앞으로 이야기할 주제는 예약 주문 결제 프로젝트를 진행하던 중 만난 동시성 문제에 관한 이야기이다.
동시성 문제란?
먼저, 동시성 문제란 한 자원에 여러 쓰레드가 동시에 접근 했을 때, 내가 예상했던 값이 결과로 나타나지 않는 것을 말한다.
예를 들어보면,
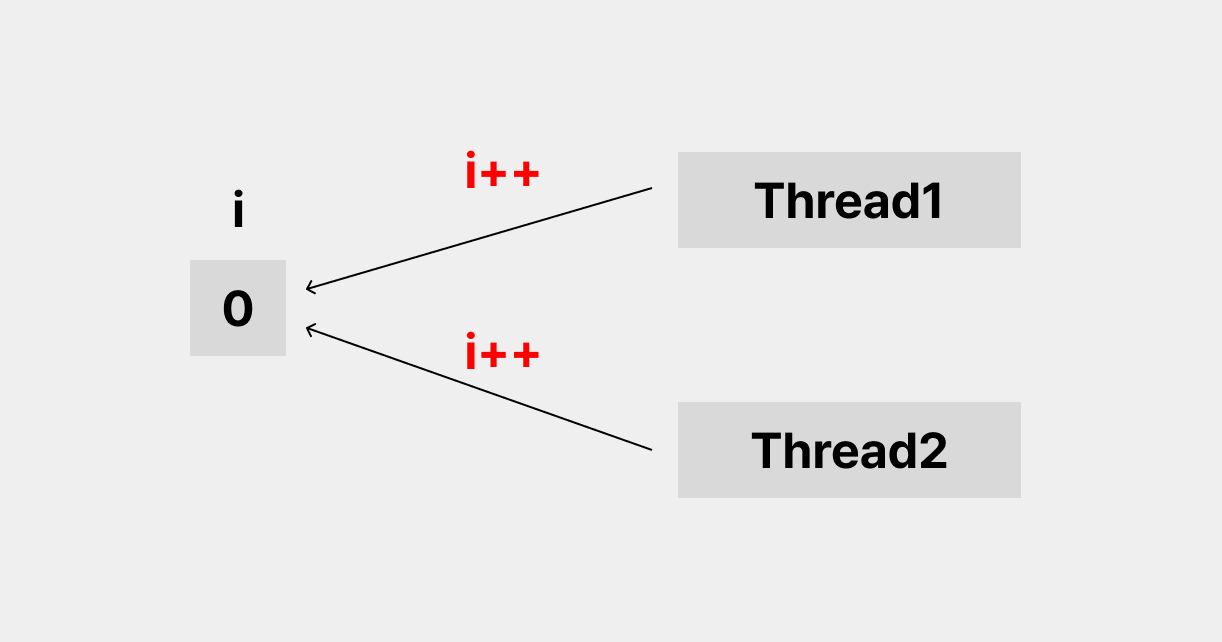
위의 그림처럼 i라는 자원에 대해서 두 쓰레드가 동시에 접근한다고 가정해보자.
동시에 접근한 후에 i++를 해주었다. 우리가 예상한 값은 2 이지만, i 값은 1이 되었다. 왜 이러한 결과가 나타났을까? 과정을 살펴보자.
- thread1이 i를 읽는다. 동시에 thread2도 i를 읽는다. 두 쓰레드가 읽은 값은 0 이다.
- 두 쓰레드는 0에다가 1을 더 해준 후 i에 값을 덮어씌운다.
- i의 값은 1이된다.
결국은 i라는 값을 읽을 때, 두 쓰레드가 같은 값을 읽기 때문에 발생 하는 문제이다.
맨 처음에 말했듯이, 이번 프로젝트는 예약 구매 상황에서 많은 사용자가 동시에 결제를 하고자 접근했을 때, 발생한 문제를 해결하고자 하였다.
시뮬레이션
시뮬레이션 계획은 다음과 같다.
- 예약 구매가 가능한 A상품이 있고, 재고 수량은 10개이다.
- 동시에 몰리는 이용자의 수는 10000명이다.
- 시뮬레이션 진행과정
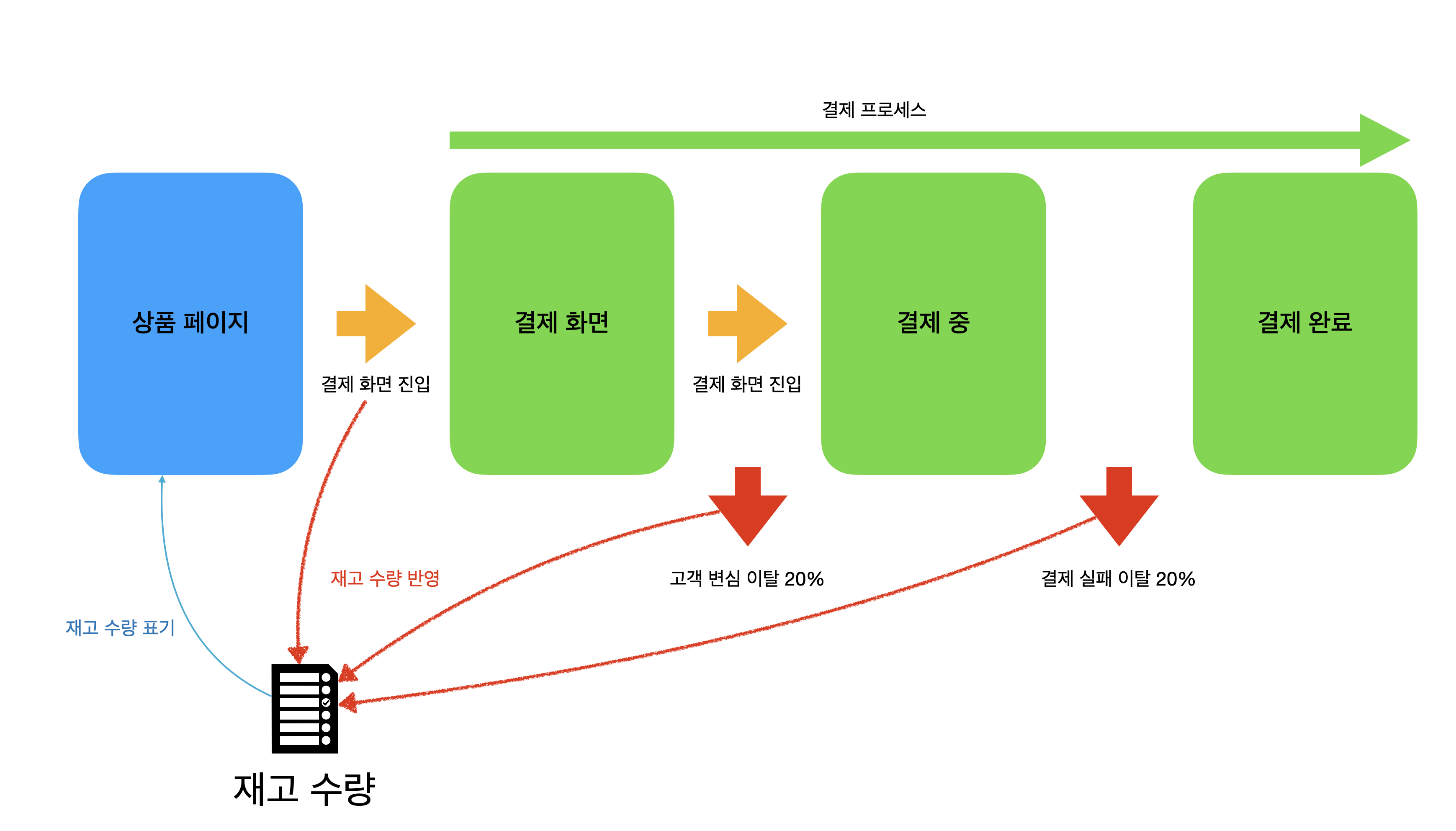
결제 진입 API를 자세하게 살펴보자.
결제 진입에서 체크할 부분은 두 가지 이다.
- 예약 상품이라면 현재 시간이 예약 시간을 지났는지 체크
- 재고 예약 가능한 상태인지 체크
동시성 문제가 발생할 수 있는 부분은 상품의 재고를 처리(재고 예약 or 취소)하는 부분이다.
재고를 예약하는 내부 로직은 다음과 같다.
public Boolean reserveStock(EnterPayRequestDto payRequestDto) {
//상품 조회
Item item = itemRepository.findById(payRequestDto.getItemId())
.orElseThrow(() -> new ItemServiceException(ErrorCode.NO_ITEMS));
//재고 예약으로 인한 재고 감소
Long newStock = item.getStock() - payRequestDto.getCount();
//재고 예약이 가능한 경우
if (newStock >= 0) {
//DB 재고 변경
item.changeStock(newStock);
return true;
// 재고 예약이 불가능한 경우
}else{
return false;
}
}- 먼저 상품 재고를 조회한다.
- 재고를 예약 한 후에도 재고가 0개 이상이라면, 재고를 예약해주고, DB에 반영한 후
true를 return 한다. - 재고를 예약 한 후 재고가 0개 미만이라면, false를 return 한다.
위와 같은 메서드에 동시에 두개의 쓰레드가 접근한다면 어떻게 될까?
상품 개수가 10개 일때 Thread A와 B가 동시에 재고를 조회했다고 하자.
A와 B가 조회한 상품 개수는 10개이다. 상품을 하나씩 구매한다고 했을 때,
예상되는 남은 상품 재고는 8개이다. 하지만 실제 결과는 9개가 남게 되었다.
위의 그림에서 i가 DB에서 상품의 재고 수 라고 해보자.
Thread A와 Thread B는 같은 재고 수를 조회 하게 된다. 따라서, 모두 하나씩 재고를 감소 시켜 재고 2개를 감소시켜야 하지만, 결과적으로는 1이 감소되게 된다.
이러한 동시성 문제는 어떻게 해결하면 좋을까? 이제부터 동시성 문제를 어떻게 해결 했는지 알아보도록 하겠다.
문제 해결 순서
그렇다면, 동시성 문제는 어떠한 방식으로 해결할 수 있을까?
나는 다음과 같은 순서로 동시성 문제 해결을 진행하려고 한다.
- java @synchronized
- RDB pessimistic Lock(write), 베타적 락 사용
- 분산락
- 분산락 + redis 캐시
운영체제에서의 Synchronization 및 Lock 알고리즘에 대해 자세히 알고 싶다면 아래 블로그를 참고하면 좋을 것 같다.
참고: [운영체제]Synchronization
@synchronized로 동시성 문제 해결하기
해결 1
lombok을 이용한 Synchronized 걸어주기
@Synchronized
@Transactional
public Boolean reserveStock(EnterPayRequestDto payRequestDto) {
//상품 조회
Item item = itemRepository.findById(payRequestDto.getItemId())
.orElseThrow(() -> new ItemServiceException(ErrorCode.NO_ITEMS));
//재고 예약으로 인한 재고 감소
Long newStock = item.getStock() - payRequestDto.getCount();
//재고 예약이 가능한 경우
if (newStock >= 0) {
//DB 재고 변경
item.changeStock(newStock);
return true;
// 재고 예약이 불가능한 경우
}else{
return false;
}
}동시성 문제가 발생하는 이유는 java가 멀티쓰레드 환경이기 때문이다.
@Synchronized는 싱글 쓰레드 방식으로 로직을 처리할 수 있도록 도와 준다.
즉, Thread A가 재고 예약을 다 끝내면, Thread B가 다음 재고 예약을 시작하는 방식이다.
이 방법이면, 해결이 될 줄 알았는데, 여전히 동시성 문제가 해결되지 않았다.
이유는, @Synchronized는 트랜잭션이 시작할때부터 끝날때까지만, 유효하기 때문이다. 이말인 즉슨, 트랜잭션이 끝나고 나서야 dirty checking으로 변경된 값을 DB에 반영하게 되는데, Synchronized는 변경된 값이 반영되기 전에 끝나기 때문에, 실제적으로 DB를 수정하기 전에 재고 조회가 가능해버리게 된다.
따라서, 트랜잭션이 끝나기 전에 변경된 엔티티를 DB에 flush 해주거나, 더 넓은 범위의 트랜잭션에서 Synchronized처리를 해주어야 한다.
해결 2
나는 더 넓은 범위인 결제 진입 API에서 @Synchronized를 적용했다.
이렇게 하게 되면, 아예 싱글 쓰레드 환경이 되어 data의 일관성이 보장된다.
10000명이 10개 상품에 대하여 동시 접근하여 결제를 시도 했을 때의 결과는 다음과 같았다.
문제점
synchronized는 한 트랜잭션에 대해서만 동시성을 보장 해주기 때문에 서버를 여러대로 두는 환경에서는 적합하지 않다고 생각했고, DB Lock을 생각하게 되었다.
2. DB Lock으로 동시성 문제 해결하기
DB Lock의 종류와 특징
먼저 DB Lock의 종류에는 어떤 것들이 알아보고, 각 Lock의 특징을 알아보자.
- 낙관적 락(Optimistic Lock)
낙관적 락은 DB의 version 컬럼을 두어 동시성 문제를 해결한다.
낙관적 락은 기본적으로 트랜잭션을 사용하지 않고, DB가 아니라 Application level에서 처리한다.
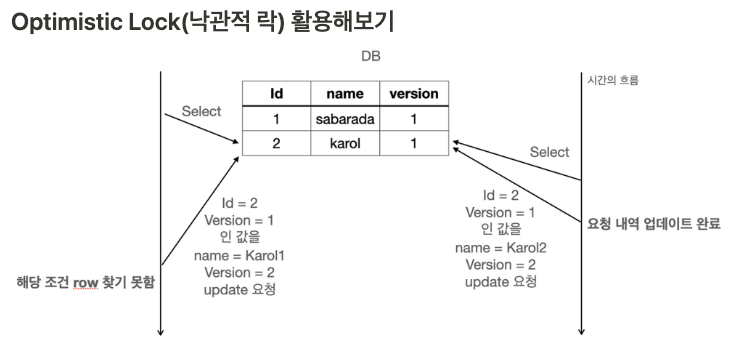
왼쪽을 Thread A, 오른쪽을 Thread B 라고 하자.
1. A와 B에서 id = 2인 값의 행을 읽어들였다. 둘다 읽어드린 행의 버전은 1이다.
2. B가 먼저 name을 업데이트 했고, version도 1 증가한 2로 업데이트 했다.
3. A가 name을 업데이트 하려고 했는데, version이 1이 아닌 2이기 때문에 업데이트 하지 못했다.
위의 예시에서 봤듯이, 낙관적 락은 버전 일치 여부를 통해 업데이트를 방지하여, 동시성 문제를 해결한다. 하지만 문제는, A가 버전이 일치하지 않아 업데이트를 하지 못했을 경우 rollback이 일어나지 않는다.
낙관적 락은 버전 충돌이 일어났을 경우 별도의 로직을 통해 롤백을 해줘야 한다.
따라서, 트랜잭션 충돌이 자주 일어나는 경우에는 사용하지 않는다.
이 프로젝트에서는 재고를 관리하는 과정에서 트랜잭션 충돌이 빈번하게 발생하므로 낙관적 락은 사용하지 않았다.
- 비관적 락(Pessimistic Lock)
비관적 락은 두가지 종류의 락이 있다.
1. 공유 락(S-Lock,read mode)
2. 베타적 락(X-Lock,write mode)
S-Lock은 읽기 전용 이라고 생각하면 된다.
다만, 공유 락이라는 이름의 특성 처럼 트랜잭션들이 락을 공유할 수 있다.
무슨 말인지 한번 구체적인 예시를 들어보겠다.
Transaction A가 공유락을 획득했을 경우, 다른 Transaction들도 공유락을 획득할 수 있다. 즉, A가 data를 읽고 있음에도, 다른 B,C Transaction들도 data를 읽을 수 있다는 것이다.
하지만, A가 S-Lock을 획득한 상태에서 D가 X-Lock을 획득한다고 한다면 이는 차단된다.
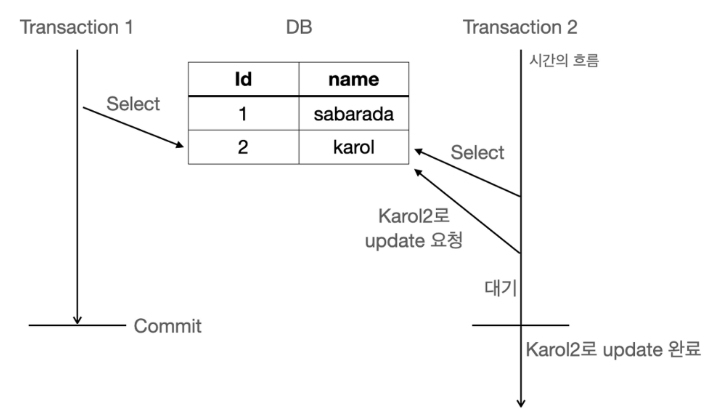
위에 그림을 보면, Transaction 1이 S-Lock을 획득한 상태에서 Transaction 2가 업데이트를 시도하려고 했지만, 차단됐다. Transaction 1이 commit을 한 이후에야 Transaction 2가 업데이트를 완료하는 것을 볼 수 있다.
위처럼, 업데이트 하기 위해 필요한 Lock이 바로 X-Lock이다. X-Lock은 쓰기 전용 이라고 생각하면 쉽다. 다만, X-Lock을 획득하게 되면, 다른 Transaction은 X-Lock과 S-Lock 모두를 획득하지 못한 채로 대기해야 한다.
결과적으로, 멀티 쓰레드 환경에서 동시에 많은 쓰레드가 재고를 조회하고 수정하려고 하기 때문에, 트랜잭션 충돌이 많이 발생할 것이고, 재고 관리에서 동시성을 보장하기 위해서는 X-Lock 처럼 한 쓰레드(유저)가 재고를 예약하여 감소시킨 값을 commit 할때까지, 다른 쓰레드가 접근하지 못해야 동시성 문제가 해결될 수 있다.
따라서, 이번 프로젝트에서는 X-Lock을 사용하게 되었다.
해결
X-Lock을 적용하는 과정은 간단하다.
jpa repository에 다음과 같이 어노테이션만 붙여주면 된다.
public interface ItemRepository extends JpaRepository<Item,Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select i from Item i where i.id = :id")
Optional<Item> findByIdForUpdate(@Param("id") Long itemId);
}문제점
문제는 MSA 환경에서는 분산 DB를 사용하기 때문에 하나의 DB에서만 동시성 문제를 해결 할 수 있는 DB Lock 방식은 이 프로젝트의 해결방법이 될 수 없었다.
분산락
redis를 이용한 분산락 방식은 redis에서 Lock을 읽고 쓰는 작업을 통해, 동시성을 제어하는 방식이다. 분산 DB에서도 data의 일관성을 보장하고 동시성을 보장해 준다. 또한 Lock을 인메모리에서 read,write를 하기 때문에 속도도 빠르다.
redis를 이용한 분산락 방식은 두가지가 있다.
분산락 종류
- rettuce 이용한 분산락
- redisson 이용한 분산락
두 방식에는 차이가 Lock을 획득하는 방식에 차이가 있다.
-
rettuce는 spin Lock 방식이다.
spin Lock은 Lock을 획득하기 위해서 계속해서 접근한다. 즉, A Thread가 Lock을 획득했을 경우, B Thread는 A가 Lock을 반환 할 때까지 계속 접근 하면서 물어본다.
Lock을 획득하기 위해서 redis에 계속 요청한다는 것은 redis에게 큰 부담이 될 수 있다. -
redisson은 비동기 방식의 메세지 큐를 사용한다.
A Thread가 Lock을 획득했을 경우, B Thread는 Lock을 획득하기 위해서 계속해서 접근할 필요가 없다. A thread가 Lock을 반환할 경우 B Thread에게 Lock이 반환되었다는 메세지가 도착한다. B Thread는 이때 Lock을 얻으려고 시도 한다.
redisson을 이용한 방식이 rettuce보다 redis에 부하를 적게 주고 성능이 훨씬 좋으므로, redisson 방식을 채택했다.
분산락 구현 With. redisson
- redis bean 등록
@Configuration
public class RedisConfiguration {
@Bean
public RedisConnectionFactory redisConnectionFactory(){
return new LettuceConnectionFactory(new RedisStandaloneConfiguration("localhost",79));
}
@Bean
public RedisTemplate<String,Long> redisTemplate(){
RedisTemplate<String,Long> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericToStringSerializer<>(Long.class));
return redisTemplate;
}
}- redisson bean 등록
@Configuration
public class RedissonConfig {
private final String redisHost = "localhost";
private final int redisPort = 79;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.useSingleServer().setAddress(REDISSON_HOST_PREFIX + redisHost + ":" + redisPort);
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}- 분산락 적용
@Transactional
public boolean reserveStockRequest(EnterPayRequestDto req) {
//Lock 설정
String lockKey = "lockKey:" + req.getItemId();
RLock lock = redissonClient.getLock(lockKey);
Boolean reserveStock = false;
try {
//락 획득
if (!lock.tryLock(10, 1, TimeUnit.SECONDS)) {
log.info("userId:{},lock 획득 실패", req.getUserId());
return false;
}
ResponseEntity<Boolean> response = itemServiceClient.reserveStock(req);
reserveStock = response.getBody();
log.info("userId:{}\nitemId:{}\nstockCount:{}\n재고 예약 가능 여부:{}", req.getUserId(), req.getItemId(), req.getCount(), reserveStock);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//락 반환
lock.unlock();
}
return reserveStock;
}-
tryLock의 첫번째 argument는 Lock 획득을 위해 기다리는 시간이다.
이 시간이 지나면, Lock 획득에 실패하게 되고 false를 return 하여 결제를 취소 한다.
Lock을 재획득하게 한다면, 모든 유저가 재고를 요청해 볼 수 있는 기회를 가지게 되겠지만, 성능이 느려지는 trade off가 있기 때문에, 성능을 더 최적화 하기 위해서 재획득 하지 않게 했다. -
tryLock의 두번째 argument는 lease Time이다. 즉, Lock이 지속되는 시간이다.
한 Thread가 Lock을 너무 오랜 시간 잡고 있으면, 그 만큼 CPU가 낭비 되는 시간이 길어지는 것이기 때문에, 적절한 lease Time을 주는 것이 중요하다. -
unlock은 반드시 finally에서 해주어야 한다. exepction이 발생한 상황에서도 Lock은 해제 해주어야 하기 때문이다.
문제점
분산락 방식이 MSA와 같은 분산 환경에서 동시성을 보장하기 위해 적합한 것은 사실이다. 하지만, 분산락 만으로 DB에 접근하게 되면, DB에서 I/O하는 것이 오버헤드가 크다. 따라서, redis를 캐시로 이용하여 재고를 조회 하도록 해 주었다.
분산락 + redis 캐시
재고를 조회하기 위해서 redis를 캐시로 사용한다. 인메모리에서 재고를 조회하기 때문에 DB에서 조회하는 것보다 훨씬 속도가 빠르다.
여러 캐시 전략 중에서 어떤 전략을 사용해야 할지 고민했다.
cache-aside 같은 읽기에 특화된 전략들은 재고 감소가 일어날 때 마다 DB에 업데이트 시켜줘야 하기 때문에 오버헤드가 크다.
반면, write back cache 전략은 감소시킨 재고를 cache에만 업데이트 해주고 있다가, 한번에 DB에 업데이트 해주는 방식이다.
예를 들어, 유투브 조회수나 좋아요 같은 것들은 매번 DB에 업데이트 하지 않는다.
너무 자주 일어나기 때문에, 한번에 bulk 연산해 주는 것이 성능면에서 훨씬 좋기 때문이다.
이 프로젝트에서는 재고 변경이 빈번하게 일어나기 때문에 write back cache가 알맞은 전략이라 생각하였다.
재고 예약
재고가 남아있는지 확인 한후, 재고를 예약할 수 있도록 하였다. 재고 예약시 캐시의 재고를 감소 시킨다. 마지막으로, 재고 예약이 가능하다면 true, 재고 예약이 가능하지 않다면 false를 return 해준다.
public Boolean reserveStock(EnterPayRequestDto payRequestDto) {
// 캐시에서 재고 조회
String key = "itemId:stock:" + payRequestDto.getItemId();
Long stock = redisTemplate.opsForValue().get(key);
//캐시에 재고가 존재 한다면
if (stock != null) {
//재고를 줄인다.
if (stock - payRequestDto.getCount() >= 0) {
Long newStock = redisTemplate.opsForValue().decrement(key, payRequestDto.getCount());
return true;
} else {
//재고 부족
return false;
}
}
//캐시에 재고가 존재하지 않는다면
else {
Item item = itemRepository.findById(payRequestDto.getItemId()).orElseThrow(() -> new ItemServiceException(ErrorCode.NO_ITEMS));
Long newStock = item.getStock() - payRequestDto.getCount();
//재고 예약이 가능한 경우
if (newStock >= 0) {
//DB 재고 변경
item.changeStock(newStock);
//cache에 추가
redisTemplate.opsForValue().set(key, newStock);
return true;
} else {
return false;
}
}
}
재고 예약 취소
재고 예약을 취소하게 되면 다시 캐시의 재고를 올려준다.
public void cancelStock(EnterPayRequestDto payRequestDto) {
// 캐시에서 재고 조회
String key = "itemId:stock:" + payRequestDto.getItemId();
Long stock = redisTemplate.opsForValue().get(key);
//캐시에 재고가 존재 한다면
if (stock != null) {
//재고를 증가 시킨다.
redisTemplate.opsForValue().increment(key, payRequestDto.getCount());
}
//캐시에 재고 존재하지 않는다면
else {
Item item = itemRepository.findById(payRequestDto.getItemId()).orElseThrow(() -> new ItemServiceException(ErrorCode.NO_ITEMS));
Long newStock = item.getStock() + payRequestDto.getCount();
item.changeStock(newStock);
redisTemplate.opsForValue().set(key, newStock);
}
}DB와 캐시 동기화
DB와 캐시의 동기화를 위해 @Scheduled를 사용했다. 5초마다 DB와 캐시의 동기화가 일어난다.
@Scheduled(fixedRate = 5000)
public void syncDB() {
// SCAN 옵션 생성, 매치할 키 패턴 설정
ScanOptions options = ScanOptions.scanOptions().match("itemId:stock:*").build();
try (Cursor<byte[]> cursor = redisTemplate.getConnectionFactory().getConnection().scan(options)) {
while (cursor.hasNext()) {
String key = new String(cursor.next());
// 캐시에서 itemId의 재고 조회
Long stock = redisTemplate.opsForValue().get(key);
// itemId 파싱
String itemId = key.split(":")[2];
// DB 업데이트
Item item = itemRepository.findById(Long.parseLong(itemId)).orElseThrow(() -> new ItemServiceException(ErrorCode.NO_ITEMS));
item.changeStock(stock);
}
} catch (Exception e) {
// 예외 처리 로직 추가
e.printStackTrace();
}
}성능 테스트
Jmeter를 사용해서 테스트 하였고, 10000개의 Thread가 1초 동안 발생하도록 설정하였다. 성능을 측정하기 위해 내가 확인할 부분은 throughput이다.
throughput은 초당 처리 가능한 요청 수 이다. 따라서 throughput이 높다면 성능이 높다고 할 수 있다.
테스트의 주요 쟁점
1. 상품 10개를 결제 하기 위해 동시에 10000명이 접근했을 때, 10명만 결제가 완료 되도록 한다.
2. 성능
Synchronized

- throughput : 81.3/sec
하나의 서버를 두고 하나의 트랜잭션에 대해서만 동시성을 보장할 수 있다.
하지만, 서버가 여러대일 경우에는 동시성 보장이 되지 않는다.
MSA 환경에서는 scale out을 해야하기 때문에 사용할 수 없다.
DB Lock

- throughput : 150/sec
synchronized에 비해 굉장히 빠르다. 하지만, 분산 DB 환경에서는 사용할 수가 없다.
분산락

- throughput: 66.1/sec
분산락은 MSA와 같은 분산 DB 환경에서 동시성을 보장해주는 장점이 있다.
하지만, 기본적으로 외부 서버에 API 요청을 자주 하기 때문에, 네트워크 지연으로 인한 오버헤드가 크다. 따라서 성능이 잘 나오지 않는다.
분산락 + 캐시

-
throughput: 82.9/sec
-
분산락 사용만으로는 성능이 너무 낮기 때문에, 이를 보완하기 위해서 redis를 캐시로 사용하였다.
-
캐싱 전략: write back
-
이유: 재고를 매번 수정해야 하고, 캐시의 값으로만 재고를 조회하기 때문에, DB에 빠른 동기화는 필요하지 않다.
-
분산락만 사용했을때보다 25.42%의 성능 증가를 보였다.
