논문 제목: Similarity of Neural Network Representations Revisited
📕 Summary
Abstract
이 백서에서는 표준 상관 분석(CCA)을 사용하여 신경망 표현을 비교하는 방법을 살펴보고, 서로 다른 초기화에서 학습된 네트워크의 표현 간의 대응을 안정적으로 식별할 수 있는 중심 커널 정렬(CKA)이라는 유사성 지수를 소개합니다.
CKA는 표현 유사도 행렬 간의 관계를 측정하는 유사도 인덱스로, CCA와 밀접하게 연결되어 있습니다. CCA와 달리 CKA는 데이터 포인트 수보다 더 높은 차원의 표현을 비교할 때 제한을 받지 않습니다.
Introduction

이 논문은 심층 신경망 표현 간의 유사성을 측정하는 문제를 다루며 데이터에서 학습된 이러한 표현을 이해하고 특성화하는 것이 중요하다는 점을 강조합니다.
이전 연구에서는 신경망 훈련 과정의 이론적 역학을 탐구했지만, 훈련 역학과 구조화된 데이터 간의 복잡한 상호 작용을 충분히 고려하지 않았습니다.
이 논문은 표현 유사성을 측정하는 효과적인 방법을 제공하는 것을 목표로 하며, 이를 통해 아키텍처는 같지만 초기화가 다른 네트워크가 유사한 표현을 학습하는지, 서로 다른 네트워크 아키텍처의 레이어 간에 대응 관계를 설정하는지, 동일한 네트워크 아키텍처를 사용하여 서로 다른 데이터 세트에서 학습한 표현의 유사성을 평가하는 등의 질문에 답하는 데 도움이 될 수 있습니다.
저자들은 표현 유사성 분석을 사용하여 뇌 영역, 개인, 종, 행동, 뇌와 신경망 간의 표현을 비교하는 신경과학 연구에서 영감을 얻었습니다.
📕 Solution
Algorithm
📕 Conclusion
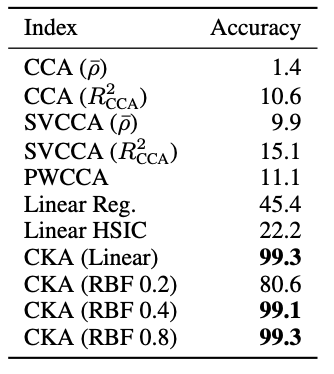
이 논문에서는 서로 다른 초기화에서 학습된 네트워크에서 표현 간의 대응을 안정적으로 식별할 수 있는 중심 커널 정렬(CKA)이라는 유사성 지수를 제안합니다. CKA는 신경망의 숨겨진 레이어에서 표현 간의 유사성에 대한 직관적인 개념을 포착하는 데 있어 다른 방법보다 뛰어난 성능을 발휘합니다.
CKA는 표준 상관관계 분석(CCA)과 밀접하게 연관되어 있지만 데이터 포인트 수보다 더 높은 차원의 표현을 비교할 때 제한이 없습니다. 표현 간의 의미 있는 유사성을 측정할 수 있으며 표현 유사성을 측정하는 측면에서 CCA와 동등합니다.
CKA는 서로 다른 초기화에서 학습된 동일한 네트워크 내에서의 표현뿐만 아니라 완전히 다른 아키텍처 전반의 표현을 비교하는 데 효과적입니다. 이는 레이어 간의 대응을 일관되게 식별하여 유사도 인덱스의 공간을 이해하기 위한 통합 프레임워크를 제공합니다.
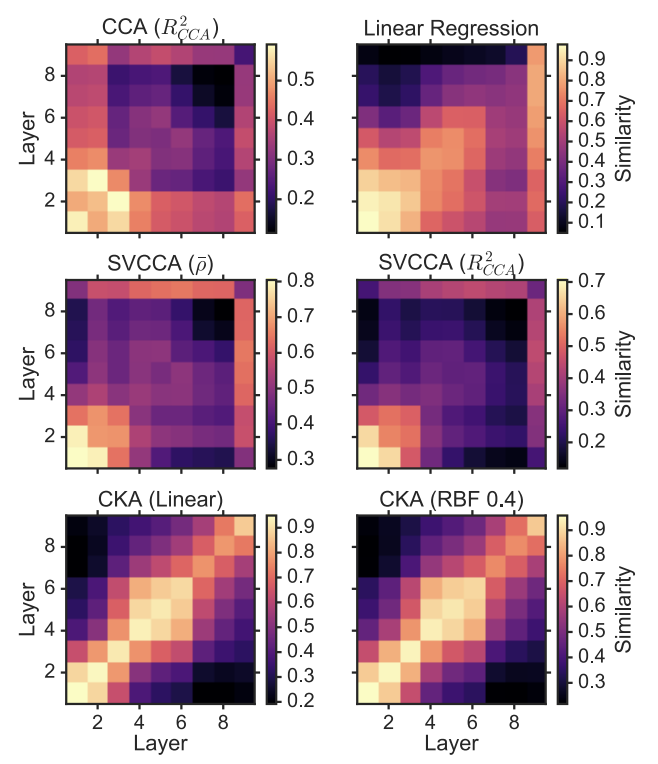
이 논문은 CKA에서 커널 선택과 가중치 부여에 관한 미해결 문제가 여전히 존재한다는 점을 인정하며 향후 연구 과제로 남겨두고 있습니다. 그러나 CKA는 신경망에서 학습된 표현 간의 대응을 찾는 데 있어 이전 방법보다 훨씬 더 나은 것으로 보입니다.
Contribution
이 논문에서는 신경망 표현을 비교하기 위한 유사성 지표로 중심 커널 정렬(CKA)을 소개하며, 이 지표는 서로 다른 초기화에서 학습된 네트워크의 표현 간의 대응을 안정적으로 식별할 수 있습니다.
CKA는 더 높은 차원의 표현 간의 의미 있는 유사성을 포착하는 데 있어 표준 상관관계 분석(CCA)과 같은 다른 방법보다 성능이 뛰어난 것으로 나타났습니다. 표현 유사도 행렬 간의 관계를 측정할 수 있으며 고차원 표현을 비교할 때 제한을 받지 않습니다.
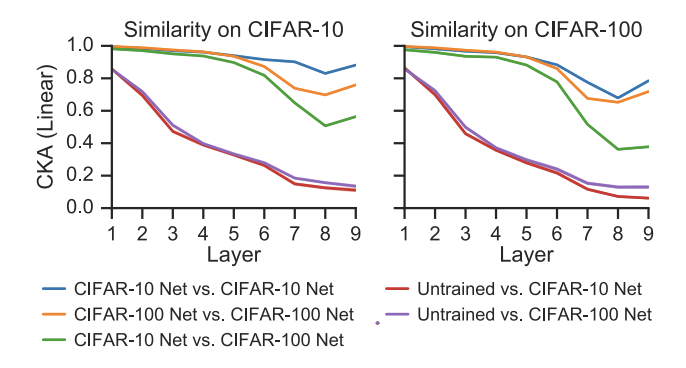
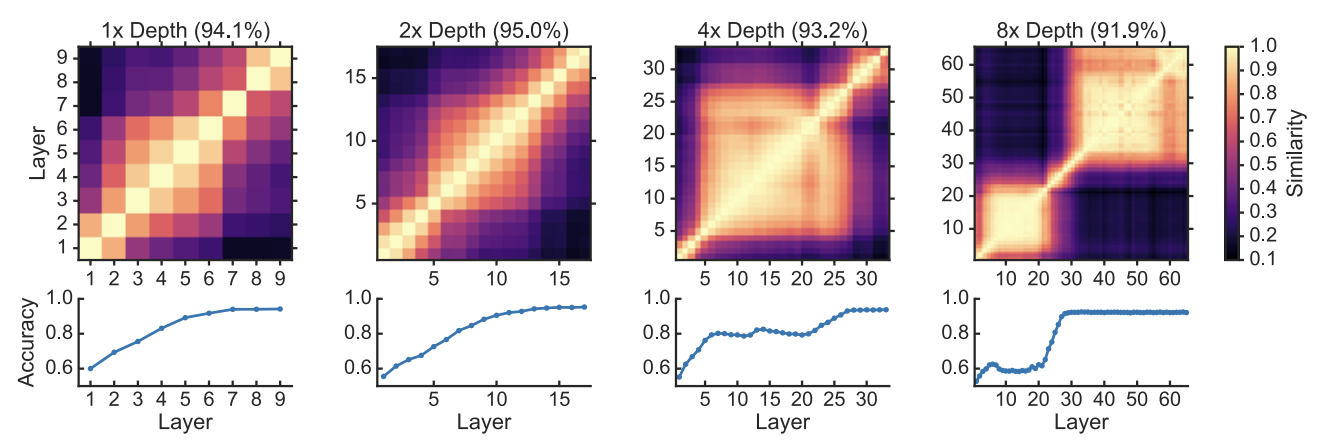
<Figure3. CKA는 깊이가 병적으로 변하는 시점을 알려줍니다>
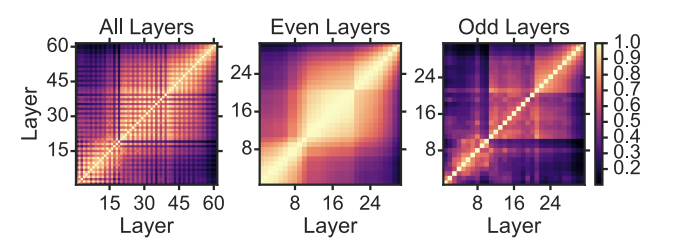
<Figure4. 짝수, 홀수 레이어 비교>
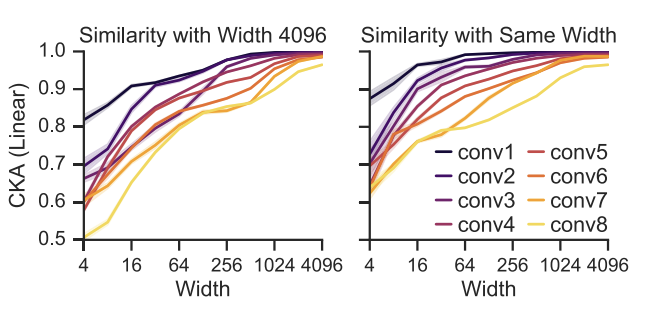
이 논문은 CKA가 서로 다른 무작위 초기화와 서로 다른 폭으로 훈련된 신경망의 숨겨진 레이어 간의 대응을 결정할 수 있음을 보여줍니다(이전에 제안된 유사성 지수가 실패하는 시나리오).
8
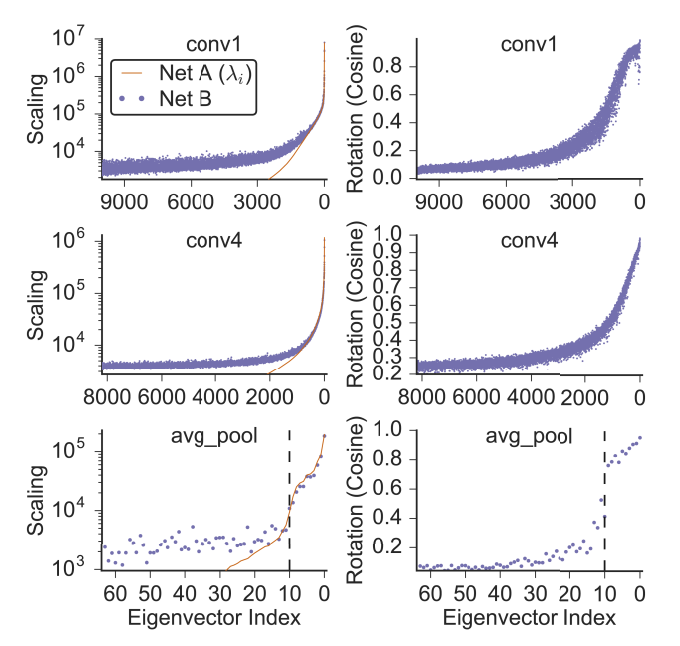
저자들은 더 넓은 네트워크가 더 유사한 표현을 학습하고 초기 레이어의 유사성이 이후 레이어보다 더 적은 채널에서 포화된다는 것을 확인했습니다. 또한 초기 계층이 후기 계층과 달리 서로 다른 데이터 세트에서 유사한 표현을 학습한다는 사실도 입증했습니다.
