DFS(Depth First Search, 깊이 우선 탐색)
탐색할때 깊은 것을 우선적으로 하여 탐색
맹목적으로 각 노드를 탐색할 때 이용
stack 사용
사실은 재귀만으로도 구현 가능
DFS는 다음과 같은 알고리즘에 의해 구현된다.
- 스택의 최상단 노드를 확인한다.
- 최상단 노드에게 방문하지 않은 노드가 있으면 그 노드를 스택에 넣고 방문처리한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 뺀다.
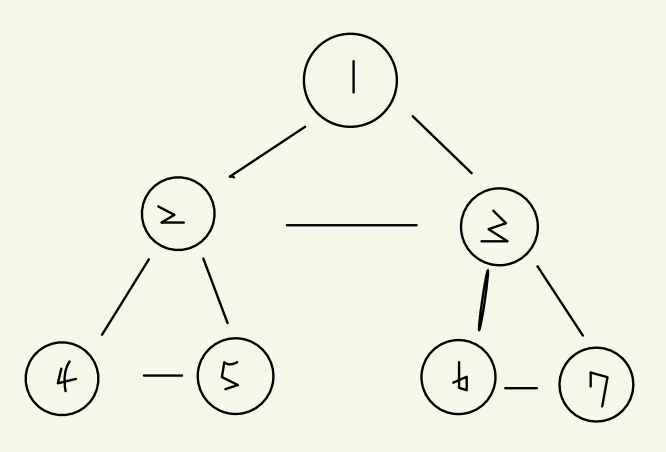
먼저 최상단 노드인 1을 확인한다.
1의 방문하지 않은 노드인 2를 스택에 넣고 방문처리
stack: 2 1]
최상단 노드인 2를 확인
2의 인접노드인 3확인
3을 stack에 넣고 방문처리
stack: 3 2 1]
최상단 노드 3확인
3의 인접노드인 6 확인
6을 stack에 넣고 방문처리
stack: 6 3 2 1]
최상단 노드 6 확인
6의 인접노드 7확인
7을 stack에 넣고 방문처리
stack: 7 6 3 2 1]
최상단 노드 7 확인
방문할 인접노드 없으므로 최상단 노드인 7을 제거
stack:6 3 2 1
마찬가지로 6,3제거
stack: 2 1]
최상단 노드 2 확인
2 인접노드 4확인
4 스택에 넣고 방문처리
stack: 4 2 1]
최상단 노드 4 확인
인접노드 5확인
5 stack에 넣고 방문처리
stack: 5 4 2 1]
방문하지 않은 인접노드 없으므로 5 4 2 1순으로 스택에서 제거
재귀적으로 구현
컴퓨터에서 프로그램의 구조 자체가 stack이기 때문에 대회 같은 곳에서는 보통 재귀함수로 구현한다.
#include <iostream>
#include <vector>
using namespace std;
//노드 개수
int number = 7;
//방문 체크
int c[7];
//각 인접한 노드
vector<int> a[8];
void dfs(int x){
if(c[x]) return;
c[x] = true;
cout << x << ' ';
for(int i = 0; i<a[x].size(); i++){
int y = a[x][i];
dfs(y);
}
}
int main(){
a[1].push_back(2);
a[2].push_back(1);
a[1].push_back(3);
a[3].push_back(1);
a[2].push_back(3);
a[3].push_back(2);
a[2].push_back(4);
a[4].push_back(2);
a[2].push_back(5);
a[5].push_back(2);
a[4].push_back(5);
a[5].push_back(4);
a[3].push_back(6);
a[6].push_back(3);
a[3].push_back(7);
a[7].push_back(3);
a[6].push_back(7);
a[7].push_back(6);
dfs(1);
}