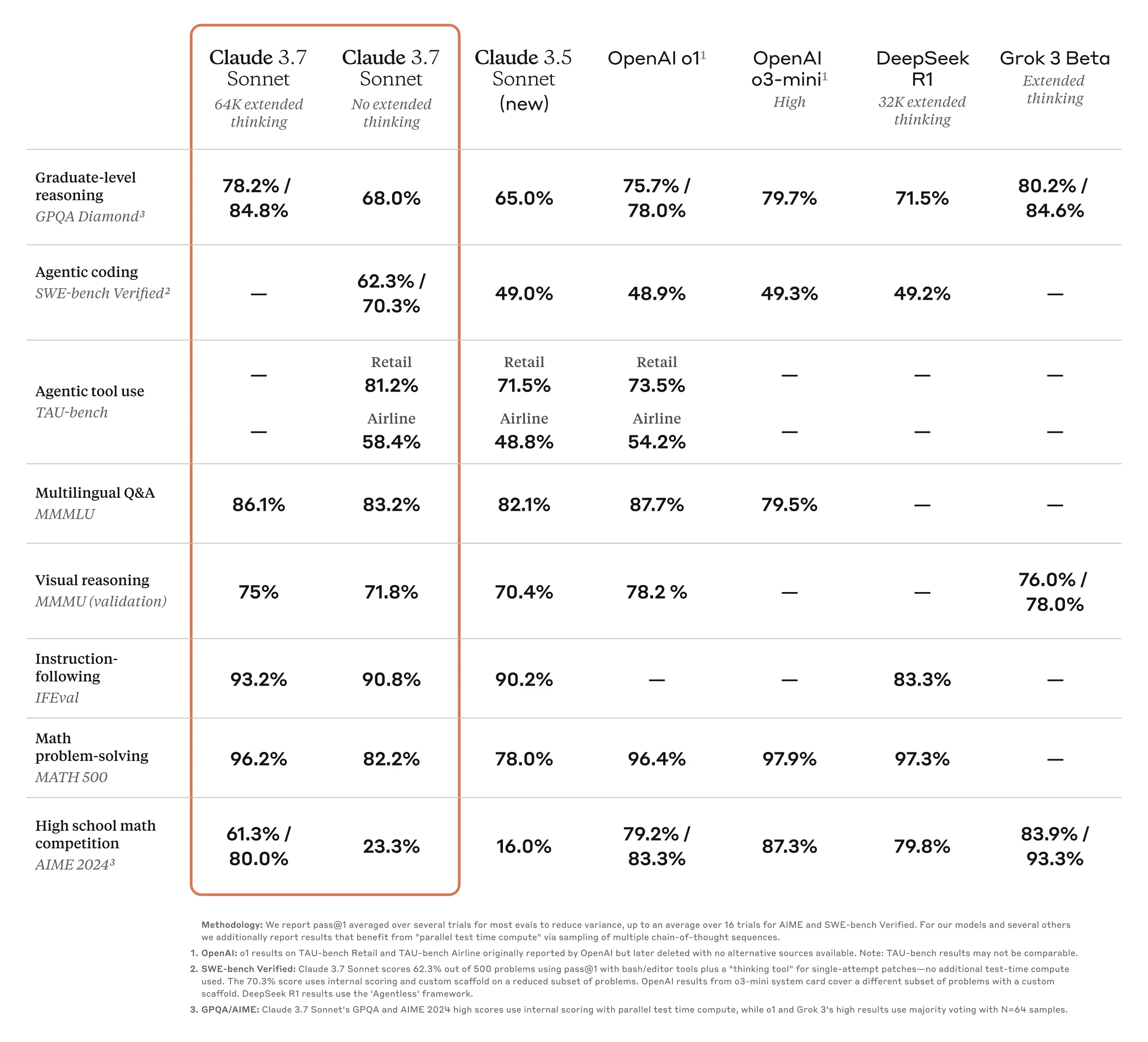
[tip] 다양한 외부 평가 결과에서 Claude 3.7 Sonnet은 복잡한 코드베이스 처리, 도구 활용, 계획 수립, 에이전트 작업 등에서 최고 수준의 성능을 입증하였습니다.
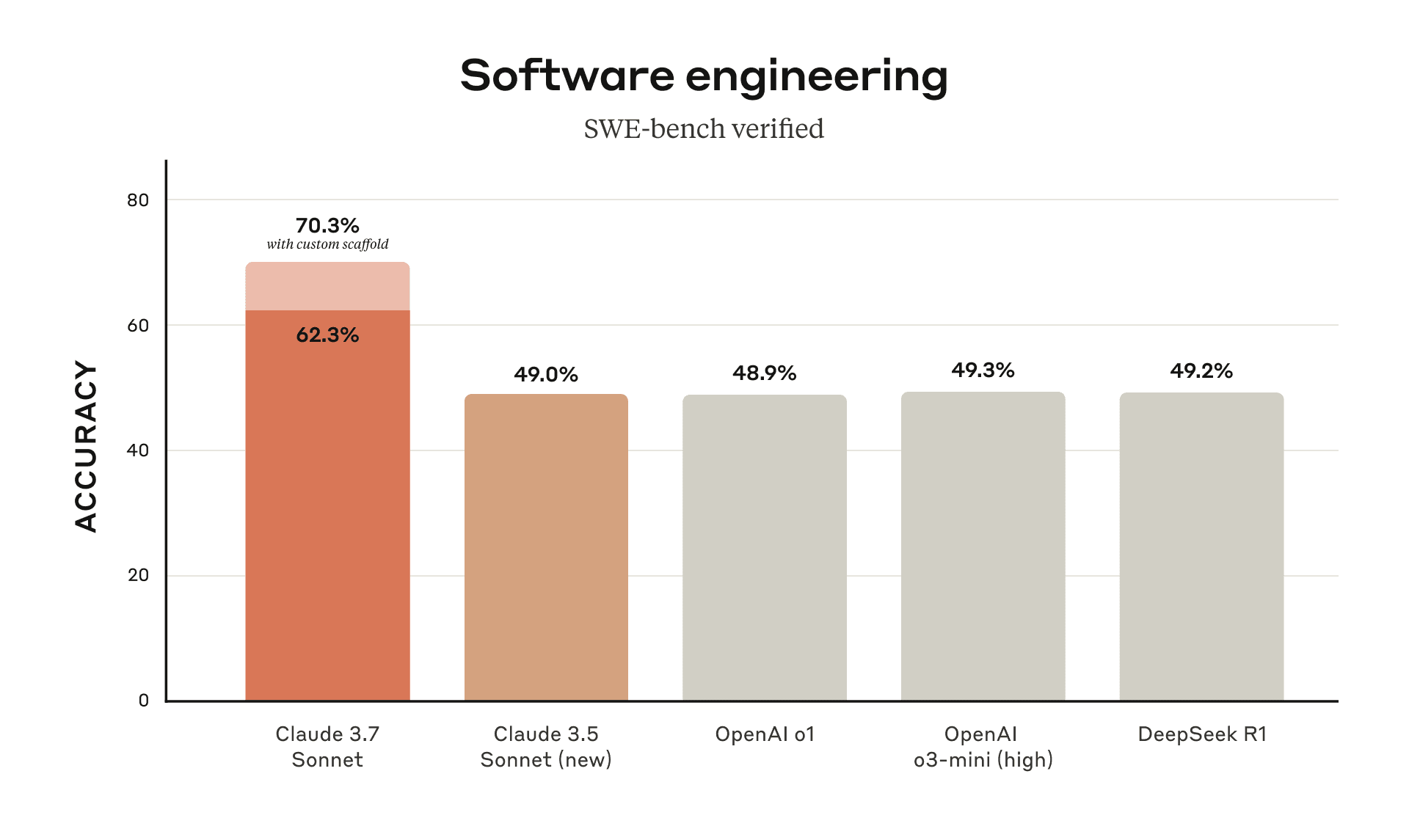
- SWE-bench Verified:
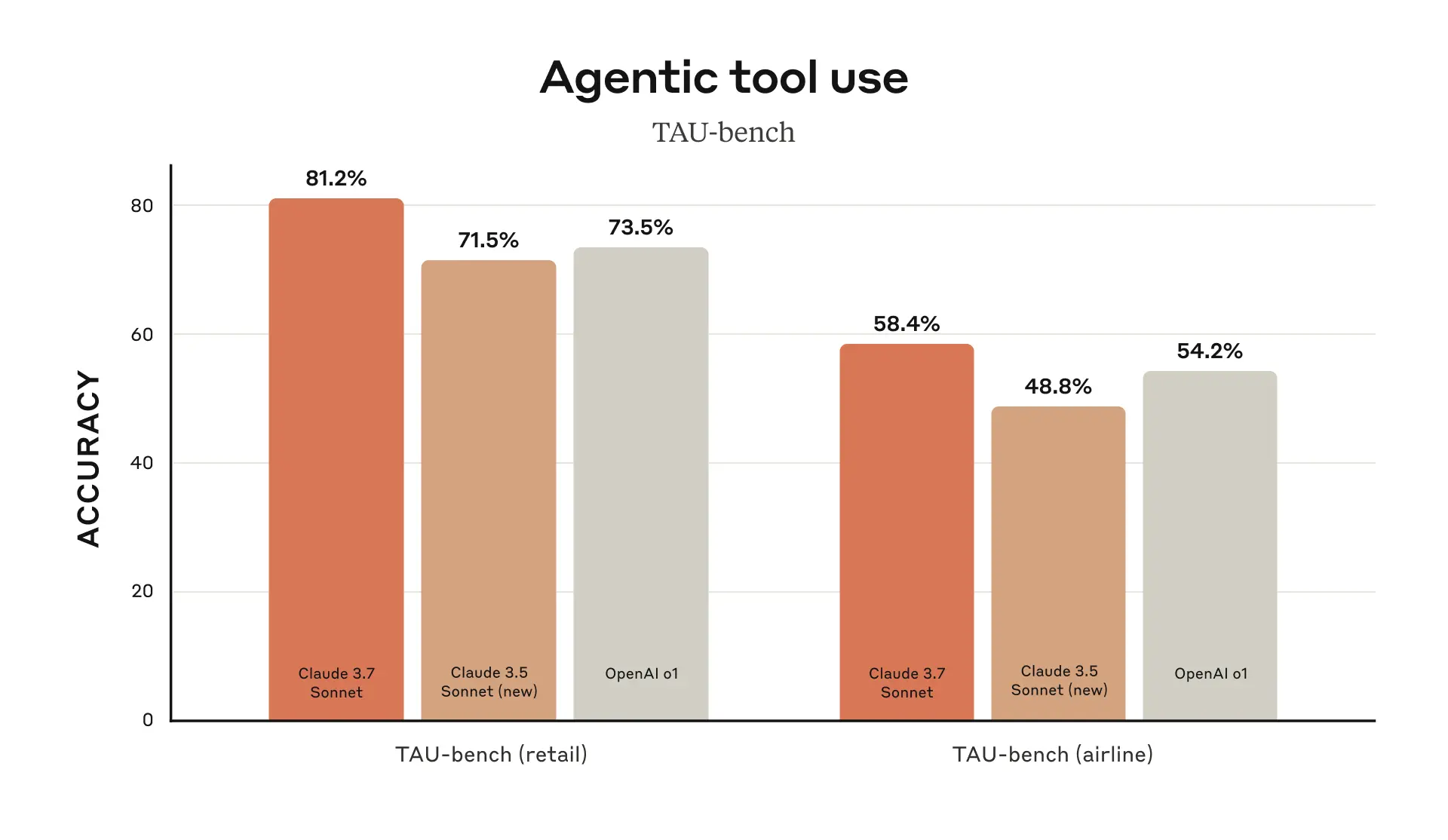
실제 소프트웨어 문제 해결 능력을 평가하는 SWE-bench Verified에서 최첨단 성능을 달성했습니다. - TAU-bench:
사용자 및 도구 상호작용을 포함한 복잡한 현실 세계 작업에 대한 평가에서도 우수한 점수를 기록했습니다. - Pokémon 플레이 테스트:
전 모델 대비 향상된 사고 능력을 바탕으로 복잡한 게임 테스트에서도 우수한 성능을 보였습니다.
아래는 Claude 3.7 Sonnet의 성능을 시각적으로 보여주는 벤치마크 차트입니다.
Claude Code: 에이전틱 코딩 도구
Claude 3.7 Sonnet의 코딩 성능 향상에 힘입어, Anthropic은 개발자들을 위한 최초의 agentic coding 도구인 Claude Code를 제한된 연구 프리뷰로 선보입니다.
Claude Code 기능
- 에이전트릭 협업:
- 코드 검색 및 읽기
- 파일 편집 및 수정
- 테스트 작성 및 실행
- GitHub에 코드 커밋 및 푸시
- 커맨드 라인 도구 사용
- 효율적인 개발 지원:
Claude Code는 테스트 주도 개발, 복잡한 문제 디버깅, 대규모 리팩토링 작업을 단일 프로세스로 줄여, 45분 이상의 수작업을 단 한 번의 패스로 처리할 정도로 높은 효율을 자랑합니다.
아래의 영상은 Claude Code의 개요와 작동 방식을 소개합니다.
개발자와의 밀접한 연계
Claude Code는 Claude.ai 플랫폼 내에서 GitHub 통합 기능과 함께 제공되어, 개발자들이 자신의 코드 저장소와 직접 연동하여 작업할 수 있도록 지원합니다. Claude 3.7 Sonnet은 개인, 업무 및 오픈 소스 프로젝트에 대한 이해를 바탕으로 버그 수정, 기능 개발, 문서화에 큰 도움을 줍니다.
책임 있는 AI 개발 및 안전성 확보
Anthropic은 Claude 3.7 Sonnet의 광범위한 테스트 및 외부 전문가와의 협업을 통해 보안, 안전성 및 신뢰성을 보장하고 있습니다.
- 안전성 평가 및 시스템 카드:
Claude 3.7 Sonnet의 시스템 카드는 다양한 안전성 평가 결과와 저해 위험, prompt injection 공격 대응 등을 상세히 설명합니다. - 불필요한 거부율 감소:
이전 버전 대비 불필요한 요청 거부율을 45% 감소시켰습니다.
[warning] AI 시스템의 안정성과 보안을 유지하는 것은 사용자와 기업 모두에게 중요한 과제이며, 지속적인 모니터링과 평가가 필요합니다.
미래 전망
Claude 3.7 Sonnet과 Claude Code는 AI가 인간의 능력을 보완하고 확장하는 미래로 나아가는 중요한 발걸음입니다. 심도 있는 추론, 자율 작업, 협업 기능을 통해 AI는 더욱 풍부하고 혁신적인 가능성을 열어가고 있습니다.

부록
평가 데이터 소스
TAU-bench 세부 정보
TAU-bench는 AI 에이전트가 사용자 및 도구와 상호작용하며 문제를 해결하는 과정을 평가하는 프레임워크입니다.
- Airline Agent Policy에 추가된 프롬프트를 사용하여 Claude가 “planning” 도구를 효율적으로 활용하도록 유도합니다.
- 문제 해결 과정에서의 최대 스텝 수를 기존 30단계에서 100단계로 증대하여, 복잡한 문제 해결 능력을 발휘합니다.
SWE-bench Verified 세부 정보
SWE-bench Verified는 에이전트틱 작업에서의 모델 성능을 평가합니다.
- Claude 3.7 Sonnet은 최소한의 scaffolding으로, bash 도구와 파일 편집 도구(문자열 치환 기반)를 사용하며 ‘planning tool’을 활용합니다.
- 내부 인프라 상에서 489/500 문제를 해결하였으며, 추가 복잡도와 병렬 테스트를 통해 최종 점수를 산출합니다.
참고문헌
