VAE 탐구
1.VAE 탐구 - 1/6
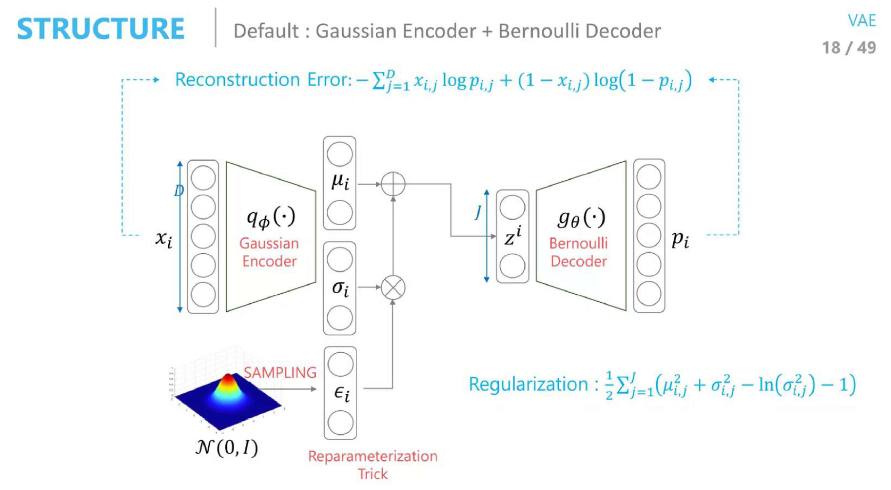
VAE 대강 훑어보고 정리
2024년 5월 21일
2.VAE 탐구 - 2/6

- 이 글에서는 이전 글에 이어서 확률론부터 KL-divergence까지 정리해보고자 한다. KL-divergence까지 필요한 사전정보가 대부분이다. 단순사건과 확률질량함수 유한 개의 사건이 존재하는 경우 각 단순사건에 대한 확률만 정의하는 함수를 확률질량함수 (
2024년 5월 21일
3.VAE 탐구 - 3/6
가능도함수 이제부터는 확률분포 X에 대한 확률 밀도함수 또는 확률질량함수를 다음과 같이 대표하여 쓰기로 한다. $$ p(x;\theta) $$ 베르누이 확률분포라면, $\theta=\mu$ 이항분포라면, ( 베르누이 여러번 ) $\theta=(N,\mu)$ 정규분
2024년 5월 22일
4.VAE 탐구 - 4/6
이 글에서는 KL-Divergence의 정의를 분포의 평균과 분산으로 전개하고자 한다.$mean(평균) : \\mu, \\;variance(분산) : \\sigma^2$$$N(\\mu,\\sigma^2)=\\frac{1}{\\sqrt{2\\pi\\sigma^2}}e^{
2024년 5월 22일
5.VAE 탐구 - 5/6

이 글에서는 $p(x), p(z|x), q\_\\phi(z|x)$ 사이의 관계를 전개하고 Regularization Error 수식 도출을 하고자 한다.$p(x)$의 가능도를 최대로 올리는 것이 목표이다.$x$ 데이터는 여러 개 이므로 아래 수식을 곱이 아닌 합으로 변
2024년 5월 22일
6.VAE 탐구 - 6/6
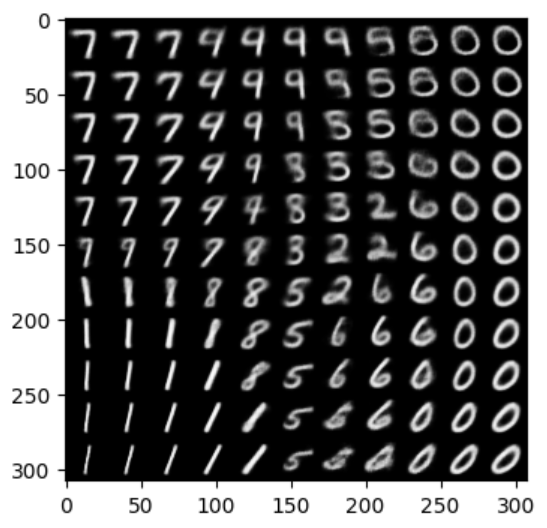
이 글에서는 마지막으로 코드 구현을 해보고자 한다.latent_space가 0 근방에 모이긴 했지만 생각보다 학습이 제대로 이루어 지진 않은 듯하다.X
2024년 5월 22일