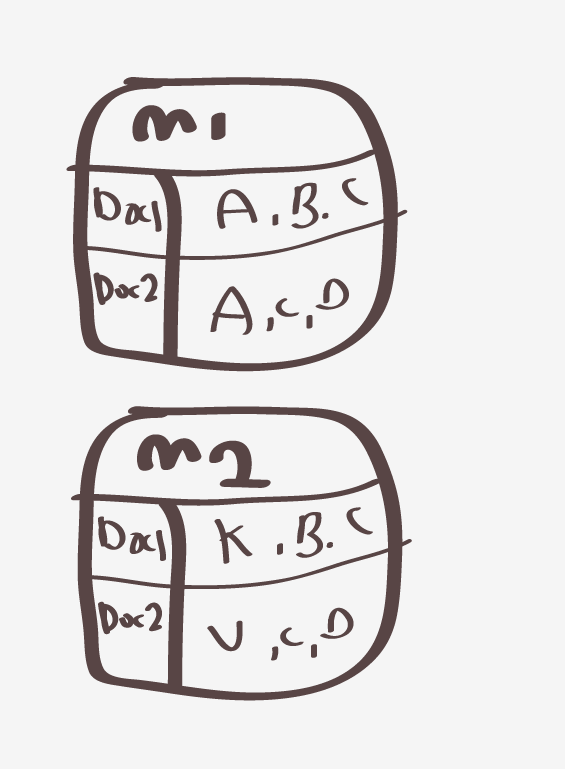
MapReduce WordCounting 알고리즘
가정 두개의 머신 M1,M2 그리고 Docs는 라인이 1개가정 그리고 Mi 마다 mapper 하나씩 호출 (mapper는 각라인하나마다 차례대로 호출)
(그림판 발그림)
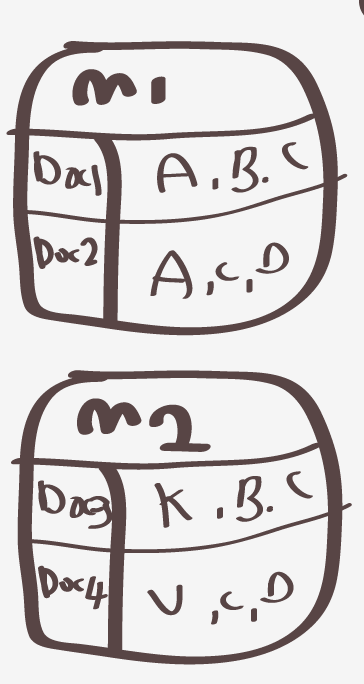
다음과 같이 있다고 가정한다..
그러면
맵페이즈를 거치게되면 다음과같이 나오게된다
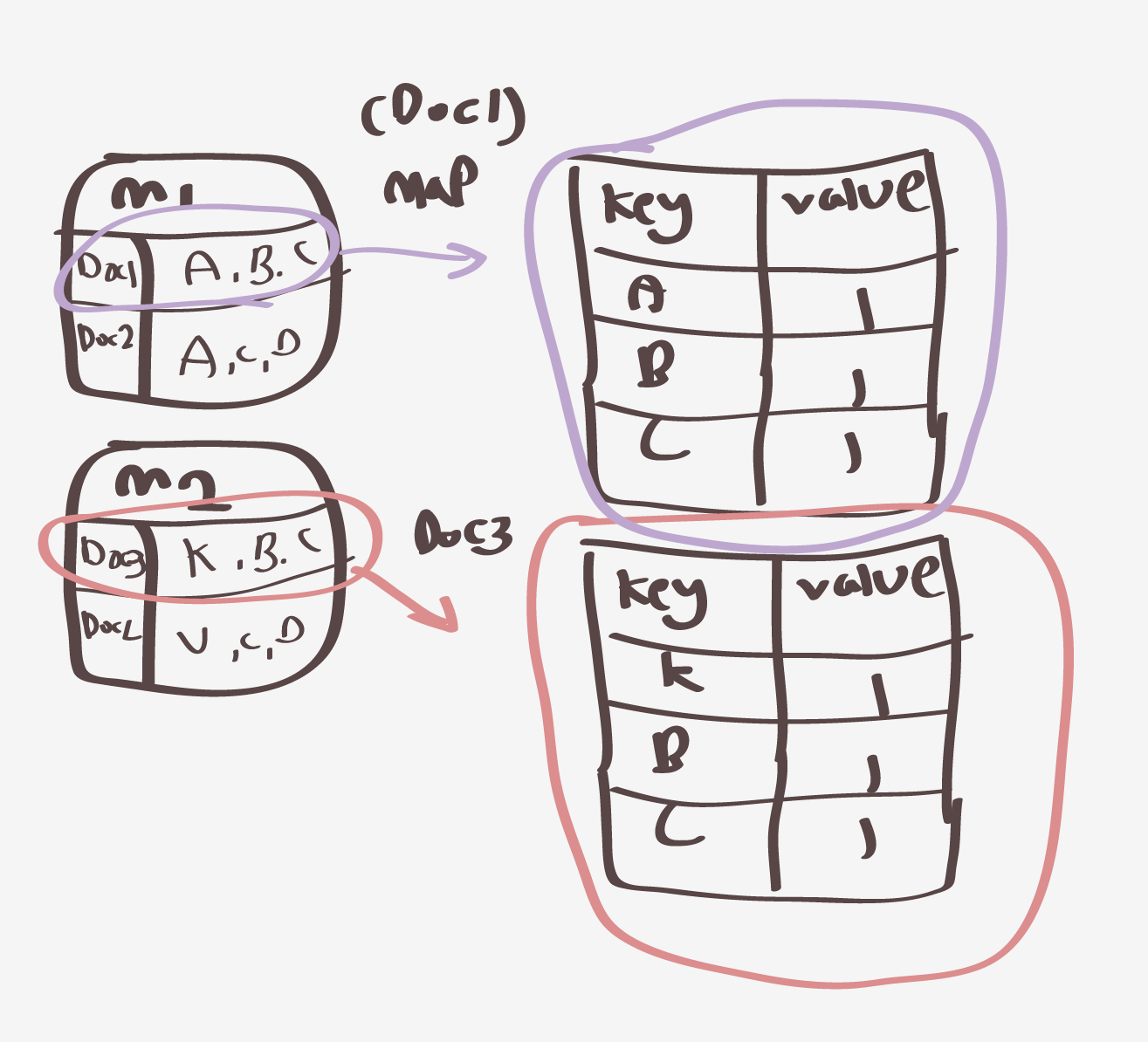
다음 이러한
m1 ,m2 모든 Docs 에대한 맵페이즈를 거치게된다면 (m1에 대한결과는 key -value로 구성했을때 다음과같이된다.)
다음은 m1 , m2를 가지고 셔플링으로 가게된다..
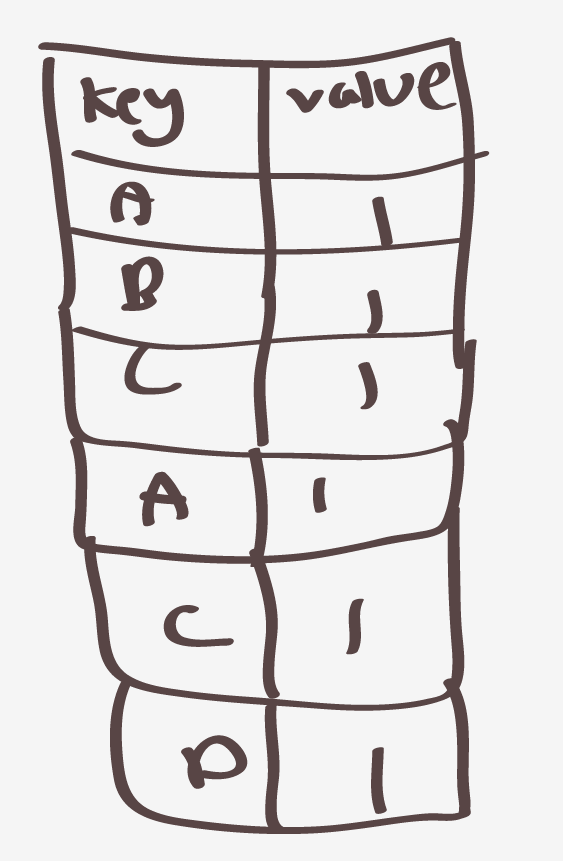
그러면 사실상 value-list로 만드는과정인데 m1에대해서만 만들어진 페이즈를 가지고 셔플링을 하게되면
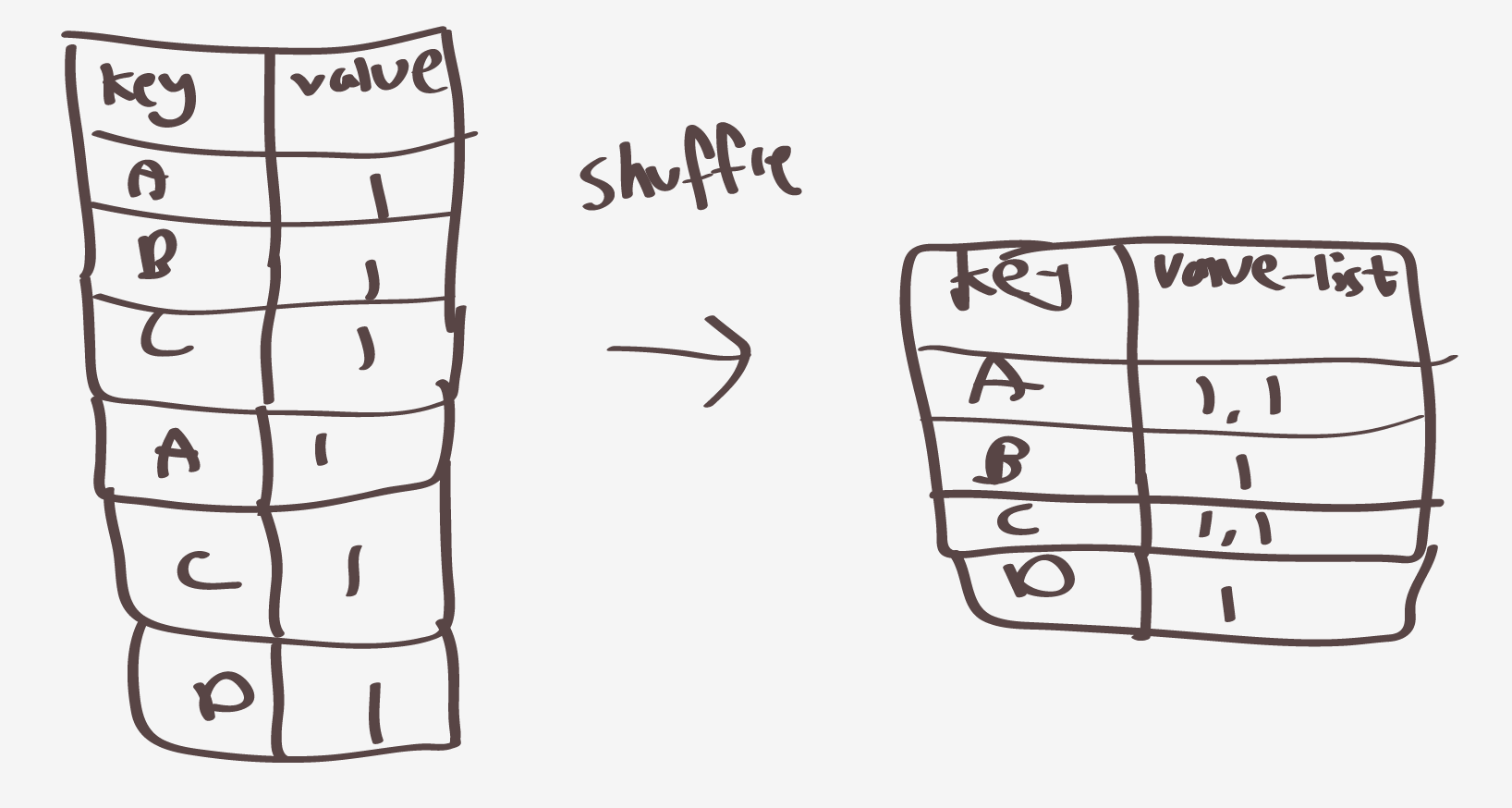
다음과같이 된다 이로써 셔플링 페이즈는 끝
그렇다면 이러한 셔플링 페이즈 결과로 리듀스 페이지를 가게된다
리듀스페이지는 Reduce함수를 호출하지만 해당 알고리즘은 워드 카운팅이기 때문에 각각 갯수를 새주는 과정을 진행
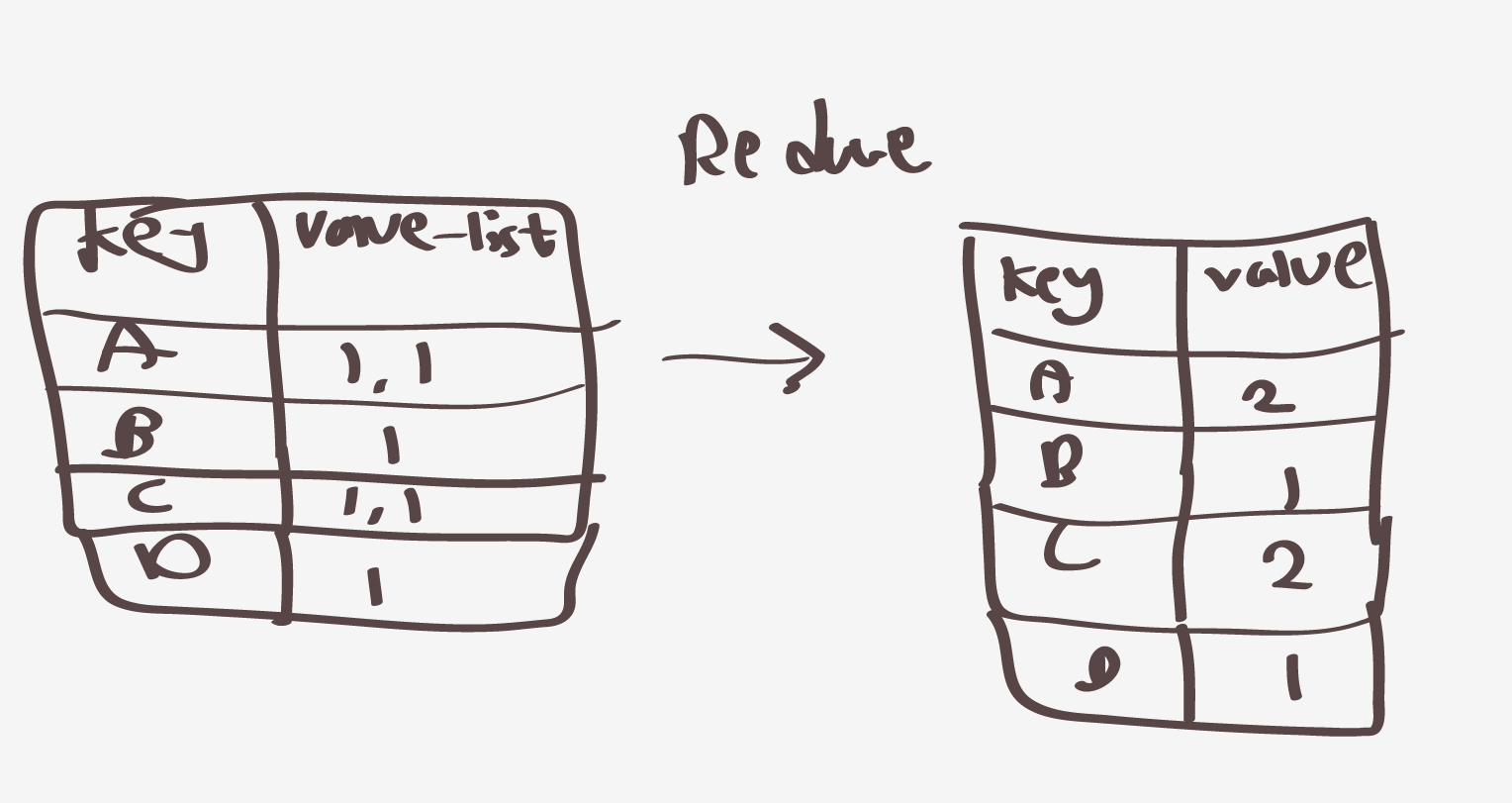
이렇게된다
한번에 그림으로 나타내면 (m1에 대해서만)
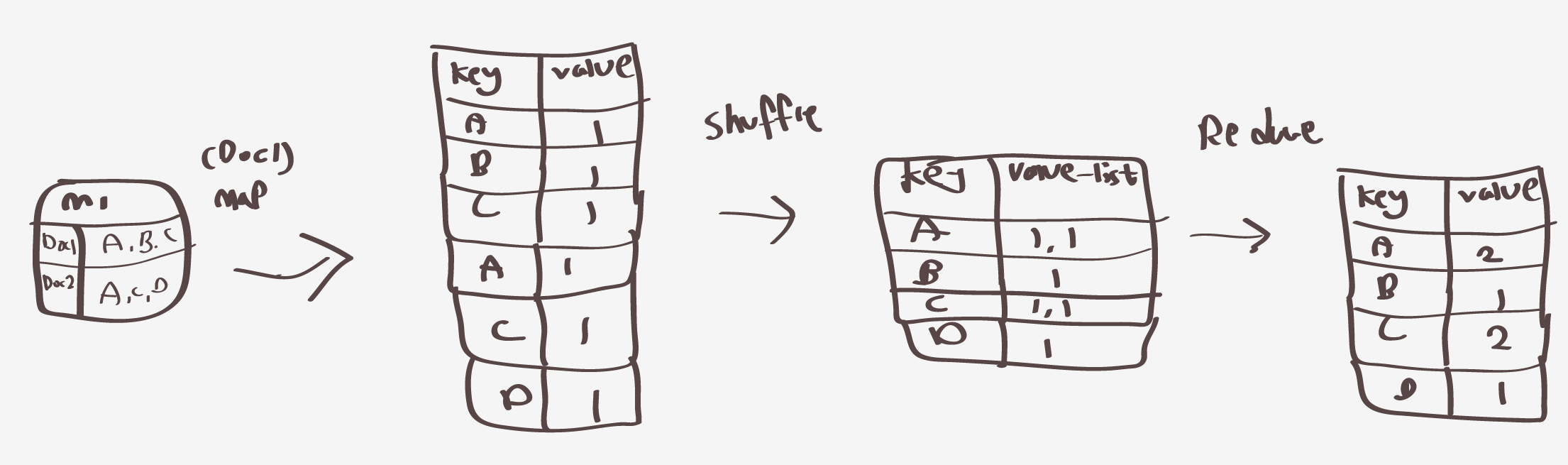
요렇게된다
이러한 문서들을 m1,m2이렇게나눳지만 여러개로 분산해서 처리한다고한다..
Combine 함수?
Map함수에 결과크기 줄여줌
사실 Reduce함수의 역할을 Shuffle전에 한번해줌 그렇게함으로써 셔플링비용을줄여줌
따라서 맵리듀스 알고리즘 디자인에서좋음
? 먼소린지모르게쒀요 ..
그렇다면 아까 map~shuffling 한그림을다시보면
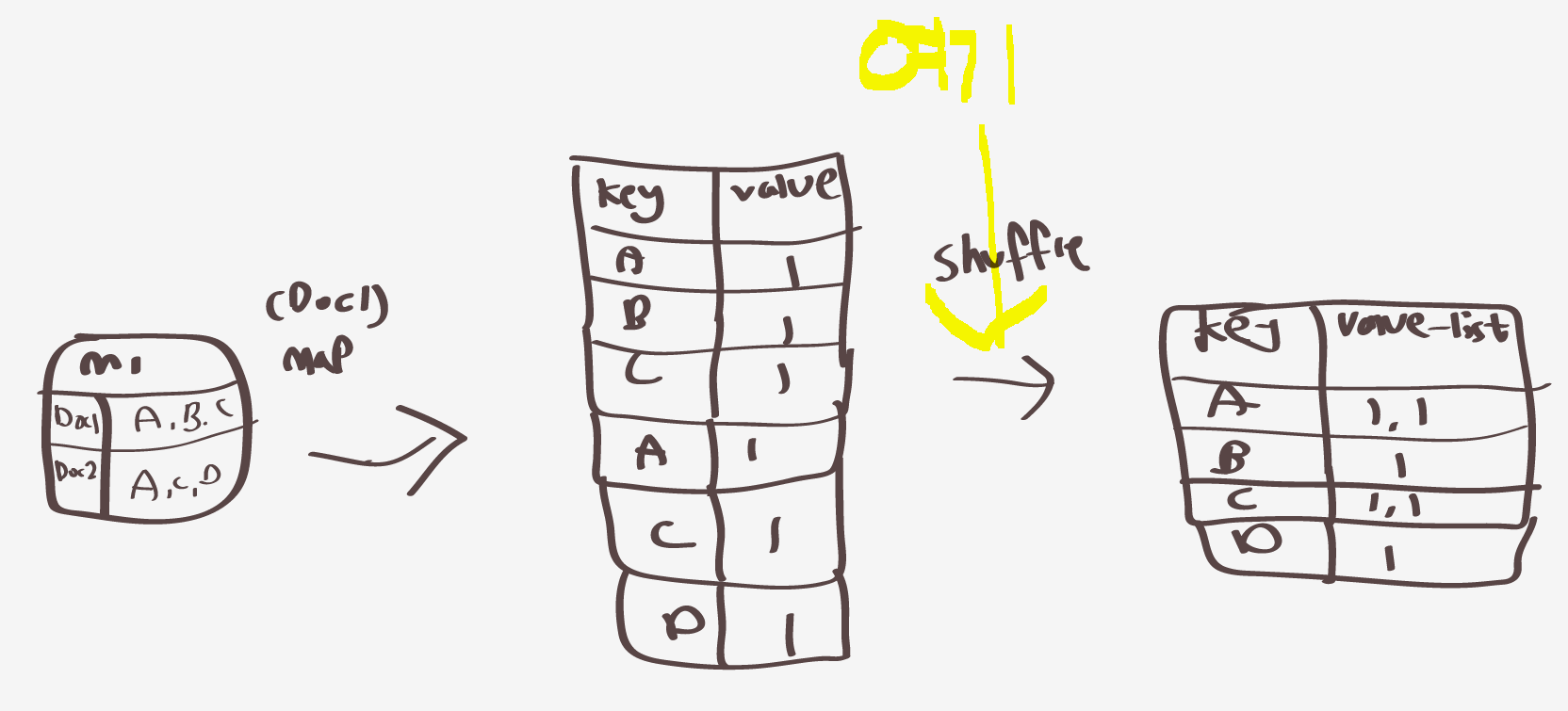
셔플링전 여기 에 combine이 적용된다고한다
그렇다면 적용을 하게되면
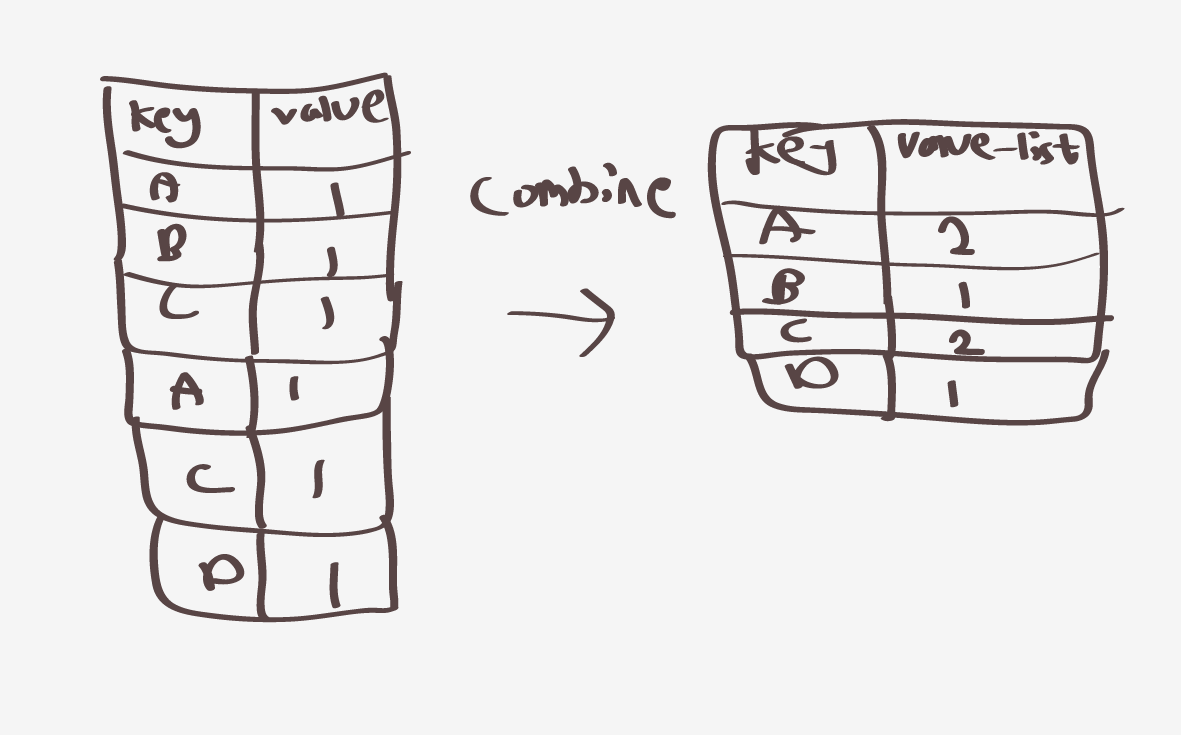
이렇게되고
m2에서도 combine 한결과가 2,1,2,1 똑같이 있다고 가정하게되면
맨처음 맵페이즈에서 한 doc3,4랑은 다른 m2임.. 그냥임의가정
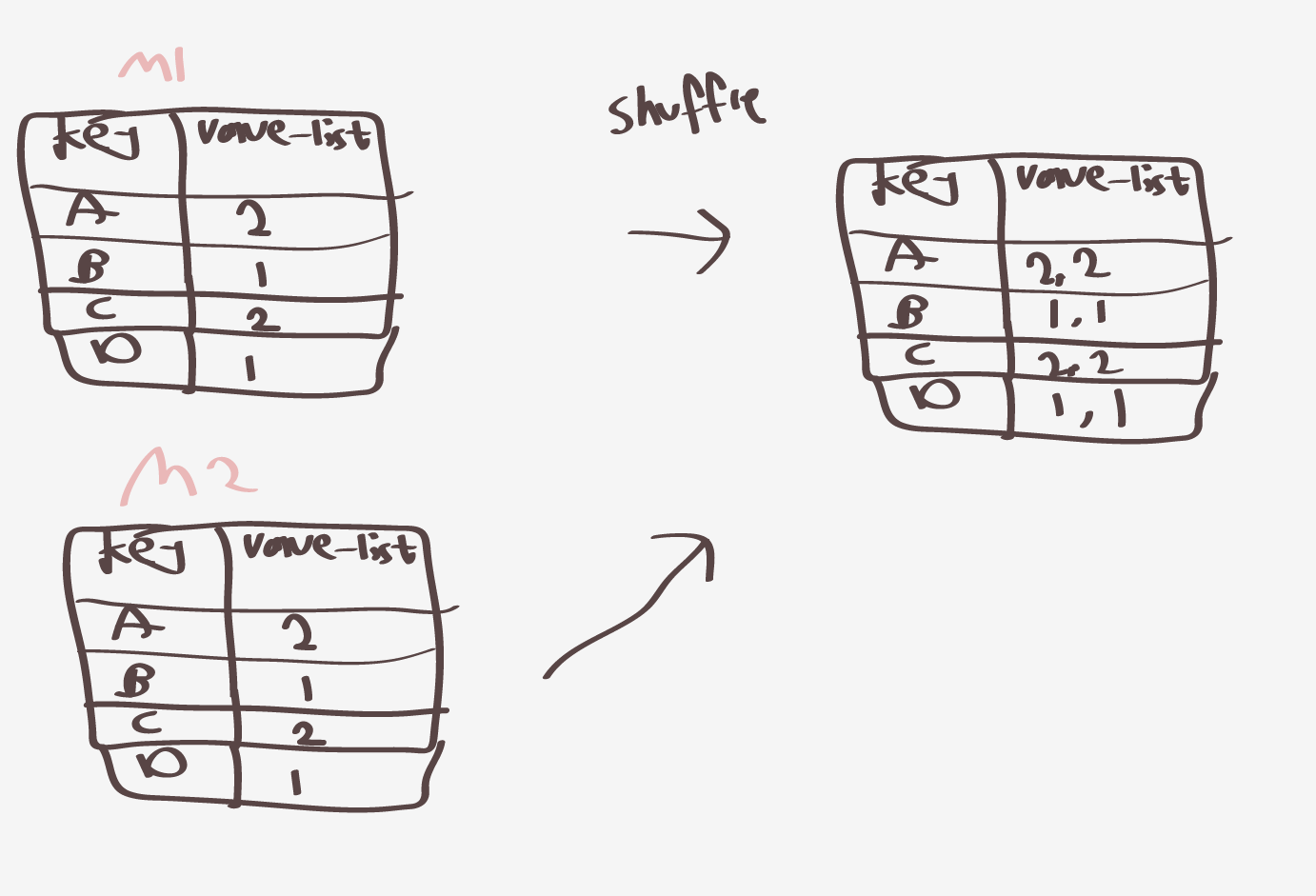
요렇게진행하게되고
나중에 리듀스할때 좀더 줄어들기때문에 결국
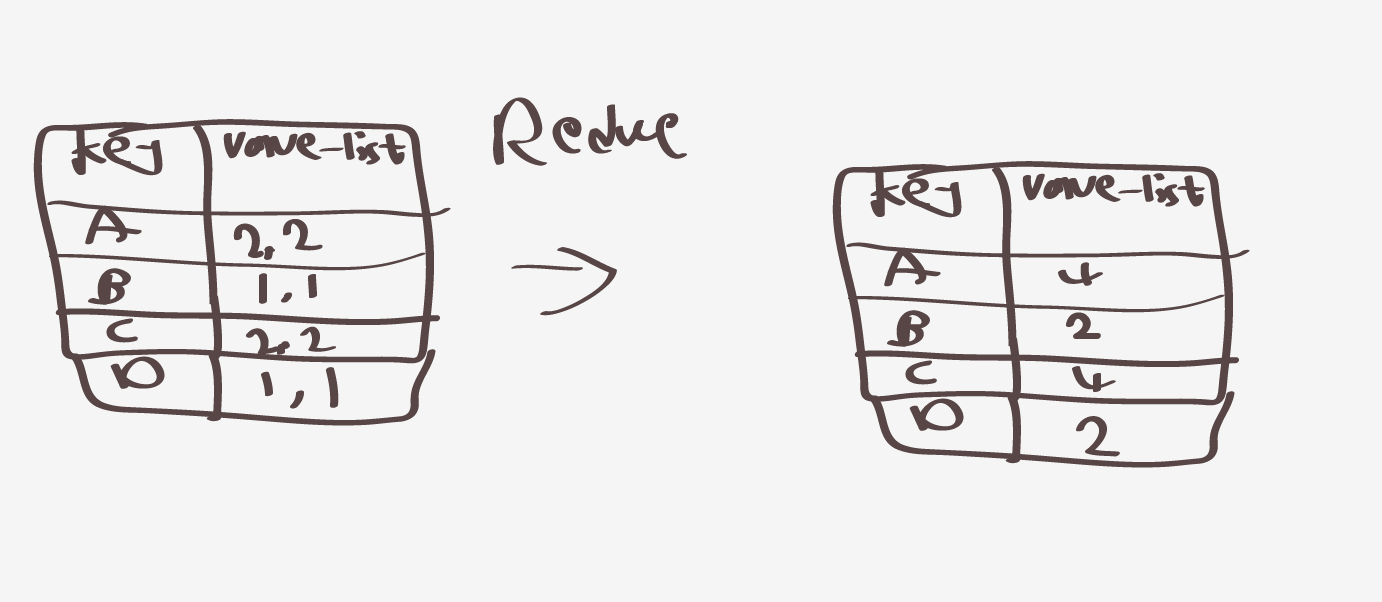
다음과같이 결과가나오게된다.
==> 정리
- mapper : map함수 (setup cleanup 가능)
- reducer : reduce함수 (setup cleanup 가능)
- combine : reduce 미리해줌 , 셔플링비용 네트웍 트래픽감소
(setup : 첫 map이나 reduce 함수 호출전에 수행 , cleanup : 마지막 map 이나 reduce 끝나고 수행하는것..)
결국 setup 과 cleanup 함수는 해당 사이클이 저렇게된다고 저기에 각자입맛에 맞게 커스터마이징이 가능하다는것같다..
