C++ 쓰레드
작업 관리자를 실행하면, 막대한 양의 프로세스가 나오는 것을 볼 수 있음
프로세스: 운영체제에서 실행되는 프로그램의 최소 단위, CPU의 코어에서 실행됨.
1개의 프로그램을 가리킬 때 보통 1개의 프로세스를 의미함.
컨텍스트 스위칭
CPU는 한 프로그램을 통째로 쭉 실행시키는 게 아니라, 이 프로그램 조금, 저 프로그램 조금씩 골라서 차례를 돌며 실행시킨다.
운영체제의 스케줄러가 프로그램에서 프로그램으로 스위치할 때 "어느 프로그램으로" 스위치할 지 결정하는 역할을 한다.
쓰레드
- 쓰레드: CPU 코어에서 돌아가는 프로그램 단위
- CPU 코어 하나에 한번에 한 개의 쓰레드의 명령을 실행
- 1개의 프로세스는 최소 1개~ 여러 개의 쓰레드로 이루어짐
-> 멀티 쓰레드(multi thread) 프로그램 : 여러개의 쓰레드로 구성된 프로그램
쓰레드와 프로세스의 차이점
프로세스들은 서로 메모리를 공유하지 않음.
프로세스 1, 프로세스 2 중 프로세스1은 프로세스2의 메모리에 접근 불가,
프로세스2도 프로세스 1의 메모리에 접근 불가.
프로세스는 서로의 메모리를 접근 불가, 같은 프로세스 내 쓰레드끼리는 메모리를 공유함.
한 프로세스 내에 쓰레드 1, 쓰레드 2가 있다면 서로 같은 메모리를 공유함.
왜 멀티쓰레드인가?
병렬 가능한(Parallelizable) 작업들
프로그램 논리 구조 상 연산들 간의 의존 관계가 많을수록 병렬화가 어려워지고,
반대로 다른 연산의 결과와 관계없이 독립적으로 수행할 수 있는 구조가 많을수록 병렬화가 매우 쉬워짐.
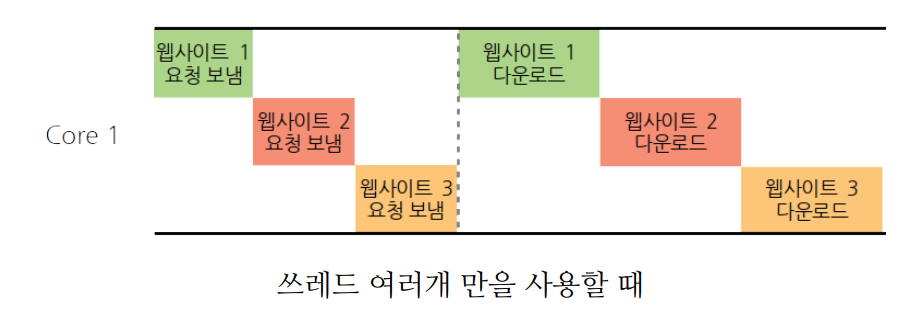
대기시간이 긴 작업들
예를 들어, 웹사이트를 다운받는 작업을 한다고 치면, 아래와 같이 쓰레드 1개만을 사용할 때와 달리 쓰레드 여러개를 사용할 때가 더 효율적으로 작업을 할 수 있다.

C++에서 쓰레드 생성하기
C++11에서부터 표준에 쓰레드가 추가되면서, 쓰레드 사용이 매우 편리해졌음.
멀티 쓰레드 프로그램을 만들어보자.
// 내 생에 첫 쓰레드
#include <iostream>
#include <thread>
using std::thread;
void func1() {
for (int i = 0; i < 10; i++) {
std::cout << "쓰레드 1 작동중! \n";
}
}
void func2() {
for (int i = 0; i < 10; i++) {
std::cout << "쓰레드 2 작동중! \n";
}
}
void func3() {
for (int i = 0; i < 10; i++) {
std::cout << "쓰레드 3 작동중! \n";
}
}
int main() {
// 아래와 같이 thread 객체를 생성
thread t1(func1);
thread t2(func2);
thread t3(func3);
t1.join();
t2.join();
t3.join();
}
이때, 결과는 늘 그때마다 다르다는 것을 확인할 수 있다.
프로그램을 실행할 때마다 그 결과가 달라진다는 게 가장 재밌는 점이다.
운영체제가 쓰레드들을 어떤 코어에 할당하고, 또 어떤 순서로 스케줄할 지는 그때그때마다 상황에 맞게 바뀌기 때문에 그 결과를 정확히 예측할 수 없다(주의).
join: 해당하는 쓰레드들이 실행을 종료하면 리턴하는 함수
join과 detach
join되거나 detach되지 않는 쓰레드들의 소멸자가 호출하면 예외를 발생시킴
(main 함수 종료되면 쓰레드 객체들의 소멸자가 호출, 스레드 부르고 join 호출 안하면 예외 발생)
detach
해당 스레드를 실행시킨 후, 잊어버리는 것
(메인함수 종료 후에도 백그라운드에서 실행됨)
쓰레드에 인자 전달하기
쓰레드는 리턴값이란 게 없기 때문에 만약 어떤 결과를 반환하고 싶으면 포인터의 형태로 전달하면 됨.
이때, 컨텍스트 스위치가 되는 그 변수를 출력하고 싶으면 cout 이 아닌 printf 를 사용해야 함
<- 컨텍스트 스위치가 되더라도 다른 쓰레드들이 그 사이에 메세지를 집어넣지 못하게 막기 때문
