개요
프로젝트 중 MVC로 되어있던 레거시 코드들을 클린아키텍처와 MVVM 디자인 패턴을 도입하여 리팩토링 했었던 것에 대해 나의 의도와 생각을 말해보고자 한다.(클린 아키텍처에 대해서는 다소 간략하게 소개를 하고 리팩토링 과정에 대해 포커싱을 둘 것이다.)
이번 편에서는 클린아키텍처로의 리팩토링에 대한 나의 생각을 적을 것이고 이후에 2편에서 MVVM에 대한 생각도 적어볼 예정이다.
클린아키텍처에 대하여. . .
안드로이드 진영에서 이제는 정석이 되었다고 해도 무방한 클린아키텍처에 대해 말해보고자 한다.
아키텍처란?
아키텍처는 소프트웨어의 구성 요소들의 유기적 관계를 표현하고 요구사항을 해결하려는 계획 과정등의 원칙을 말한다.
안드로이드의 정책이 바뀌고, 요구사항이 변경되어 지속적인 유지보수가 필요한 상황들이 반드시 오게 된다.
이때 애플리케이션은 당연하게도 점점 거대해지고 유지보수비가 늘어나는 것이 필연적이다.
아키텍처가 잘 설계된 애플리케이션이라면 유지보수 비용이 점차 줄어들 것이지만 그렇지 않은 애플리케이션이라면 급속도로 유지보수 비용이 늘어날 것이다.
클린아키텍처란?
추상적으로 말하자면 유연하게 변경하며 견고한 구조를 만들기 위한 소프트웨어 철학이자 원칙이다.
이 원칙에 대해 좀 더 구체적으로 말하자면 아래와 같다.
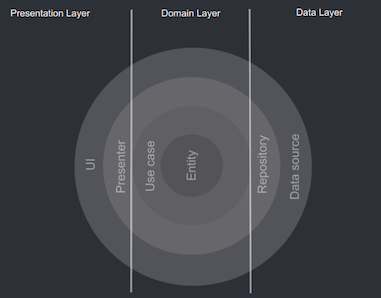
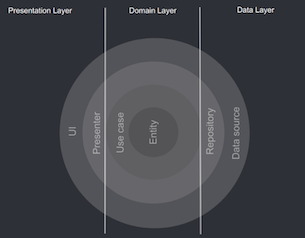
소프트웨어의 관심사를 계층별로 분리하여 코드 종속성이 외부로부터 내부로 의존하도록 한다. 즉 구성 요소를 계층적으로 분리하고 코드 변동성은 원 바깥으로 향할수록 크고 의존성은 원 바깥쪽에서 안쪽으로 향하도록 한다.
관심사 분리가 핵심이라고 생각한다.
엔티티
엔티티는 어떤 서비스를 제공해야 하는지에 대한 중요 로직을 포함한다. 즉 비즈니스 로직의 핵심 구성요소이다.
유즈케이스
유즈케이스는 사용자와 시스템 간 주요 활동을 기술하고 엔티티 간 데이터 흐름을 조정한다. 또한 비즈니스 로직을 캡슐화하는 역할을 한다.
도메인
도메인 지식은 서비스에 대한 전문적인 지식을 뜻한다. 즉, 도메인 레이어의 역할은 애플리케이션이 어떤 서비스를 제공해야 하는 지에 대한 핵심 비즈니스 로직을 포함하고 있는 계층이다.
리포지터리와 프레젠터
리포지터리는 데이터를 생성, 저장, 변경하는 방식을 결정하고 데이터 소스에서 생성한 모델을 엔티티로 변환하여 전달한다.
프레젠터는 뷰의 상태를 생성하는 역할을 한다.
데이터 소스와 유저 인터페이스
데이터 소스는 네트워크 통신 등을 통해 데이터를 생성, 저장, 변경하는 역할을 한다.
유저 인터페이스는 사용자와 상호작용 및 데이터를 화면에 표시한다.
리팩토링 시 지키고자 했던 클린 아키텍처의 레이어
클린 아키텍처 레이어
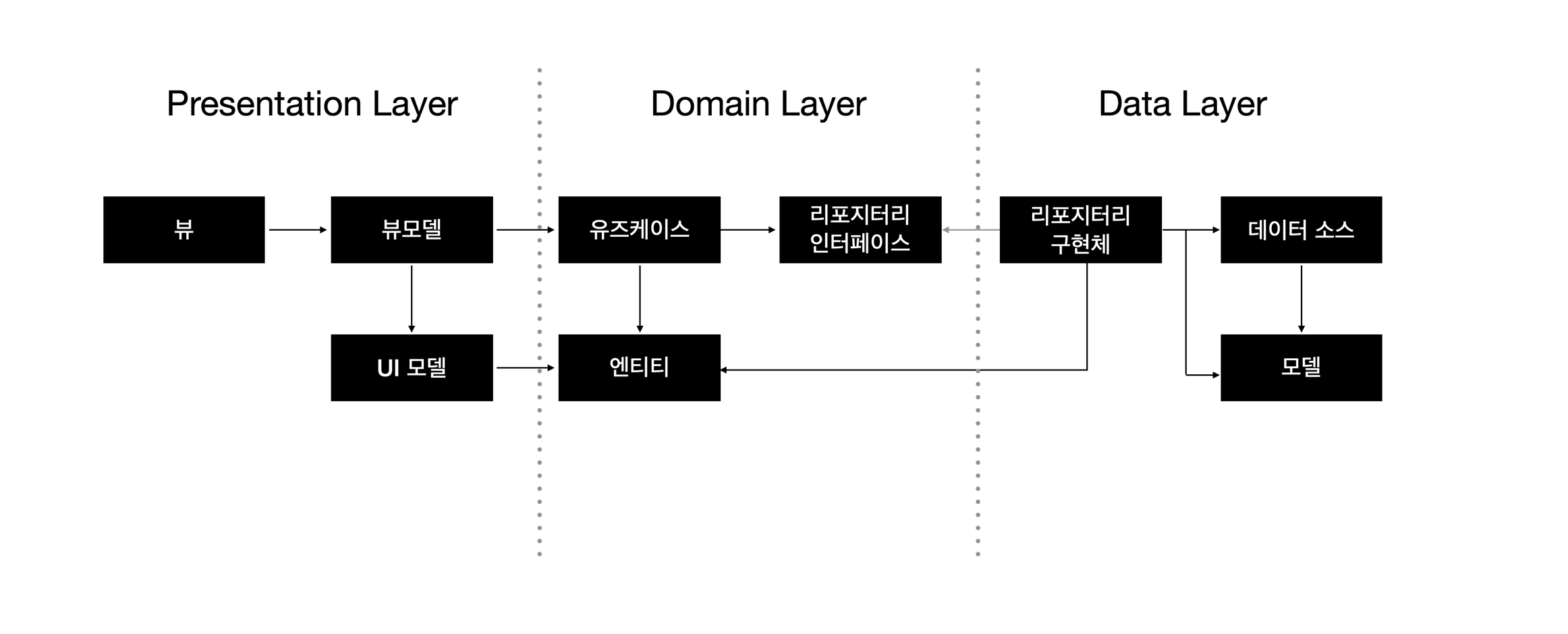
프레젠테이션 레이어
실제 데이터를 갖고 뷰상태를 생성하고 화면에 표시하는 역할을 한다.
플랫폼과 가장 의존성이 높은 UI 레벨의 레이어로서 MVP, MVVM 등과 같은 패턴을 사용할 수 있다.
Presentation Logic은 Domain Layer를 대상으로 의존성을 가지고 우리는 MVVM 패턴을 사용중이었기에 패턴도 그대로 적용하였다.
도메인 레이어
Domain Layer는 애플리케이션이 어떤 서비스를 갖고 있는 지를 담고 있고, 비즈니스 로직을 포함하고 있다. UseCase를 통해 넘겨줄 데이터를 담을 Model과 Presentation Layer와 Domain Layer를 이어줄 UseCase, 그리고 Data Layer의 데이터 소스를 통해 데이터를 가져올 Repository가 있다.
데이터 레이어
데이터를 생성, 저장, 변경하는 역할을 한다.
데이터 레이어에서의 모델은 오로지 데이터 전송을 위한 클래스이며 별도의 로직을 포함하지 않는다.
리포지터리가 필요한 이유
위의 전체 구조를 보면 Data Layer의 리포지터리 구현체와 Domain Layer에 리포지터리 인터페이스가 있을 것이다.
그렇다면 이 리포지터리는 왜 필요한 것일까?
리포지터리가 없는 상태를 보자.
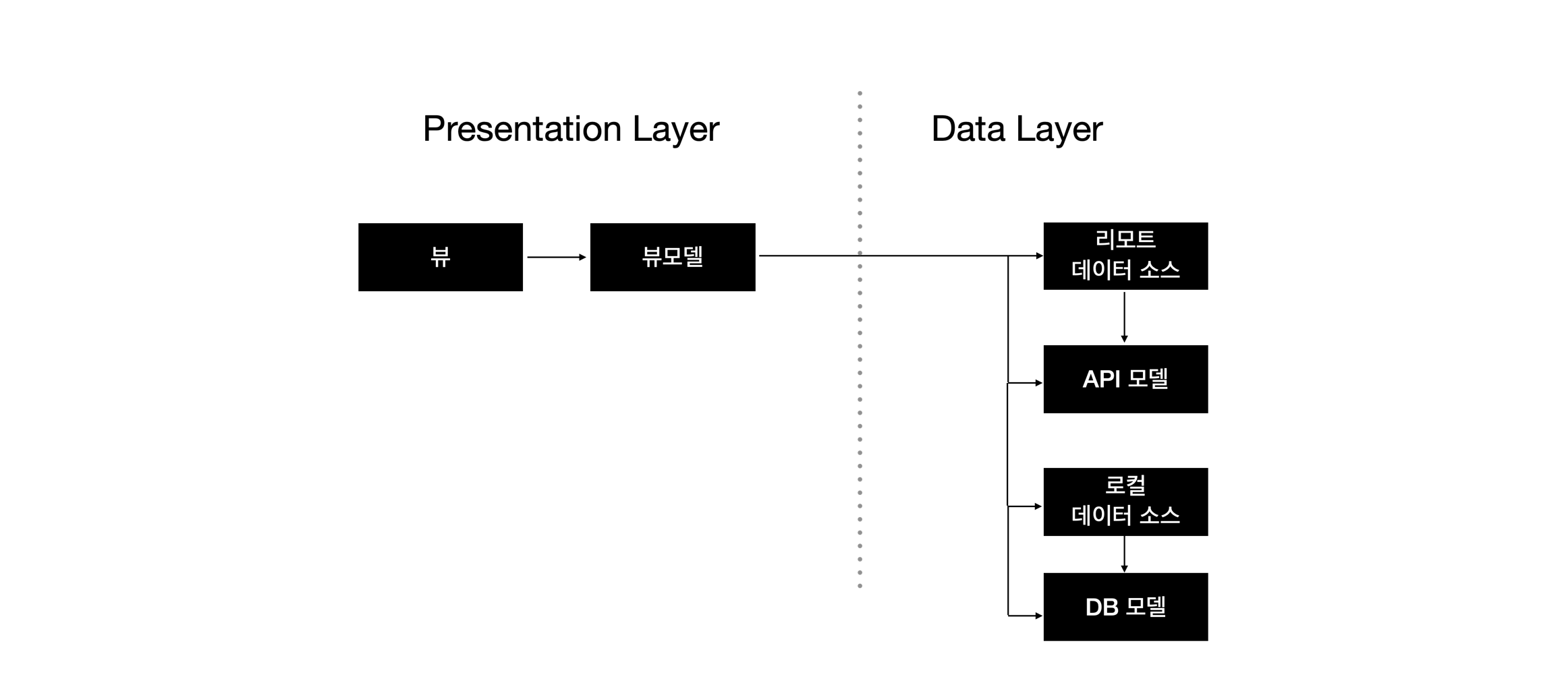
리포지터리가 없는 경우이므로 도메인 레이어는 잠시 생략해두고 생각해보자.
Presentation Layer의 뷰모델은 데이터 레이어에 의존성을 두고있다.
뷰모델에서 동일한 뷰 상태를 생성하더라도 모델의 타입이 다른 경우 별도의 로직을 추가해야 한다.
즉, 모델의 타입이 늘어날수록 뷰모델이 복잡해질 것이다. 이러한 문제를 해결하기 위해 데이터 레이어에 리포지터리를 추가해보자.
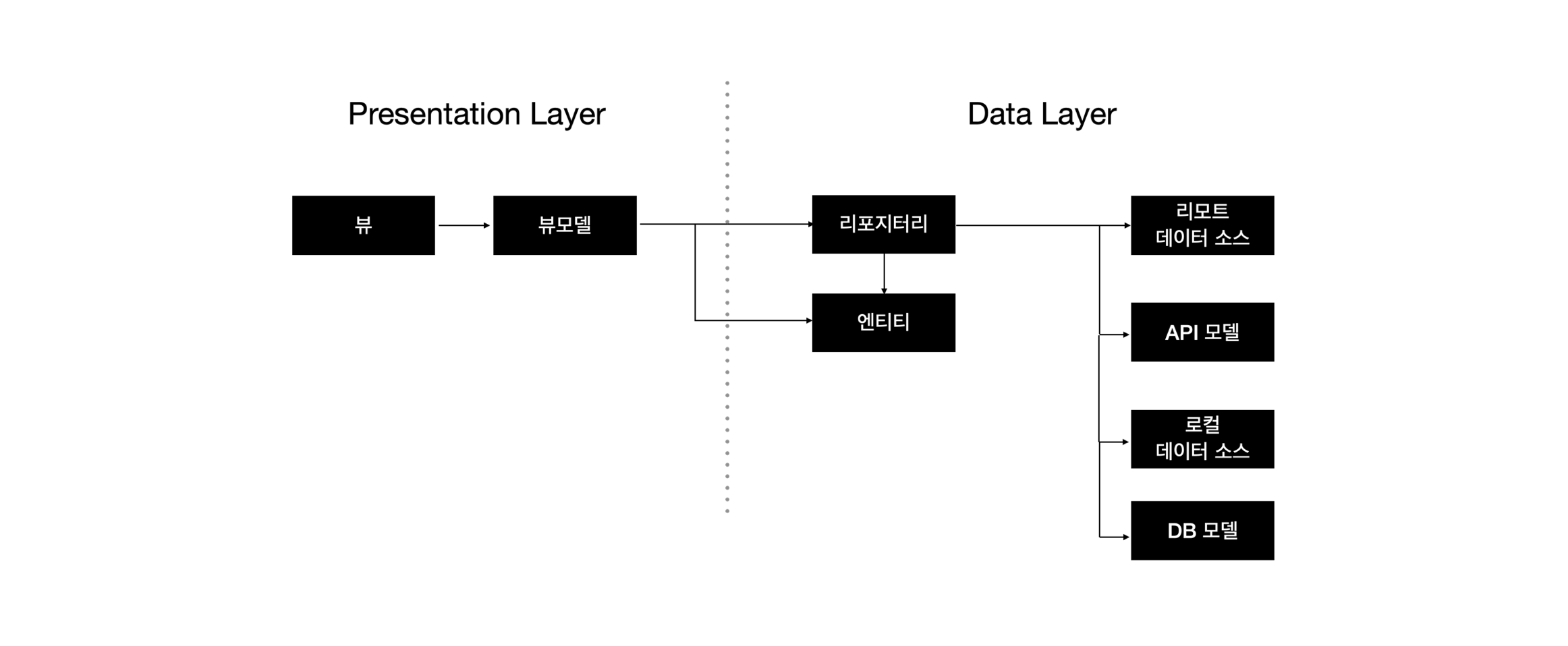
뷰모델에서 공통된 뷰 상태를 생성할 때 각 모델의 출처 및 타입을 알지 못하게 하기 위해 리포지터리를 추가하고 엔티티를 추가하였다.
리포지터리는 데이터 소스에서 생성한 모델을 갖고 통일된 데이터인 엔티티를 전달한다. 그래서 모델 타입이 늘어나더라도 뷰모델 로직은 변경되지 않는다.
그렇다면 리포지터리 인터페이스를 통한 의존성 역전이 필요한 이유?
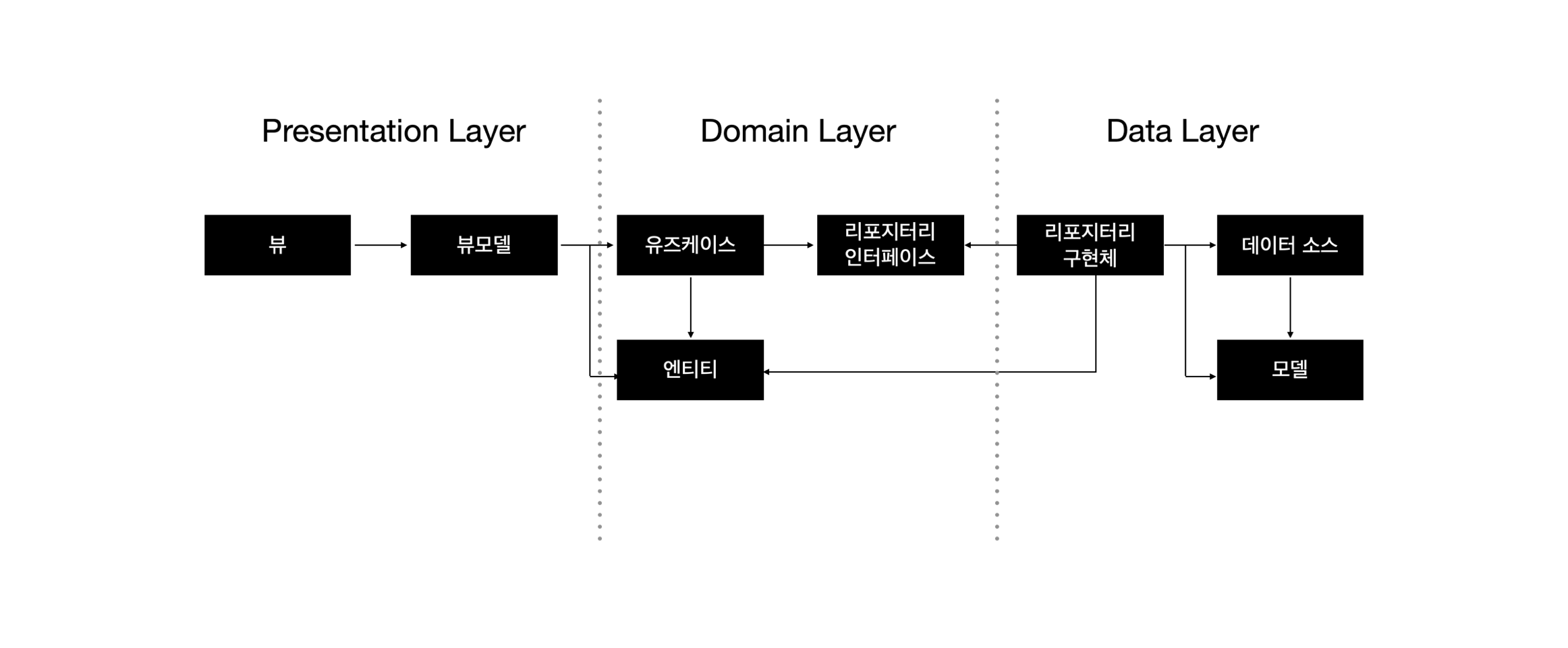
데이터는 Data Layer의 데이터 소스를 통해 Domain Layer로 흐르게 되어있다.
그래서 Domain Layer는 Data Layer를 참조해서 데이터를 조회해야 하기 때문에 Data Layer에 의존성을 갖는다.
이러한 구조는 클린아키텍처의 의존성 규칙에 위반된다.
문제가 뭐냐하면, Data Layer의 인프라가 변경이 되면 비즈니스 로직을 담당하는 Domain Layer가 변경이 된다.
Retrofit을 사용하다가 Volley로 변경했다고(혹은 로컬 DB로) 해서 비즈니스 로직이 변경이 된다는 것이다.
그저 동일한 역할을 하는 라이브러리로 교체를 한 것 뿐인데...
(의류 판매 업체의 비즈니스가 스파오에서 유니클로로 바뀐다고 해서 의류 판매가 아닌 음식 판매 업체가 되지 않는 것이 당연한 것처럼?)
클린아키텍처는의 원칙은 코드 종속성이 외부로부터 내부로 의존하여야 하는데, Domain Layer는 Data Layer보다 내부에 있기 때문에 이 문제를 해결하기 위해 리포지터리 인터페이스가 필요하다.
그래서 Domain Layer에 추상적인 리포지터리 인터페이스를 두고 Data Layer에 구체적인 리포지터리 인터페이스 구현체를 둠으로써 의존성 관계를 역전시킬 수 있다.
MVC라는 오래된 레거시 . . .
프로젝트 내에 코틀린, 클린아키텍처, MVVM으로 되어있는 부분들도 꽤 있었지만 자바와 MVC 패턴으로 된 부분도 상당했다. 이 상황을 보고 오히려 기뻤다. 주니어 개발자로서 레거시 코드를 리팩토링 할 수 있는 기회가 있다는 것은 내가 알고있는 지식을 직접 적용해볼 수 있는 좋은 경험과 동시에 트렌디한 기술, 아키텍처 등이 왜 나오게 되었고, 왜 인기가 많은 지에 대해 레거시와 비교하며 체감할 수 있기 때문이다.
굉장히 불편했던 단점
개선했던 코드 중 검색 결과 화면에 대한 일부분을 예시로 들겠다.
검색 결과 화면에서의 수많은 기능 중 검색 키워드를 입력하여 해당 키워드에 맞는 상품들을 보여주는 기능이 있다. 정리하면 아래와 같다.
- 검색 키워드 입력
- 검색 필터에 키워드 저장
- 검색 필터를 파라미터로 검색 API 호출
- 검색 결과 상품들 화면에 렌더링
우선 코드자체가 Activity/Fragment에 몰려있었으며 Controller 또한 많은 양의 코드가 몰려있었다. 또한 서로 굉장히 깊은 커플링이 있었고 이는 하나만 수정해도 연쇄적으로 수정해야 하는 어려움이 있었고 일단 파악하는데 코드 보기가 너무 불편했다..
또한, 커플링이 심했고 API 호출하는 부분이 Activity/Fragment와 Controller에 있었기 때문에 API 모델이 조금만 바뀌어도 수정할 부분이 굉장히 많았고 수정 또한 쉽지 않았다.
개선 과정
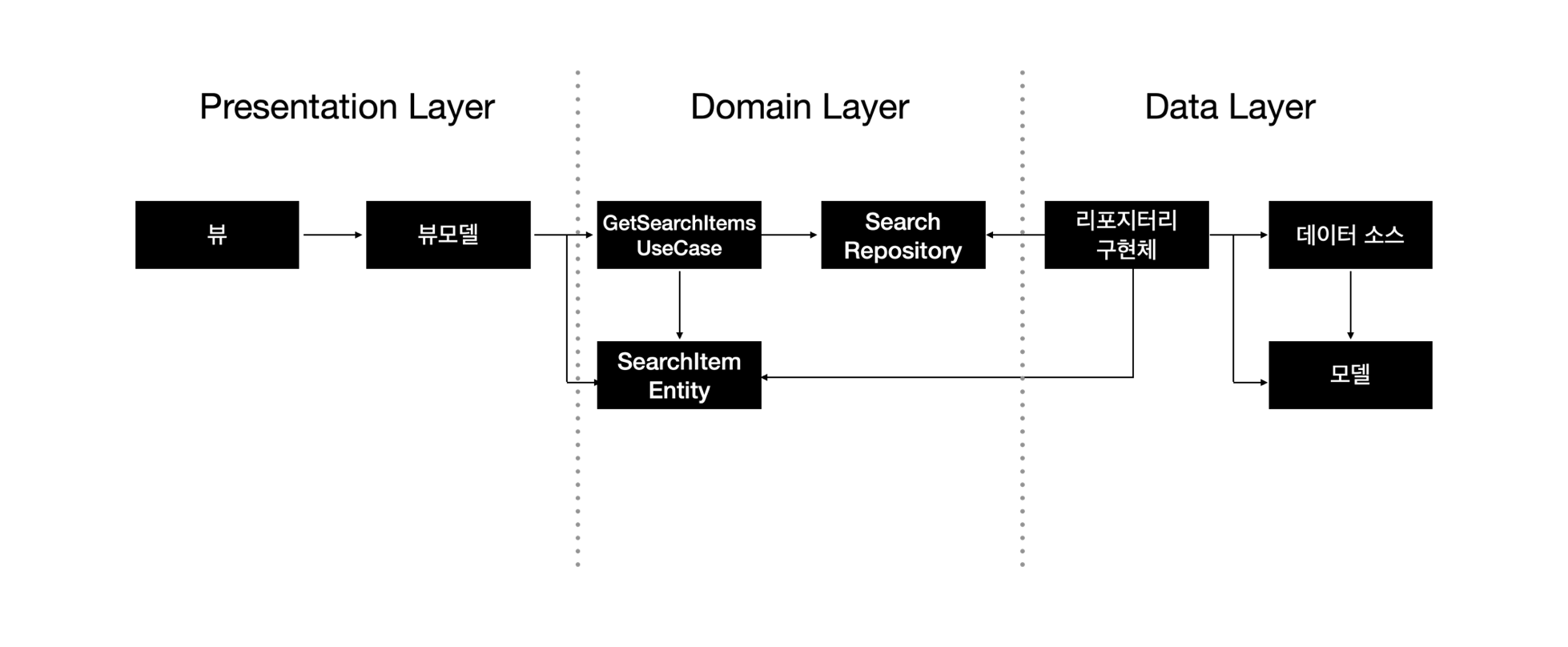
우선 어떤 서비스를 담고있는지(검색)를 나타내는 Domain Layer부터 작업을 했다.
검색 결과에 대한 정보들을 담고있는 SearchItemEntity, 이 데이터를 뷰상태로 만들기 위해 뷰모델에서 참조할 GetSearchItemsUseCase 그리고 검색 결과 API를 호출하기 위한, 의존성 역전 원칙을 적용한 Search Repository Interface를 만들었다.
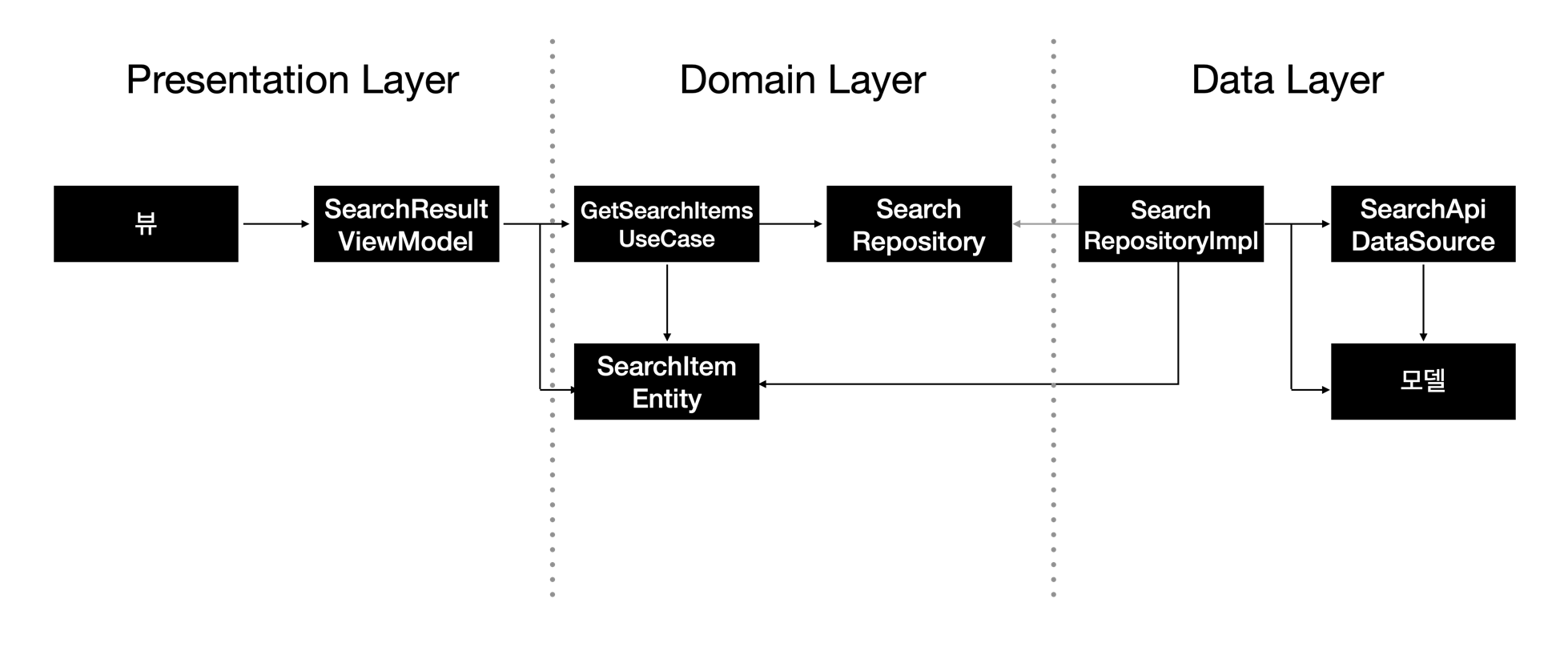
그 후 Data Layer에서 검색 API를 통해 데이터를 가져올 모델과 SearchApiDataSource 작업을 진행했고, 이를 SearchRepository의 구현체인 SearchRepositoryImpl 작업을 했다.
그 후 Presentation Layer에서는 SearchResultViewModel을 생성하여 UseCase를 통해 데이터를 전달 받아 뷰 상태를 관리하였다.
UI Model 도입
리팩토링을 진행하며 UI Model을 도입하였다. 기존의 클린아키텍처가 적용되어있는 부분들은 Presentation Layer에서 별다른 모델을 두지 않고 Domain Layer의 Entity를 사용 중이었다.
얼핏보면 Data Layer에서 변경이 되어도 뷰모델에서 수정사항이 생기지 않도록 하기 위해 Domain Layer의 리포지터리와 Entity가 존재하는 것이므로 그대로 Presentation Layer에서 사용해도 되는 것 아닌가? 라는 생각이 들 수도 있다.
하지만 여기에는 문제가 있다.
Entity와 UI Layer와의 커플링
내 생각에 UI Model이 필요한 이유는 기본적으로 클린아키텍처의 주요 원칙인 관심사 분리에 어긋나지 않기 위함이다.
UI Layer에서 Entity를 직접 사용하면 UI와 비즈니스 로직을 담당하는 Domain Layer와의 아주 강한 커플링이 생기게 된다.
이는 관심사 분리를 위배한다는 것이 되고, 아래에서 좀 더 설명을 하겠다.
우리는 다양한 상호작용이 있는 앱을 제공하고 있고,
코드 변동성은 원 바깥으로 향할수록 커야 한다.
다채로운 UX가 많이 개발 되면서 요구사항 또한 많아졌고 강조 표시를 할 상품과 그렇지 않은 상품, 이벤트 전달 방식 등 여러 형태로 개발자들이 개발/유지보수에 대해 고려해야 할 부분이 많아졌다.
우리는 다양한 상호작용이 있는 앱을 제공하고 있고, 코드 변동성은 원 바깥으로 향할수록 커야 한다.
다채로운 UX가 많이 개발 되면서 요구사항 또한 많아졌고 강조 표시를 할 상품과 그렇지 않은 상품, 이벤트 전달 방식 등 여러 형태로 개발자들이 개발/유지보수에 대해 고려해야 할 부분이 많아졌다.
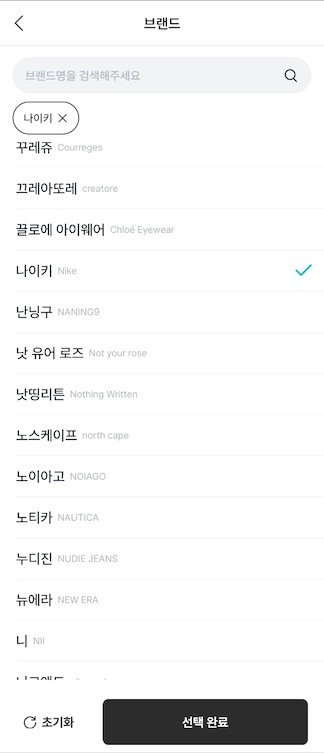
위의 화면은 상품 검색 시 브랜드 필터 화면이다.
브랜드 리스트 중 사용자가 선택한 브랜드들이 무엇인지 판단 후 해당 브랜드들의 Idx를 검색 필터에 넣어줘야 한다.
선택 여부를 판단하기 위해 브랜드 Model에는 isSelected 와 같은 Boolean 타입이 새롭게 필요하다.
이 때 Domain Layer의 Entity를 Presentation Layer에서 사용한다면 UI 상태 변화를 위해 Entity가 수정되어야 한다.
즉, 원 안쪽에 있는 Domain Layer가 변경이 잦은 원 바깥쪽의 Presentation Layer에 의존하게 된다.
그러므로 클린아키텍처의 원칙을 위반하게 된다.
또한, 이와 함께 오는 문제가 Domain Layer는 우리의 서비스에 대한 정보 등을 담고 있다. 그래서 한 화면 혹은 기능에서만 의존하고 있는 것이 아니라 여러 군데에서 의존하고 있을 가능성이 크다.
결국 위에서 언급했던 내용이기는 하지만 브랜드 필터를 위해 다른 브랜드 관련 기능에서 필요없는 프로퍼티 등이 추가되어 불필요한 작업이 수행될 수 있다는 점이다.
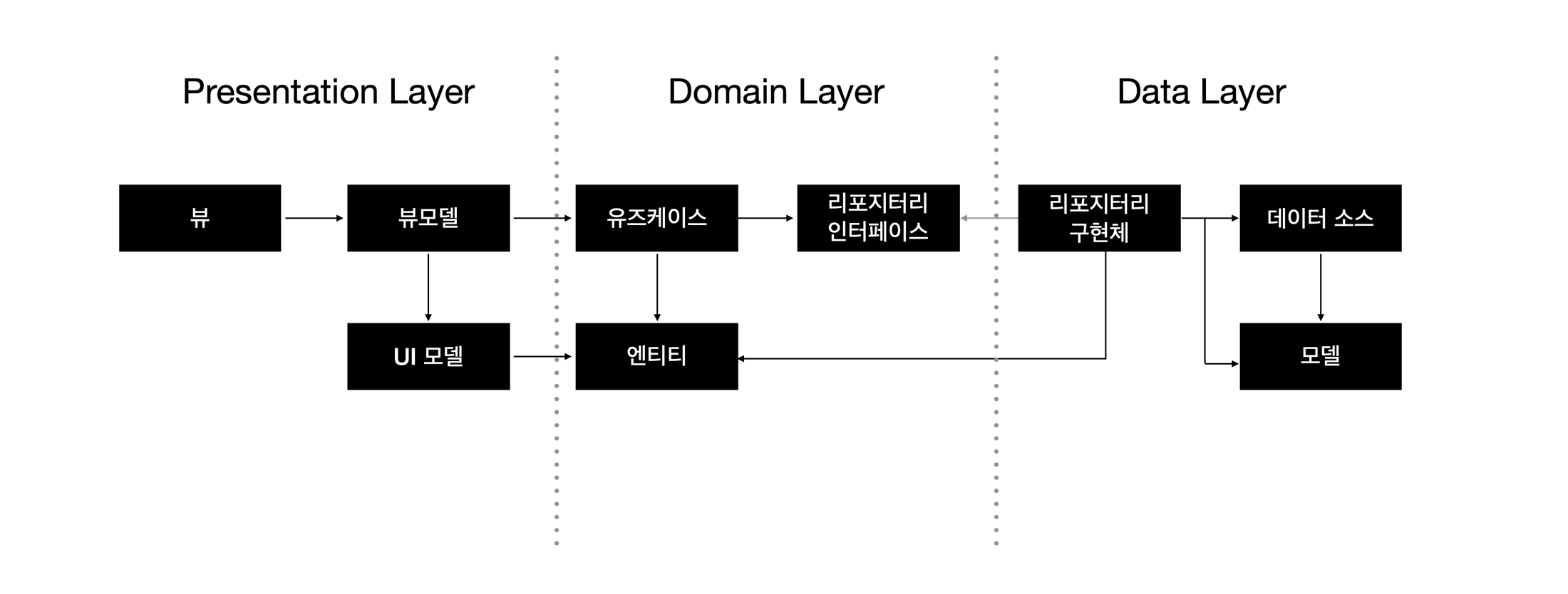
Entity -> UI Model변환
UI Model을 생성하고 Mapper를 이용하여 Entity를 변환하면 된다.
data class ItemBrandDataUiModel(
var brandIdx: String = "",
var korean: String = "",
var english: String = "",
val count: Int = 0,
var isSelected: Boolean = false
) : Parcelable
/**
* Mapper
* [ItemBrandDataEntity] to [ItemBrandDataUiModel]
*/
fun ItemBrandDataEntity.toUiModel(): ItemBrandDataUiModel {
return ItemBrandDataUiModel(
brandIdx = this.brandIdx.orEmpty(),
korean = this.korean.orEmpty(),
english = this.english.orEmpty(),
isHighlighting = false.orFalse(),
)
}Mapping에 대한 수행은 ViewModel에서 하면 된다.
ViewModel의 역할은 리포지터리에서 데이터를 가져와 뷰 상태를 생성하는 것이므로 데이터를 사용하는 과정에서 Mapping하여 뷰 상태를 만들어내는 것이라고 생각하면 된다.
/**
* 상품 브랜드 목록 가져오기
*/
fun getBrands(query: String?) {
if (query.isNullOrEmpty()) {
refreshItem()
}
getItemBrandUseCase(ItemBrandRequest(q = query), PageRequest())
.map { pagingData -> pagingData.map { it.toUiModel() } }
.onEach { _brands.value = it }
.launchIn(viewModelScope)
}고민했던 부분들
Domain Layer에서의 로그
Domain Layer는 제일 안쪽에 있는 계층이므로 바깥쪽에 있는 계층에 의존적이지 말아야 한다. 즉, 안드로이드 플랫폼에도 종속되지 말아야 하며 순수 자바/코틀린만이 존재해야 한다는 것이 나의 생각이다.
하지만 로그를 남기기 위해서 안드로이드 플랫폼에 의존적인 android.util.Log가 사용되었다.
이를 해결하기 위해서는 Logger를 추상화 시키고 Log Module이나 Util, Common Module 등을 따로 두고 거기에서 구현을 하면 될 것이다.
그럼에도 불구하고 고민이 되었던 점은 '위치'였다. 현재 우리 프로젝트는 Presentation, Domain, Data, Common, Design으로 총 5개 모듈로 나뉘어져 있었다.
Logger Module을 만들거나 Common Module에 넣으면 될 것 아닌가? 라고 생각 할 수도 있겠지만 이것도 나름의 사정이 있었다.
우리의 개발문화는 굉장히 개방적이고 변화에 자연스러운 조직 문화였지만 함께 작업하는 프로젝트이니만큼 최소한의 논의는 필요했다.
하지만 우리는 시간이 촉박했고 이것 말고도 의논해야 할 것, 각자 할 일, 스프린트 등이 기다리고 있었다.
android.util.Log는 안드로이드 플랫폼에 의존적이기는 하지만 변동가능성이 적어 의존을 한다고 해도 Domain Layer에 미치는 영향이 아주 적을 것이라고 생각이 들었기에 우선순위에서 밀려난 후 아직 내 고민 리스트에 추가만 되어있는 상태이다.
UI Model로 인한 보일러 플레이트 코드 증가
UI Model을 도입하면서 Entity -> UI Model에 대한 Mapper 코드의 보일러 플레이트 코드가 많아졌다.
Data Layer -> Domain Layer에서의 Mapper는 Entity 자체를 공통으로 사용하는 경우가 많고 한 번 작성해 놓으면 API가 변경되지 않는 이상 수정할 일이 크게 없기 때문에 괜찮았지만 UI Model 같은 경우 여러 화면에서 다양한 형태로 사용되기 때문에 중복 코드가 많아졌다.
이는 코드를 작성할 때의 피곤함과 더불어 코드 생산성에도 귀결되는 내용이다.
물론 해결책은 있었다. 어노테이션을 사용하여 Mapping을 쉽게 도와주는 라이브러리도 있었고, 확장함수를 만들어 사용하는 방법도 있었다.
하지만 이를 채택하지 않고 고민을 했던 이유는 '성능' 때문이다. 라이브러리 내부를 뜯어봐도 그렇고, 확장함수를 사용하는 방법 또한 리플렉션을 사용해야 했기 때문이다.
(리플렉션을 사용할 경우 런타임에 많은 연산을 요구하고 또한 컴파일러의 최적화가 제한될 수 있기 때문)
성능 체크를 직접 해보고 비교하여 트레이드 오프(trade-off)를 감안하고 팀원들과 함께 결정할 수도 있었겠지만 이것 또한.. 시간이 문제였다. 그래서 우선순위에서 밀려나 아직 내 고민 리스트에 남아있다.
하지만 명확한 것은 이러한 고민 때문에 UI Model을 도입하지 않는 것은 다소 이해가 가지 않는 입장이었기에 UI Model은 도입하였다.
다소 힘들었던 점 , , ,
기존 코드를 리팩토링 하기로 마음 먹고 코드를 살펴보자마자 기존 코드는 모두 제거하고 새롭게 만들어야 겠다는 생각을 했다.
일단 우리는 멀티모듈(Presentation, Domain, Data, Common, Design)의 형태로 클린아키텍처를 적용중이었는데, 커플링이 너무 심하여 기존 코드에서 일부분씩 떼어내서 작업을 하는 것은 거의 불가능했고, 가능해도 시간이 몇배는 더 걸릴 것 같았기 때문이다.
하지만 새로 뜯어내는 것도 쉽지 않았다. 검색 결과 화면에는 굉장히 많은 코드들이 있었고 MVC 형태로 되어있었기에 기존 동작들에 대한 명세를 파악하기 힘들었다.
리팩토링을 했을 때 가장 중요한 점은 기존과 기능이 동일해야 하는 것이기에 파악이 중요했는데.. 모델, 뷰, 컨트롤러가 하는 역할이 분리되어있기는 했지만 그 경계가 모호한 것들도 많았고, 역할들이 몰려있어서 파악이 더 힘들었다.
뷰와 상호작용하는 코드들과 호출하는 API 그리고 트래킹 등을 문서에 정리했고, 안드로이드 프로젝트 두 개를 켜놓은 후 한 개는 레거시 코드를, 한 개는 리팩토링 할 프로젝트를 화면에 띄워놓고 한 부분씩 위의 클린아키텍처를 적용해 나갔다.
