Problem
lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones.
Solution
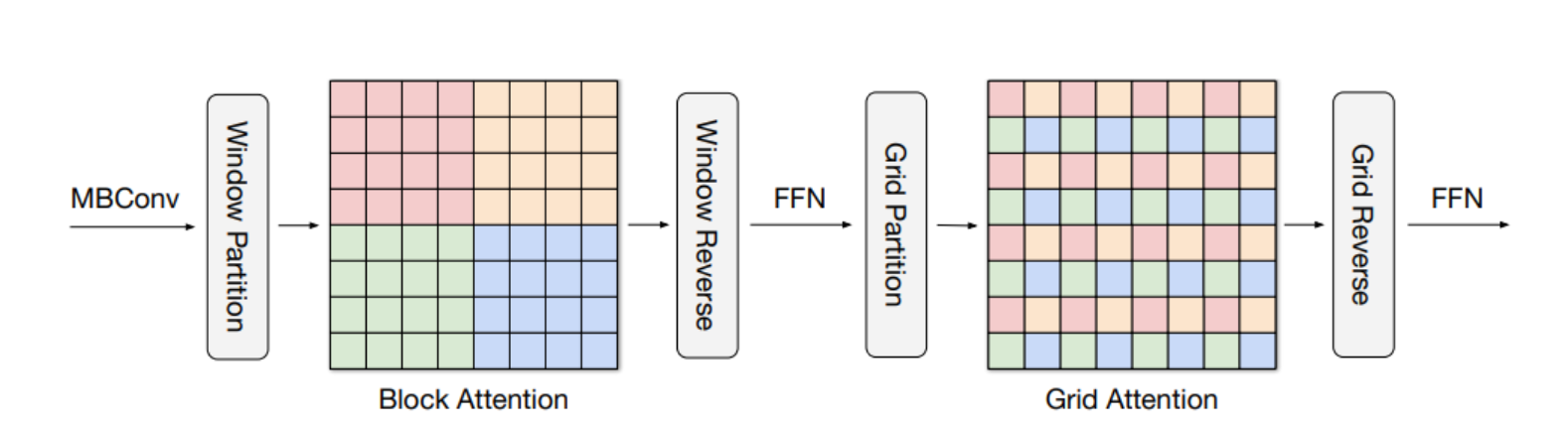
multi-axis attention, which allows global-local spatial interactions on arbitrary input resolutions with only linear complexity
-> Ensenble (Backbone : dubbed MaxViT, by repeating the basic building block over multiple stages.)
Performance : image classification, object detection, and visual aesthetic assessment.
Contribution
MaxViT, can achieve state-of-the-art performance on a variety of vision tasks, and more importantly, scale extremely well to massive scale data sizes.
State-of-the-art performancea
MaxViT model on the AVA benchmark [61]. This
dataset consists of 255K images rated by armature photographers through pho-tography contest
how well?

Psuedo code

