※ 본 포스트는 인하대학교 지능형반도체 연구실의 최영규 교수님의 허가 하에 작성되었습니다.
※ 교수님의 설명에 해당하는 내용을 제외하고, 제 의견은 노란색 글씨로 작성 하겠습니다.
※ solution에 대한 코드는 절대 제공되지 않으며, 수업진행에 필요한 모든 도움은 최영규 교수님의 자료 및 이메일을 참고하길 바랍니다.
요약 + 간단한 의견으로 구성됩니다.
자세한 내용은 반드시 강의를 참고해주시길 바랍니다.

이번주에는 코드 리팩터링을 해서, fir filter 코드를 최적화하고 가속화 해봅니다.
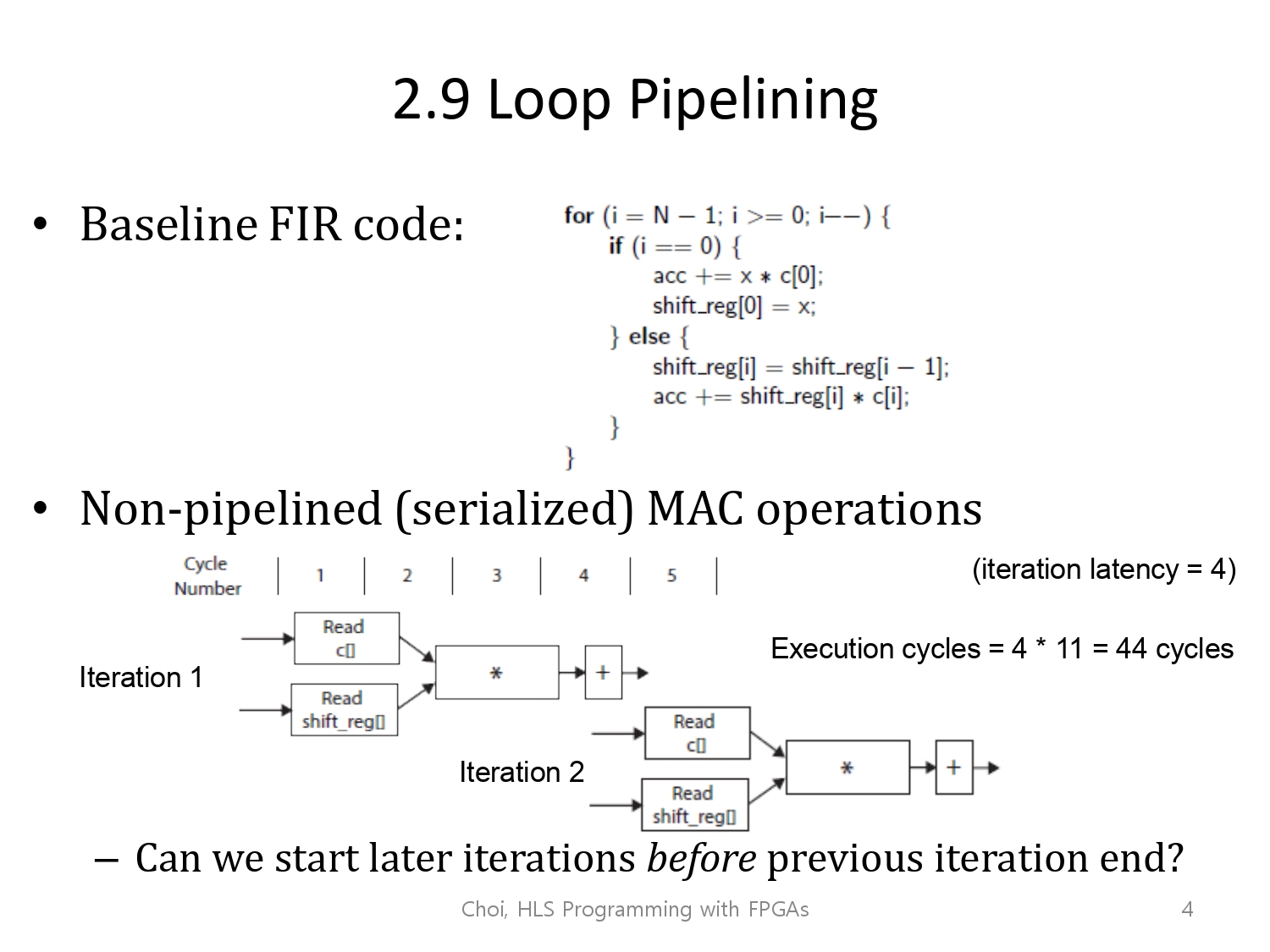
위 자료는, 코드에 대한 실제 연산(CPU) 수행과정입니다.
반복 연산을 수행하는 과정에서 첫번째 반복이 종료될 때, 두번째 반복이 수행되고 있음을 볼 수 있으며, 한 개의 반복마다 4개의 사이클이 소요되는 것을 볼 수 있습니다.
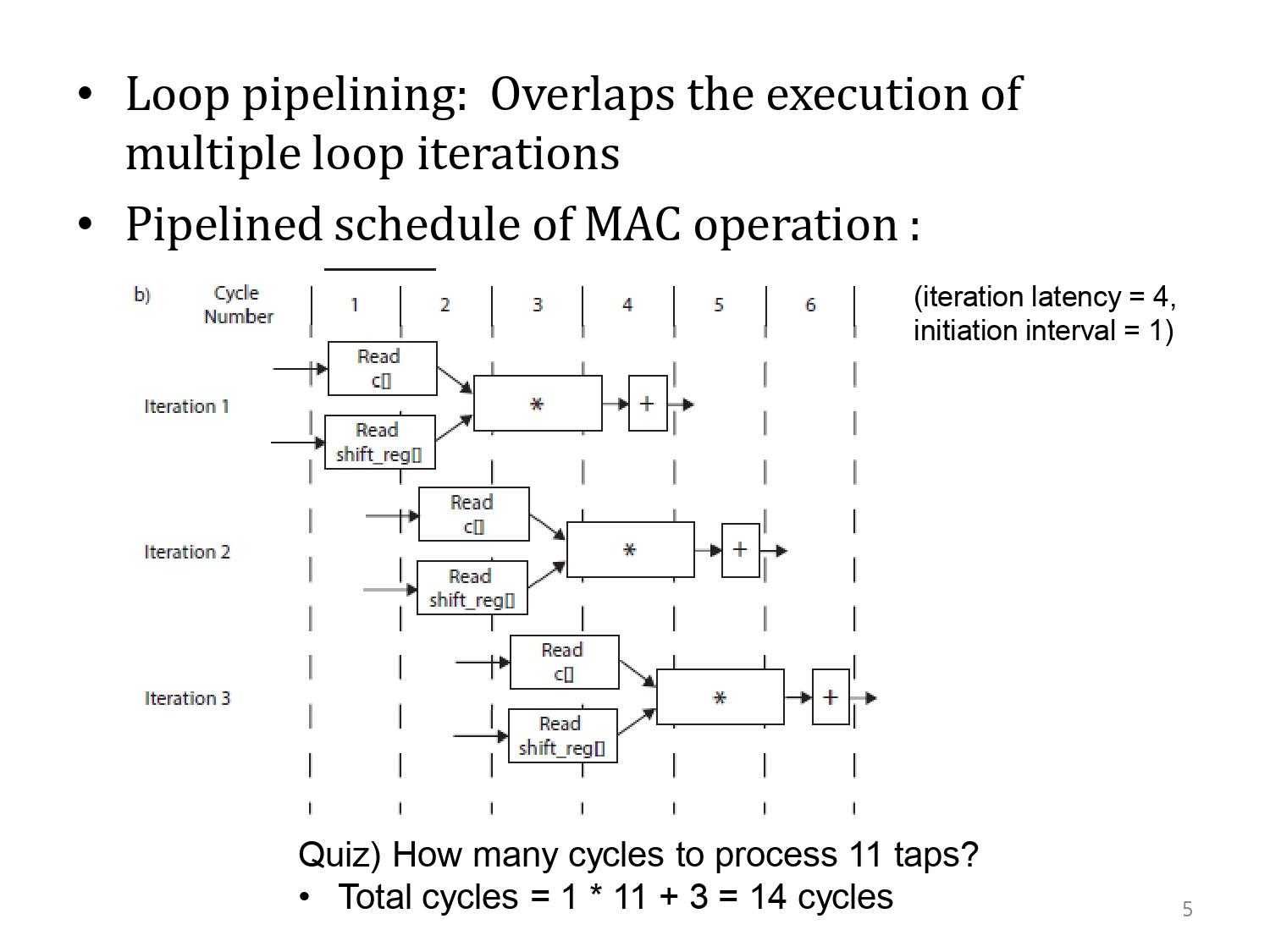
루프 파이프 라이닝은 이런 루프의 실행을 중첩시키는 것입니다. 즉, 한 개의 반복마다 4개의 사이클이 소요되는 것을 최대한으로 당겨서 1개의 사이클로 줄이는 것입니다.
이는 각각의 루프가 동일 시점에서 시작하지 않습니다. 최대한 다음 샘플을 빠르게 실행할 수 있게 당겨온 과정이라 볼 수 있습니다. 결과적으로, 동일 시점에서 각 루프는 서로 다른 스테이지를 겪고 있음을 알 수 있습니다.
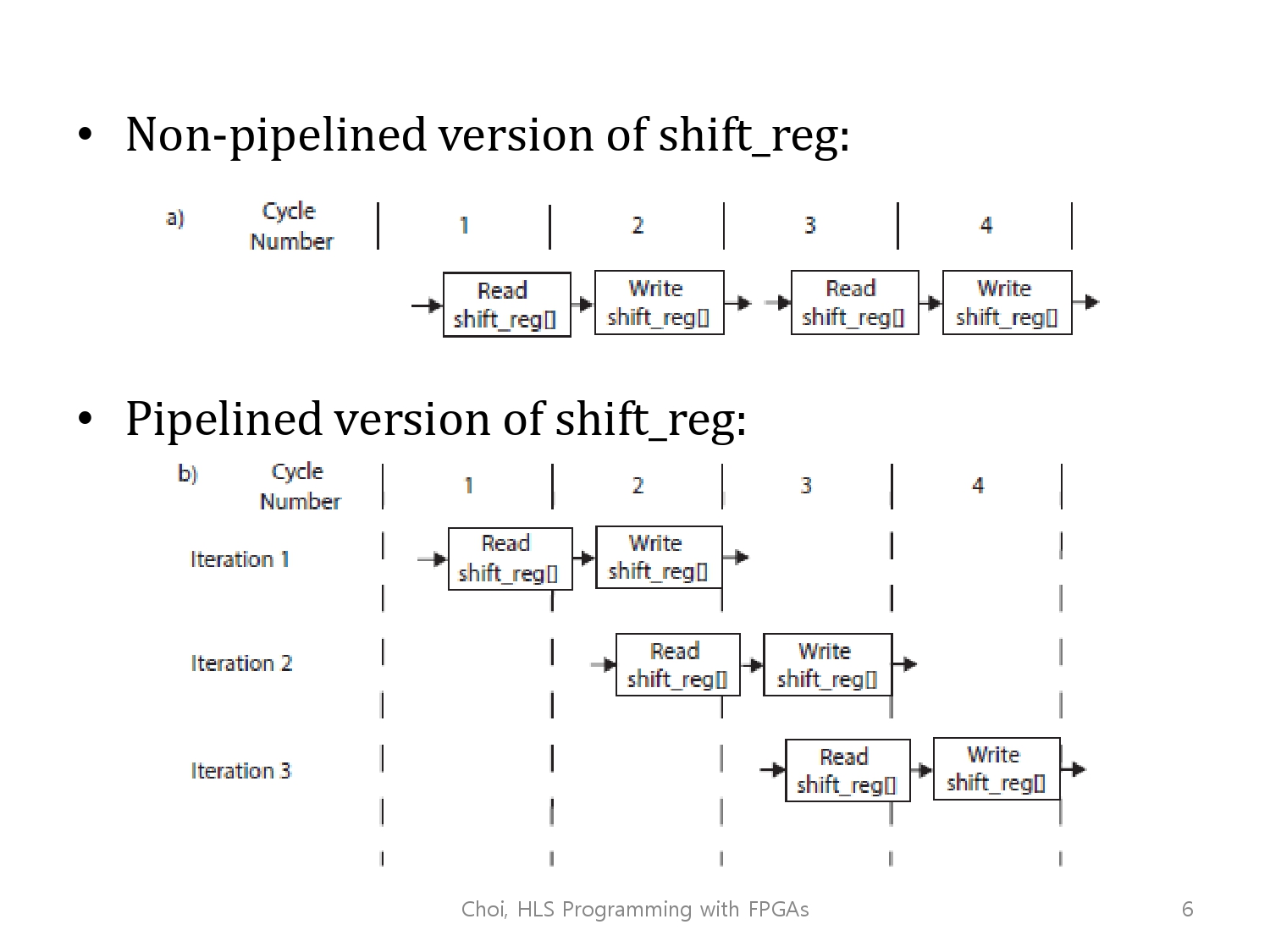
이 핵심은 동일 시점에 같은 stage를 절대로 공유하지 않는다는 것인데(시작 시점이 다르기 때문), 이를

먼저 loop pipelining 코드입니다. #pragma HLS pipeline을 올바른 위치에 놔주면 자동으로 파이프라이닝을 적용해줍니다.
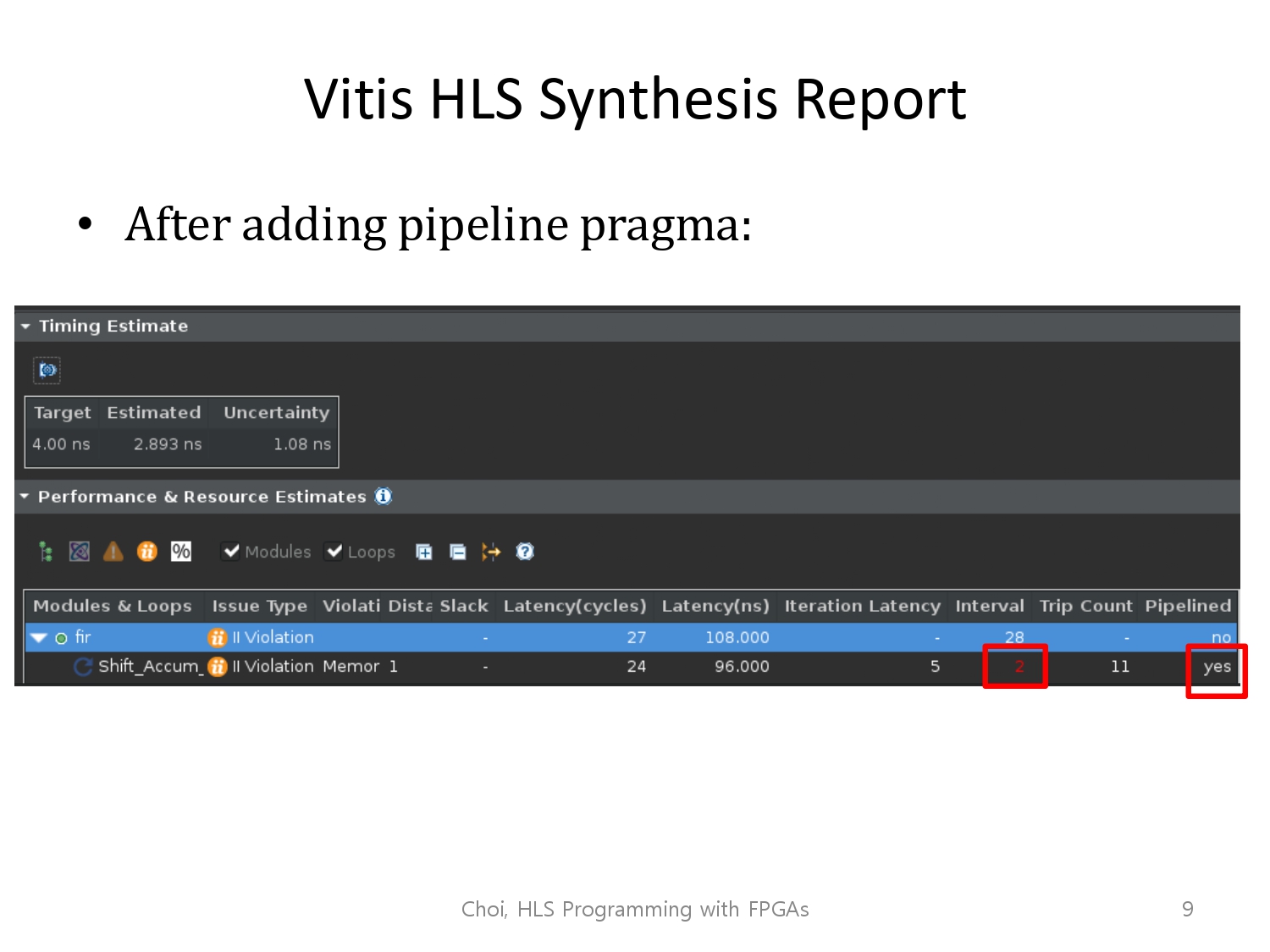
파이프라이닝이 적용됐다는 메시지는 뜹니다.
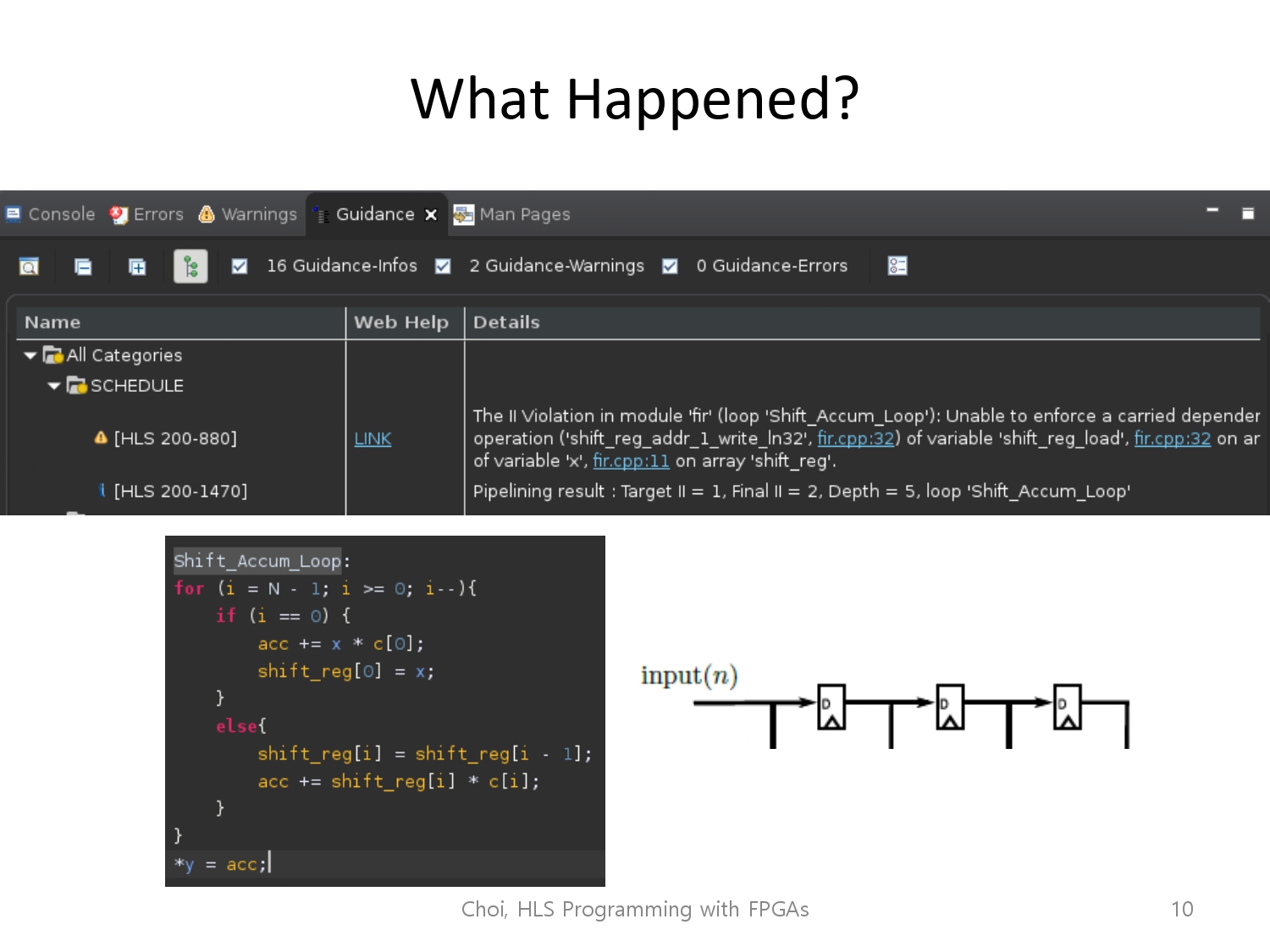
다만, 문제가 실제로 최적화를 하는 과정이 동작하지 않았는데, Loop piplining을 자동으로 수행해주는 과정에서 위의 코드 스타일이 최적화 기능을 동작하지 않게 하였습니다.
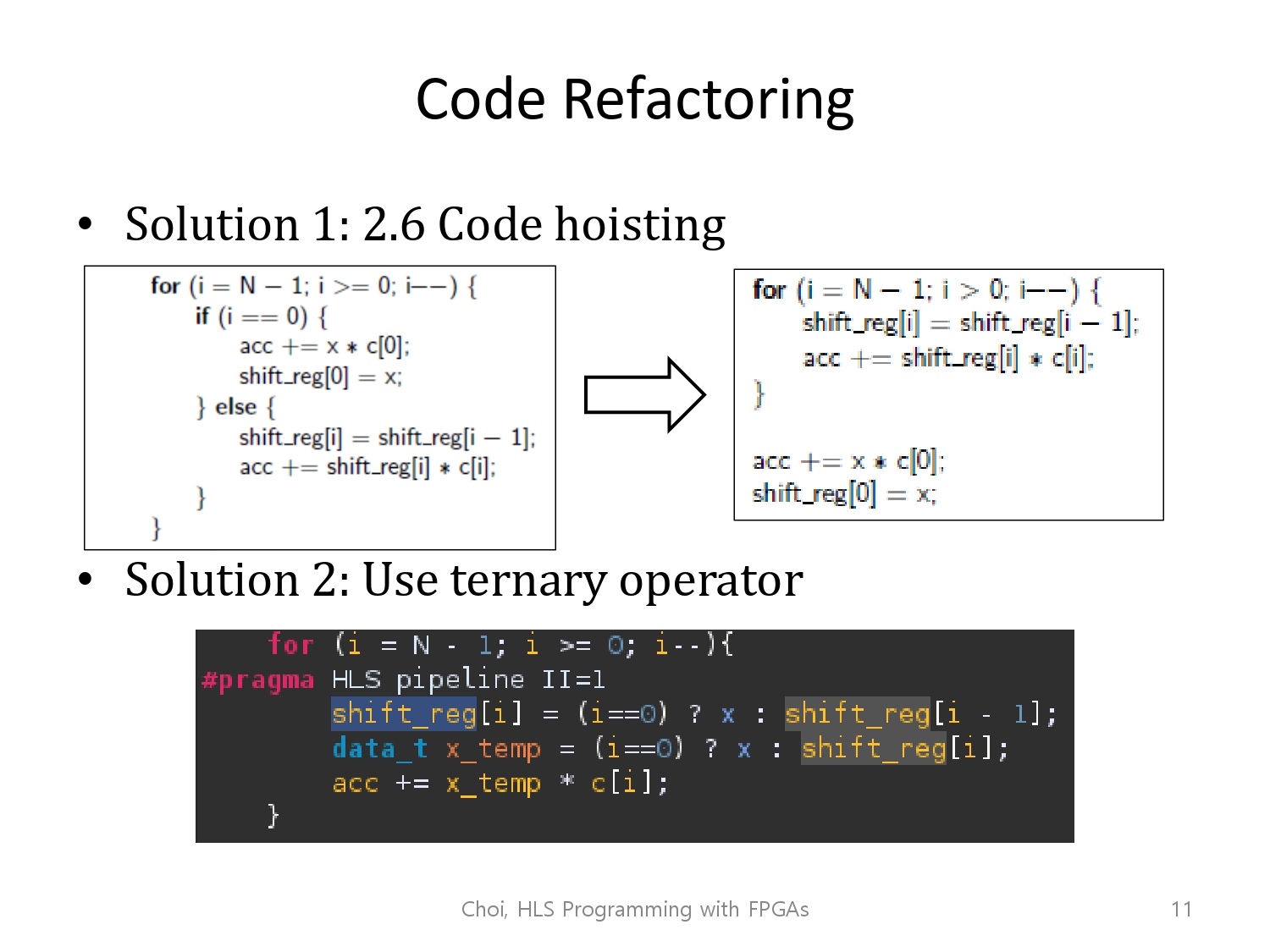
이에 대한 코드 리팩토링을 수행하는데, 수정된 코드들의 공통점은 코드를 가속하는 tool이 헷갈리지 않게 하는 역할을 수행한다는 것입니다.
if else 분기로 코드가 나뉘게 되는데, 이는 for문의 각각의 반복을 서로 다른 수행으로 인식하게할 수 있어서 그런 것이라고 생각합니다. 따라서 분기에 따라 수행하는 코드라인이 바뀌지 않는 방식이라는게 공통점이라고 생각했습니다.(주관적)

Interval 값이 2에서 1로 줄어든 모습을 볼 수 있습니다.
이로 인해 하나의 샘플에 대해 27사이클 => 17사이클로 감소했습니다.
이에 대한 speedup을 계산해보면, 하나의 샘플에 대한(샘플의 개수에 대한 변수는 변화 없으므로) 사이클의 변화만큼 빨라집니다.
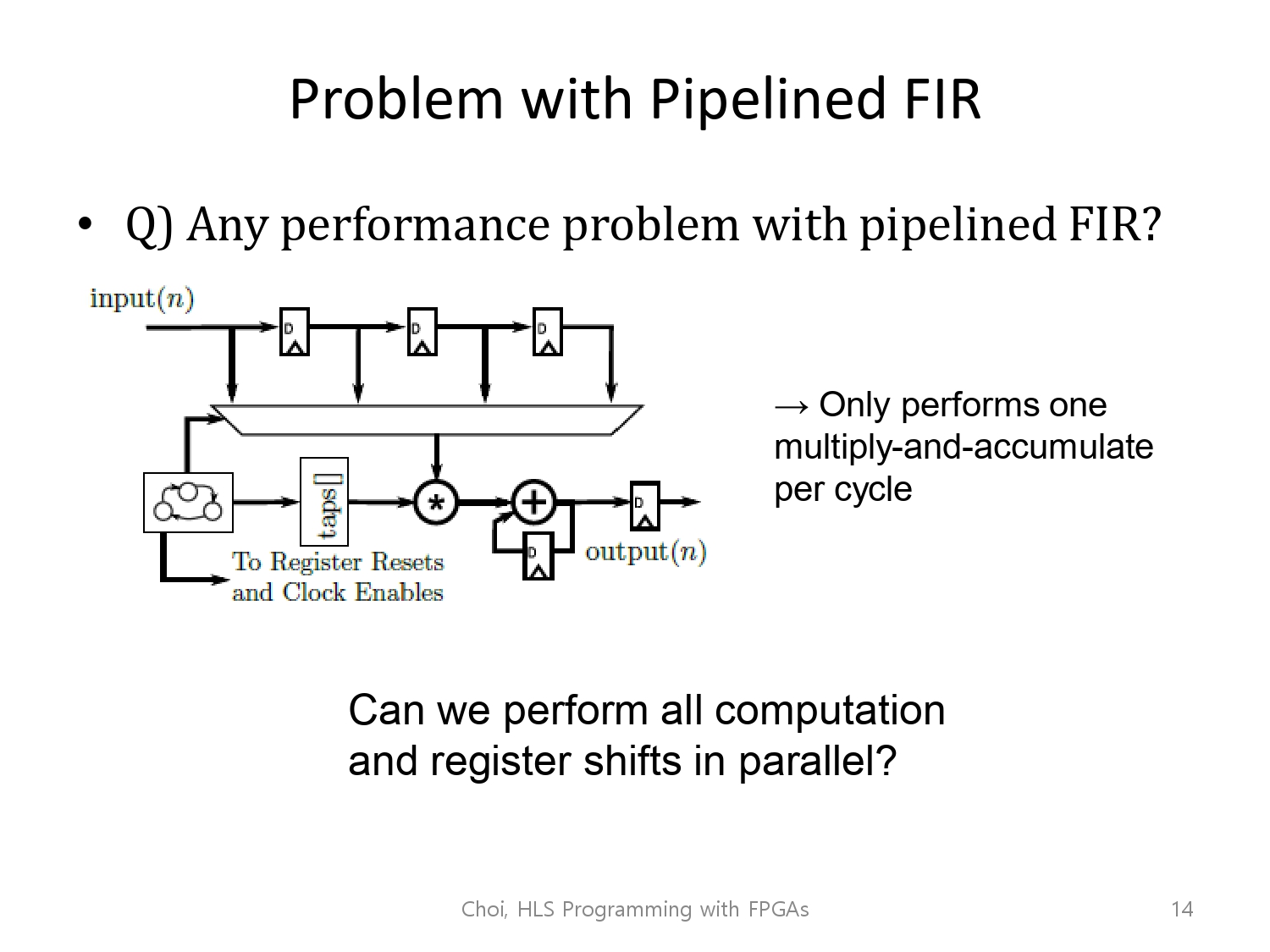
성능 개선은 파이프라이닝 만으로 끝나지 않습니다.
아예 연산 자체를 동일시점에 같이 시작하면(동일 시점, 같은 스테이지를 겪게됨) 더 빠르게 할 수 있지 않을까요?
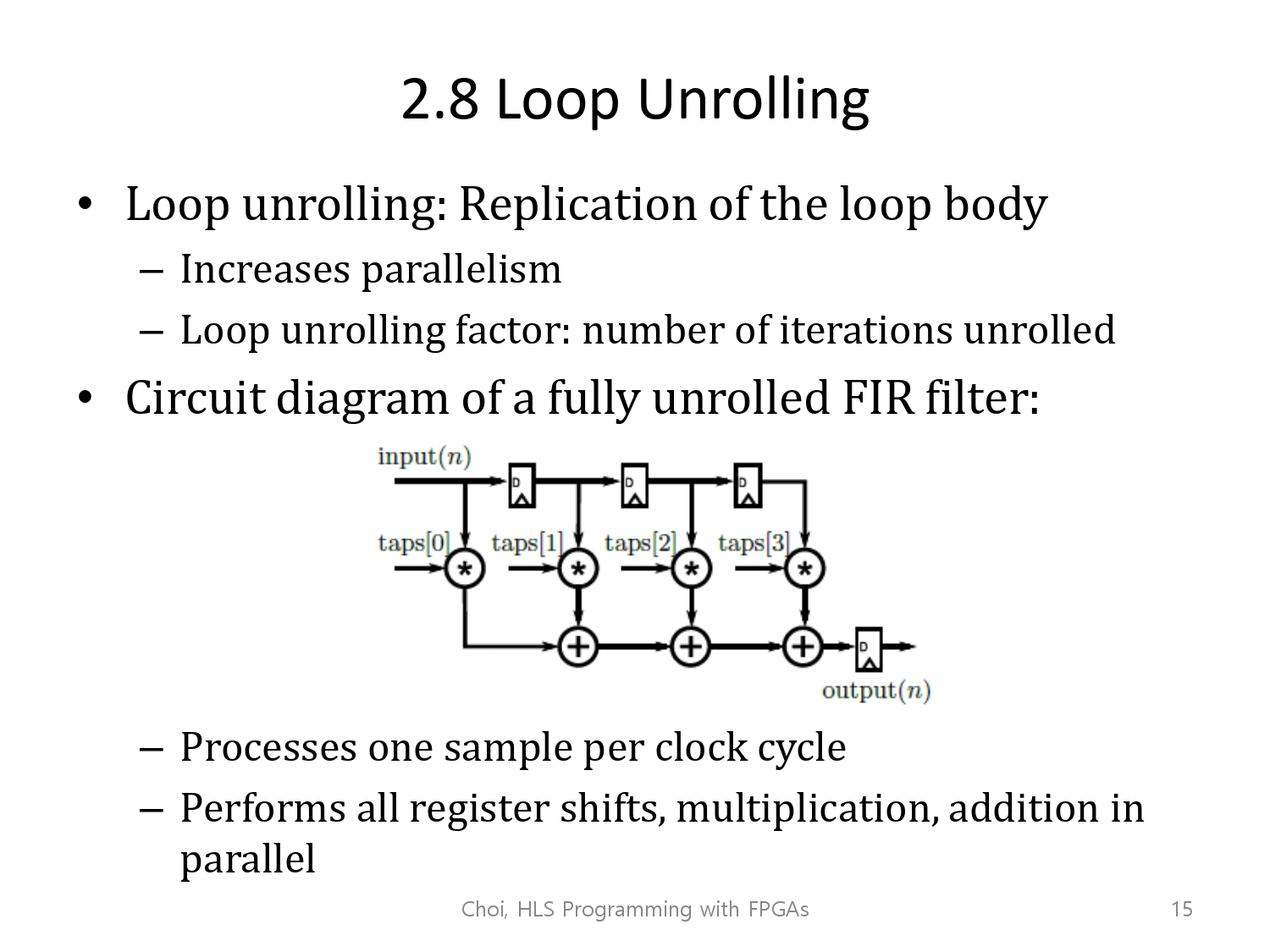
연산에 대해서 병렬로 처리하는 것을 loop unrolling이라 합니다.
pipeline은 반복 사이의 텀을 최대한 줄였지만, 이전 반복이 확실하게 실행되고 난 후에 다음 연산이 실행되는 과정이라, 같은 stage를 각 반복이 같이 사용할 수 없기에 각 반복에 대기 시간이 조금씩 존재합니다.
그에 반해, unrolling은 아예 동일 시점에 같이 시작을 하는 것입니다.
pipeline는 다른 연산자를 병렬로 하는 거라 상관 없는데
unroll은 같은 연산자를 병렬로 하는 거라 랜덤메모리 접근을 쪼개서 비순차적 접근 가능하게 해줘야합니다
= 설정 필요

차이점
pipelining : 다른 종류의 연산자가 병렬적으로 수행됨, (컴퓨팅의 다른 stage에서)
loop unrolling: 같은 종류의 연산자가 병렬적으로 수행됨, (다른 데이터에 대해서)
이해를 돕기 위해 예시를 들어드리겠습니다. (설명을 돕기위한 단순 예시입니다)
반복이 발생하는 상황입니다.
반복 각각이 서로 영향을 미치지 않고, 한 종류의 stage를 여러개 동시에 이용이 가능한 상황(예시임)에서, 모든 연산을 동시에 시작할 수 있습니다. => stage 중첩 (unrolling)
반복 각각이 서로 영향을 미치거나 혹은, 한 종류의 stage를 동시에 이용이 불가능한 상황(예시임)에서는, 연산을 동시에 시작할 수 없습니다. => stage 중첩 불가 (pipelining)
이를 바탕으로 차이점을 이해하는데 도움이 되시면 좋겠습니다.
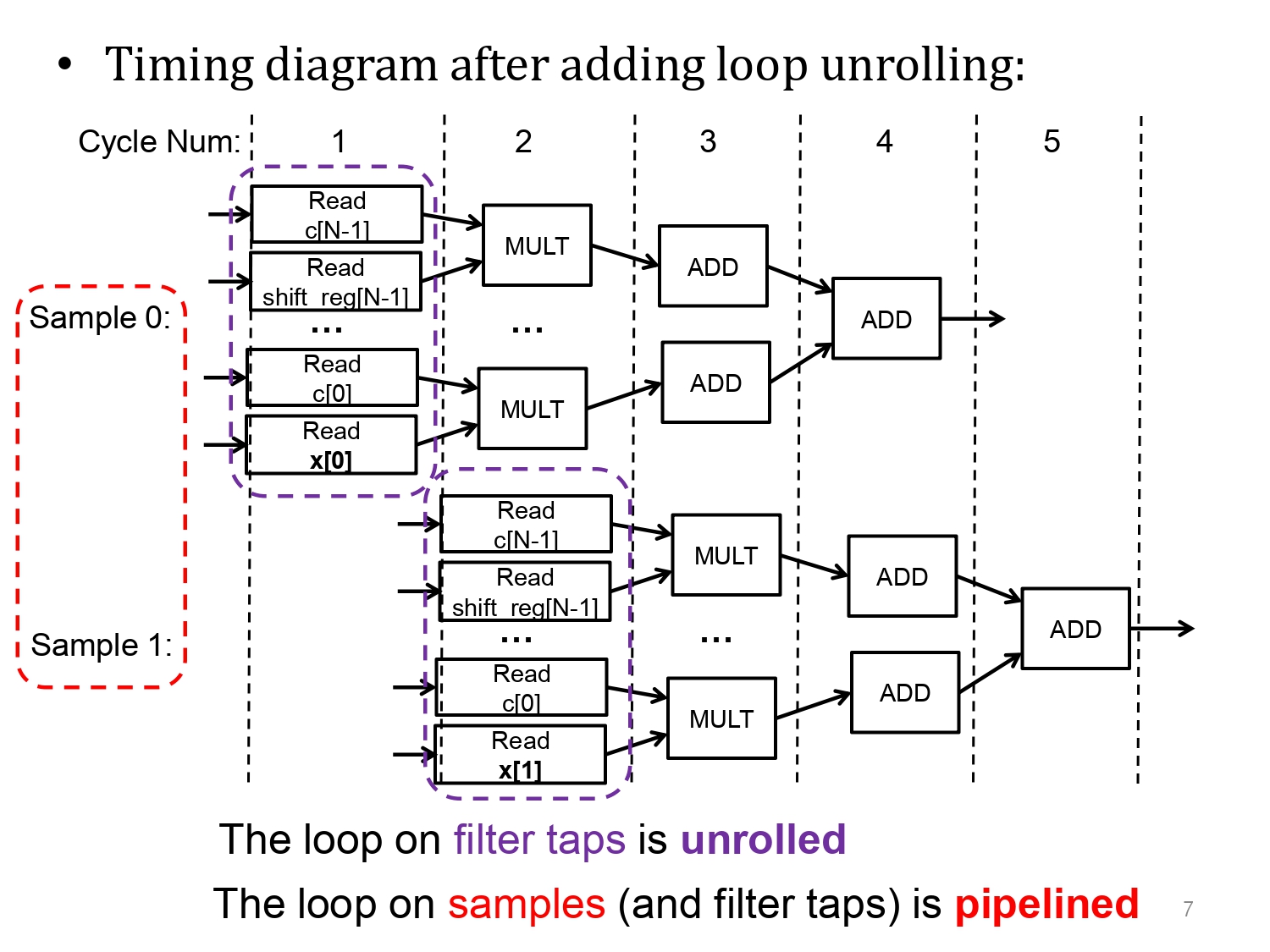
제가 앞서 설명한 내용에 더불어, 차이점을 가장 잘 보여주는 교수님의 자료입니다.
보라색으로 묶인 연산덩어리가 unrolling, 붉은색으로 나뉜 각 sample이 pipelining입니다.
이전 슬라이드의 설명으로 예시를 들면, unrolling은 각각의 연산이 따로따로 병렬처리가 가능한 상황에서 병렬처리가 된 것입니다.
그에 반해 Sample간에는 pipelining이 되었는데, 한 종류의 stage를 다른 sample끼리 동시에 차지할 수 없는 상황이어서, stage내 중첩이 되지 않고, 최대한 빠르게 다음 샘플에 대해서 이어서 수행한 모습입니다.

unrolling의 사용법입니다.

이 부분에 대해서 소스코드는 직접 제공하지 않습니다.
fscan, fprintf 등 어떤 함수는 host(fir_test.cpp)에서만 사용가능하며, 그 외에 어떤 함수는 kernal(fir.cpp)에서만 사용가능하다는 것을 알고 있으면 유용합니다.
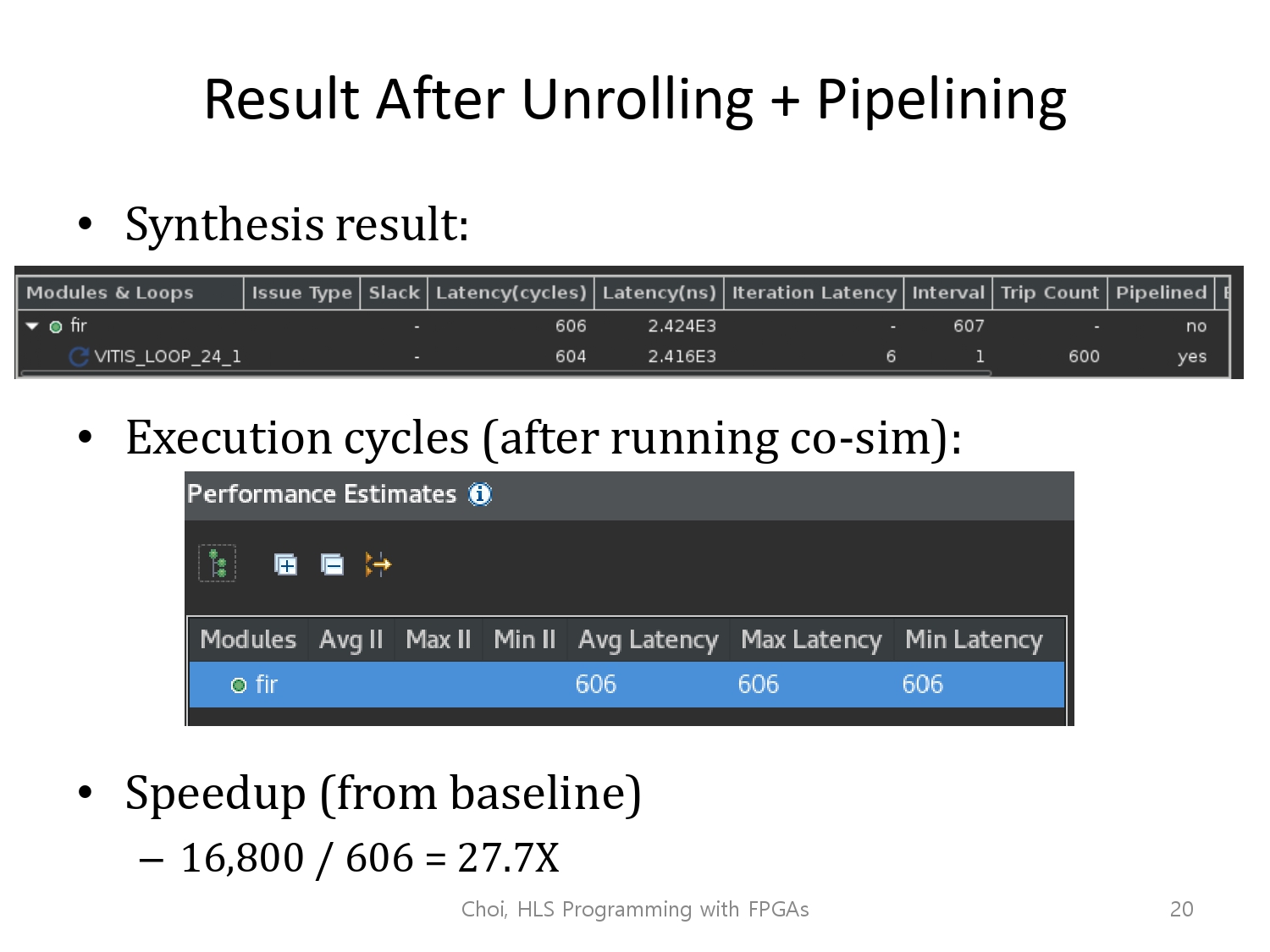
unrollong 까지 적용된 모습입니다. 아마 버전에 따른 차이는 있겠지만, 대략적으로 근사한 speedup을 얻어냈다면, 정답입니다.
감사합니다. 다음장에서 뵙겠습니다.
