python=3.8
airflow=2.5.2AWS의 SageMaker를 사용하여 분류 모델링 테스트를 진행하고 있다. 회사의 데이터베이스에 저장된 데이터를 학습 데이터로 활용하고 있다.
이미 초기 학습데이터를 구성했지만, 시간이 지남에 따라 추가로 활용할 수 있는 데이터가 DB에 저장되고 있어 학습 데이터를 주기적으로 업데이트 해줄 필요가 있다. 주기적인 업데이트가 필요하여 Airflow 를 활용하면 도움이 될 것이라고 생각했다.
기본적으로 모델 학습에 SageMaker를 사용하고 있고, 학습 데이터 역시 S3에 저장해두고 사용하고 있다. 그래서 DB에서 원하는 데이터를 추출하고 변환하고 이를 S3에 저장해야 한다.
이 작업을 진행하기 위해선 우선적으로 airflow 와 AWS S3를 연결할 수 있어야 한다.
Create Airflow Connection
BigQuery 를 연결했던 것과 동일하게 Connection를 생성해야 한다.
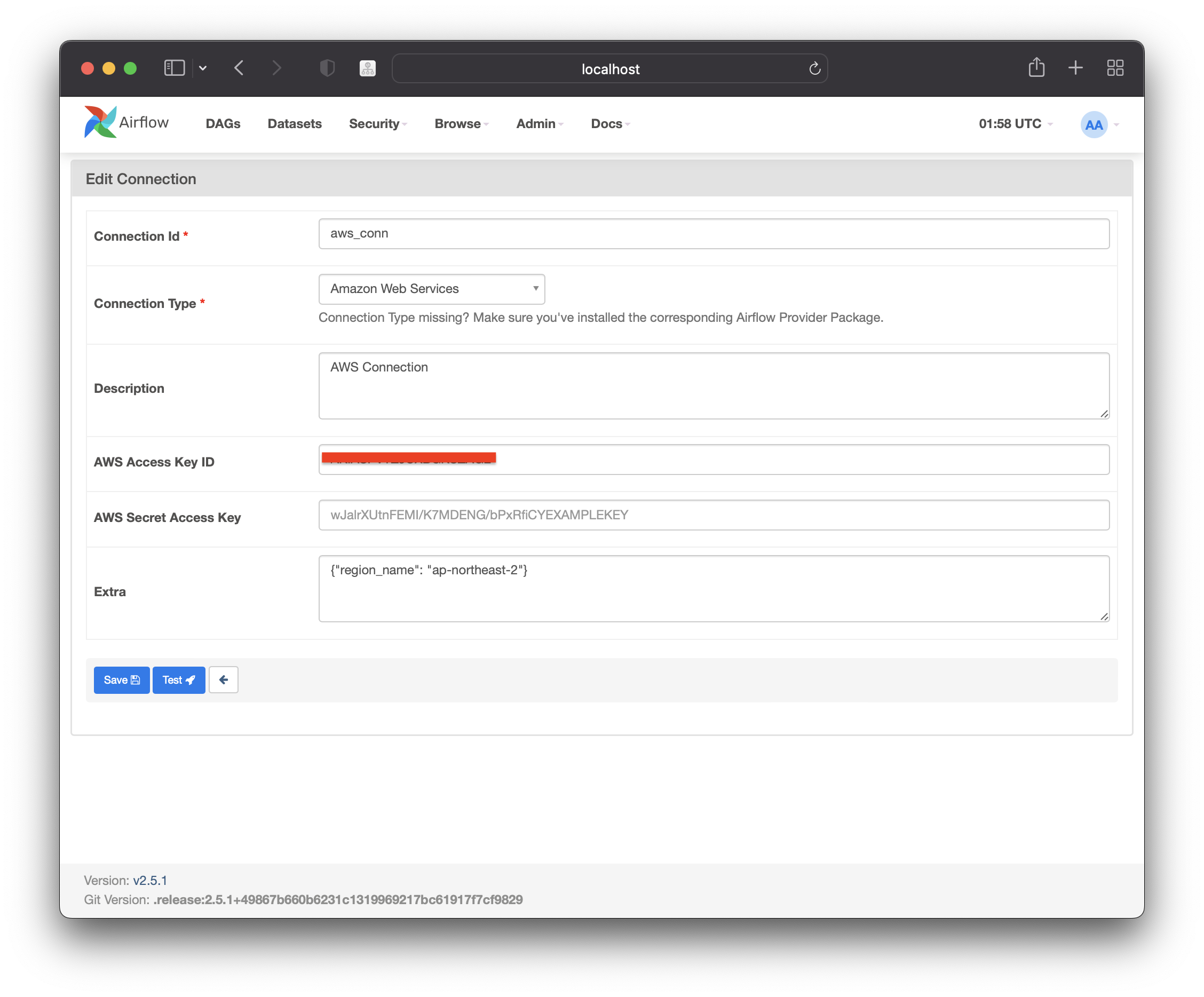
이때 connection Type 에 Amazon Web Service 를 선택하고 비어있는 값들을 채워주면 된다. 가장 중요한 값은 AWS Access Key ID 와 AWS Secret Access Key 이다.
원하는 AWS 계정 및 AWS 환경에 접근할 수 있는 환경변수라고 생각할 수 있다. 이 두개는 AWS 계정 및 iam 콘솔에서 확인할 수 있다.
extra 부분에 json 형태로 access Key 를 제외한 조건들을 지정할 수 있는데, 이때 region_name 을 지정해주면 지역의 default 값을 설정해주었다.
Amazon Web Service에 잘 연결할 수 있는 지 아래 "test" 버튼을 통해 확인할 수 있다. 연결이 가능하면 초록색의 알림창과 함께 AWS access Key에 해당하는 userId, account, iam 가 나타난다.
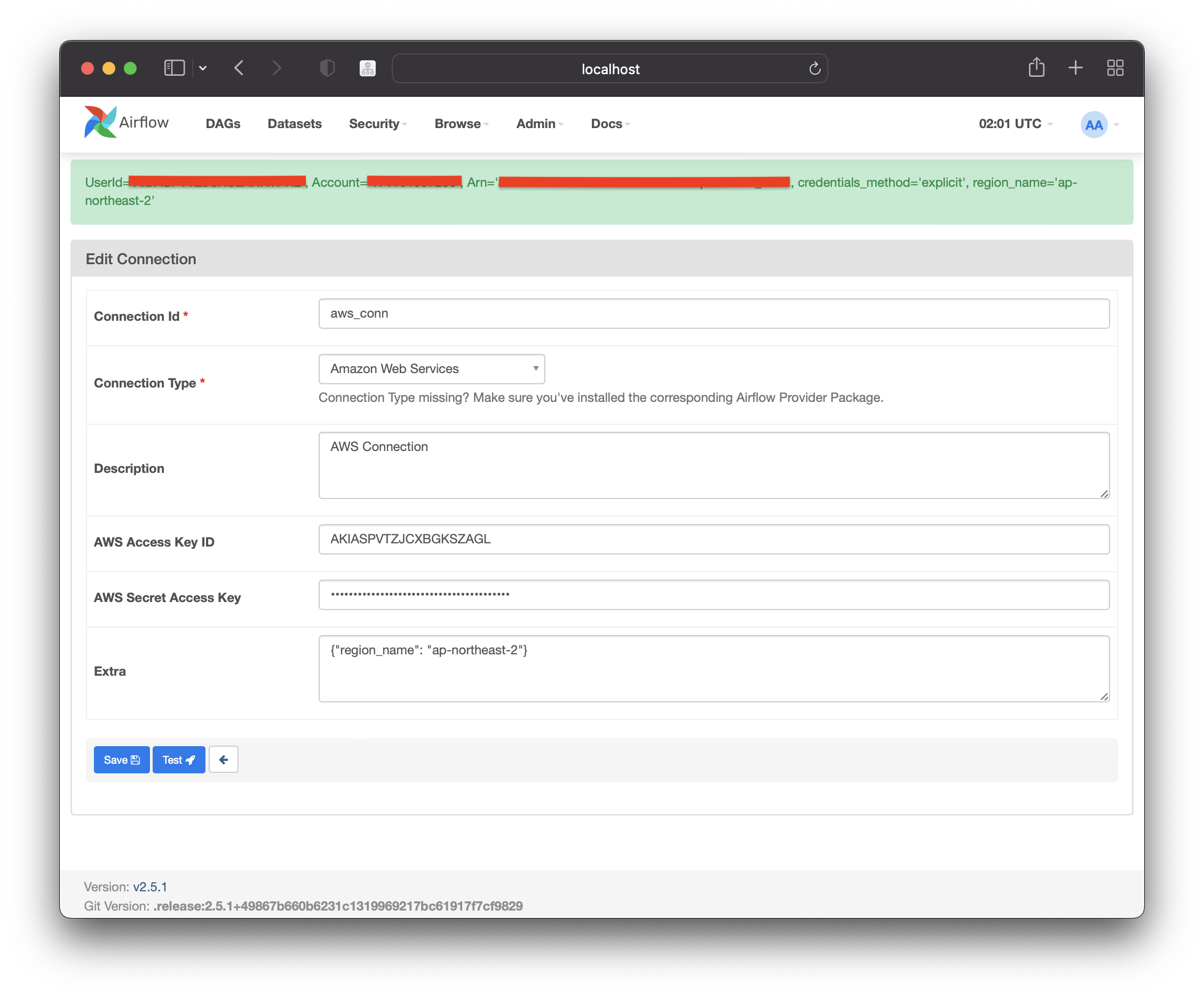
그리고 "Save" 버튼을 누르면 Amazon Web Service와의 Connection이 만들어진다.
Local to S3 Bucket
로컬에 저장된 파일을 S3 Bucket에 저장하는 DAG를 구성했고, 이를 테스트한다. 이때 S3Hook 과 PythonOperator 로 기능을 구현했다.
S3Hook 에 앞서 생성한 Connection의 Id를 입력한다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
def upload_to_s3(filename: str, key: str, bucket_name: str) -> None:
hook = S3Hook('aws_conn')
hook.load_file(filename=filename,
key=key,
bucket_name=bucket_name,
replace=True)
with DAG('upload_to_s3',
schedule_interval=None,
start_date=datetime(2022, 1, 1),
catchup=False
) as dag:
upload = PythonOperator(task_id='upload',
python_callable=upload_to_s3,
op_kwargs={
'filename': '/opt/airflow/data/test.csv',
'key': 'dataSource/test.csv',
'bucket_name': 'your-bucket-name'
})
uploaddocker-compose.yaml 파일에 volume 마운트 부분에 /opt/airflow/data 을 추가해둔 상태이다. 해당 폴더에 저장 및 지정된 파일을 S3d에 load하는 것이다.
해당 DAG를 수행하고 나면 S3 bucket에 파일이 저장된 것을 볼 수 있다.
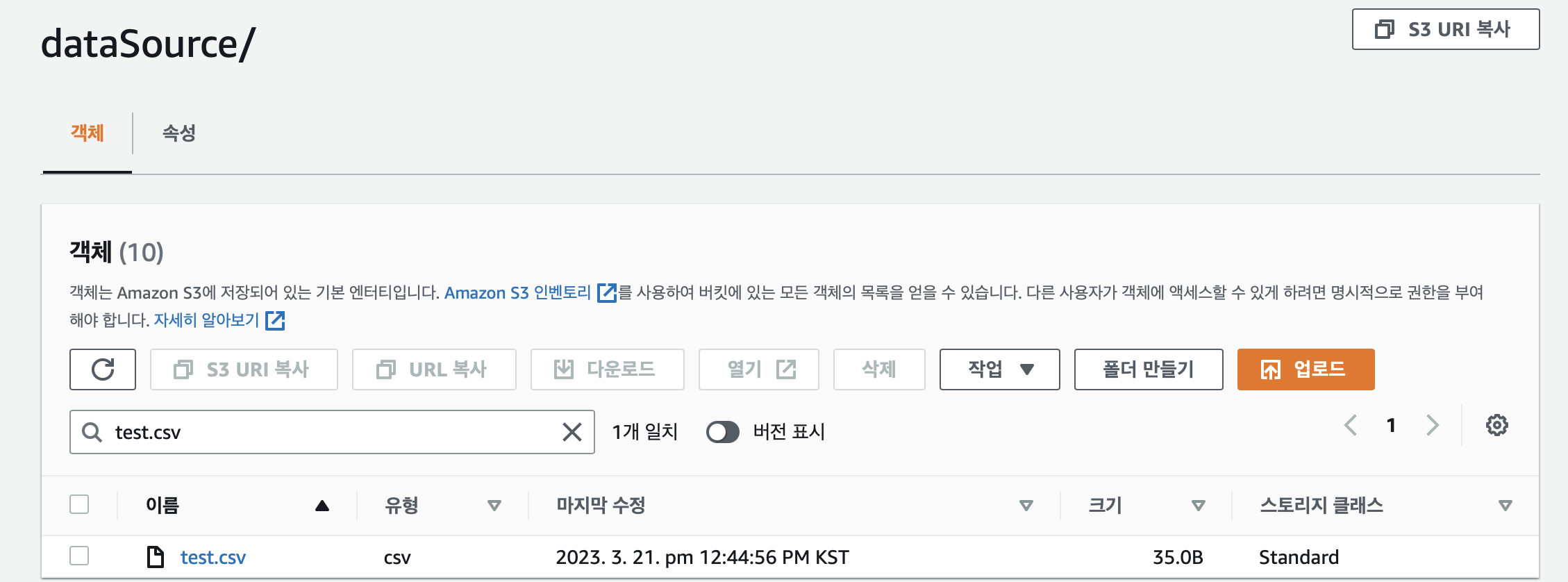
Airflow 2.5.2 최신 버전으로 테스트을 진행하다보니 구글링이 쉽지 않다. 원하는 ETL 작업을 완료하기 위해 한단계씩 해볼 예정
