C++ 템플릿 라이브러리 - 시퀀스 컨테이너
- 임의 타입의 객체를 보관할 수 있는 컨테이너(container)
-> 편지를 보관하는 각각의 편지함 - 컨테이너에 보관된 원소에 접근할 수 있는 반복자(iterator)
-> 편지를 보고 원하는 편지함을 찾는 일 - 반복자들을 가지고 일련의 작업을 수행하는 알고리즘(algorithm)
-> 편지들을 편지함에 날짜 순서로 정렬해 넣는 일
C++ STL 컨테이너 - 벡터(std::vector)
- 시퀀스 컨테이너(sequence container): 배열처럼 객체들을 순차적으로 보관
- 연관 컨테이너(associative container): 키를 바탕으로 대응되는 값을 찾아줌
시퀀스 컨테이너 -> vector, list, deque 3개가 정의됨
이 중 vector는,
- at함수: 임의의 위치에 있는 원소에 접근: O(1)
- push_back, pop_back: 맨 뒤에 새로운 원소를 추가하거나 제거: O(1)
-> 이때 amortized O(1)이라고 부름. - insert, erase: 임의의 위치 원소 추가 및 제거: O(n)
반복자(iterator)
알고리즘 라이브러리의 경우 대부분이 반복자를 인자로 받아서 알고리즘을 수행.
반복자 -> 컨테이너에 iterator 멤버 타입으로 정의되어 있음
vector: 반복자를 얻기 위해 begin() 함수와 end() 함수를 사용할 수 있는데 이는 다음과 같은 위치를 리턴함.
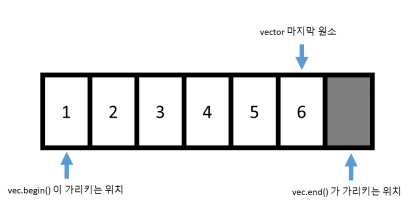
이렇게 할 경우 begin()==end()라면 원소가 없는 벡터를 의미하는 걸로 할 수 있음.
반복자는 다음과 같이 선언하고 사용함
// 반복자 사용 예시
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
// 전체 벡터를 출력하기
// 😲 **선언 부분**
for (std::vector<int>::iterator itr = vec.begin(); itr != vec.end(); ++itr) {
// 😲 **반복자를 포인터처럼 사용**
std::cout << *itr << std::endl;
}
// int arr[4] = {10, 20, 30, 40}
// *(arr + 2) == arr[2] == 30;
// *(itr + 2) == vec[2] == 30;
std::vector<int>::iterator itr = vec.begin() + 2;
std::cout << "3 번째 원소 :: " << *itr << std::endl;
}이때 반복자를 포인터처럼 사용한다는 말은, 반복자가 실제 포인터는 아니고, * 연산자를 오버로딩해서 마치 포인터처럼 동작하게 만든 거임.
(즉, itr이 가리키는 원소의 레퍼런스를 리턴)
반복자 사용 시 주의
for (; itr != end_itr; itr++) {
if (*itr == 20) {
vec.erase(itr);
}
}이때 erase를 실행하면 itr 자체가 소실되므로, 무한 루프를 돌게 되는 결과를 가져온다.
(즉, itr은 더이상 유효한 반복자가 아니게 됨)
해결
for (std::vector<int>::size_type i = 0; i != vec.size(); i++) {
if (vec[i] == 20) {
vec.erase(vec.begin() + i);
i--;
}
}
이 코드는 사실 비효율적임. 20인 원소를 지우고, 다시 처음으로 돌아가서 원소들을 찾고 있기 때문.
역반복자
#include <iostream>
#include <vector>
template <typename T>
void print_vector(std::vector<T>& vec) {
// 전체 벡터를 출력하기
for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end();
++itr) {
std::cout << *itr << std::endl;
}
}
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
std::cout << "초기 vec 상태" << std::endl; print_vector(vec);
std::cout << "역으로 vec 출력하기!" << std::endl;
// itr 은 vec[2] 를 가리킨다.
std::vector<int>::reverse_iterator r_iter = vec.rbegin();
for (; r_iter != vec.rend(); r_iter++) {
std::cout << *r_iter << std::endl;
}
}범위 기반 for문(range based for loop)
컨테이너의 원소를 for문으로 접근하는 패턴
C++11에서부터는 이와 같은 패턴을 매우 간단하게 나타낼 수 있는 방식을 제공
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
// range-based for 문
for (int elem : vec) {
std::cout << "원소 : " << elem << std::endl;
}
return 0;
}
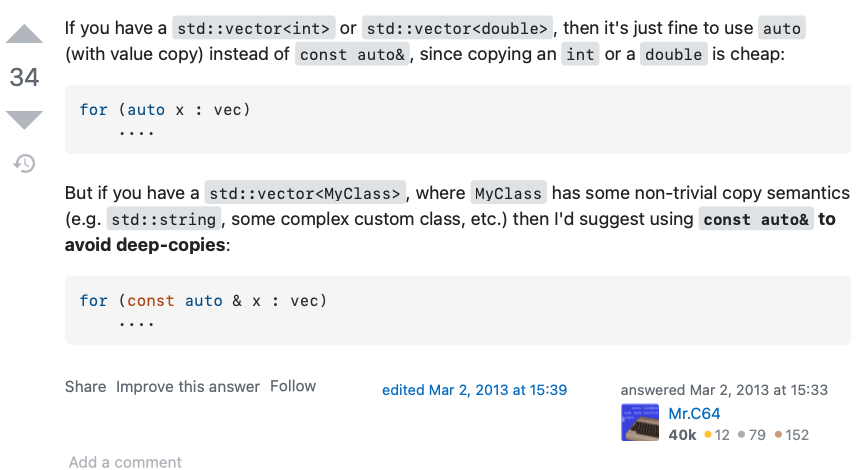
그런데 만약 int 타입의 객체 배열인 vec가 아니라, 하나하나의 객체 크기가 매우 큰 객체 배열 big_vec라고 해 보자.
이럴 경우, big_vec의 객체를 매번 element에 deep_copy하는데 시간적 비용이 매우 클 것이다.
=> 따라서 big_vec의 경우 아래와 같이 사용하면 시간적 비용이 적다.
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
// 🥰 ** 집중!: shallow copy range-based for 문 **
for (const int& elem : big_vec) {
std::cout << "elem : " << elem << std::endl;
std::cout << "address: " << &elem << std::endl;
}
return 0;
}
<참고>
리스트
양방형 연결 구조를 가진 자료형
- 장점: 추가하거나 제거하는 작업이 O(1)
- 단점: 임의의 위치의 원소를 조회하는 작업이 O(n)
따라서 반복자에 itr+5 이런 거 수행 못함. (한번에 한칸씩만 이동해야 하기 때문)
#include <iostream>
#include <list>
int main() {
std::list<int> lst;
lst.push_back(10);
lst.push_back(20);
lst.push_back(30);
lst.push_back(40);
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << std::endl;
}
}덱
덱은 벡터와 달리 실제 메모리상에 연속적으로 존재하지 않음
원소들이 어디에 저장되어 있는 지에 대한 정보를 보관 위해 추가적인 메모리가 더 필요로 함.
덱 -> 실행 속도를 위해 메모리를 희생하는 포인터
언제 어떤 컨테이너?
- 일반적으로 벡터 사용
- 만약 맨 끝이 아닌 중간에 원소들을 추가,제거하는 일을 많이 하고, 원소들을 순차적으로만 접근하면 리스트 사용
- 만약 맨 처음과 끝 모두에 원소들을 추가하는 작업을 많이 하면 덱을 사용
속도가 중요한 환경이면 적정한 밴치마크를 통해 성능 가늠하는 게 좋음.
