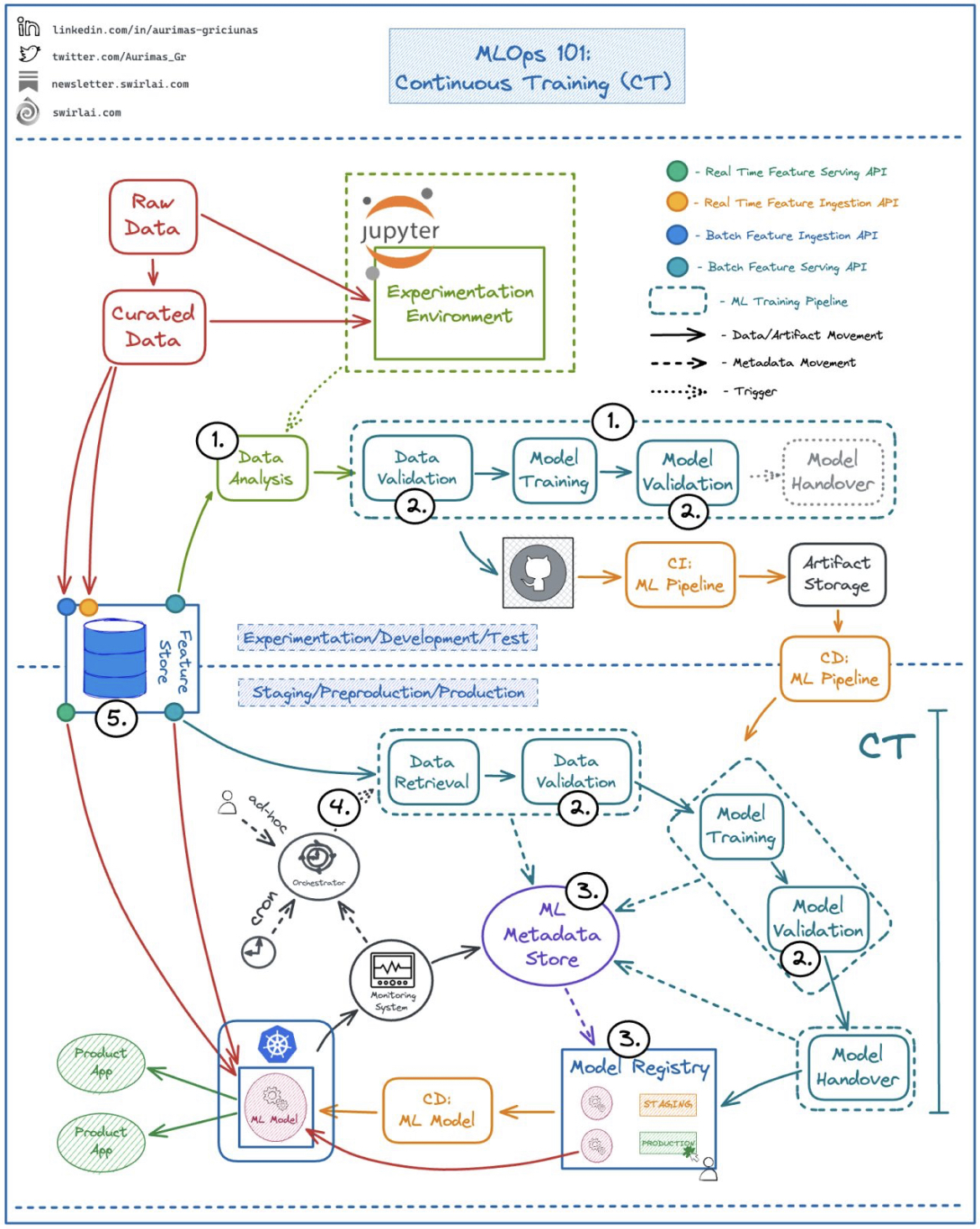
What is 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 (𝗖𝗧) in MLOps and what steps are needed to achieve it?
CT is the process of automated ML Model retraining in Production Environments on a specific trigger. Let’s look into some prerequisites for this:
1️⃣ Automation of ML Pipelines.
👉 Pipelines are orchestrated.
👉 Each pipeline step is developed independently and is able to run on different technology stacks.
👉 Pipelines are treated as a code artifact.
✅ You deploy Pipelines instead of Model Artifacts allowing Continuous Training In production.
✅ Reuse of components allows for rapid experimentation.
2️⃣ Introduction of strict Data and Model Validation steps in the ML Pipeline.
👉 Data is validated before training the Model. If inconsistencies are found - Pipeline is aborted.
👉 Model is validated after training. Only after it passes the validation is it handed over for deployment.
✅ Short circuits of the Pipeline allow for safe CT in production.
3️⃣ Introduction of ML Metadata Store.
👉 Any Metadata related to ML artifact creation is tracked here.
👉 We also track performance of the ML Model.
✅ Experiments become reproducible and comparable between each other.
✅ Model Registry acts as glue between training and deployment pipelines.
4️⃣ Different Pipeline triggers in production.
👉 Ad-hoc.
👉 Cron.
👉 Reactive to Metrics produced in Model Monitoring System.
👉 Arrival of New Data.
✅ This is where the Continuous Training is actually triggered.
5️⃣ Introduction of Feature Store (Optional).
👉 Avoid work duplication when defining features.
👉 Reduce risk of Training/Serving Skew.
𝗠𝘆 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀 𝗼𝗻 𝗖𝗧:
➡️ Introduction of CT is not straightforward and you should approach it iteratively. The following could be good Quarterly Goals to set:
👉 Experiment Tracking is extremely important at any level of ML Maturity and the least invasive in the process of ML Model training - I would start with ML Metadata Store introduction.
👉 Orchestration of ML Pipelines is always a good idea, there are many tools supporting this (Airflow, Kubeflow, VertexAI etc.). If you are not doing it yet - grab this next, also make the validation steps part of this goal.
👉 The need for Feature Store will wary on the types of Models you are deploying. I would prioritize it if you have Models that perform Online predictions as it will help with avoiding Training/Serving Skew.
👉 Don’t rush with Automated retraining. Ad-hoc and on-schedule will bring you a long way.
Let me know your thoughts! 👇
Follow Aurimas Griciūnas to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 👍, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://lnkd.in/e5d3GuJe
출처 : Aurimas, Machine Learning Community
