Airflow?

(출처 - https://airflow.apache.org/)
- Python 기반 오픈소스 기반 워크플로우 관리도구
- 워크플로우를 생성하고, 스케쥴링, 모니터링으로 관리할 수 있음
- ETL 작업을 자동화할 수 있는 장점
- 정교한 dependency를 가진 파이프라인을 설정할 수 있다. (오늘의집 : 제킨스에서 airflow로 워크플로우 개선)
- AWS,GCP와 같은 다양한 클라우드 서비스에서도 Airflow를 제공
- 넓은 커뮤니티
Airflow의 특징
- python으로 워크플로우를 생성해야함
- DAG(Directed Acyclic Graph) : 하나의 워크플로우를 의미. DAG 안에는 1개 이상의 Task가 존재
- Task간 선후행 연결이 가능하고 방향성을 가짐. 그러나, 순환되지는 않음
- Cron 기반의 스케쥴링
- 모니터링과 실패 작업에 대한 재실행 기능이 용이한 것이 특징
- 자유도와 확장성이 높다
Airflow의 구조
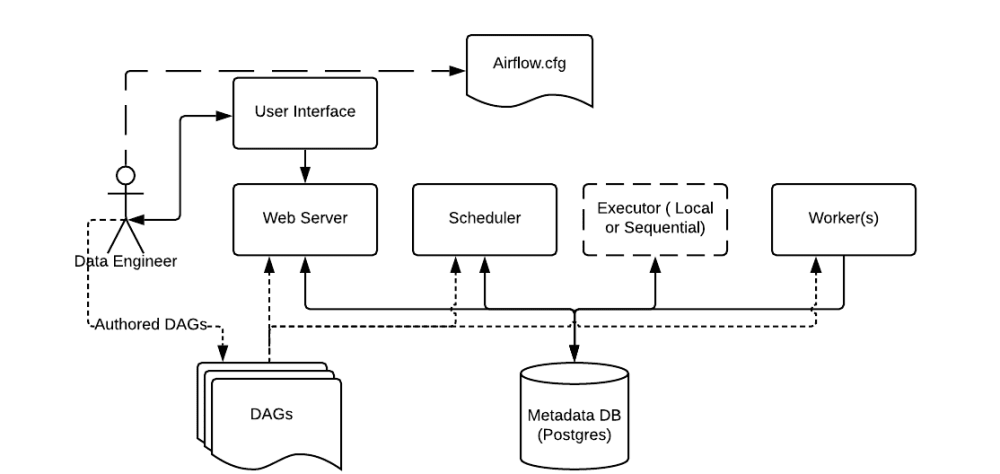
(출처 - https://airflow.apache.org/docs/apache-airflow/stable/concepts.html)
- Scheduler : 모든 DAG와 Task를 모니터링 및 관리, 실행해야할 Task를 스케쥴링
- Web server: Airflow의 Web UI server
- DAG(Directed Acyclic Graph) : python으로 작성한 워크플로우. Task들의 dependency를 정의
- Database : Airflow에 존재하는 DAG와 task의 metadata를 저장
- Worker : Task를 싱행하는 주테. Excutor 종류에 의해 동작 방식이 결정됨
📌 Airflow의 작동흐름
Airflow DAG를 읽는다 -> Scheduler가 Task를 스케쥴링한다 -> Worker가 Task를 실행한다 -> Task의 실행상태가 DB에 저장된다 -> 사용자가 UI로 Task의 실행상태, 성공여부를 확인할 수 있다
DAG(Directed Acyclic Graph)
-
DAG는 Task들 간의 관계와 dependency를 표현하고 있는 모음
-
Task간의 실행순서와 dependency, scheduler의 종류에 대한 정보를 가지고 있음
-
DAG를 정확하게 설정함으로써 Task를 적절하게 스케쥴링할 수 있음

(출처 - https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/overview.html) -
색별로 상태가 나와있어 모니터링하기 좋음. 원한다면 재실행하는 것도 용이함
- 초록색 (Green) - 성공 (Success): 태스크가 성공적으로 완료되었음을 나타냅니다.
- 빨간색 (Red) - 실패 (Failed): 태스크 실행이 실패했음을 나타냅니다. 오류가 발생한 경우를 의미합니다.
- 주황색 (Orange) - 실행 중 (Running): 태스크가 현재 실행 중임을 나타냅니다.
- 회색 (Grey) - 대기 중 (Queued): 태스크가 실행 큐에 있으며 실행을 기다리고 있음을 나타냅니다.
Executer
- Task를 실행하는 주체로, 종류가 다양하기 때문에 각 상황에 맞게 적절히 사용
- 작업을 어떻게 실행할 것인지 결정하는 구성요소
- 각 executor의 장단점, 특징에 맞게 사용
1. SequentialExecutor
장점: 설정이 간단하며, 작은 워크플로우나 테스트에 적합합니다.
단점: 한 번에 하나의 태스크만 실행할 수 있어, 대규모 또는 병렬 처리에는 부적합합니다.
2. LocalExecutor
장점: 병렬 실행이 가능하며, 중간 규모의 워크플로우에 적합합니다. 설정이 비교적 간단합니다.
단점: 실행되는 모든 태스크가 동일한 머신에서 처리되므로, 리소스가 제한적일 수 있습니다.
3. CeleryExecutor
장점: 대규모 분산 환경에서 효과적이며, 여러 서버에 태스크를 분산시켜 병렬 처리가 가능합니다.
단점: RabbitMQ나 Redis와 같은 메시지 브로커가 필요하며, 설정과 관리가 복잡할 수 있습니다.
4. KubernetesExecutor
장점: Kubernetes 클러스터에서 동적으로 태스크를 실행할 수 있으며, 각 태스크마다 별도의 컨테이너를 사용합니다. 확장성과 격리성이 뛰어납니다.
단점: Kubernetes 환경 설정이 필요하며, Kubernetes에 대한 이해가 요구됩니다.
5. DaskExecutor
장점: 대규모 데이터 처리와 복잡한 병렬 처리에 적합합니다. Dask는 데이터 과학 작업에 최적화된 라이브러리입니다.
단점: Dask 클러스터 설정이 필요하며, Dask에 대한 추가적인 이해가 필요할 수 있습니다.
참고
오늘의집 : 버킷플레이스 Airflow 도입기
[데이터 엔지니어링 with Airflow] 1강. Airflow 소개 및 비교 : 슬기로운 통계생활
Airflow
