
일정 규모 이상의 Kafka 클러스터를 운영하다 보면 클러스터 내 불균형이 일어날 때가 있습니다. 여기서 말하는 "불균형"의 유형은 아래와 같습니다.
1. 리더 분포의 불균형 ( leader Skew ) - leader partition이 각 브로커 마다 골고루 분포되지 않은 상태
2. 브로커 불균형 ( Broker skew ) - 각 브로커 별 파티션 개수, message in/out, bytes in/out, throughput 등이 균형있게 분포되지 않은 상태
이러한 불균형 상태는 특정 브로커의 CPU, Disk 문제를 야기시킬 수 있으며, 전체적인 클러스터의 성능을 저하시킬 가능성이 있습니다.
이러한 불균형은 특히 클러스터 내 새로운 브로커를 추가할 때 거의 필수적으로 발생하게 되는데요,
새로운 토픽이 만들어지거나 임의로 파티션을 옮겨주지 않는 이상 추가된 브로커에는 파티션이 할당되지 않기 때문에 위와 같은 불균형이 발생하게 됩니다.
1. 리더 분포의 불균형(leader Skew) 상세 / 해결법
위에서 리더 분포의 불균형을 leader partition이 각 브로커 마다 골고루 분포되지 않은 상태라고 정의 하였는데요, 어떻게 이런 불균형이 발생되는지 아래 시나리오를 통해 확인해보겠습니다.
그림/내용 출처 : https://hashedin.com/blog/re-balance-your-kafka/
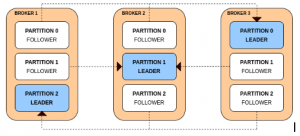
- 위 그림과 같이 3개의 브로커에 대해 각각 3 Replication Factor 를 가진 파티션 세개가 배포되었다고 가정해 보겠습니다. 브로커 입장에서는 각각 하나의 Leader 파티션을 포함하고 있어, 리더 분포의 균형을 이루고 있는 것을 확인할 수 있습니다.
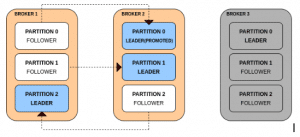
- 운영 중 Broker3이 다운되었습니다. 이에, Broker 3에 있던 Partition 0의 리더가 다운되었기 때문에 Broker2에 있던 Partition 0의 팔로워가 리더로 승격되어 서비스를 재개하게 됩니다.
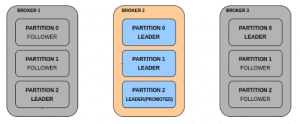
- 운영 중 Broker1도 다운되었습니다. Broker 1에 있던 Partition2의 리더 역시 다운되었기 때문에 Broker2에 있던 Partition2의 팔로워가 리더로 승격되어 서비스를 재개하게 됩니다.
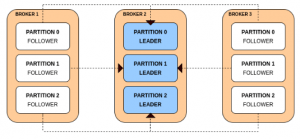
- 다운되어있던 Broker1과 Broker3이 온라인 상태가 되었지만 파티션들의 리더는 모두 Broker2에 여전히 집중되어 있어 리더 분포의 불균형(Leader Skew) 상태를 보이게 됩니다.
참고 - Kafka에서 Partition Leader를 선정하는 방법
기본적으로 Kafka에서 새로운 토픽이 생성 될 때 Kafka에서는 Leader Election 알고리즘을 실행하여 각 파티션 별로 "Preferred Leader"를 선정합니다. partition replicas의 첫번째 숫자가 Preferred leader이며, Leader의 숫자값과 동일할 때 preferred leader(replica) 의 balance가 맞다고 표현합니다.
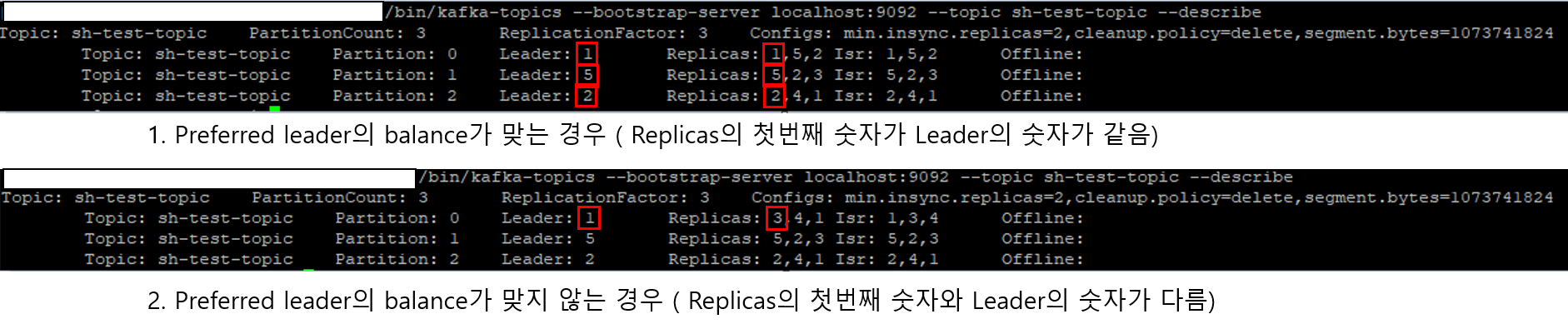
리더 분포의 불균형(leader Skew) 해결법
리더 분포의 불균형(leader skew)를 해결하는 방법은 크게 두가지가 있습니다.
- auto.leader.rebalance.enable 옵션을 사용하는방법
- kafka-leader-election.sh 를 실행시키는 방법
1. auto.leader.rebalance.enable 옵션 사용
auto.leader.rebalance.enable 옵션을 true로 할 경우, 백그라운드에서 별도의 스레드가 리더의 불균형 상태를 체크합니다. "leader.imbalance.check.interval.seconds" 로 Controller가 leader imbalance를 체크하는 주기를 설정 할 수 있으며, 리더 불균형이 브로커 별로'leader.imbalance.per.broker.percentage'를 초과하는 경우 preferred leader에 대한 rebalance 작업이 실행됩니다.
일반적인 상황에서는 auto.leader.rebalance.enable 옵션을 true로 할 때 운영의 수고로움을 덜어줄 수 있지만, 새로운 브로커를 추가하는 등 특정 상황에는 해당 옵션 사용에 대해 검토해 봐야 할 것 같습니다.
2. kafka-leader-election.sh의 사용
kafka-leader-election.sh를 실행하면 preferred leader 에 맞게 leader가 재선정되어 리더 분포의 불균형을 해결할 수 있습니다.
해당 툴이 실행되면 전체 파티션에 대한 preferred replica와 leader의 비교를 하게 되고, imbalance한 파티션이 발견되는 경우 Controller는 해당 브로커에 preferred leader를 파티션 리더로 지정하라는 요청을 보내게 됩니다. Preferred replica가 ISR(In-Sync-Replica) 목록에 없으면 Controller는 데이터 유실을 막기위해 작업을 실패 처리하게 됩니다.
Json 파일을 통해 특정 토픽과 파티션에 대해서만 해당 툴이 실행되도록 제한할 수 있으며, Json 파일 없이 실행할 경우 카프카 클러스터 내 모든 토픽과 파티션을 대상으로 합니다.(Zookeeper내 Query를 통해 모든 토픽/파티션 리스트를 받음)
-
현재 sh-test-topic의 상태는 모든 파티션들에 대해 preferred leader와 leader가 일치하지 않습니다.
(리더 분포가 불균형한 상태)

-
kafka-leader-election.sh 를 실행시킵니다. (특정 토픽/파티션에만 적용시키기 위해 --path-to-json-file 옵션을 사용하였습니다.)
$ bin/kafka-leader-election.sh --bootstrap-server BROKER:9092 --election-type preferred --path-to-json-file sample.json
##### sample.json은 아래와 같습니다. ########
{
"version" : 1,
"partitions" :[
{"topic":"sh-test-topic", "partition":0},
{"topic":"sh-test-topic", "partition":1},
{"topic":"sh-test-topic", "partition":2}
]
}- 툴 실행을 통해 모든 파티션들에 대해 preferred leader와 leader가 일치하게 맞는것을 확인 할 수 있습니다.

Kafka-preferred-replica-election.sh를 사용할 수도 있으나, 2.4.0 이상의 kafka 버전에서는 해당 툴이 deprecated되어 kafka-leader-election.sh 사용을 권고합니다.
https://issues.apache.org/jira/browse/KAFKA-8405
다음 포스팅에서는 브로커 불균형 ( Broker skew ) 의 상세 내용과 해결 방법에 대해 다뤄보도록 하겠습니다.
Reference :
https://kafka.apache.org/documentation/
https://hashedin.com/blog/re-balance-your-kafka/
https://medium.com/@mandeep309/preferred-leader-election-in-kafka-4ec09682a7c4
https://knight76.tistory.com/entry/kafka-%EB%B3%B5%EC%A0%9Creplication
