Computer Vision이란?
: 기계가 이미지 및 영상을 이해하고 분석하도록 만드는 AI 기술 분야
ML Pipeline 🧩
ML Pipeline은 “입력 데이터를 받아 모델을 만들고, 실전에 적용해 결과를 얻기까지”의 전체 흐름을 뜻한다.
- Preprocessing: 입력 이미지를 모델이 다루기 좋은 형태로 정리한다.
- Learning: 데이터로부터 패턴을 학습시킨다.
- Evaluation: 지표로 과적합/일반화 등의 성능을 검증한다.
- Inference: 실전 데이터로 예측을 수행한다.
- Postprocessing: 모델 출력값을 활용하기 좋은 형태로 정제한다.
이 포스팅에서는 1, 4, 5번에 대해 다룬다.
1. Pre-processing 🧪
Pre-processing은 모델이 정확하게 학습하고, 안정적으로 추론하도록 돕는 단계다.
전처리는 다음의 세 가지 작업을 통해 할 수 있다.
- 기하학(Geometry): 위치/크기비율/좌표계와 같은 “형태와 배치”를 다룬다.
- 광도/색상(Photometric/Color): 밝기/색감/노이즈와 같은 “픽셀 값”을 다룬다.
- 데이터 증강(Augmentation): 학습 데이터에 변형을 줘 일반화를 강화한다.
1) Geometric Transformations
이미지의 좌표계를 조작해 형태·크기·위치를 바꾸는 기술이다.
기하학적 변형은 다음 세 가지 방법으로 진행할 수 있다.
1. 크기 조정(Resizing) & 다운샘플링(Downsampling)
2. 비율 유지 패딩(Letterbox Padding)
3. 이미지 피라미드(Image Pyramid)
⚠️ 0. 단순 Resizing의 한계
이미지를 강제로 정사각형으로 바꾸면 종횡비(Aspect Ratio)가 깨져서 객체가 찌그러지고, 모델이 형태 특징을 학습하기 어려워진다.
1. Downsampling
고해상도 이미지를 모델 입력 크기에 맞게 축소하는 과정이다.
- 축소 과정에서 정보 손실이 생길 수 있다.
- 특히 앨리어싱(Aliasing)을 줄이기 위해 보간(Interpolation)을 사용한다.
참고: 작은 텍스트(OCR)나 얇은 경계(Edge)는 축소에 더 취약하다.
2. Letterbox Padding
왜곡을 방지하기 위해 종횡비를 유지한 채로 resize하고, 남는 영역을 패딩으로 채우는 방식이다.
OCR처럼 “비율”이 중요한 문제에서 특히 효과적이다.
3. Image Pyramid
원본 이미지를 여러 해상도로 만들어 작은 객체/큰 객체를 더 잘 다루게 하는 전략이다.
- 단일 해상도만으로는 작은 객체 + 큰 객체를 동시에 잡기 어렵다.
- 여러 해상도에서 특징(Feature)을 뽑아 쓰는 아이디어다.
- FPN(Feature Pyramid Network) 같은 멀티스케일 구조와 연결된다.
2) 광도 및 색상 변환(Photometric & Color Transformations)
조명 변화, 색상 왜곡, 노이즈 같은 현실 변수를 견디게 하기 위해 픽셀 값 자체를 조정하는 과정이다.
1. Normalization
2. Color Correction & Color Space
3. Denoising
1. Normalization
디지털 이미지는 보통 픽셀 값이 0~255(정수) 범위다.
신경망은 입력 스케일에 민감해서, 스케일이 크면 학습이 불안정해질 수 있다.
대표 방식
- Scaling:
x / 255→ 0~1 범위로 변환한다. - Standardization: 채널별로
(x - mean) / std로 표준화한다.- 사전학습 모델을 쓰면 그 모델이 기대하는 mean/std를 맞추는 경우가 많다.
2. Color Correction & Color Space
같은 물체도 조명(색온도/밝기/그림자)에 따라 RGB가 쉽게 흔들리기 마련이다.
그래서 색상 분포를 안정화하거나, 더 다루기 쉬운 축으로 변환하기도 한다.
- 히스토그램 평활화(Histogram Equalization): 명암 분포를 펼쳐 대비를 개선한다.
- Color Space Transform
- RGB → HSV / LAB / YCrCb 등으로 변환한다.
- 밝기(V/Y)와 색상 성분을 분리해 밝기만 조절하는 식으로 적용할 수 있다.
3. Denoising
저조도, 센서 잡음 등으로 생긴 노이즈는 경계(Edge)나 질감(Texture) 같은 핵심 성분을 훼손할 수 있다.
- Gaussian Filter: 전반적으로 부드럽게 만든다.
- Median Filter: 점 노이즈(소금-후추)에 강하다.
주의: 노이즈 제거를 과하게 하면 디테일까지 날아갈 수 있다.
3) 데이터 증강(Data Augmentation)
한정된 학습 데이터에 변형을 주어 데이터의 양과 다양성을 늘리고 과적합을 줄여 일반화 성능을 높인다.
다음과 같은 방법으로 데이터를 변형할 수 있다.
1. 기하학적 증강: 좌우반전, 회전, 크롭, 이동(Shift), 스케일 변화
2. 광도적 증강 / 커널 기반 증강: 밝기/대비/채도 변화, 블러, 노이즈 추가
3. 고급 증강
- Mosaic: 4장 이미지를 한 장으로 합성한다(탐지에서 유용하다).
- MixUp: 두 이미지를 가중치로 섞는다(분류에서 자주 활용된다).
- CutMix: 이미지 일부를 잘라 다른 이미지로 대체한다.
팁: 서비스 환경에서 실제로 발생할 변화 위주로 증강을 설계하는 편이 좋다.
4. Inference 🤔
학습된 모델을 실전(Production)에 투입해
새로운 데이터(Unseen Data)를 예측하는 단계다.
실전에서는 정확도뿐 아니라 아래도 같이 본다.
- 지연시간(Latency)
- 처리량(Throughput)
- 효율(Efficiency)
대표 비전 과제들
1. Image Classification
2. Object Detection
3. Image Segmentation
4. Face Recognition
5. Pose Estimation
6. OCR
1. Image Classification
이미지 전체를 보고, 미리 정해진 클래스 중 하나를 고르는 작업이다.
대표적인 모델은 다음과 같다.
- ResNet
- EfficientNet
- ViT
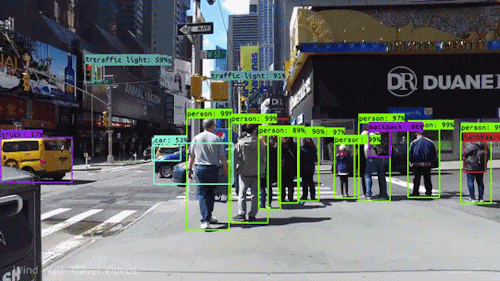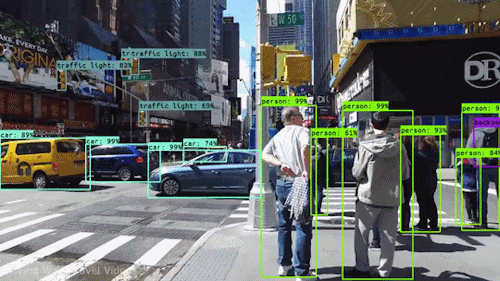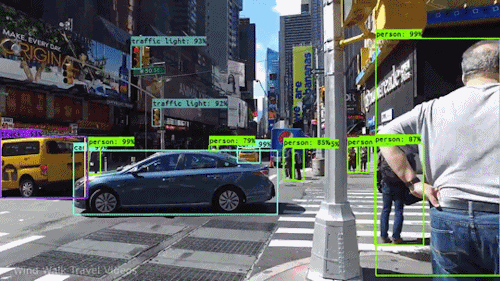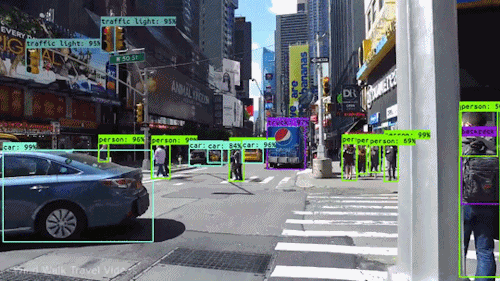
2. Object Detection
이미지 내 여러 객체의 종류(Class)와 위치(Localization)를 바운딩 박스(Bounding Box)로 함께 예측하는 과제다.
대표적인 모델은 다음과 같다.
- YOLO 계열
3. Image Segmentation
픽셀 단위로 영역을 나누는 과제이며 목적에 따라 다음으로 나뉜다.
- 의미론적 분할(Semantic Segmentation)
- 인스턴스 분할(Instance Segmentation)
4. Face Recognition
사람 얼굴을 인식하는 문제이며 보통 다음 흐름을 따른다.
1. 얼굴 탐지(Detection)
2. 정렬(Alignment)
3. 특징 벡터(Embedding) 추출
4. DB 비교(Verification/Identification)
5. Pose Estimation
주요 관절(Keypoints)을 탐지하고 골격(Skeleton)을 복원한다.
6. OCR(Optical Character Recognition)
이미지 속 문자를 텍스트로 변환하는 기술이다.
5. Post-processing ⚗️
모델이 출력한 원시 값(Raw Output)을 사람이 이해하거나 시스템이 쓰기 좋은 형태로 다듬는 과정이다.
객체 탐지(Object Detection)에서는 전형적으로 아래 후처리들이 함께 묶여 적용된다.
1. 임계값 필터링(Thresholding): Confidence가 기준치 이상인 결과만 남긴다.
2. 비최대억제(NMS): 겹치는 박스 중 중복을 제거한다(IoU 기준).
3. 좌표 변환 및 스케일링(Coordinate Scaling): 전처리로 바뀐 좌표를 원본 이미지 기준으로 되돌린다.
4. 시각화(Visualization): Bounding Box, 마스크, 히트맵 등으로 결과를 표현한다.
OCR + NLP 후처리 전략
- 디코딩 및 정규화: 토큰 → 문자열 변환, 공백/특수문자 정리 등을 수행한다.
- LLM 기반 보정: 문맥 기반 오타/형식 보정을 적용할 수 있다.
모델/라이브러리 정리 📝
- YOLO: 한 번에 위치+종류를 예측하는 실시간 객체 탐지 모델이다.
- EasyOCR: CRAFT(검출) + CRNN+CTC(인식) 기반 OCR 라이브러리다.
- TrOCR: ViT 인코더 + Transformer 디코더 기반 OCR(마이크로소프트)다.
