컴퓨터 메모리 구조

- CPU: 연산처리 하는 놈
- Memory: CPU가 활용하는 보조 저장도구
- Disk: 영구적으로 저장 하는놈
CPU는 빠르게 계산을 처리해야하고
Memory는 계산 중간중간 값을 저장하고, 계산이 끝나면 사용했던 값을 지운다
Disk는 계산이 끝나고 영구적으로 값을 저장한다
처리속도
메모리와 디스크의 IO 성능은 수십에서 수천배 차이가난다
CPU >>>>>>>>>>>> Memory >>>>>>>>>>>>>>>>>>>> Disk
CPU >>>>>>>>>>>> 캐시 >>>>>>>>>>>>>>>>>>>> RDB
캐시의 특징
- Disk에 비해서 겁나 빠르다
- Disk와 달리 값이 영구적으로 저장되지않는다 (휘발성이다)
캐시의 대표적인 오픈 소스 서비스 = Redis
- 이해를 쉽게 하기 위해
- Memory = Redis
- Disk = DB
- 라고 표현하도록 하겠다
Redis (Remote Dictionary Storage)
- Redis: Memory 기반의 Data 저장소 -> 휘발성
Redis 특)
- key-value 형식으로 데이터 저장
- 초당 수백만 요청 실행 가능 <--> (RDBMS는 일반적으로 초당 수천~수십만개 처리 가능)
- Disk가 아닌 Memory에 데이터 저장
- 싱글 쓰레드 동작
key-value 형식으로 데이터 저장한다고 하였는데...
- Redis는 다른 다양한 데이터 타입을 지원한다
- String
- Lists
- Sets
- Sorted sets
- Hashes
- Geospatial
실제로 사용하기위해 도커를 활용해서 redis image 다운로드 받아둔것을 활용하여보자
- 상세한 내용은 하단에 기술하도록 하겠다
다운로드받은 redis image를 실행후, redis-cli를 통하여 들어가보자

String

- 잘되는 모습이다
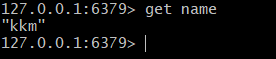
- 굳!
- name키를 설정하고, value값을 가져오는데에 성공하였다
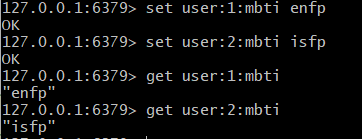
- 중간 중간 들어가는 :은 관례이니 필수는 아니다

- 한번에 가져올 수도있다

- 없는값을 찍으면 nil이 찍힌다
SET Key Value -> 데이터를 저장한다.
set name viva -> name이라는 키에 viva라는 값 넣기
get name -> name이라는 키에 있는 값 가져오기
============================================================
SET user:{userid}:name viva -> user:1:name 이라는 키에 viva라는 값 넣기
set user:1:name viva1
set user:2:name viva2
set user:3:name viva3
set user:4:name viva4
============================================================
mget : 여러개의 key의 값을 한번에 가져오는 기능
mget user:1:name user:2:name user:3:nameLists
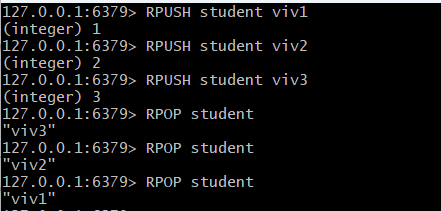
- RPUSH로 각 요소들을 오른쪽으로 차곡차곡 쌓고
- RPOP으로 하나 오른쪽에있는것들부터 하나씩 지운다
Lists는 LinkedList, Stack, Queue를 의미합니다.
Stack의 경우
RPUSH students viva1
RPUSH students viva2
RPUSH students viva3
RPUSH students viva4
RPUSH students viva5
RPOP students -> viva5
RPOP students -> viva4
RPOP students -> viva3
RPOP students -> viva2
RPOP students -> viva1
Queue의 경우
RPUSH teachers viva1
RPUSH teachers viva2
RPUSH teachers viva3
RPUSH teachers viva4
RPUSH teachers viva5
LPOP teachers -> viva1
LPOP teachers -> viva2
LPOP teachers -> viva3
LPOP teachers -> viva4
LPOP teachers -> viva5
RPUSH = queue
LPUSH = stackSets
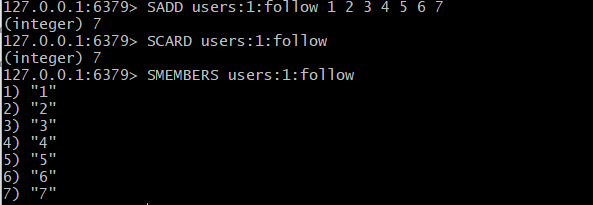
- SADD 값 추가
- SCARD 요소 몇개 들어있는지
- SMEMBERS 각 요소가 어떤 벨류값들을 가지고있는지

- SINTER을 통하여 첫번째 키값과, 두번째 키값의 벨류값들중 공통된 값을 뽑을 수 있다
- 현재 이상태에서 다시해보면

- 잘 나오는것을 확인 할 수 있다
유니크한 정보의 모음을 의미합니다.
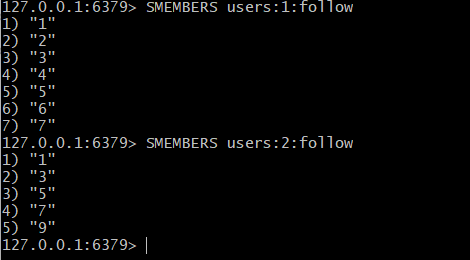
redis의 sets를 활용하는 대표적인 예시 'SNS follow'
SADD users:1:follow 1 2 3 4 5 6 7 -> userId 1번의 follow에 유저 1,2,3,4,5,6,7 넣기
SCARD users:1:follow -> userId 1번의 모든 follow 유저 갯수 출력
SMEMBERS users:1:follow -> userId 1번의 모든 follow 유저 출력
## SET은 유니크한 값 유지
SADD users:1:follow 1
SADD users:1:follow 1
SADD users:1:follow 1
SADD users:1:follow 1
SMEMBERS users:1:follow -> 똑같이 1,2,3,4,5,6,7 출력 됨
## userId 1번과 userId 2번의 공통된 follow 찾기
SADD users:2:follow 1 3 5 7 9
SINTER users:1:follow users:2:follow -> 1,3,5,7 출력 됨
Hash
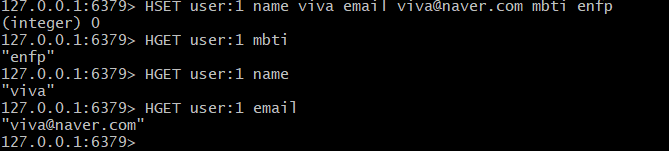
# HSET {key} {필드} {필드 값} {필드} {필드 값} ...
HSET user:1 name viva email viva@naver.com mbti enfj
HGET user:1 email
HGET user:1 mbti
HGETALL user:1 -> 모든 필드 출력
## 팔로우 추가 해봅시다
HSET user:1 follow 0
HGETALL user:1 -> 모든 필드 출력
HINCRBY user:1 follow 1
HGETALL user:1 -> 모든 필드 출력
HINCRBY user:1 follow 1
HGETALL user:1 -> 모든 필드 출력Sorted Set

- 추가해준다

- 명령어 입력
- user rank라는 key에서 +inf (가장 마지막 인덱스까지 검사할거야), byscore (score를 기준으로) 조회할거야, rev(거꾸로 = 점수가 높은순으로), limit 0 3 (0,1,2 순위를 가져올거야) withscores(점수 포함해서)

- ZINCRBY로 특정 key의 벨류값의 score를 추가시켜주고, 다시 동일한 명령문을 날리니, 순서가 다르게 나오는 모습이다
Sets와 비슷하지만 정렬 기능이 추가된 개념
redis의 Sorted Set을 사용하는 대표적인 예시 '게임 랭킹'
## ZADD {key} {score} {value} {score} {value}...
ZADD user:rank 100 viva1 200 viva2 300 viva3 400 viva4
## ZRANGE {key} {시작 index} {종료 index} {기준} {몇 개 출력할건지} {점수랑 같이 출력할건지}
zrange user:rank +inf 0 byscore rev limit 0 3 withscores
뜻은
user:rank 라는 키에서 +inf(가장 마지막 인덱스) 부터 0번까지 score 기준으로 검색할건데 REV(거꾸로)
옵션으로 검색할 것이다.
LIMIT 0 3 1위 ~ 3위까지만 검색할 것이다 WITHSOCRES 점수랑 같이 조회 할것이다.
## ZINCRBY {key} {score} {value}
ZINCRBY user:rank 10000 viva1
zrange user:rank +inf 0 byscore rev limit 0 3 withscores -> 1위가 변경되었는지 확인Geospatial
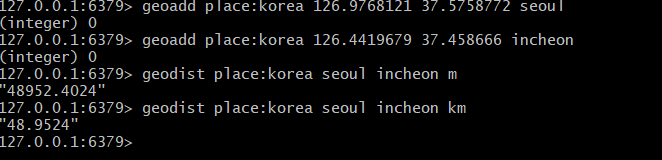
- 위도와 경도를 활용하여 거리를 측정 할 수 있다
Geospatial는 위도 경도를 나타내는 데이터
https://www.findlatlng.org/
광화문에서 인천공항까지 거리 측정 예시
## GEOADD {key} {위도 경도} {value}
geoadd place:korea 126.9768121 37.5758772 seoul
geoadd place:korea 126.4419679 37.458666 incheon
## GEODIST {key} {value} {value}
## 광화문에서 인천공항까지 거리
geodist place:korea seoul incheon {default m}
geodist place:korea seoul incheon km
거리 측정 실제 비교해보기!
https://www.google.co.kr/maps/place/%EC%9D%B8%EC%B2%9C%EA%B5%AD%EC%A0%9C%EA%B3%B5%ED%95%AD/data=!3m1!4b1!4m6!3m5!1s0x357b9a833a5efa59:0x8d4ba096cb5cbed4!8m2!3d37.458666!4d126.4419679!16zL20vMDE2MWdi?hl=ko&entry=ttu&g_ep=EgoyMDI0MDkxNi4wIKXMDSoASAFQAw%3D%3Dㅇㅋ 좋은데, mysql 워크밴치처럼 보여주는게 없나?
- 있다 Redis에서는 이러한 불편함을 인지하고있기에, 도커에 이미지로 넣어놨다, 다운받아서 사용해보자
- https://hub.docker.com/r/redis/redisinsight 해당 링크에서 자세하게 어떻게 하라고 알려주고있다
// 이미지 받기
docker pull redis/redisinsight
- 다운완료

- 해당 명령어로 도커 실행
- 후에 localhost 5540 접속
- 뭔가 나오는 모습이다!
- submit 버튼 클릭후, add database 까지해주자
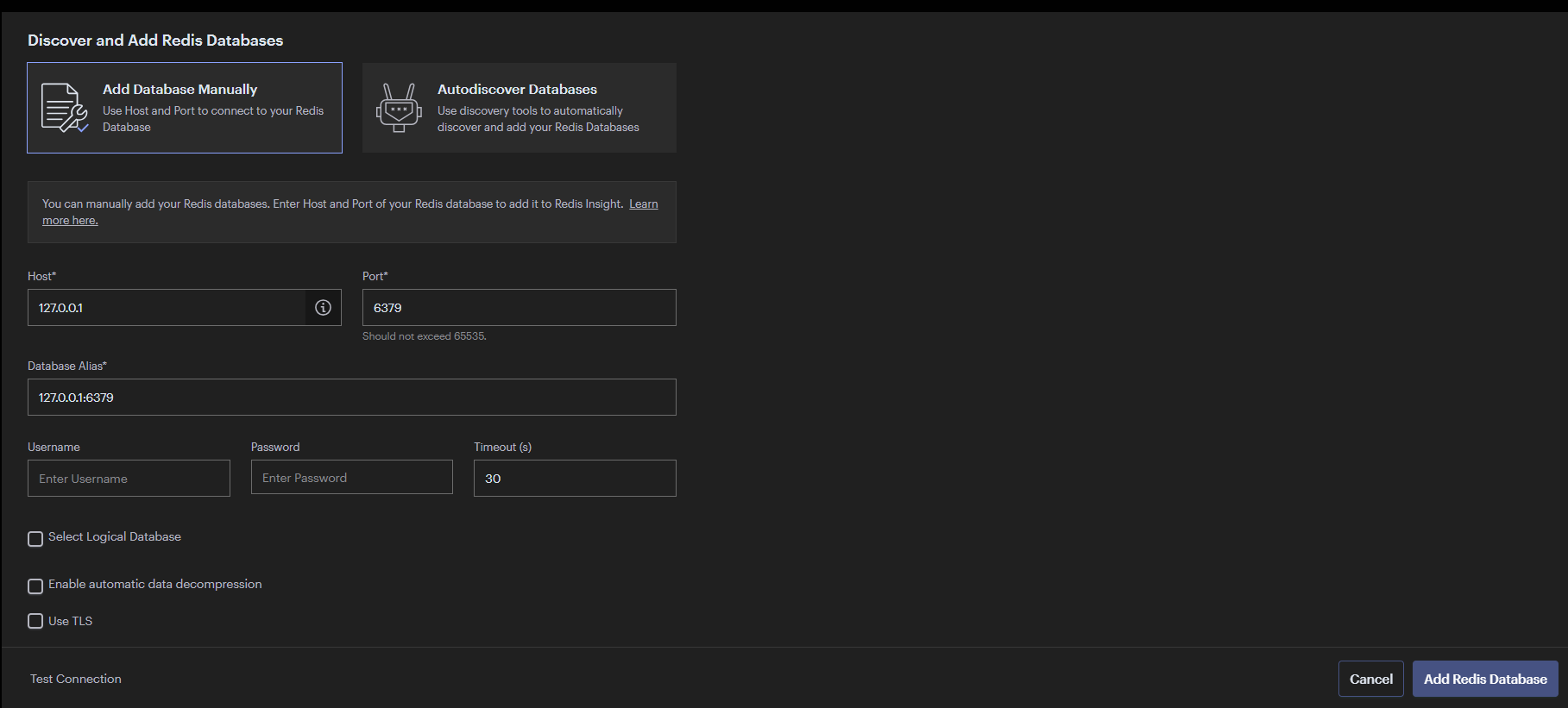
- redis port를 맞춰주고, DB 생성 진행!

- 하지만 에러가난다, 걱정마라 이건 정상적인 결과이니 해결책을 알아보자
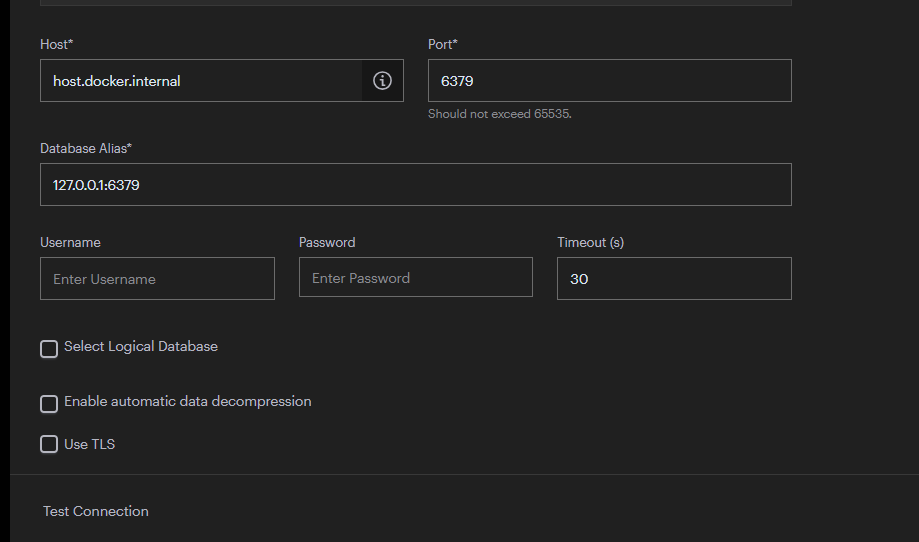
- 호스트 부분만 host.docker.internal로 바꿔주고 만들어주면
정상적으로 만들어진다
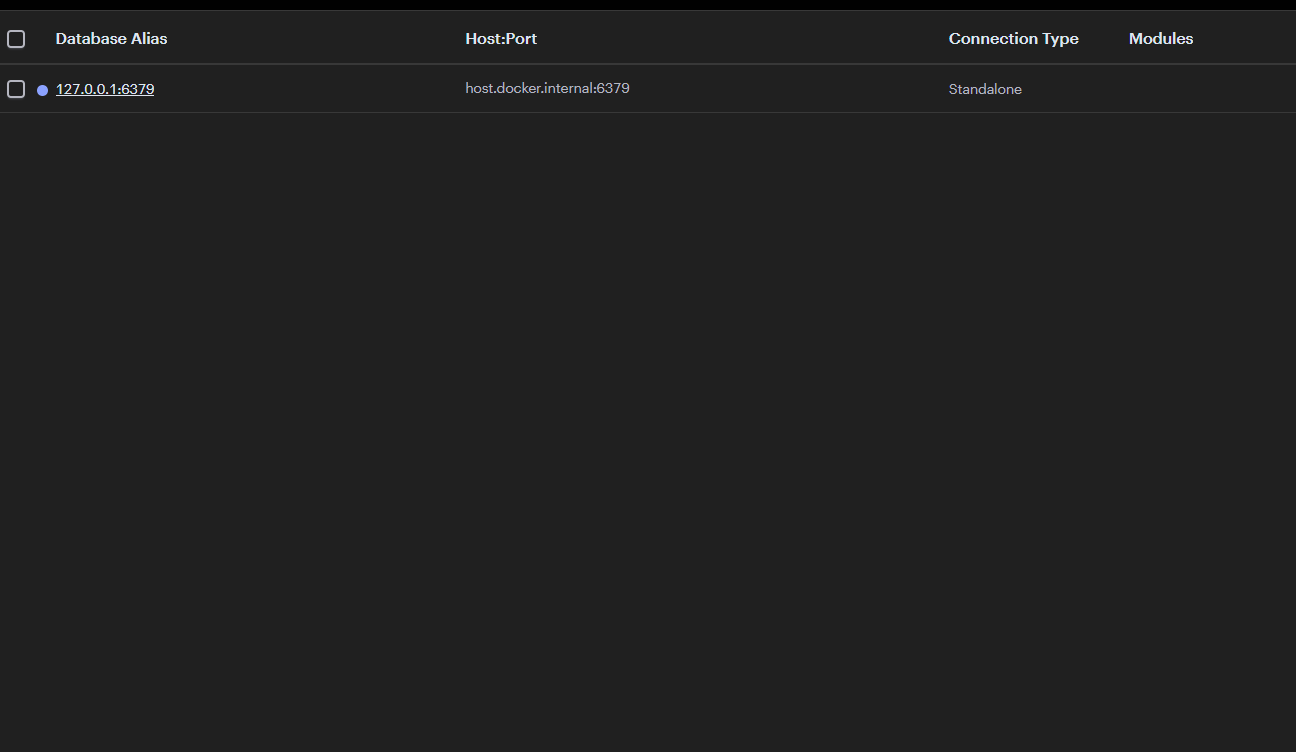
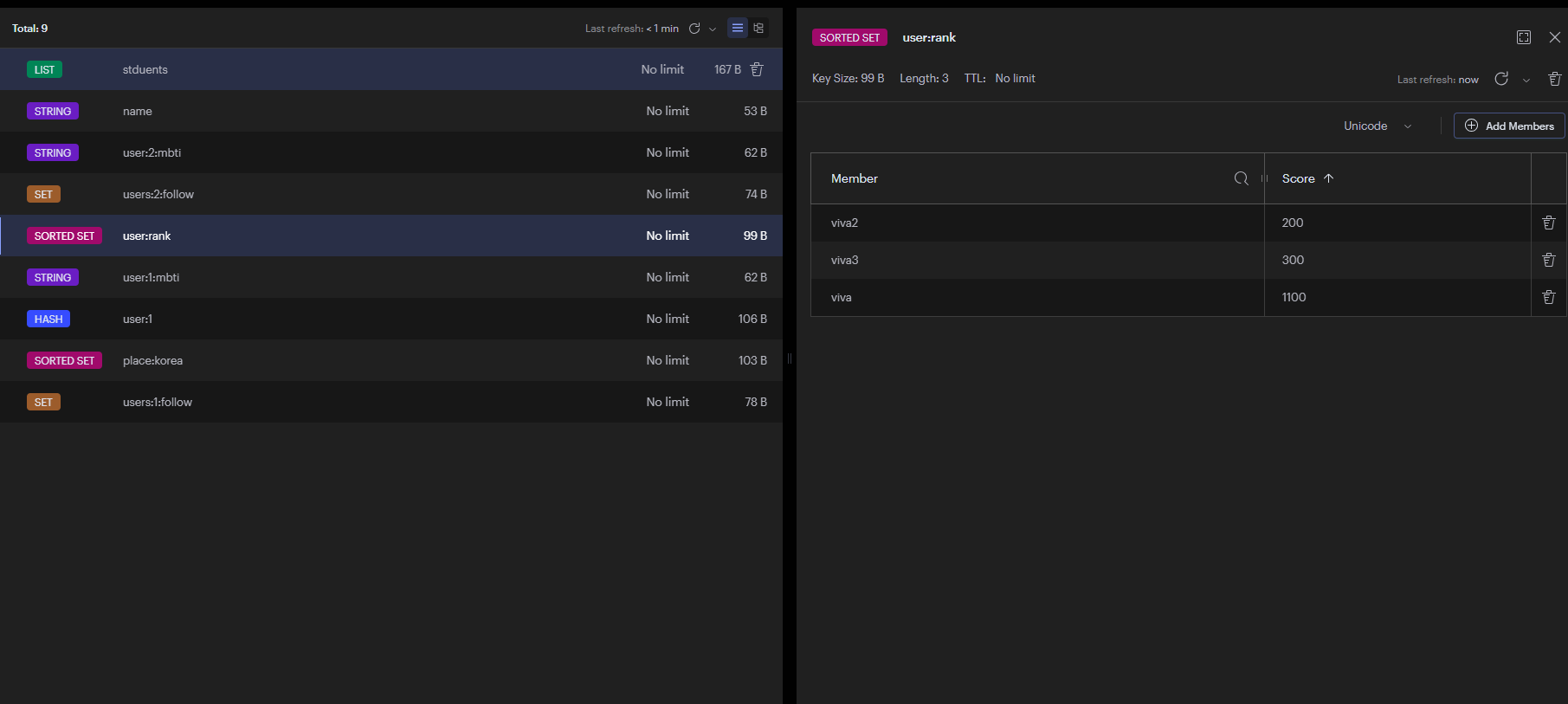
- 내가 여태까지 만들어놨던 데이터들을 이쁘게 볼 수 있다!
근데 왜 localhost로는 안되는걸까?
- docker의 컨테이너 개념은 갑자기 등장한것이아닌, 리눅스의 커널서비스로부터 시작된것을 기억하는가?
- docker는 "독립된 환경" 에서 실행된다
- 우리가 docker를 통해서 컨테이너를 띄웠는데, 각각의 컨테이너 입장에서는 "새로운 컴퓨터를 켰다"와 동일한 의미입니다
- 다시말해, 각 컨테이너마다 컴퓨터가 하나씩 배정되었다는 의미이다
- 우리가 Redis database에 연결할때의 127.0.0.1은 우리가 실제로 사용하고있는 컴퓨터의 localhost가 아닌, redis/redisinsight라는 컨테이너의 컴퓨터의 localhost를 지칭하게 되는것이다 !
- 그럼 어떻게 해결가능한가 ?
- host.docker.internal을 입력하여 해결 가능하다
마치며
- 도커 내부적으로도 네트워크 개념이 있는데, 이것을 언젠가 면밀히 알아보고싶다

테러대응전문가