사용 언어: python 3.9.1
❓ Problem
📕 피드백
1. 발전 방향
왠만하면 N으로 처리 말고 len(리스트)으로 처리하기.
← 이유: 내가 반례 찾아가는 과정에서 잘못된 반례(예: N=3, list=[1,2,3,4])를 입력하는 경우
2. 느낀점
멍 때리는 시간보다 아이패드로 그리고 코드로 직접 구현하면서 머리를 풀로 회전시키는 연습이 필요해 보인다. 너무 오래 걸린다..
🚩 Solution
1. 접근법
TRY 1
11
10 20 10 30 20 21 22 23 24 25 50원래 코드(for문o 스택x, 재귀x)로는 이 경우 부분 수열을 제대로 못 찾고 {20 21 23 24 25 50} 으로 처리한다.
즉, 중간에 있는 30 때문에 10을 추가하지 못한다. 따라서 재귀를 써야 한다는 결론에 도달.
TRY 2
재귀와 메모이제이션을 썼고, for문으로 현재 원소 뒤의 원소들과 비교해가며
- A[cur]와 같은 크기의 A[next]의 경우: 무시
- A[cur]보다 작은 A[next]의 경우: 해당 원소에 대해 재귀를 돌도록 한다. 이때 A[next] 뒤에 쌓일 스택이 from_behind[next]에 들어간다. A[next]의 값은 A[cur]와 무관하므로 A[cur]에 넣지 않는다.
- A[cur]보다 큰 A[next]의 경우: 해당 원소에 대해 재귀를 돌은 값으로 쌓인 스택 + 1로 갱신 후보로 넣어줘서 갱신 전 값보다 클 때만 갱신하도록 했다.
이때 A[cur] > A[next]일 때 from_behind[next]와 from_behind[cur]가 무관한 이유: {10 30 5 6 7} 의 경우를 생각해 보자. 이 경우 가능한 증가하는 부분수열은 {10 30}, {5 6 7}이다. 이때 from_behind는 사실상 뒤에서부터 쌓이는 스택을 표현한다.
즉, 편의상 (<시스템의 스택>, {from_behind 배열})으로 표현하면
그러면 <10> , {0 0 0 0 1}→ ... → <10 30 5 6 7> , {0 0 0 0 1} → ... → <10 30> , {0 0 3 2 1} → <10>, {0 1 3 2 1} → <>, {2 1 3 2 1}
이렇게 된다. 따라서 무관할 수 밖에 없다.
이때 from_behind는 앞서 예시를 들어 설명했듯이 A 배열의 해당 원소가 가장 처음이면서 길이가 최대인 증가하는 부분수열의 길이이다. from_behind는 뒤에서부터 차례로 갱신을 거치고, 가장 처음인 원소가 꼭 길이가 최대인 증가하는 부분수열에 포함되어 있으리라는 보장이 없기 때문에 정답으로 max(from_behind)를 반환한다.
- 그림 참고
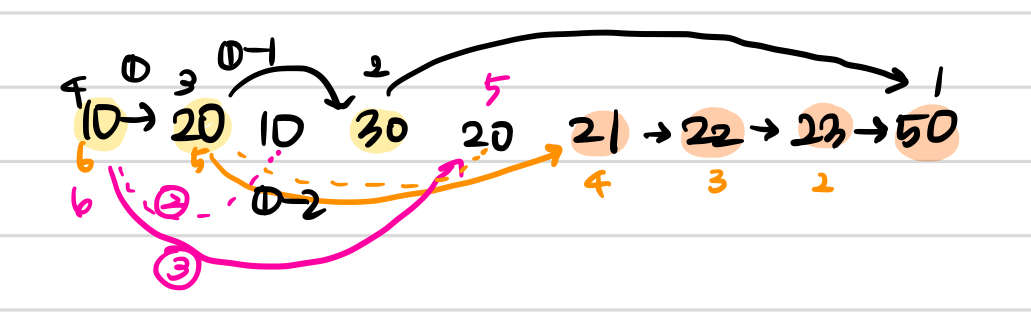
그런데 틀렸습니다로 결과가 떴다. 😭... 그래서 찾아낸 반례는 다음과 같다.
11
10 50 10 50 1 2 3 4 10 50 10알고 보니까 10 50 10과 같은 부분에서 각각 [2 1 1]이 되어야 하는데 [1 0 1]처럼 되는 것이었다.
이는 A[i]가 나머지보다 모두 큰 경우일 때 A[i]>A[j]만 걸려서 from_behind가 계속 0으로 값이 유지되기 떄문.
이런 경우: 즉 계속 0으로 남아있는 경우 1로 값을 갱신시켜줘서 이를 방지함(for문 끝난 직후 있는 if not문 참고).
2. 코드
import sys; read = sys.stdin.readline
sys.setrecursionlimit(10000)
def getLongPartNums(i):
# i는 cur, j는 next
if from_behind[i]:
return from_behind[i]
for j in range(i+1, len(A)):
if A[i] == A[j]:
continue
elif A[i] > A[j]:
getLongPartNums(j) # 새로 시작!
elif A[i] < A[j]:
from_behind[i] = max(from_behind[i], getLongPartNums(j) + 1)
if not from_behind[i]: from_behind[i] = 1
# 진짜 반례 2에서 유추해낸 코드
return from_behind[i]
N = int(read())
A = list(map(int, read()[:-1].split()))
from_behind = [0]*(len(A)-1)+[1]
getLongPartNums(0)
print(max(from_behind))3. 결과
29964 KB, 252 ms, 632 B
시간 복잡도 분석
대강 O((n^2)/2) 정도 되는 것 같다.
