
SIFT
이미지에서 중요한 정보를 담고 있는 특징점(key point)를 뽑아내는 알고리즘이다.
key point를 뽑아낸 후 그 근처에 있는 기술자도 뽑아내는 과정을 추가적으로 알아보자.
이때 기술자는 스케일, 회전, 명암 변화에도 끄떡없는 중요한 정보들을 갖고 있다.
기술자가 중요한 이유는 추후에 object detection에서 해당 point들을 가지고 detection을 수행할 수 있기 때문이다.
크게 3단계로 구성된다.
1. 다중 스케일 영상 구축
가우시안 스무딩과 피라미드를 이용한다.
각 피라미드들의 집합을 ‘옥타브(octave)’ 라고 부른다.
한 옥타브당 6개의 이미지가 피라미드처럼 쌓여져 있다.

첫번째 옥타브에서 맨 밑 이미지는 σ=1.6으로 가우시안 스무딩 된 영상에서 출발한다.
이후 첫번째 옥타브에서 두번째, 세번째,… k번째 이미지의 σ값은 이전 이미지의 σ에 k값을 곱하여 만든다. (2의 3분의 1승) 등비수열로 옥타브의 σ 계산.
따라서 첫번째 옥타브의 첫번째 이미지는 원본 이미지에 σ=1.6 스무딩 된 영상,
첫번째 옥타브의 두번째 이미지는 원본 이미지에 σ=2.0159 스무딩된 영상(σ=1.6 x k)
그러나 문제가 있다. i가 클 수록 σ값이 커지고 필터가 커져서 연산이 오래걸리게 된다.
따라서 원본 이미지에 kσ값으로 스무딩 하는 방식보다 이전 피라미드의 이미지와 현재 적용해야하는 σ 값의 차이를 이용하여
즉, σ값의 차이를 구하여 이전 피라미드의 이미지에 스무딩하는 방식을 채택한다.
그 다음 옥타브의 맨 밑 이미지는 이전 옥타브의 4번째 이미지(원본이미지 기준 σ=3.2로 스무딩 된 영상)을 반으로 축소하여 얻는다. 그리고 위의 과정을 반복한다.
2.다중 스케일 영상의 미분값 추출
이제 옥타브들이 구축이 되었다면 이미지들에게 정규 라플라시안 필터를 콘벌루션하여 미분 값을 구한다.
그러나 연산 시간을 줄이기 위해 정규 라플라시안과 매우 유사하다고 증명된 DOG를 이용하기로 한다.
DOG는 이웃한 영상끼리 화소별로 빼면 되기에 아주 빠르게 계산이 가능하다.
(i번째 이미지와 이웃 이미지와의 뺄셈)
이렇게 미분값을 얻어낸다.
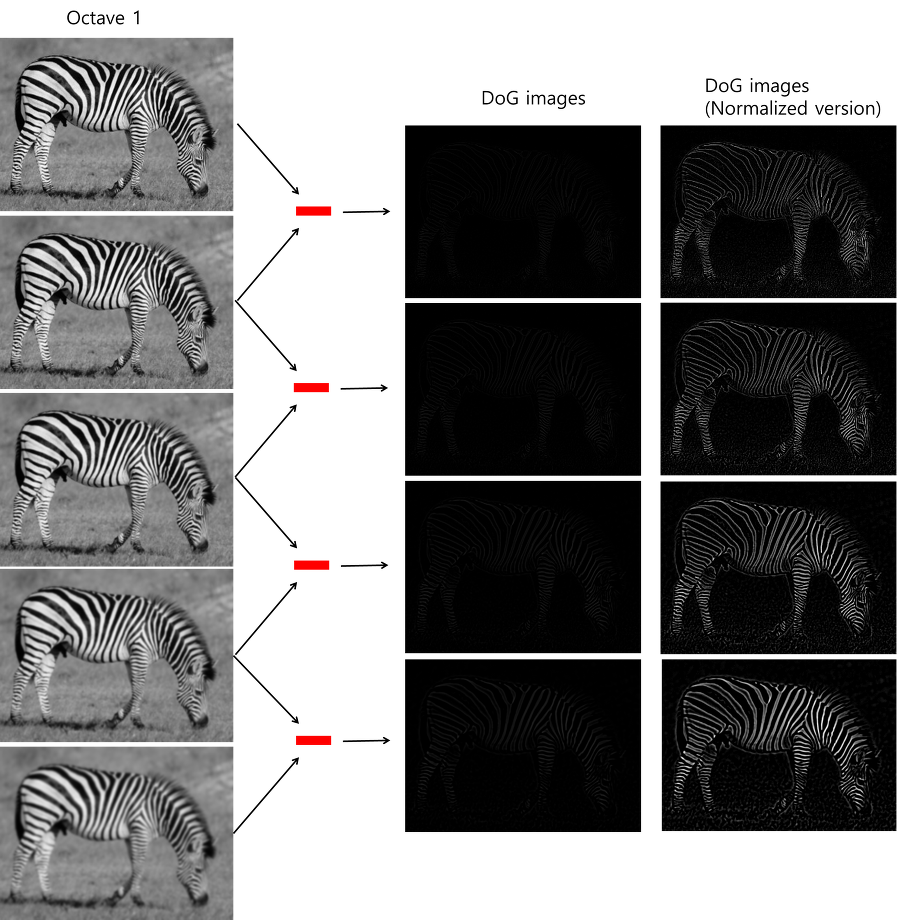
3. 특징점 검출
이제 DOG 영상에서 극점을 찾아 특징점을 검출해보자
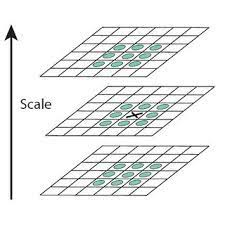
i번째 DOG영상에서 특징점 여부를 확인하고 싶은 point를 X라고 두자. i번째 이미지의 X이웃화소 8개, i-1,i+1 영상의 이웃화소9x2개 해서 총26개의 이웃화소와 X값을 비교한다.
X의 화소가 26개의 화소보다 크다면 X를 극점으로 인정하고 특징점으로 취한다.
이때 특징점으로 추출된 화소위치를(y,x,σ,i)로 표시한다.
(y,x=화소위치,σ,i는 스케일 정보를 담아낸다,σ=옥타브,i는 몇번째 영상인지)
이렇게 추출된 특징점 후보들을 threshold와 비교하여 임계값을 넘은 특징점들만 최종적으로 특징점들로 취한다.
이제 이렇게 추출된 특징점들 주위에 존재하는 기술자까지 뽑아내보자
SIFT 기술자(descriptor) 추출
SIFT 특징점의 위치와 스케일 정보를 알아냈다(y,x,σ,i)
하지만 물체를 매칭하는 데 스케일 정보만을 이용하기엔 부족하다
그렇기에 스케일 ,회전, 명암 변화에도 robust한 기술자를 찾아냃 필요성이 있다
1. 스케일 불변성 달성
(y,x,σ,i) 정보를 가진 특징점에서 기술자를 추출함으로써 스케일 불변성을 달성한다
(특징점에서 이미 스케일 불변 달성)
2. 회전 불변성 달성
지배적 방향을 정하고 방향을 중심으로 특징을 추출하면된다
지배적 방향을 정하는 방법은 아래와 같다
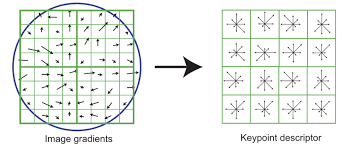
- 특징점으로부터 아주 작은 영역을 샘플링한다
예를들어 특징점이 (10,10)에 있다면 그 근처를 실수 값으로 확대하여 (10.1,10.1),(10.2,10.2) 이런 방식으로 아주 작은 영역을 샘플링한다.
그러나 우리가 알고 있는 정보는 (10,10),(11,11)으로 int형 정보다 그래서 아주 작은 영역을 샘플링하기 위해 보간법을 수행하여 작은 영역의 공간들을 채우고 거기로부터 샘플링을 진행한다
- 그레이디언트 강도와 방향을 계산한다
작은 영역들을 에지 연산자를 이용하여 그레이디언트 강도와 방향을 계산한다
각도는 총 0도~360도, 이를 10도 간격으로 양자화 하여 총 36개의 칸을 가진 히스토그램을 구한다
이때 가우시안 가중치를 사용하여 구한다
- 지배적 방향 추출
히스토그램에서 최대값을 갖는 방향을 지배적방향으로 채택한다
또한 최대값의 0.8을 넘기는 다른 칸이 있다면 그 방향도 지배적 방향으로 채택한다
이제 (y,x,σ,i)값에 θ를 추가하여 (y,x,σ,θ)로 표시한다
(σ=σ와 i정보 내포)
이제 회전불변성까지 달성했다
3. 명암 불변성 달성
빛의 변화에도 robust한 기술자를 뽑아내야한다
기술자를 기술자의 크기로 나누어 단위벡터로 바꿈으로써 명암 불변성을 달성한다
만약 단위 벡터에 0.2보다 큰 값이 있다면 0.2로 바꾸어 준 후 단위벡터로 바꾼다
이렇게 얻은 기술자가 최종 기술자가 된다
이때 기술자는 (y,x,σ,θ,x) (x=벡터의 크기) 로 표현한다
σ = 스케일 불변성
θ = 회전 불변성
x = 명암 불변성
이렇게 기술자를 뽑아내고 서로 다른 두 영상에서 기술자들끼리 매칭하여 객체를 탐지한다
매칭 알고리즘에는 다양한 방법이 있지만 이 부분의 대한 설명은 생략하겠다
사진은 내가 기술자들을 추출한 사진이다

