1. 개요
팀프로젝트 <포털사이트를 이용한 뉴스 분야별 이슈 크롤링>은 주요 검색 포털 사이트인 네이버를 크롤링하는 방법을 통해, 현재 화제가 되고 있는 뉴스 키워드들을 분야별, 빈도순으로 나열하여 한눈에 보기 쉽게 하기 위함을 목표로 하여 시행하였습니다.
구체적으로 네이버 뉴스의 사회 뉴스, 정치 뉴스, 경제 뉴스, 문화 뉴스, 과학 뉴스, IT 뉴스로 분야별로 나누어 단어들을 중심으로 크롤링하였습니다.
이러한 주제를 선정하게 된 배경에는 크게 세 가지입니다.
A. 실시간 검색어 폐지
지난 2월, 여론조작 등의 이유로 실시간 검색어가 폐지되었습니다.
실시간 검색어 기능은 쉽고 빠르게 현재 이슈되고 있는 화제거리들을 알 수 있게 하는 장점을 가지고 있었습니다.
지금은 실시간 검색어 기능뿐만 아니라, 뉴스토픽 제공 기능까지 사라진 상태입니다.
이에 많은 사람들은 요즘 대두되고 있는 뉴스거리들을 바로바로 알기가 어렵다는 불편함을 호소하고 있습니다.
따라서, 단어 크롤링을 통해 가장 많이 사용되는 뉴스 키워드들을 추출하여 이에 도움이 되고자 하는 것이 저희의 목표였습니다.B. 만연한 뉴스 기사들
인터넷 뉴스 매체가 과도하게 많아지면서, 진중하지 못한 저퀄리티 뉴스 기사들이 너무 많아지고 있는 현실입니다.
똑같은 내용을 제목만 자극적으로 바꾸거나, 중요성이 매우 떨어지는 기사거리를 중요한 뉴스인 것처럼 과대포장하여, 정작 중요한 기사들은 묻히고 있는 실상이 반복되고 있습니다.
따라서, 주요 포털 사이트에서의 뉴스 키워드 빈도수 크롤링을 통해 정말로 화제가 되고 있는 뉴스 키워드들을 도출해내는 것이 중요하다고 생각하게 되었습니다.C. 바쁜 현대 사회
요즈음은 모든 것이 빨라야 하는 바쁜 현대 사회입니다.
하루하루 바쁘게 살아가는 현대인들을 위해, 그 날의 주요 이슈와 주요 뉴스 키워드들을 한눈에 빠르게 정리하여 제공하는 것이 필수 요소가 되었습니다.
2. 전체 구조
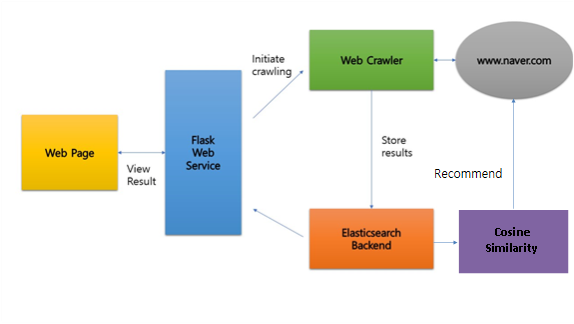
3. 기본 및 추가기능 설계
A. 실행환경 셋업 및 자동실행 쉘 스크립트
본 프로젝트는 Linux 환경에서 개발되었으며, 대표적으로 Python 언어와 git을 이용한 코드 version control을 시행하였습니다. Shell 파일로 6시간마다 자동으로 갱신되도록 하는 것을 목표로 하였습니다.
B. 외부 웹페이지 crawling 기능
news_naver.py : 검색 포털 사이트인 네이버의 뉴스 페이지에서 찾을 수 있는 단어들을 모두 크롤링 해오는 과정을 통해 이슈되고 있는 키워드들을 추출해내었습니다. 크롤링을 위해 BeautifulSoup 모듈을 사용하였고, konlpy 모듈을 통해 한국어 자연어 처리를 완료하였습니다. 또한 크롤링해온 단어들을 elasticsearch Backend에 JSON의 형식으로 저장하였습니다.
C. elasticsearch 기반 데이터 관리
news_naver.py, mapping_nori.json : elasticsearch 모듈을 이용하여 데이터베이스 내에 JSON을 저장하는 Insert 함수, 데이터베이스 내 데이터들을 제목으로 검색하는 Search 함수, 인덱스를 조회하는 check_index 함수, 인덱스를 새로 생성하는 create_index 함수, 인덱스를 삭제하는 delete_index 함수를 구현하였습니다.
D. Flask 기반 웹서비스 제공
app.py, naver.html, home.html, result.html : elasticsearch Backend 데이터들을 기반으로, 검색 결과를 Flask를 이용한 웹 페이지에 표시되도록 함으로써 사용자가 한눈에 중요한 뉴스 키워드들을 빈도수별로 볼 수 있게 하였습니다. 또한 사용자가 키워드 검색을 하였을 때 해당되는 뉴스 기사 및 링크가 연결되도록 설계하였습니다.
E. Cosine Similarity 유사도 분석 (추가 기능)
cosine_similarity.py : 사용자가 원하는 키워드를 검색한 후 도출된 기사 제목 링크들 중 하나의 뉴스 기사를 선택하면, Cosine Similarity 유사도 분석을 통해 그 기사내용과 다른 기사들의 본문들과 유사도를 비교해 가장 높은 10개의 추천 뉴스 기사로 도출하도록 하였습니다.
4. 결과
프로젝트 제출 직전에 프론트엔드 개발 담당 팀원의 연락이 두절됨에 따라 제출 당일 급하게 html 사용법을 찾아보며 웹 페이지 비슷한 느낌만 나게 만들었기 때문에 디자인적 요소는 형편없습니다.
news_naver.py을 통해 성공적으로 네이버 뉴스 메인 홈페이지에서 유의미한 단어들을 추출해와 빈도수를 셀 수 있었습니다.
아래의 이미지와 같이, 경제, 정치, IT 등으로 분야별로 뉴스 키워드를 크롤링했기 때문에 다양한 방면의 주요 이슈들을 알 수 있습니다.
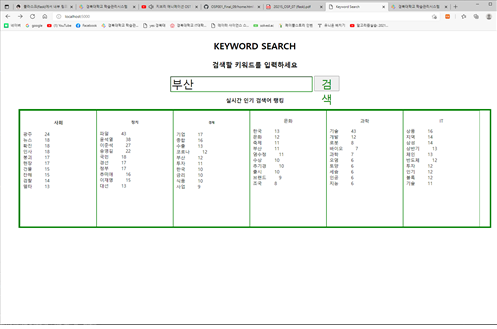
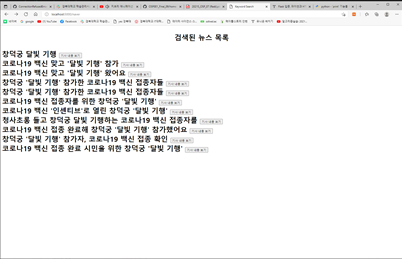
또한, 사용자가 원하는 키워드를 입력하면 추출된 뉴스 기사 중에서 검색을 도와주는 코드도 구현 완료하였습니다.
실행 결과는 아래와 같이 도출되었습니다.
5. 고찰
백엔드 개발을 진행하면서 생각보다 쉽지 않음을 느꼈습니다. 특히 크롤링 부분은 중간에 네이버 뉴스 제공 구성 방식이 바뀌어 한 번 코드 수정을 진행해야 했고, 데이터베이스 개발은 코드 오류들과 싸우는 시간이었습니다. 그래도 결과가 계획한 대로 나와서 다행이라 생각하고, 간단하다고 생각한 뉴스 제공과 실시간 키워드 순위 제공 기능이 생각보다 쉽지 않음을 느꼈습니다. 첫 개발이어서 그런지 조금 더 힘들었다고 생각하는데, 개발을 진행하며 공부를 다시 진행하고 의미있는 기능을 개발해 보니, 후에 이런 기능들을 개발하는 것이 조금 더 익숙해지면 그 때는 이번 프로젝트보다는 조금 더 쉽게 개발할 수 있을 것이라 생각합니다. 다만 프론트엔드 담당 팀원의 급작스런 연락 두절로 인해 웹 디자인을 급하게 하느라 보기 좋지 않은 점이 매우 아쉬웠으며, 이번 경험을 통해 팀원 간 지속적인 소통과 개발 상황 공유가 중요하다는 점을 느끼게 되었습니다.
프로젝트에 대한 코드는 https://github.com/17THgit/OS2021 를 참고해 주세요.
