.png)
루씬(Lucene) 기반의 Java 오픈소스 분산 검색 엔진
한줄 설명에서 루씬이라는 말이 나오는데요. ElasticSearch 를 알아보기 위해서 들어왔는데 갑자기 루씬 ?!???!?!?!?!

이게 뭐지 ? 포스팅을 잘 못 들어왔나 ? 라고 생각하고 나가실 수 있지만 잠깐만 기다려주세요. 루씬은 ES 내에서 실질적으로 돌아가는 검색 엔진입니다 !
즉, ES 는 루씬 이라는 검색엔진을 기반으로 패키징 되서 편하게 사용할 수 있는 검색 솔루션인데요. 여기까지만 읽었을때 이해가 안되신다 ? 정상입니다. 저도 그랬거든요. 물론 이해 되시는 분도 정상입니다🙂 그럼 루씬부터 차근차근 알아보도록 하겠습니다
루씬이란 ?
루씬은 자바로 만들어진 고성능 정보 검색 라이브러리입니다.파일 검색이나 웹 문서 수집, 웹 검색 등에 바로 사용할 수 있는 애플리케이션은 아니고, 검색 기능을 가지고 있는 애플리케이션을 개발할 때 사용할 수 있는 라이브러리 입니다. 자체적으로 수집기능은 제공하지 않습니다.
루씬의 검색 어플리케이션 구조는 아래와 같습니다. 이걸 아래에 있는 검색 대상 분석과 위쪽에 있는 검색 과정으로 나눠서 좀 더 자세히 알아보겠습니다.
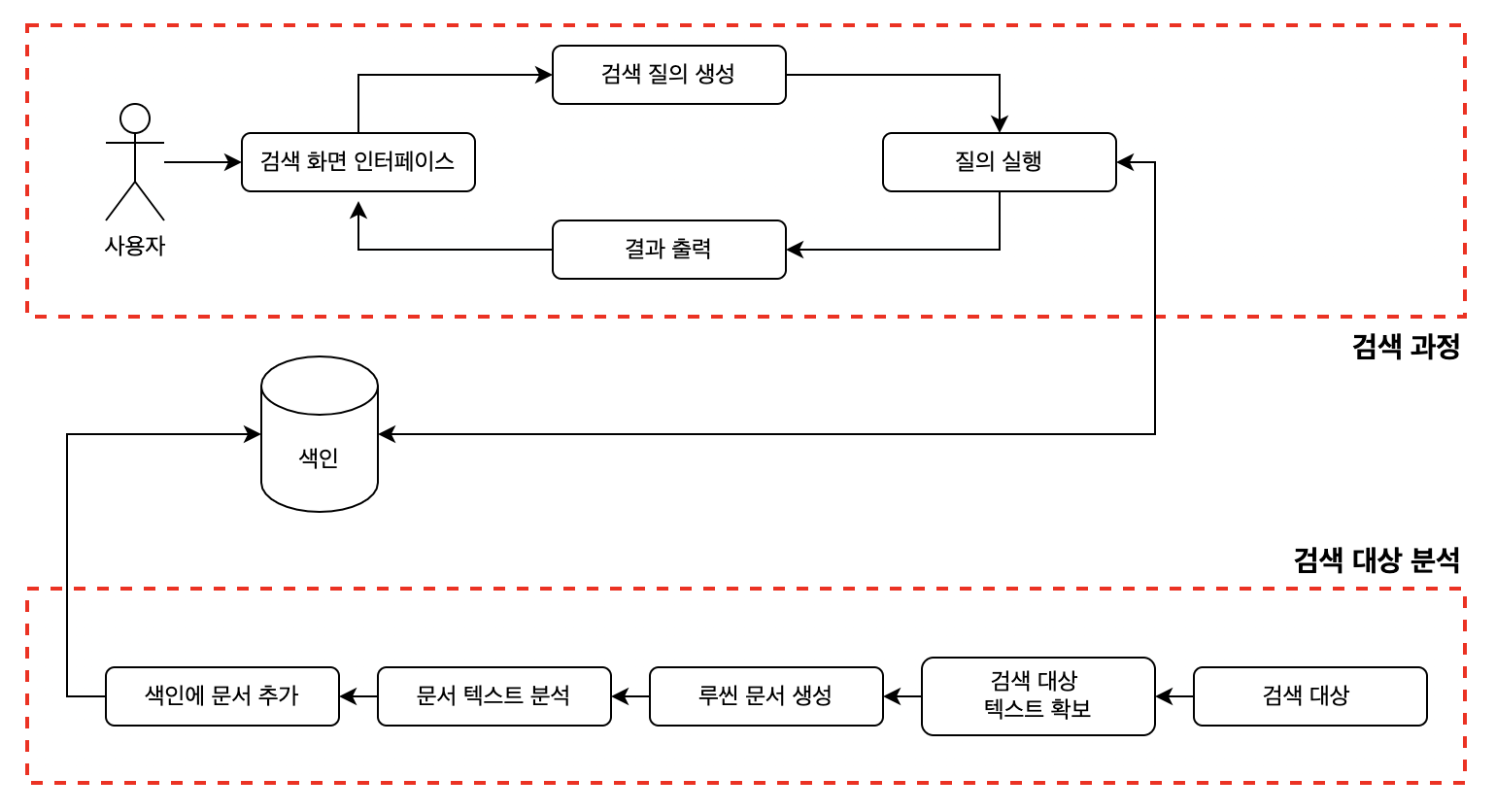
검색 대상 분석
검색 대상 텍스트 확보 ➡️ 루씬 문서 생성 ➡️ 문서 텍스트 분석 ➡️ 색인에 문서 추가
1) 검색 대상 텍스트를 확보합니다.여기서 주위할 점은 루씬 자체는 수집에 관한 기능을 제공하지 않는 다는 점입니다.
2) 루씬 문서를 생성합니다.문서란 루씬에서 사용하는 개별 단위입니다. 루씬 문서는 여러 개의 필드로 구성되어 있습니다.
3) 문서 텍스트를 분석합니다.루씬 문서의 텍스트를 텍스트 분석기를 사용해서 토큰이라고 불리는 단위로 분리합니다. 루씬 내에 여러개의 텍스트 분석기가 내장되어 있고, 필요에 따라 직접 만들어서 사용할 수 있습니다.
4) 색인에 문서를 추가합니다.색인 과정이 끝난 해당 문서를 색인에 추가합니다.
검색 과정
검색 화면 인터페이스 ➡️ 검색 질의 생성 ➡️ 질의 실행 ➡️ 결과 출력
1) 검색 화면 인터페이스를 통해 검색어를 전달 받습니다
2) 검색 질의를 생성합니다검색 화면 인터페이스를 통해 전달받은 검색어를 검색 엔진에서 인식하는 query 객체로 변환합니다.
3) 질의를 통해 검색합니다검색 질의에서 생성한 query 객체에 해당하는 결과를 받아옵니다.이때 검색 모델 중순수 불리언 모델(지정된 질의에 문서가 해당하는지 아닌지 여부를 확인, 점수 계산은 X) 과벡터 공간 모델(질의와 문서 모두 고차원 공간의 벡터로 표현, 거리를 계산하여 문서와 질의 사이의 연관도나 유사도를 확인)총 두가지 모델을 사용하며, 필요의 경우 어떤 모델을 사용할지 지정할 수 있습니다.
이제 루씬 개념을 알아보면서 몸을 풀었으니 본격적으로 ElasticSearch 에 대해서 알아보도록 하겠습니다.
ElasticSearch 란 ?
ElasticSearch 는 위에서 얘기했던 것처럼 루씬을 기반으로 방대한 양의 데이터를 신속하게 검색할 수 있는 분석 엔진입니다.
ES 는 NRT 검색 플랫폼 이라는 특징을 가지고 있는데요. NRT 는 Near Real Time 의 약자로 문서를 색인화 하는 시점부터 문서가 검색 가능해지는 시점까지 약간의 대기 시간(대개 1초) 이 있어 실시간은 아니지만 거의 실시간에 가까운 속도로 색인된 데이터의 검색, 집계가 가능합니다.
또한, 검색을 위해 단독으로 사용되기도 하지만 보통 ELK Stack로 사용됩니다.
ELK Stack 이란 ?
ELK Stack = ElasticSearch + Logstash + Kibana 로 요즘은 ELK Stack 에 Beats 를 더해서 Elastic Stack 이라고 합니다.
🔎 Logstash① 데이터 수집 파이프라인② 파이프라인으로 데이터를 수집하여 필터를 통해 변환 후 ES 로 전송
🔎 Kibana① ES 에서 색인된 데이터를 검색하여 분석 및 시각화
🔎 Beats① 경량 데이터 수집기② 서버에 에이전트로 설치하여 다양한 유형의 데이터를 Logstash나 Elasticsearch에 전송
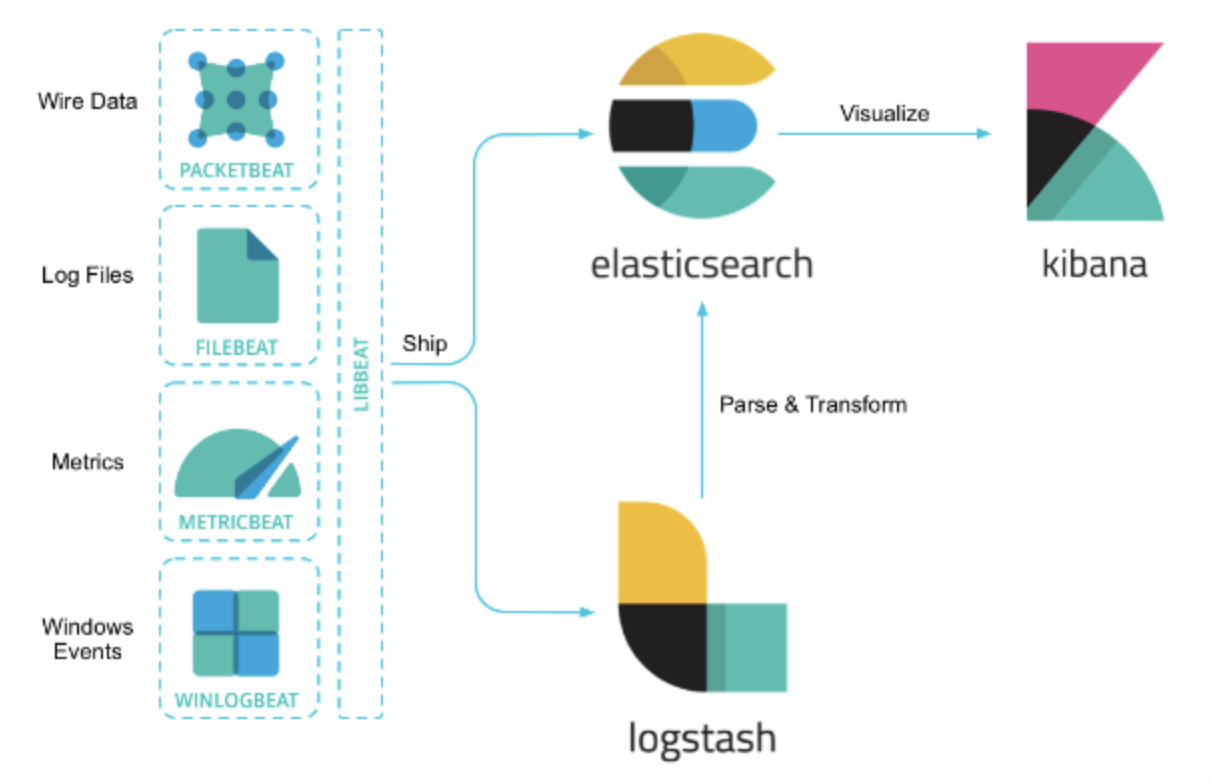
Beats 를 통해 데이터 수집 ﹥ Logstash 로 데이터 필터링 ﹥ ElasticSearch 에서 데이터 인덱싱 ﹥ Kibana 로 비주얼라이징 됩니다.
ES 에 대해서 어느정도 감이 오시나요 ? 그러면 이제 ES 의 내부 구조를 살펴봅시다. 🤓 (이제 반 왔습니다 조금만 더 힘내봅시다 💪)
ElasticSearch 의 구조
ES 의 구조는 ① 논리적 구조와 ② 물리적 구조 총 2개로 나눠서 볼 수 있습니다.
데이터 관점에서의 구조 먼저 살펴보도록 하겠습니다.
논리적 구조
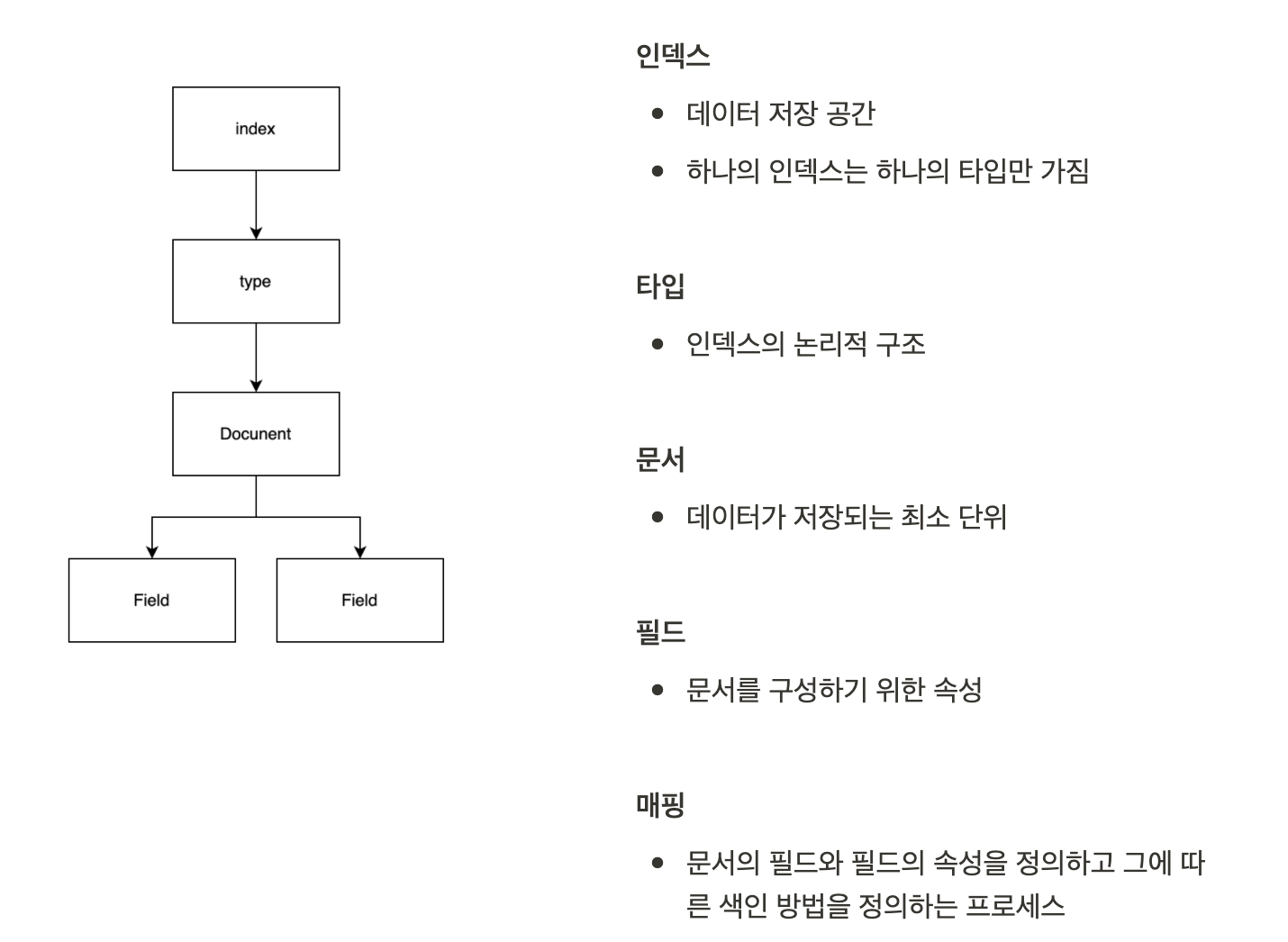
으로 ElasticSearch 와 RDBMS 를 대응시켰을 땐 다음과 같이 대응 될 수 있습니다.
🌟 버전 7.0 부터 매핑 타입이 사라졌습니다 자세한 건 아래 문서를 참고해주세요➡️ https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html
물리적 구조
클러스터는 ES 에서 가장 큰 시스템 단위를 의미하는데요. 클러스터의 입장에서 ES 를 바라봤을 때에는 아래와 같이 구조가 나뉘게 됩니다.
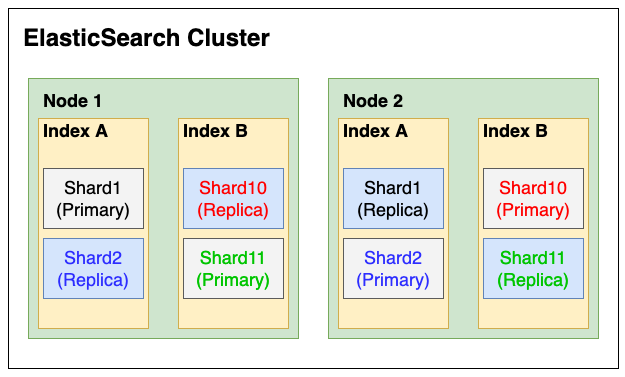
해당 이미지를 봤을 때에는클러스터 > 노드 > 인덱스 > 샤드 로 나뉘는 걸 확인 할 수 있습니다. 그러면 각 항목별로 더 자세하게 알아보겠습니다.
클러스터 (Cluster)
최소 하나 이상의 노드로 이루어진 노드들의 집합입니다. 서로 다른 클러스터는 데이터 접근, 교환을 할 수 없는 독립적인 시스템으로 유지됩니다.
노드 (Node)
클러스터에 포함된 단일 서버입니다.노드의 종류는 다음과 같습니다.
① master 노드 (node.master: true)﹥ master 노드는 인덱스 생성 또는 삭제, 클러스터에 속한 노드 추적, 어떤 노드에 할당할 샤드 결정과 같은 클러스터 전체의 경량 작업을 담당합니다.﹥ 클러스터에는 반드시 하나의 활성화된 master 노드가 있어야 하며, 그 외 노드들은 master 노드로 선출될 수 있는 master 후보 노드입니다. 기존 master 노드가 다운되는 경우 다른 master 후보 노드 중 하나가 master 노드로 선출됩니다.
② data 노드 (node.data: true)﹥ 실제로 색인된 데이터를 저장하는 노드입니다.﹥ CPU, 메모리 등 자원을 많이 소모하기 때문에 모니터링이 필요하며, master 노드와 분리되어야 함
③ ingest 노드 (node.ingest: true)﹥ 데이터를 인덱싱하기 전에 다양한 전처리를 할 수 있는 메커니즘을 제공하는 노드입니다.﹥ 하나 이상의 수집 프로세서로 이루어진 사전 처리 파이프라인 실행합니다.
④ coordinating 노드 (node.master, node.data, node.ingest: false)﹥ 로드밸런서 처럼 노드를 분산시키는 역할을 합니다.﹥ aggregation 쿼리는 많은 부하를 일으키는데 coordinating 노드가 없을 때 aggregation 쿼리를 날리면 그걸 data node 에서 처리하는데에 큰 부하를 일으킬 수 있습니다. 하지만, coordinating 노드에서 먼저 aggregation 쿼리를 받아 각 data node 에 적절하게 요청을 분산하면 data node 는 search 쿼리만 날리면 되기 때문에 본래의 indexing 기능을 충실하게 수행할 수 있게 됩니다.
작동 방식은 아래와 같습니다.
- 모든 데이터는 모든 데이터 노드에 샤드로 분산되어 데이터가 저장되어 있기 때문에 사용자의 검색 요청을 받은 노드는 클러스터에 존재하는 모든 데이터 노드에 검색을 요청
- 각 샤드는 자신이 가지고 있는 데이터 범위 내에서 검색을 수행하고 결과를 최초 요청한 Coordination 노드에게 전달
- Coordination 노드는 검색 결과가 도착하면 결과들을 하나의 커다란 응답 데이터로 병합해서 사용자에게 전달
- 각 데이터 노드에게 전달받은 데이터를 하나로 병합하는 작업에 많은 양의 메로리가 필요하기 때문에 전용 노드를 따로 구성하는게 좋음
이거 외에도 여러가지 노드가 더 있는데 더 알고 싶은 분은 elastic 에서 제공하는 노드에 대한 문서를 봐주세요 👉 노드 공식문서
인덱스 (Index)
단일 데이터 단위인 도큐먼트를 모아놓은 집합체를 인덱스라고 합니다.
샤드 (Shard)
일종의 파티션으로 인덱스의 도큐먼트를 분산해서 저장하는 저장소입니다.샤드의 갯수는 인덱스를 생성할 때에만 설정할 수 있으며, 중간에 샤드의 갯수를 바꾸려고 하는 경우 리인덱싱을 해줘야 합니다.샤드는 primary 샤드와 replica 샤드로 나뉘어집니다.
① primary 샤드처음 생성된 샤드를 의미합니다.
② replica 샤드primary 샤드의 복제본으로 동일한 primary 샤드와 replica 샤드는 동일한 데이터를 가지고 있으며 서로 다른 노드에 저장됩니다. 이를 통해 노드가 강제로 종료되더라도 replica 샤드를 통해서 복구 할 수 있습니다.
ElasticSearch 의 특징
ES 의 특징은 총 4가지를 가지고 있습니다.
첫번째, Scale out샤드를 통해 규모가 수평적으로 늘어날 수 있습니다.
두번째, 고가용성Replica 샤드를 통해 데이터의 안정성을 보장합니다.
세번째, Schema FreeJson 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없습니다.
네번째, Restful데이터 CURD 작업은 HTTP Restful API를 통해 수행합니다.
🙇🏻♀️ 레퍼런스
[루씬 인 액션] 1. 루씬(Lucene)의 개념 및 구조🙈[Elasticsearch] 기본 개념잡기🐵Elastic 가이드 북Elasticsearch Guide
