
347. Top K Frequent Elements
문제링크: https://leetcode.com/problems/top-k-frequent-elements/
Solution
1. Map & sort
숫자 => count를 저장하기 위해 hash map의 성질을 이용한다. 각 숫자의 count를 결과롤 가지는 map을 구성한 후 [num, count]의 count로 내림차순으로 정렬한다. 그리고 k의 조건을 만족하는 num만 남겨 결과를 반환한다. sort를 하기 때문에 O(nlogn)의 시간이 걸린다.
Algorithm
myMap에num => count의 형식으로 저장한다.myMap을[num, count]의 값을 가지는myArr의 배열로 변환하고count를 기준으로 내림차순 정렬한다.k에 해당하는count값을resultCount에 저장하고 원소중에resultCount보다 큰 앞부분의num값을 결과 배열에 넣는다.
var topKFrequent = function(nums, k) {
// map (num => count) map O(n) valuesort O(nlogn) O(n)
// 1 map , sort
const myMap = new Map();
for (let num of nums) {
myMap.has(num) ? myMap.set(num, myMap.get(num) + 1) : myMap.set(num, 1);
}
const myArr = Array.from(myMap).sort((a, b) => b[1] - a[1]);
const resultCount = myArr[k - 1][1];
console.log(myArr);
const result = [];
for ([n ,c] of myArr) {
if (c >= resultCount) result.push(n);
}
return result;
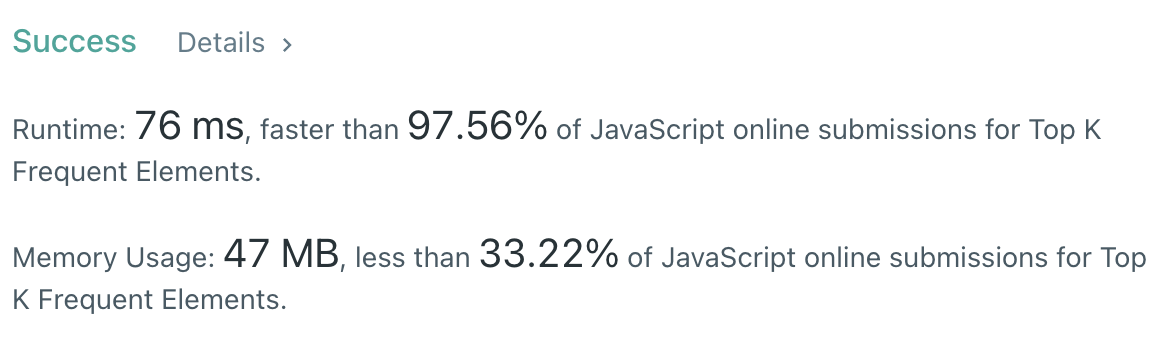
};
2. Map & bucket sort
Bucket sort는 어떤 범위내에 데이터가 균등하게 분포되었을 때 사용할 수 있다. 그리고 모든 값을 비교하지 않고 동일한 버켓에 넣어도 된다면 하나의 버켓에 넣는 방법은 해시와 동일하게 O(1)이며 전체 O(n)이 된다.
Algorithm
myMap에num => count의 방식으로 각 숫자의 개수를 넣는다.count를 index로 가지는 bucket을 만들고 안에Set을 통해 count => Set{num} 의 배열을 만든다.myMap의 데이터를 bucket으로 이동시키고 k를 만족하는 만큼 큰 순서대로 결과를 반환한다.
var topKFrequent = function(nums, k) {
// map (num => count) arr (count => Set<num>) O(n)
const myMap = new Map();
for (let num of nums) {
myMap.has(num) ? myMap.set(num, myMap.get(num) + 1) : myMap.set(num, 1);
}
const countArr = [] // count => Set{num}
for (let [num, count] of myMap) {
countArr[count] ? countArr[count].add(num) : countArr[count] = new Set().add(num);
}
const result = [];
for (let i = countArr.length - 1; i >= 0; i--) {
if (result.length < k) {
if (countArr[i]) result.push(...countArr[i]);
}
else break;
}
return result;
};
또 한번 map의 key와 value 값을 바꾸는 관점으로 생각해볼 수 있다.

로스트빌드(lostbuilds.com) 개발자, UEFN 도전, 게임이 재밌는 이유를 찾아서