[crawler]
크롤러란

post : 네이버 블로그 글 발행
get : 읽고싶을때
클라이언트가 get / post 요청하면 뭘 해줄지 코드를 짜놓는 것
ex) python 으로 클이 naver.com 을 get 요청하면 특정 웹 페이지 보내줌
이 웹페이지는 html 문서임
브라우저는 html 해석 엔진
js는 html에 다이나믹한 기능을 부여하고
css는 html에 스타일을 부여함
웹 크롤링은 웹 사이트에서 데이터를 python으로 가져온다음
내가 원하는 콘텐츠만 추리는 작업임
- 파이썬으로 데이터 들어있는 웹 사이트에 접속한다 > html을 받는다
- html 분석 툴에 집어넣어서 내가 필요한 정보만 받아오자
초기 설정
#파이참 터미널에서
pip install requests
pip install bs4#main.py
import requests #웹접속을 하기 위함
from bs4 import BeautifulSoup #python으로 웹 문서를 분석하기 위함
데이터 = requests.get('https://finance.naver.com/item/sise.nhn?code=005930')
print(데이터.content)
이렇게 뭔가 깨져서 나옴
이걸 이제 bs4에 집어넣어보자
soup = BeautifulSoup(데이터.content, 'html.parser')
print(soup)
이렇게 예쁘게 나옴
내가 원하는 데이터가 어디있는지 짚어보자
크롬 개발자도구 고고링
이 [네모 마우스 버튼] 을 누르자
글자가 담겨있는 바로 그 요소를 찾아야됨
soup.find_all('태그명', 속성명)
파이썬아 이것좀 찾아줘 하면됨 그래서 id를 유심히 봐야됨
태그명은 맨 앞에 값 ex) strong
여기서 속성명은 class 값이나 id 값 ex) id="_nowVal"
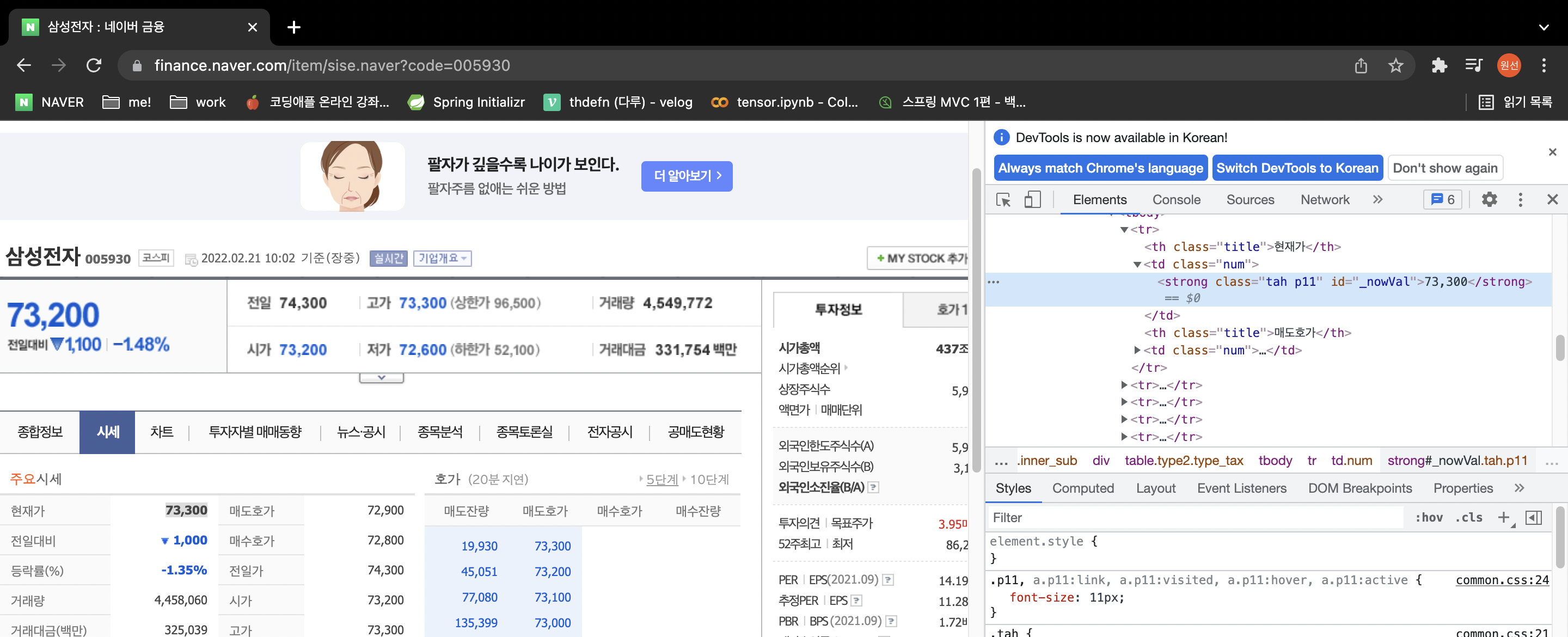

print(soup.find_all('strong', id="_nowVal"))
print(soup.find_all('strong', id="_nowVal"))[0]
print(soup.find_all('strong', id="_nowVal"))[0].text포인트는 값이 list 라는 것

주의점
*class는 python 예약어라서 속성명으로 사용하려면 그냥 하면 에러남 > class_로 해야함

print(soup.find_all('span', class_="tah p11"))*class 명이 위와 같이 띄어쓰기로 결합된 경우 클래스명이 여러개라는 것, 즉 tah와 p11 모두 클래스명이라는 것임 > tah만 쓰던가 p11만 쓰던가
print(soup.find_all('span', class_="tah"))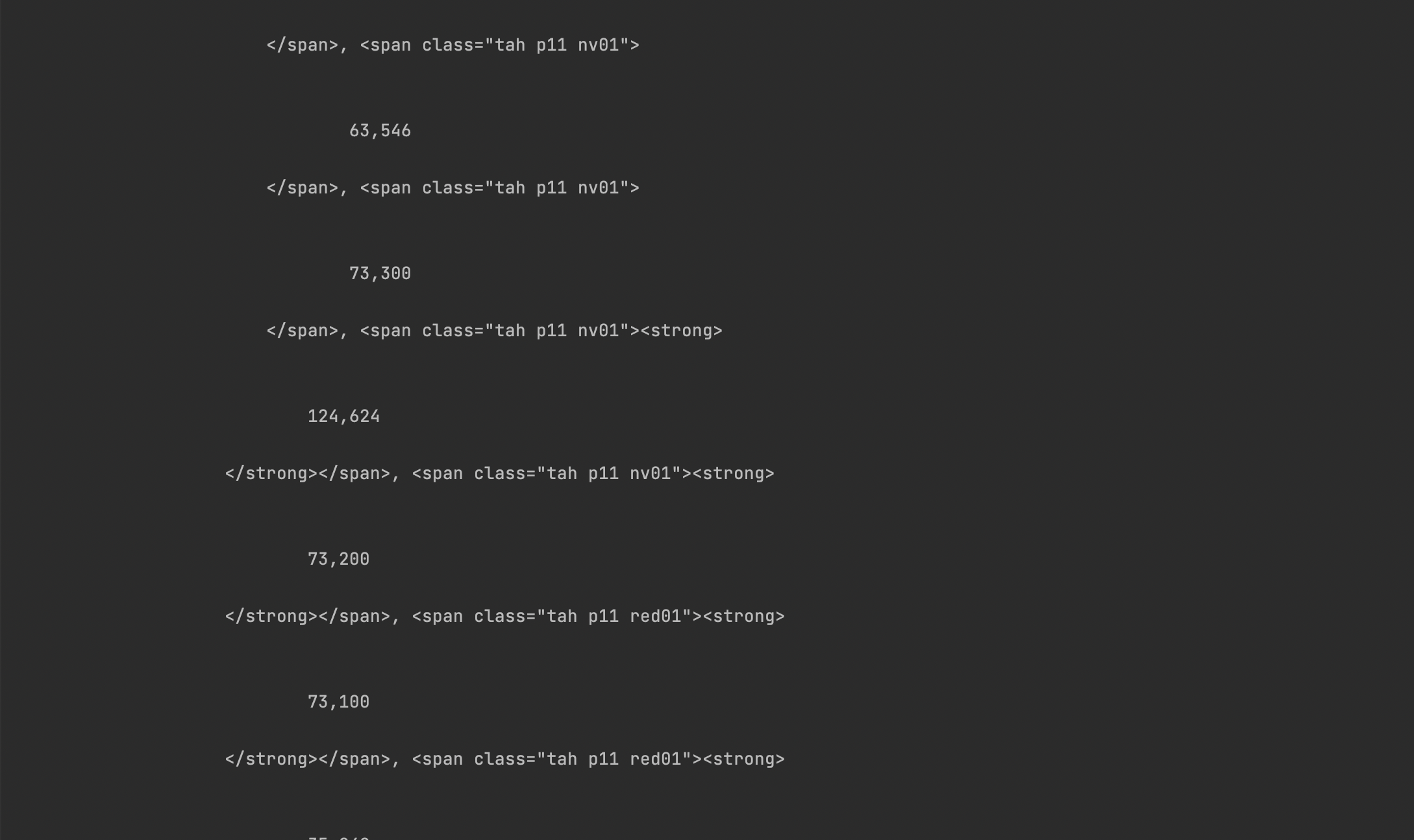
근데 이번에는 값이 좀 많다
*<태그>에 부여된 id는 유니크하지만 class는 중복으로 부여될 수 있음
찾아온 리턴값은 이런식일듯 [찾은거1, 찾은거2, 찾은거3 ...]
그래서 이때는 인덱싱을 잘해야함
print(soup.find_all('span', class_="tah p11")[5].text)개발자 도구에서 살펴봐도 클래스명이 tah인 것이 188개

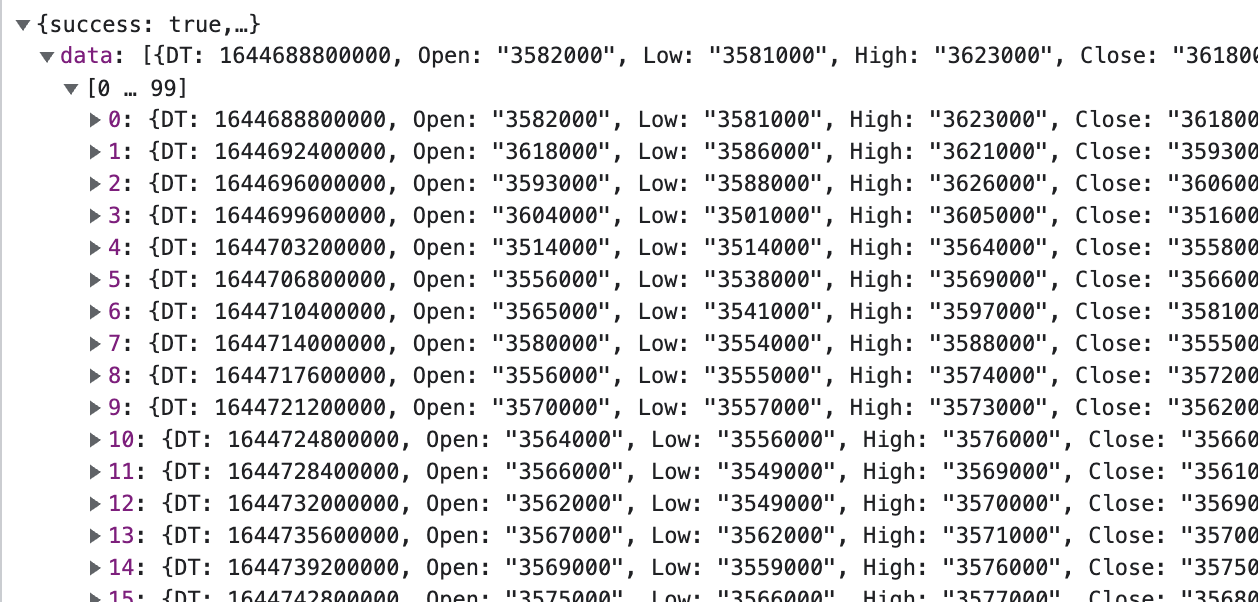
차트에 나오는 가격도 수집해보자
근데 html에 기록이 안되어있음 어떡하지 ?
그럴땐 network tab으로 들어가자
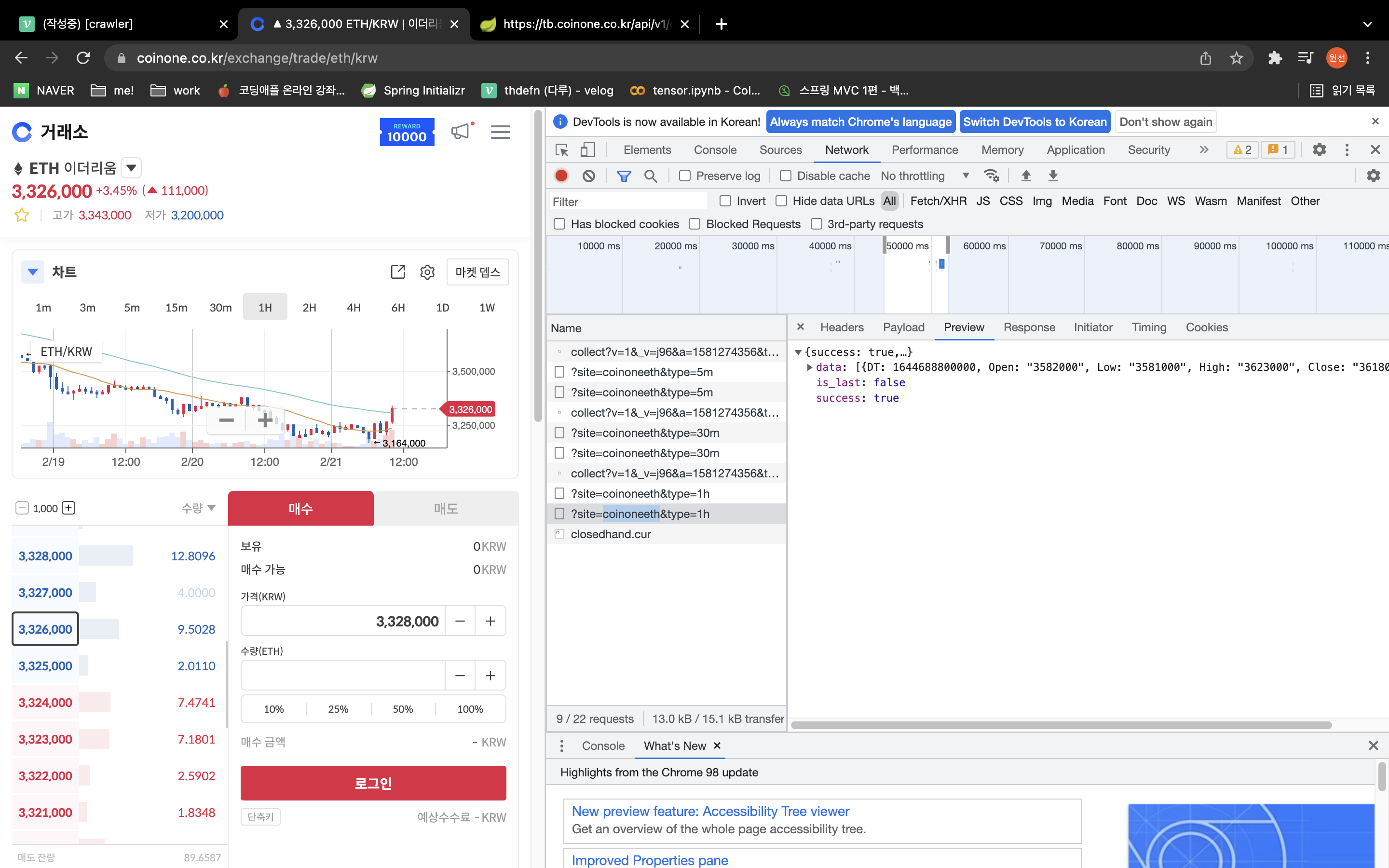
preview가 데이터 미리볼 수 있는 화면
headers에는 어떻게 요청해야하는지 알 수 있음
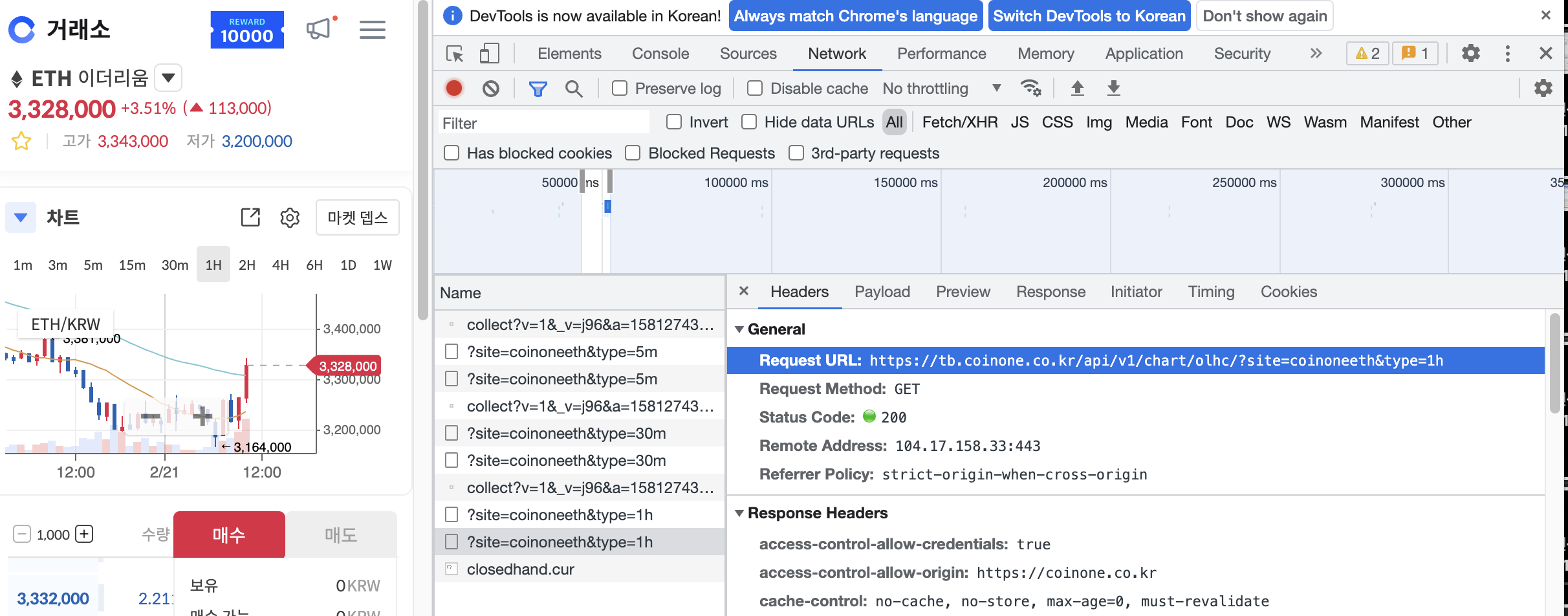
url 복사해서 request 해보자
data = requests.get('https://tb.coinone.co.kr/api/v1/chart/olhc/?site=coinoneeth&type=1h')
print(data.content)

데이터가 참 많다
{"":""} 이니까 혹시 딕셔너리 ?
딕셔너리
딕셔너리는 리스트나 튜플처럼 순차적으로(sequential) 해당 요솟값을 구하지 않고 Key를 통해 Value를 얻는다. 이것이 바로 딕셔너리의 가장 큰 특징이다.
딕셔너리도 리스트처럼 모든 자료형을 삽입할 수 있음
{Key1:Value1, Key2:Value2, Key3:Value3, ...}
-점프투파이썬
ㄴㄴ json임
딕셔너리는 {'':''}
json은 {"":""}
웹 상에서 딕셔너리 데이터를 주고받지 못함
json의 dict 변환 json.loads()
json을 편하게 다루기 위해 딕셔너리로 변환해보자
import json
딕셔너리 = json.loads(data.content)
print(딕셔너리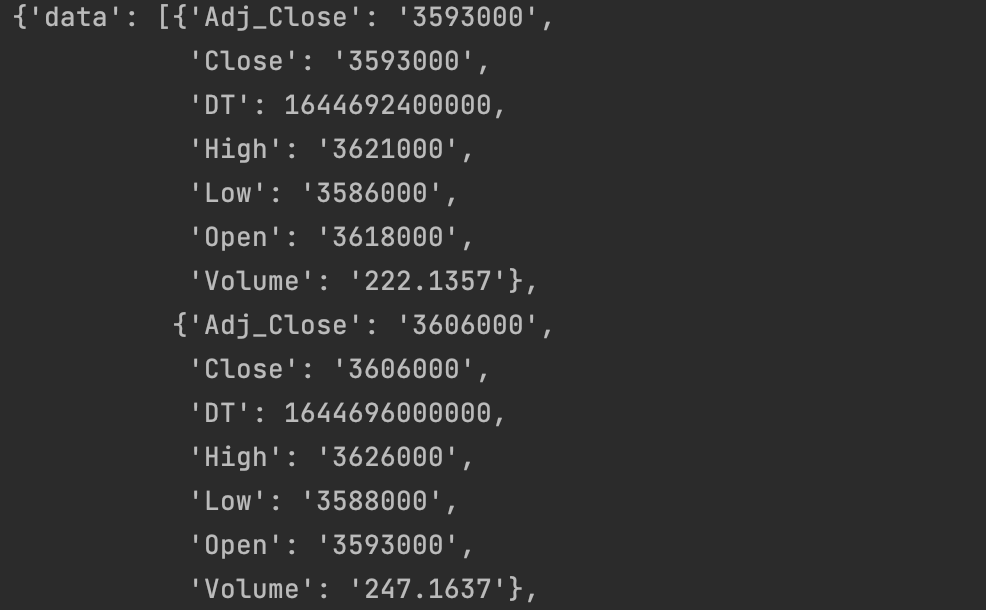
이 데이터 뽑아보자

근데 구조가 복잡해서
내가 원하는 데이터를 뽑기 위해서는 데이터를 분석해봐야하겠군...
dict를 보기 좋게 보여주는 pprint.pprint()
import pprint
pprint.pprint(딕셔너리)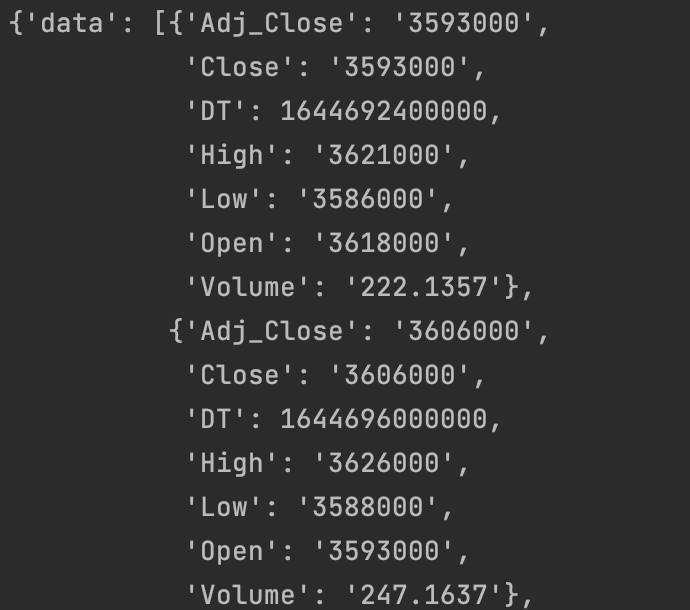
{[{뽑을데이터}]} : 딕셔너리 안에 리스트 안에 딕셔너리 안에 있음
*괄호 안에서 괄호 뽑고 이런식으로 접근하는 게 좋다
pprint.pprint(딕셔너리['data'])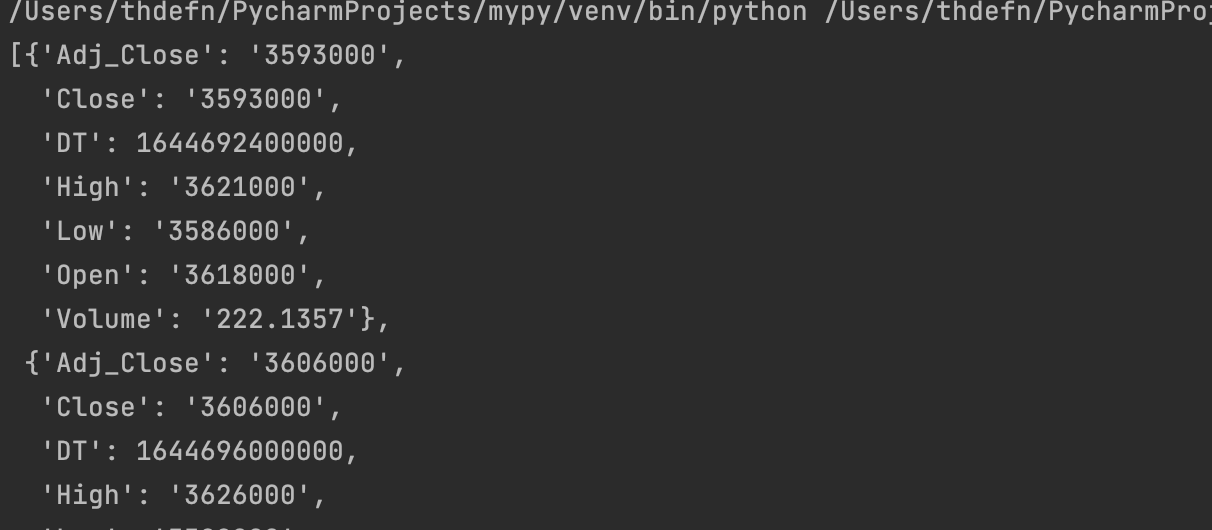
print(딕셔너리['data'][0])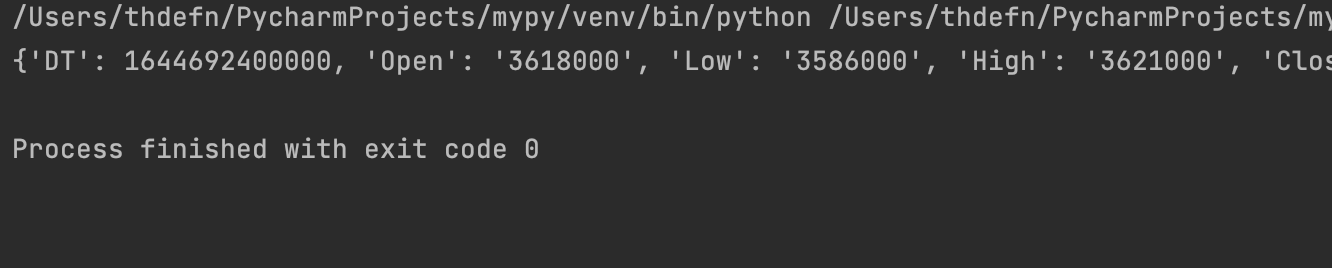
print(딕셔너리['data'][0]['Close'])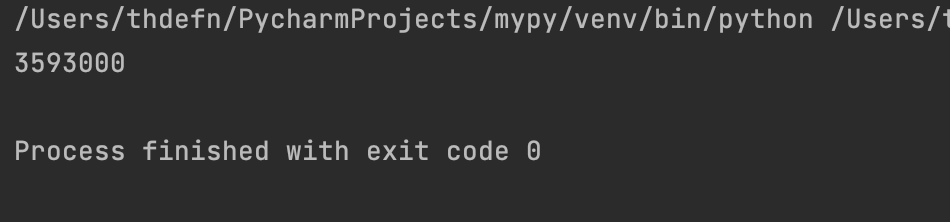
for i in range(200):
print(딕셔너리['data'][i]['Close'])