- 큰 맥락(context)이나 다중 동시 사용자 붙는 경우 GPU 메모리만으로는 감당하기 힘듦.
- Dynamo는 KV캐시 메모리 문제를 해결하기 위해 Offloading/재사용/계층적 저장 방식을 사용.
1. 구현 방식
KVBM (KV Block Manager)
- KV cache를 block 단위로 쪼개 관리.
- 각 블록의 위치(GPU VRAM, CPU DRAM, SSD, 원격 스토리지)를 추적.
- 블록 크기는 수 MB 단위로 설정되어 전송 효율과 공간 활용의 균형을 맞춤.
- 이 방식은 LRU(Least Recently Used), LFU(Least Frequently Used) 같은 교체 정책을 쉽게 적용할 수 있게 함.
여러 저장소(backends)
- GPU HBM -> CPU RAM -> SSD/네트워크 스토리지로 내려가는 다단계 계층 구조(hierarchical storage)
예: 최근 사용 안 된 KV block은 SSD로 내려가고, 자주 참조되는 블록은 HBM에 유지.
NIXL 전송 라이브러리
- GPU와 외부 저장소 간의 대용량 block 전송 최적화 라이브러리.
- DMA(Direct Memory Access)를 활용해 CPU intervention 최소화.
- 전송 시 pipeline overlapping(계산과 데이터 전송 동시 수행)으로 지연을 줄임.
통합(interfacing) 계층 제공
- vLLM, TensorRT-LLM, FasterTransformer 같은 다양한 추론 엔진에서 공통 인터페이스를 통해 KV cache 오프로드 기능 사용 가능.
- 별도의 엔진 커스터마이징 불필요.
- LMCache 같은 외부 오픈소스 서브시스템도 연동 지원.
전략 및 정책(policy)의 유연성
- Adaptive Offloading: 요청 패턴에 따라 블록을 GPU/CPU/SSD 계층 간 동적으로 이동.
- Prefetching: 앞으로 필요할 확률이 높은 블록을 미리 GPU로 불러옴.
- Pinning 정책: 시스템 템플릿, 고빈도 prompt token 같은 블록은 GPU에 고정.
환경에 따라 최적화 가능:
I/O 대역폭이 큰 서버에서는 aggressive offload
느린 네트워크 스토리지 환경에서는 conservative offload
2. Dynamo KV Block manager interface
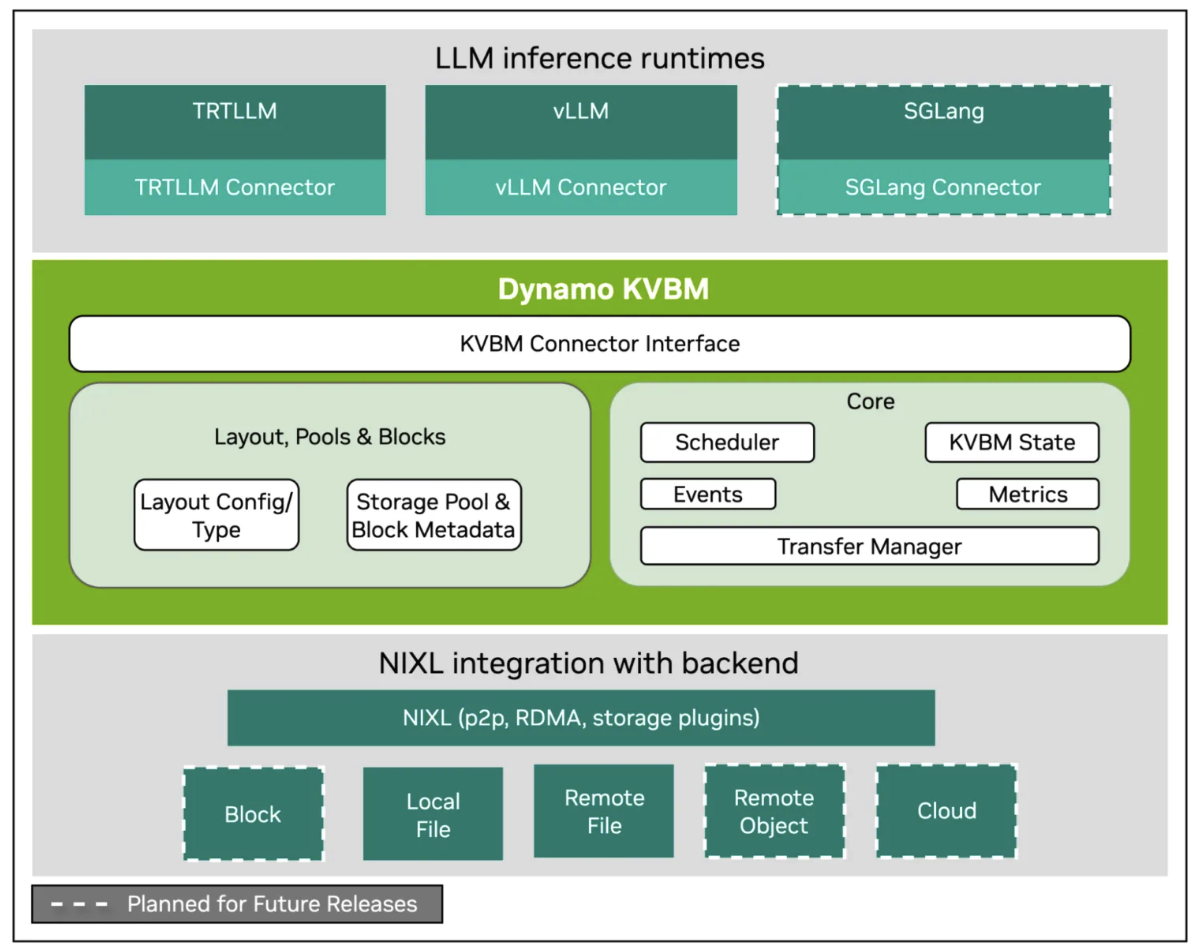
2.1. LLM Inference Runtimes 계층
- TRTLLM, vLLM, SGLang 같은 주요 추론 엔진들이 위치.
- 각 엔진은 전용 Connector를 통해 Dynamo KVBM에 접근.
- Connector는 KV cache 관리 로직을 런타임에서 분리시켜, 엔진별 구현 차이를 줄이고 표준화된 인터페이스 제공.
2.2. Dynamo interface 계층
인터페이스는 두가지로 나뉨.
Dynamo KVBM
Layout, Pools & Blocks: KV cache를 조각(block) 단위로 분리해서 계층적 저장소 간 배치/이동을 관리하는 역할.
Layout Config/Type: KV 캐시를 어떤 단위(예: block size, tensor layout 등)로 분할할지 정의.Storage Pool & Block Metadata: KV cache 블록별 위치(GPU, CPU, SSD, Remote 등), 크기, 참조 횟수 같은 메타데이터 관리.
Core: 실시간 스케줄링 및 성능 최적화 담당.
Scheduler: 어느 블록을 GPU에 남기고, 어느 블록을 오프로드할지 결정. (LRU, LFU, 핫/콜드 블록 구분 정책 등 적용 가능)Events: KV cache 이동/할당/해제 같은 이벤트 처리.Transfer Manager: GPU/CPU/SSD 간 블록 전송 관리. NIXL과 직접 연동됨.KVBM State: 현재 KV cache 상태 (메모리 점유율, 각 블록의 tier 위치 등) 기록.Metrics: 오프로드/로드 지연, 전송 대역폭, 블록 접근 패턴 등 모니터링 지표 제공.
NIXL Integration with Backend
NIXL: 데이터 전송 계층으로, p2p, RDMA, storage plugin 지원. RDMA(Remote Direct Memory Access)를 이용해 GPU/원격 스토리지 간 직접 데이터 전송 가능해, CPU 개입 최소화, latency 감소.
지원하는 backend
Local File: 로컬 SSD/NVMeRemote File: 원격 파일 시스템 (예: Lustre, NFS)Remote Object: Object storage (예: S3)Cloud: 퍼블릭 클라우드 스토리지
3. 효과
- 생성 프롬프트 길이 제한이 완화됨
- 다중 요청을 처리할 때, 더 많은 세션을 동시에 유지 가능
- TTFT (Time To First Token) 초기 응답 지연 감소

별 하나의 추억과.