이전 포스팅에서는 ejb의 탄생 배경과 특징, 가능한 기능에 대해 다루어 보았다. 이번 포스팅은 어떤 구조를 가지며, 동작 원리는 어떻게 되는 지 정리하려 한다.
용어 정리
Enterprise Beans, EJB Bean - 빈
EJB Container - 컨테이너
먼저 EJB를 사용하기 위해서는, 두 가지가 필요하다. 예전 web server와 WAS를 다룬 포스팅에서 잠깐 언급했는데, WAS의 내부 모듈이면서도 WAS의 다른 이름인 Web Container, 그리고 EJB Container이다.(일부 문서에서는 EJB 엔진이라고 표현하기도 한다.) 그리고 빈은 컨테이너 내부에서 동작하며, 컨테이너는 빈들의 lifecycle 관리를 맡는다.
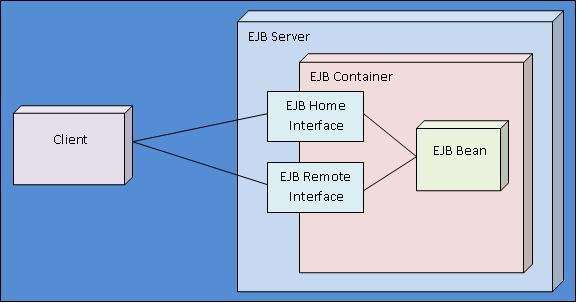
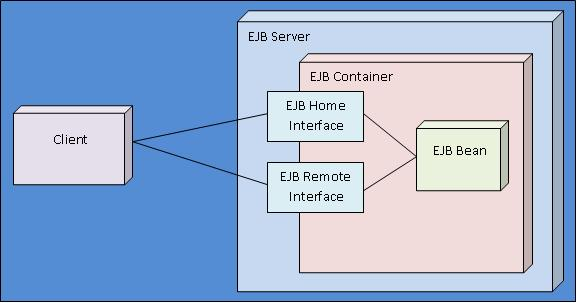
빈은 접근하기 위한 Business Interface와 비즈니스 로직 자체인 Bean class를 가진다.
Business Interface에서 원격으로 접근이 가능한 Remote Interface와 로컬에서만 동작하는 Home Interface 두 가지를 통해 Bean Class에 접근하는데, 하나의 빈은 두 가지 모두 가질 수 있지만, 둘 중 하나는 무조건 가져야 한다.
Remote Interface
서로 다른 JVM에 있는 빈을 호출하기 위한 인터페이스로, RMI 기반의 호출이다.
RMI 호출은 원격지에 있는 클라이언트가 원격 서버에 있는 메서드를 호출하는 방식으로, Stub과 Skeleton을 통해 전달 받는 방식을 사용한다.
따라서 원격의 빈을 호출해 사용하더라도, 원본 빈의 값이 달라지지는 않는다.
간단히 동작 원리를 정리해보자면,
- 조작하고자 하는 원격 개체를 가진 원격 JVM에 접속해 그 원격 개체를 찾는다.
- 원격 JVM은 해당 개체에 대응하는 원격 Stub을 보내준다.
- 그 Stub의 원하는 메서드에 조작을 위한 인자를 마샬링하여 원격 JVM으로 다시 보낸다.
- 원격 JVM의 Skeleton은 마샬링된 인자를 언마샬링하여 실제 메서드를 불러 값이나 예외를 얻는다.
- Skeleton은 값을 마샬링하여 Stub에 보낸다.
- Stub은 받은 값을 언마샬링하여 나에게 준다.
여기에서 마샬링/언마샬링은 자바가 플랫폼 독립적 언어이기 때문에 필요한 절차이다.
컴퓨터에는 Unix계열, Linux계열, Window계열과 같이 여러 운영체제가 존재하고, 운영체제나 시스템에 따라 데이터 표현 방식이 달라지는데, 이를 바이트로 쪼개 TCP/IP 통신을 가능하게 하는 형태로 바꿔주는 것을 마샬링, 반대의 경우를 언마샬링이라고 한다.
Home Interface
Remote Interface가 원격 JVM 통신을 위한 창구와 같은 느낌이라면, Home Interface는 같은 JVM 내부에서 호출할 때 사용하는 방법이다. 이 호출은 주소값으로 직접 호출을 하기 때문에 만약 객체의 값을 변경하게 될 경우 진짜 바뀌게 된다.
일반적으로 Remote Interface의 절차는 마샬링/언마샬링 과정이 반복적으로 일어나기 때문에 비교적 Home Interface보다는 성능이 느리다.
EJB 버전마다 사용 가능한 빈이 다른데, 버전에 따라 사용 가능한 빈의 종류는 다음과 같다.
EJB 1.0 - Session bean, Entity bean
EJB 2.0 - Session bean, Entity bean, MDB
EJB 3.0 이후 - Session bean, JPA, MDB
(3.0 ver 이후로는 Jakarta Enterprise Beans라는 이름으로 관리된다.)
하나씩 살펴보자.
Session Bean
비즈니스 로직을 담고 있는 재사용 가능한 컴포넌트(빈)이다. 후술할 Entity Bean의 경우는 실제 데이터를 표현하는 Persistent Object이지만, 세션 빈은 비즈니스 로직을 수행하는 데에 목적이 있다. 그래서 JDBC를 활용한 개발이 가능하기에, IBatis, MyBatis를 사용한다면 데이터베이스 CRUD도 가능하다.
세션 빈은 클라이언트의 요청을 처리하는 방식에 따라 세 가지로 나뉜다.
- Stateless Session Bean
- Stateful Session Bean
- Singleton Session Bean
Stateless Session Bean
클라이언트의 요청 상태를 유지하지 않는다. 대부분의 비즈니스 로직이 이를 무상태 세션 빈을 통해 구현되는데, 다수의 사용자들이 동시의 호출할 수 있을 만큼의 성능을 보장해야 한다.
따라서 컨테이너는 무상태 세션 빈의 인스턴스를 인스턴스 풀에 넣어 두고 요청이 들어올 때마다 하나씩 꺼내서 사용한다.
Stateful Session Bean(SFSB)
클라이언트의 요청 상태를 유지하는 세션 빈이다. 클라이언트와 1대 1로 매칭되며, 컨테이너는 클라이언트에 바인딩하는 고유한 세션 ID를 각 SFSB에 저장한다. 또한 컨테이너가 클라이언트의 사용 여부에 따라 이 빈의 활성화 여부를 결정한다.
클라이언트와 1대 1로 매칭되는 빈이기에 인스턴스를 생성하지 않아 따로 인스턴스 풀을 컨테이너가 가지고 있지는 않다.
대신 상태를 저장하고 유지해야 하기에 클래스 변수가 많이 쓰이며, 단순 비즈니스 요청 처리보다는 여러 순차적, 단계적 요청에 많이 쓰인다.
Singleton Session Bean
Singleton Pattern과 동작 방식이 유사하다. 컨테이너는 싱글톤 세션 빈의 단일 인스턴스만 생성하여 이를 모든 클라이언트와 공유한다. 따라서 동시성을 가진다.
Entity Bean
Entity Bean은 우리가 현재 쓰고 있는 ORM인 JPA의 방식과 유사하다. 즉 자바 객체와 DB row를 매핑 시키는 것이다.
따라서 Entity Bean의 클래스 변수인 property는 해당 Entity Bean과 매핑되는 테이블의 column과 일치하며, Entity Bean의 인스턴스는 테이블의 row와 일치한다.
컨테이너는 빈의 내용이 바뀌면 DB의 해당 row의 값을 수정하는 방식으로 처리가 된다.
Entity Bean을 관리하는 방식에는 2가지가 있다.
- CMP(Container Managed Persistence) - 컨테이너가 관리
- BMP(Bean Managed Persistence) - 개발자가 직접 관리
3.0버전 부터 Entity Bean은 JPA로 명칭이 바뀌어 현재의 JPA의 형태를 띈다.
Session Bean과 Entity Bean 처리 과정
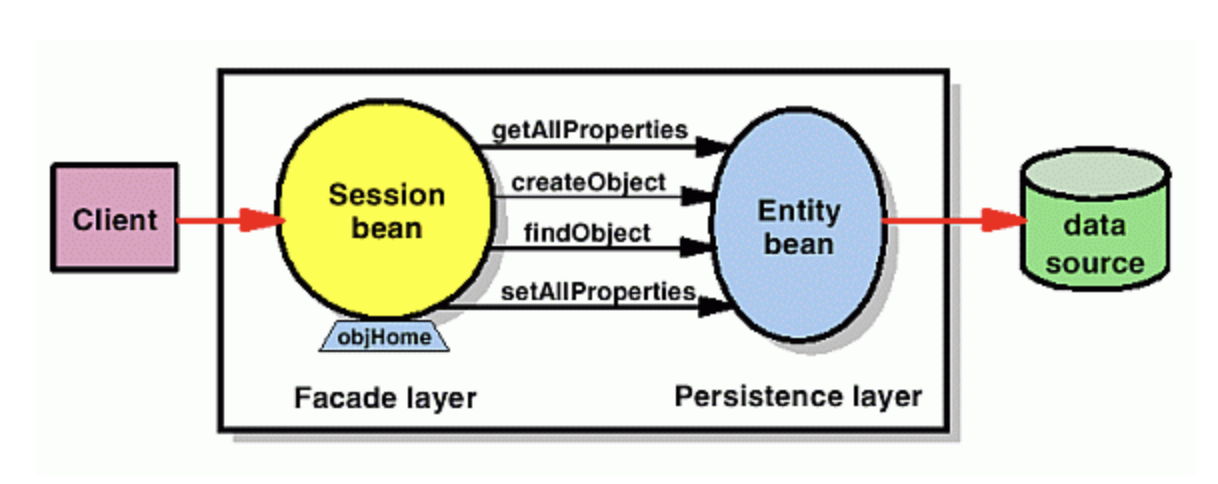
- 클라이언트에서 요청이 온다.
- Remote Interface/Home Interface에서 Session Bean으로 요청을 전달한다.
- Entity Bean을 통해 DB와 같은 데이터 소스로부터 데이터를 받아 비즈니스 로직을 처리한다.
- 로직 처리 후 결과 혹은 예외를 클라이언트에 전달한다.
MDB(Message-Driven Bean)
MDB는 요청 메시지를 queue를 사용해 쌓아 놓고 비동기를 처리하는 것이다. JMS의 특수화된 버전으로 여러 처리 과정이 필요하거나, 바로 응답이 불가능한 요청은 동기적인 작동을 할 경우 해당 요청이 서버 자원을 독점하는 경우가 발생한다. 따라서 이를 방지하기 위해 비동기적 메시징 처리를 보장하는 것이 MDB이다.
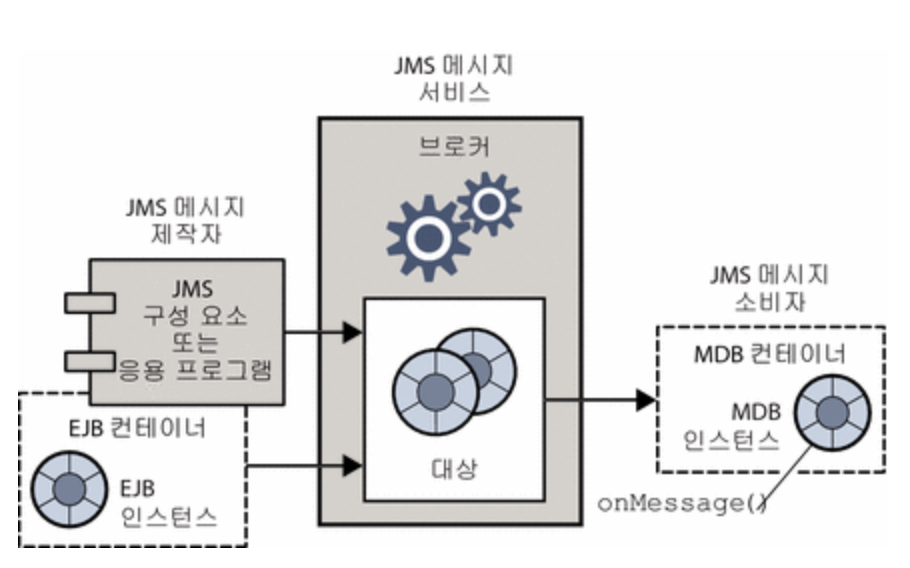
MDB는 JMS(Java Message Service) 인터페이스를 구현하는 빈이다. 단일의 JMS 브로커에 연결하여, 위 그림과 같이 onMessage()와 같은 메서드를 통해 메시지를 수신하면, 컨테이너는 MDB의 인스턴스를 생성한다.
컨테이너는 브로커와의 연결을 설정하고, 해당 브로커와 세션 풀을 생성하며 메시지 배포를 관리한다.
또한 이 모든 작업은 비동기적으로 이루어져 브로커와 MDB간 결합을 느슨하게 한다.
여기까지 EJB의 세 가지 Beans와 내부 동작에 대해 정리해보았는데,
사실 Spring에 밀릴 수 밖에 없는 실질적 이유가 있다.
먼저 개발자의 개발 업무는 보통 세 가지를 반복한다.
- 비즈니스 로직 개발
- 개발 환경에서의 테스트 및 디버깅
- 운영 환경에서의 서비스
EJB는 개발자들이 로우 레벨 기술을 신경 쓰지 않고 비즈니스 로직 개발에 집중할 수 있게 만들어진 기술이다. 따라서 로우 레벨 기술에 대한 부분은 추상화가 많이 되어있고, EJB 컨테이너에 종속적이다.
따라서 개발이나 디버깅, 테스트에 있어 단위 테스트가 오래 걸리고, EJB 아키텍쳐에 대해 이해가 없다면 단순한 에러에 대한 디버깅에도 오랜 시간이 걸리며, 그만큼 생산성이 떨어지게 된다.
또한 운영 환경에서 EJB 컨테이너가 필요한데, 이 자체가 고사양의 WAS를 필요로 하고, 고사양 만큼의 성능이 나오지도 않는다.
이러한 사유로 인해 자바 개발자들이 개고생하고 있던 중, 드디어 이 시리즈를 시작한 이유인 Spring이 등장하게 된다.
(다음 포스팅에서 계속,,)
