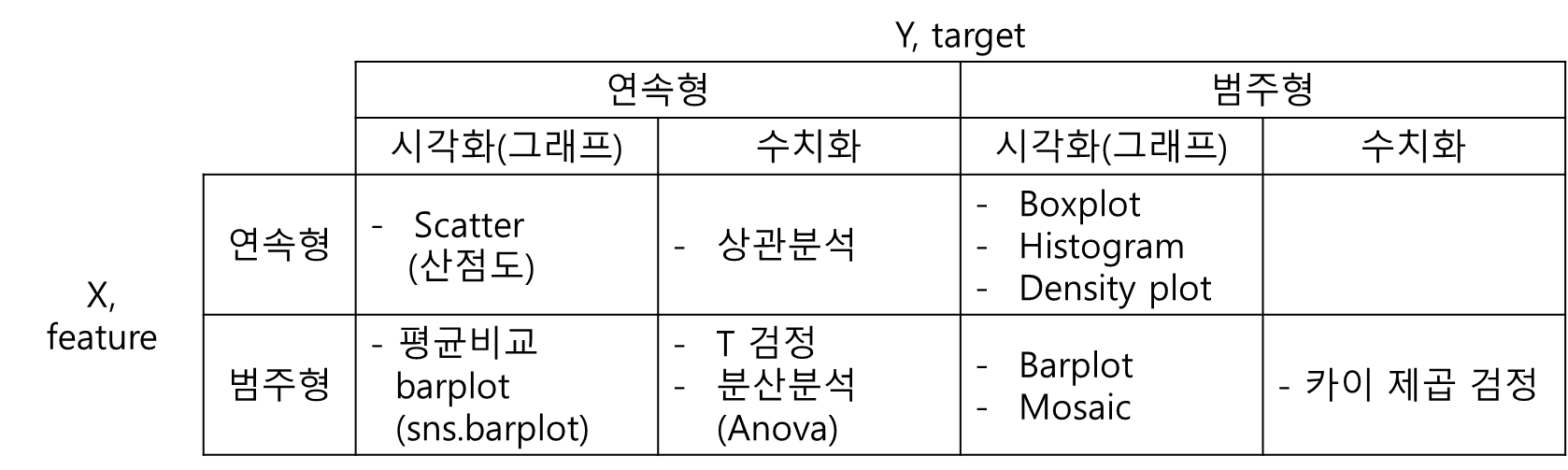
1. 사용 가능 도구
- 산점도(Scatter)
- 값을 그대로 점을 찍어 표현
- 공분산(covariance), 상관계수(correlation efficient)
- 각 점들이 직선 상에 얼마나 모여있는 계산
2. 시각화 : 산점도
- tip 데이터
- total_bill : 식사 총 금액
- tip : tip으로 낸 금액
- sex : 성별
- smoker : 흡연자 유무
- day : 식사 날짜
- time : 식사 시간대
- size : 한팀 수
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
tip = pd.read_csv('tips.csv')
sns.scatterplot(x='total_bill', y='tip', data = tip)
# sns에서 x y 명확하게 표시
plt.show()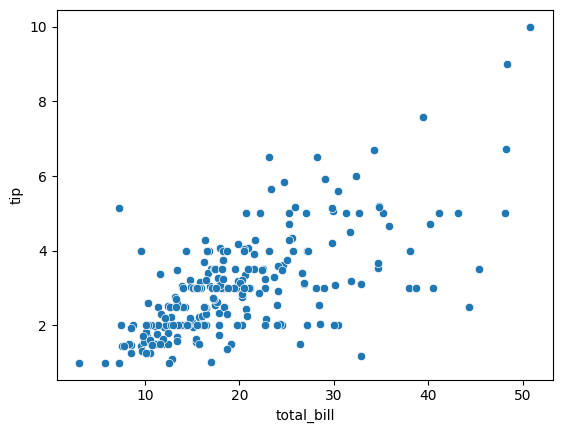
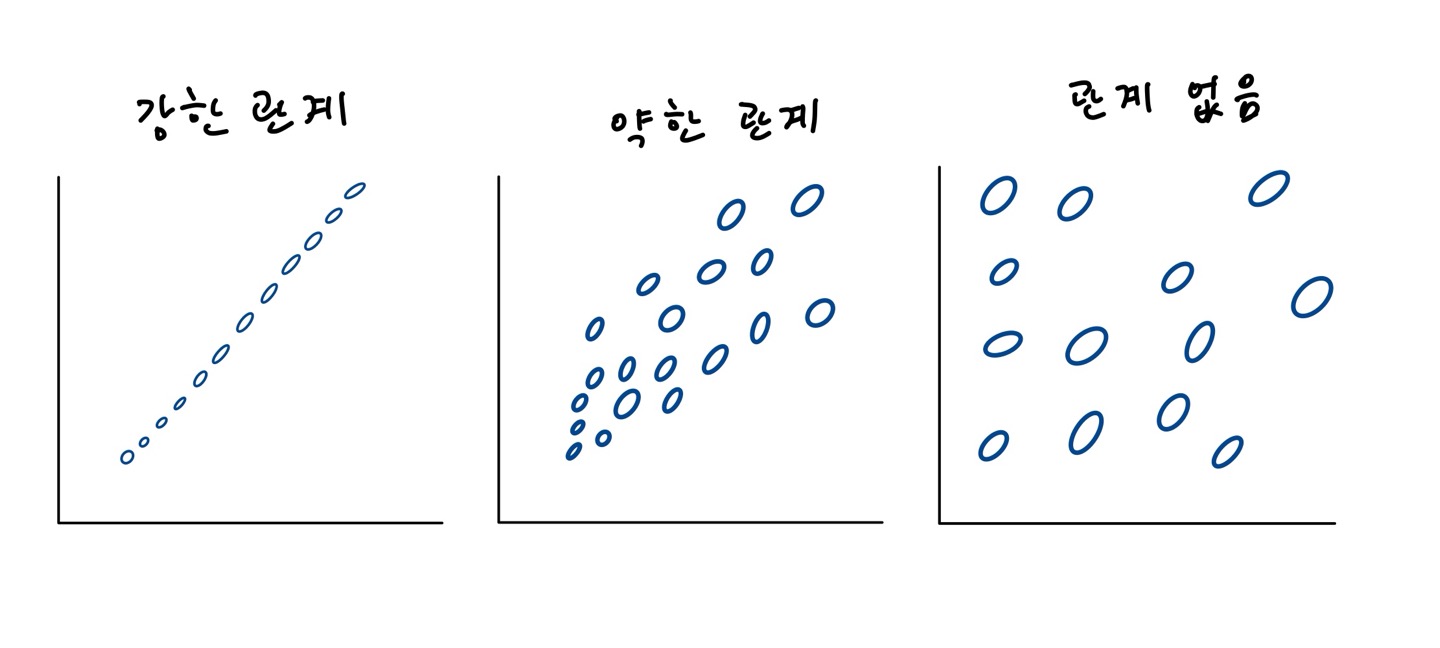
1-2. 관계의 정도
- 얼마나 직선에 모여 있는가??
- x와 y의 관계를 직선으로 얼마나 잘 설명하는가??
1-3. 히스토그램과 산점도 동시 그리기
sns.jointplot(x='total_bill', y='tip', data = tip)
plt.show()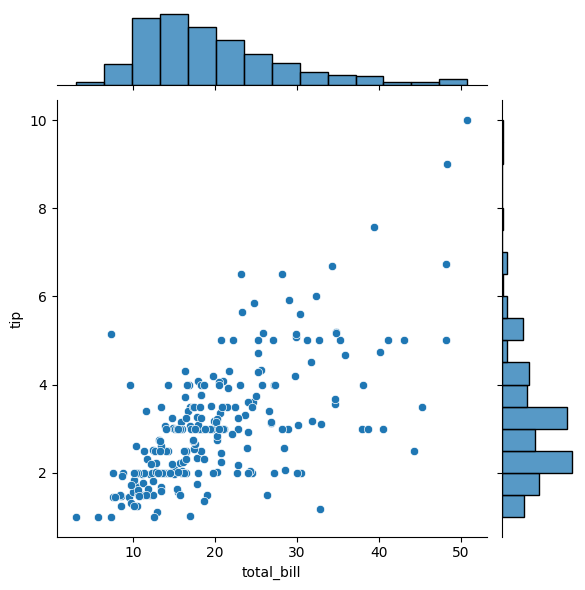
1-4. 모든 데이터에 대한 산점도 그리기
- 숫자형 변수들에 대한 산점도와 히스토그램을 한꺼번에 그림
- 변수와 데이터가 많을 경우 시간이 오래 걸리고, 일일이 확인이 어려움
sns.pairplot(tip)
plt.show()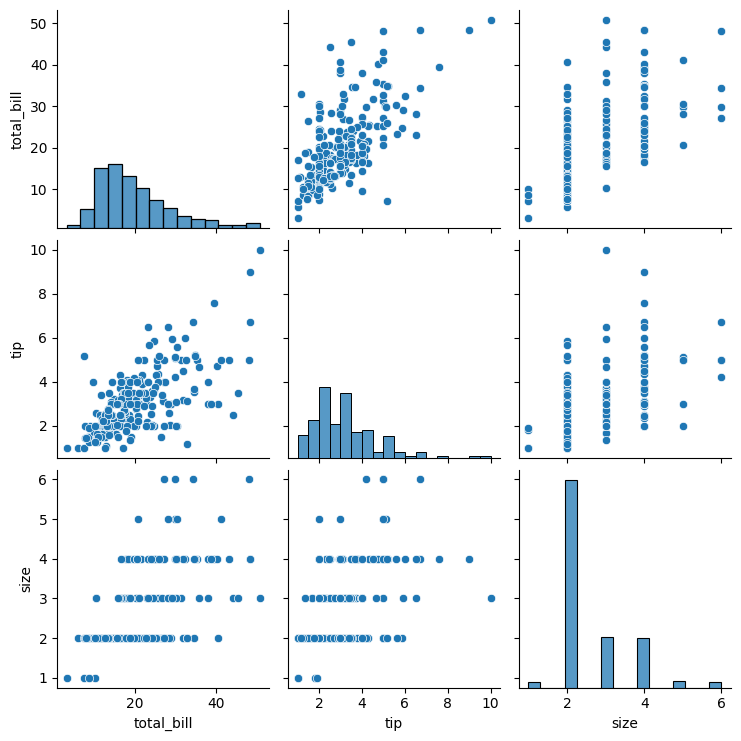
sns.pairplot(tip, kind = 'reg') # reg : 회귀선을 표시
plt.show()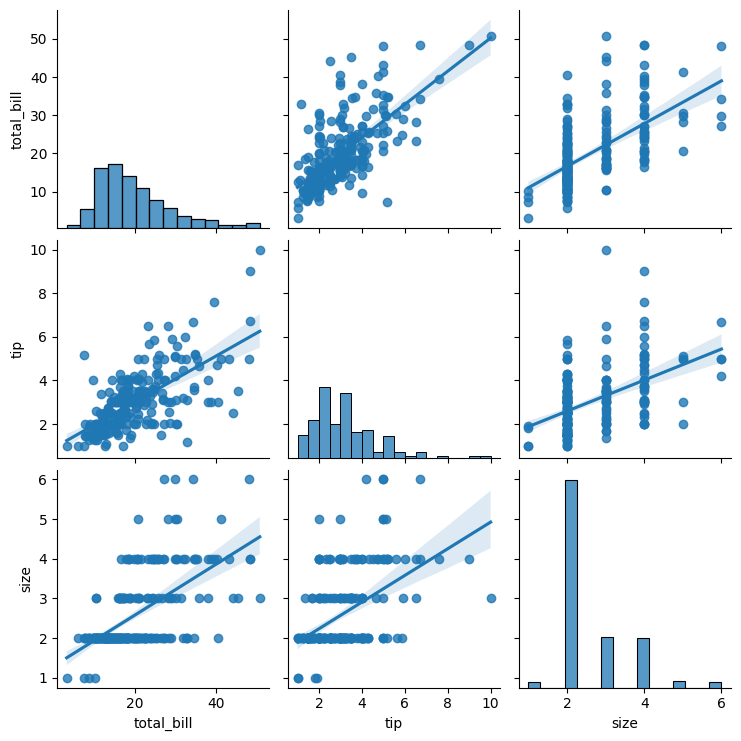
2. 수치화 : 상관계수, 상관분석
- 그래프만 보고서는 관계를 확실하게 파악하기 힘듬
- 관계를 숫자로 계산하여 파악
- 상관계수 : 관계를 수치화
- 상관분석 : 상관계수가 유의미한 지 검정
- 공분산을 이용하여 상관계수를 구할 수 있음
- 상관 계수(r)
- -1 ~ 1 사이의 값
- -1 : 음의 상관관계
- 1 : 양의 상관관계
- 0 : 관계 없음
- 절대값이 1에 가까울수록 강한 상관관계
- 상관계수끼리 비교 가능
2-1. 상관계수의 유의성 검정
- scipy.stats 모듈
- spst.pearsonr : 피어슨 상관분석 함수
- NaN이 있으면 계산 불가
- NaN 값 처리 필요
- 결과 : (상관계수, p-value)
- spst.pearsonr : 피어슨 상관분석 함수
- p-value
- 상관계수가 유의미한 지 판단
- p-value < 0.05 : 두변수 간 관계가 있음(상관관계 유의미)
- p-value >= 0.05 : 두변수 간 관계가 없음(상관관계 무의미
spst.pearsonr(tip['total_bill'], tip['tip'])
# PearsonRResult(statistic=0.6757341092113645, pvalue=6.692470646863819e-34)
# 상관계수는 약 0.67
# p-value는 0.05 보다 낮으므로 상관계수가 유의미하다는 것을 알 수 있음2-2. 모든 상관계수 구하기
- 모든 숫자형 변수들간의 상관계수 계산
- 데이터프레임 내 데이터는 모두 숫자형이어야 함
# 숫자형 데이터만 따로 추출
temp = tip[['total_bill', 'tip', 'size']]
temp.corr()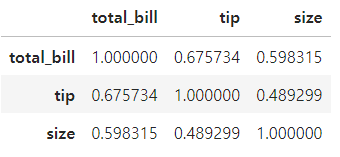
2-3. 상관계수를 heatmap으로 시각화
plt.figure(figsize = (8, 8))
sns.heatmap(temp.corr(),
annot = True, # 숫자(상관계수) 표기 여부
fmt = '.3f', # 숫자 포멧 : 소수점 3자리까지 표기
cmap = 'OrRd', # 컬러맵
vmin = -1, vmax = 1) # 값의 최소, 최대값
plt.show()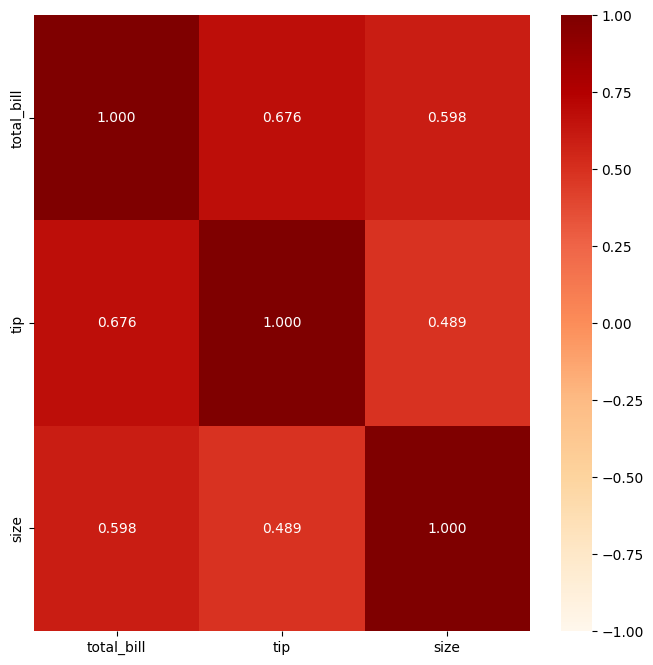
※ 컬러맵 종류 확인
https://matplotlib.org/stable/users/explain/colors/colormaps.html

데이터 분석가&엔지니어를 희망하는 취준생