객체란?
키워드 명시를 하지 않으면 알아서 private으로 설정이 됨.
생성자와 함수의 오버로딩
함수의 오버로딩(Overloading)
C++에서는 함수의 이름이 같더라도 인자가 다르면 다른 함수라고 판단해서 고전적인 C 컴파일러와는 달리 오류가 발생하지 않음.
/* 함수의 오버로딩 */
#include <iostream>
void print(int x) { std::cout << "int : " << x << std::endl; }
void print(char x) { std::cout << "char : " << x << std::endl; }
void print(double x) { std::cout << "double : " << x << std::endl; }
int main() {
int a = 1;
char b = 'c';
double c = 3.2f;
print(a);
print(b);
print(c);
return 0;
}
즉, C언어의 경우 int, char, double 타입에 ㅏ라 함수의 이름을 제각각 다르게 만들어서 호출해 주어야 하는 반면, C++에서는 컴파일러가 알아서 적합한 인자를 가지는 함수를 찾아서 호출해 줌.
/* 함수의 오버로딩 */
#include <iostream>
void print(int x) { std::cout << "int : " << x << std::endl; }
void print(double x) { std::cout << "double : " << x << std::endl; }
int main() {
int a = 1;
char b = 'c';
double c = 3.2f;
print(a);
print(b);
print(c);
return 0;
}
위 코드의 경우 int 타입이나 double 타입은 각자 자기를 인자로 하는 정확한 함수들이 있어서 성공적 호출이 가능,
BUT char 타입의 경우 자기와 정확하게 일치하는 인자를 가지는 함수가 없어서 자신과 최대한 근접한 함수를 찾음.
C++에서 함수를 오버로딩하는 과정
1단계
자신과 타입이 정확히 일치하는 함수를 찾는다.
2단계
정확히 일치하는 타입이 없는 경우 아래와 같은 형변환을 통해서 일치하는 함수를 찾아본다.
char,unsigned char,short=>intUnsigned short=> (int의 크기에 따라)int,unsigned intfloat=>doubleEnum=>int
3단계
위와 같이 변환해도 일치하는 것이 없다면 아래의 좀 더 포괄적인 형변환을 통해 일치하는 함수를 찾는다.
- 임의의 숫자 타입 => 다른 숫자 타입
- Enum => 임의 숫자 타입
- 0, 포인터 타입, 숫자 타입으로 변환된 0 => 포인터 타입, 숫자 타입
- 포인터 => void 포인터
4단계
유저 정의된 타입 변환으로 일치하는 것을 찾는다
모호하다 오류
컴파일러가 위 과정을 통하더라도 일치하는 함수를 차을 수 없거나 같은 단계에서 2개 이상이 일치하는 경우: 모호하다(ambiguous) 라고 판단해 오류를 발생
아래는 예시 코드
// 모호한 오버로딩
#include <iostream>
void print(int x) { std::cout << "int : " << x << std::endl; }
void print(char x) { std::cout << "double : " << x << std::endl; }
int main() {
int a = 1;
char b = 'c';
double c = 3.2f;
print(a);
print(b);
print(c);
return 0;
}
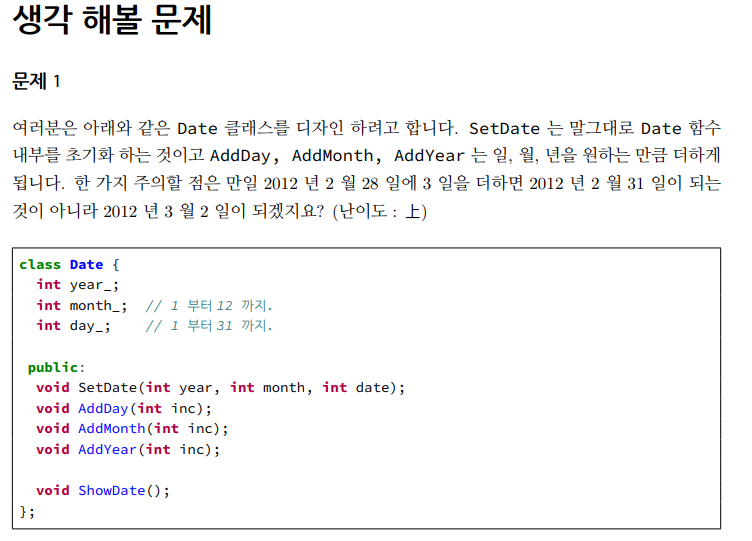
Date 클래스
- 클래스 중괄호 뒤에 ;(세미콜론) 붙여야 함 안 붙이면 에러 남
include<iostream>
class Date {
int year_;
int month_; // 1 부터 12 까지.
int day_; // 1 부터 31 까지.
public:
void SetDate(int year, int month, int date);
void AddDay(int inc);
void AddMonth(int inc);
void AddYear(int inc);
// 해당 월의 총 일 수를 구한다.
int GetCurrentMonthTotalDays(int year, int month);
void ShowDate();
};
void Date::SetDate(int year, int month, int day) {
year_ = year;
month_ = month;
day_ = day;
}
int Date::GetCurrentMonthTotalDays(int year, int month) {
static int month_day[12] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (month != 2) {
return month_day[month - 1];
} else if (year % 4 == 0 && year % 100 != 0) {
return 29; // 윤년
} else {
return 28;
}
}
void Date::AddDay(int inc) {
while (true) {
// 현재 달의 총 일 수
int current_month_total_days = GetCurrentMonthTotalDays(year_, month_);
// 같은 달 안에 들어온다면;
if (day_ + inc <= current_month_total_days) {
day_ += inc;
return;
} else {
// 다음달로 넘어가야 한다.
inc -= (current_month_total_days - day_ + 1);
day_ = 1;
AddMonth(1);
}
}
}
void Date::AddMonth(int inc) {
AddYear((inc + month_ - 1) / 12);
month_ = month_ + inc % 12;
month_ = (month_ == 12 ? 12 : month_ % 12);
}
void Date::AddYear(int inc) { year_ += inc; }
void Date::ShowDate() {
std::cout << "오늘은 " << year_ << " 년 " << month_ << " 월 " << day_
<< " 일 입니다 " << std::endl;
}
int main() {
Date day;
day.SetDate(2011, 3, 1);
day.ShowDate();
day.AddDay(30);
day.ShowDate();
day.AddDay(2000);
day.ShowDate();
day.SetDate(2012, 1, 31); // 윤년
day.AddDay(29);
day.ShowDate();
day.SetDate(2012, 8, 4);
day.AddDay(2500);
day.ShowDate();
return 0;
}
보통 간단한 함수를 제외하면 대부분의 함수들은 클래스 바깥에서 위와 같이 정의하게 됨.
클래스 내부에 쓸 경우 클래스 크기가 너무 길어져 보기 좋지 않기 때문.
생성자
생성자: 객체 생성시 자동으로 호출되는 함수
자동으로 호출되면서 객체를 초기화해주는 역할을 담당
암시적 방법, 명시적 방법 두가지가 있음.
Date day(2011, 3, 1); // 암시적 방법 (implicit)
Date day = Date(2012, 3, 1); // 명시적 방법 (explicit)디폴트 생성자
처음에 생성자 정의를 하지 않은 채 Date day; 로 했을 때 디폴트 생성자가 호출됨
이때 멤버 변수는 0, NULL 등으로 초기화된다.
명시적으로 디폴트 생성자 사용하기
C++11부터 명시적으로 디폴트 생성자를 사용하도록 명시 가능
class Test {
public:
Test() = default; // 디폴트 생성자를 정의해라
};
생성자 오버로딩
생성자 역시 함수이기 때문에 함수의 오버로딩이 적용됨.
생각 해보기
복사 생성자와 소멸자
소멸자
-
객체가 파괴될 때 호출되는 소멸자
-
객체가 동적으로 할당받은 메모리를 해체하는 일을 수행
-
인자를 가지지 않음: 따라서 오버로딩 역시 되지 않음
-
디폴트 소멸자도 존재
-
쓰레드 사이에서 lock된 것을 푸는 역할 등의 역할도 수행하게 됨
-> 나중에 알아보기
복사 생성자
예시
// 포토캐논
#include <string.h>
#include <iostream>
class Photon_Cannon {
int hp, shield;
int coord_x, coord_y;
int damage;
public:
Photon_Cannon(int x, int y);
Photon_Cannon(const Photon_Cannon& pc);
void show_status();
};
Photon_Cannon::Photon_Cannon(const Photon_Cannon& pc) {
// !! 복사 생성자
std::cout << "복사 생성자 호출 !" << std::endl;
hp = pc.hp;
shield = pc.shield;
coord_x = pc.coord_x;
coord_y = pc.coord_y;
damage = pc.damage;
}
Photon_Cannon::Photon_Cannon(int x, int y) {
std::cout << "생성자 호출 !" << std::endl;
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
}
void Photon_Cannon::show_status() {
std::cout << "Photon Cannon " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Photon_Cannon pc1(3, 3);
Photon_Cannon pc2(pc1);
Photon_Cannon pc3 = pc2;
pc1.show_status();
pc2.show_status();
}
-
어떤 클래스 T가 있다면
T(const T& a);로 정의됨 -
즉, 다른 T의 객체 a를 상수 레퍼런스로 받는다.
-
여기서 a가 const이기 때문에 우리는 복사 생성자 내부에서 a의 데이터를 변경할 수 없고, 오직 새롭게 초기화되는 인스턴스 변수들에게 a의 데이터를 복사만 할 수 있게 됨.
-
추가로, 함수 내부에서 받은 인자값을 변화시키는 일이 없으면 꼭 const를 붙여줘야 함
-
특이점
Photon_Cannon pc3 = pc2;
Photon_Cannon pc3(pc2);
// 이 둘은 동일하게 취급됨- C++ 컴파일러는 이미 디폴트 복사 생성자를 지원해 줌
- 복사 생성자를 한번 지워보고 실행하면 이전과 정확히 동일한 결과가 나타남
디폴트 복사 생성자의 한계
// 디폴트 복사 생성자의 한계
#include <string.h>
#include <iostream>
class Photon_Cannon {
int hp, shield;
int coord_x, coord_y;
int damage;
char *name;
public:
Photon_Cannon(int x, int y);
Photon_Cannon(int x, int y, const char *cannon_name);
~Photon_Cannon();
void show_status();
};
Photon_Cannon::Photon_Cannon(int x, int y) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = NULL;
}
Photon_Cannon::Photon_Cannon(int x, int y, const char *cannon_name) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = new char[strlen(cannon_name) + 1];
strcpy(name, cannon_name);
}
Photon_Cannon::~Photon_Cannon() {
// 0 이 아닌 값은 if 문에서 true 로 처리되므로
// 0 인가 아닌가를 비교할 때 그냥 if(name) 하면
// if(name != 0) 과 동일한 의미를 가질 수 있다.
// 참고로 if 문 다음에 문장이 1 개만 온다면
// 중괄호를 생략 가능하다.
if (name) delete[] name;
}
void Photon_Cannon::show_status() {
std::cout << "Photon Cannon :: " << name << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Photon_Cannon pc1(3, 3, "Cannon");
Photon_Cannon pc2 = pc1;
pc1.show_status();
pc2.show_status();
}디폴트 복사 생성자의 경우, char 배열이 같은 주소값을 복사해서, 소멸자를 호출했을 때 가리키고 있는 주소값의 변수를 아예 삭제해 버린다.
-> 따라서 pc1이 먼저 파괴되면 pc2의 char 포인터(배열)이 해제된 메모리를 이미 가리키고 있는 상황이 발생해 버린다.
-> 따라서 컴파일 에러가 먼저 뜬다(한번 해제된 메모리는 다시 해제될 수 없다).
=> 이를 주의하기 위해 복사 생성자에서 name을 그대로 복사하지 말고 따로 다른 메모리에 동적 할당을 해서 그 내용만 복사한다. 즉, deep copy를 수행하면 해당 컴파일 에러는 발생하지 않는다.
deep copy
name = new char[strlen(pc.name) + 1];
strcpy(name, pc.name);
물론 string 쓰는 게 가장 이상적이며, char 배열로 문자열을 다루는 건 매우 비추천한다고 함
