[tensorflow](1)
머신러닝 : 컴퓨터가 스스로 문제를 풀 수 있도록 데이터셋을 이용해 학습시키는 것
컴퓨터가 직접 개랑 고양이를 구분할 수 있는 능력을 키워주는 것
딥러닝은 그저 머신러닝의 방법론 중 하나임
하지만 사람의 가이드가 불필요함
데이터셋을 많이 주면 개와 고양이의 특성을 직접 판단함
ex) 스팸 메일 데이터셋을 컴퓨터에게 주면, 어떤 문자가 있을 때 스팸 메일일 확률이 높은지 스스로 학습
Supervised Learning : 주어진 데이터셋에 라벨(정답)이 있어요 / 예측 결과에도 정답이 명확해요
Unsupervised Learning : 데이터셋에 라벨이 없어요 / 예측 결과에도 정답이 없어요
컴퓨터가 알아서 비슷한 거끼리 분류해봐! ex)옷 추천, 영화 추천 등등
Reinforcement Learning : 잘하면 보상을 주고, 못하면 벌점을 줘요 / 최종점수를 높이는 방향으로 컴퓨터가 직접 trial and error
Perceptron
다수의 입력으로부터 하나의 결과를 내보내는 단순한 알고리즘

기계가 사람처럼 생각할 수 있게 만들면 더 좋은 결과가 나올 수 있지 않을까?
인간의 뉴런에서 모티브
이게 딥러닝
hidden Layer
입력값들이 레이어를 거쳐서 예측 결과를 내도록 만들어요

Neural Network
레이어가 모여 있는 것
ex)
차 사진을 입력했을 때
레이어를 거쳐가면서
어떤건 로고고, 어떤건 바퀴이고 직접 컴퓨터가 분류해서 추론함 --> feature extraction
전통적인 머신러닝은 사람이 가이드를 했어야 했는데
딥러닝은 자신이 알아서 차의 특징을 추출해요 --> 뉴럴 네트워크를 이용하는 이유
히든레이어의 동작 방식

여기서 w는 가중치,
우리는 컴퓨터가 직접 이 가중치를 구할 수 있도록 데이터셋을 줌
동그라미 하나가 node
컴퓨터가 오차를 줄이는 방향으로 배우도록 할건데,
여기서 오차들도 직접 컴퓨터에게 제공해야함

손실함수 : 예측한 값과 실제값의 오차를 측정하기 위한 함수
그런데 여기서 문제는, 히든 레이어를 쓰던 안쓰던 결과값이 똑같다 ?
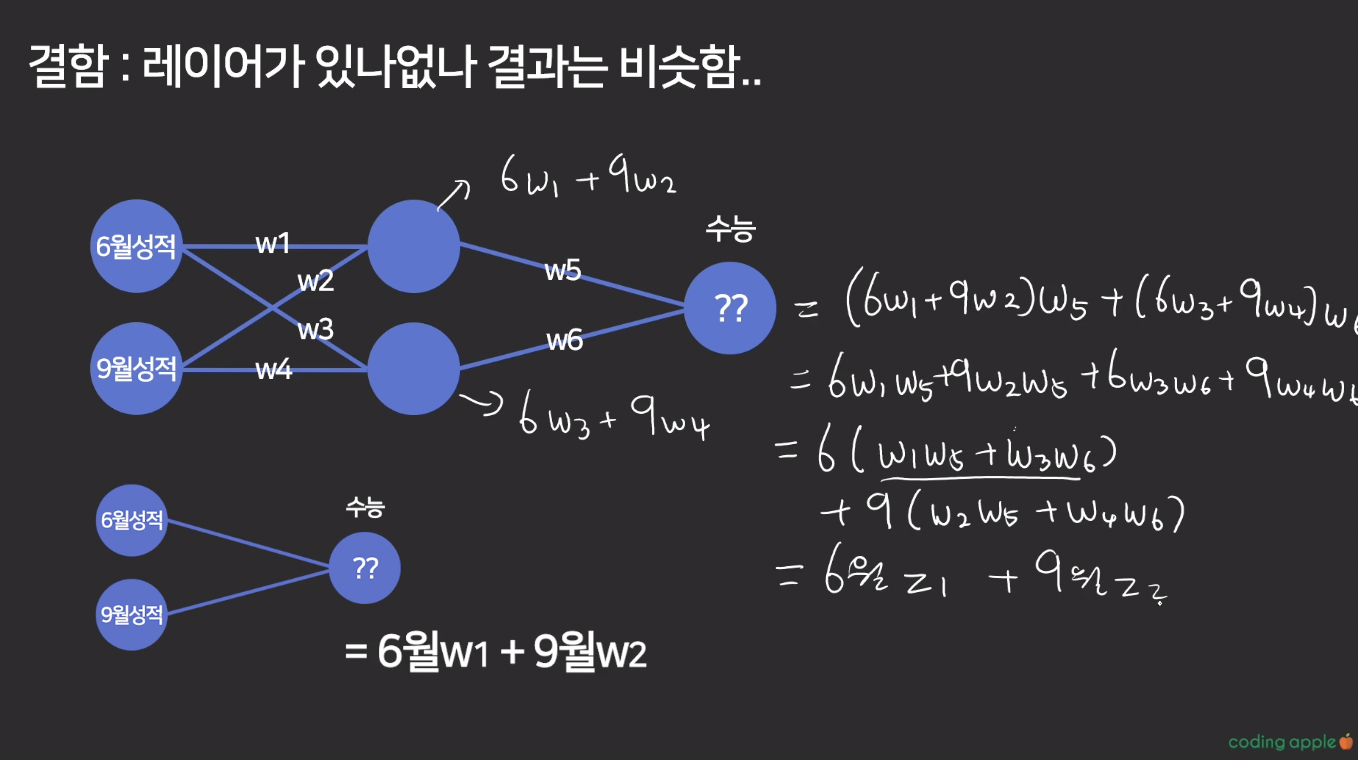
레이어가 있거나 없거나
6월 Input에 어떤 값(z1)을 곱하고
7월 Input에 어떤 값(z2)를 곱한다는 개념은 같음
-> 레이어가 제 역할을 해주고 있지 못함
활성함수가 필요해
노드의 값을 계산하고, 다른 노드로 바로 진행하지 말고
해당 노드의 결과값을 활성 함수에 대입해보자
ex) sigmoid, softmax, hyperbolic tangent
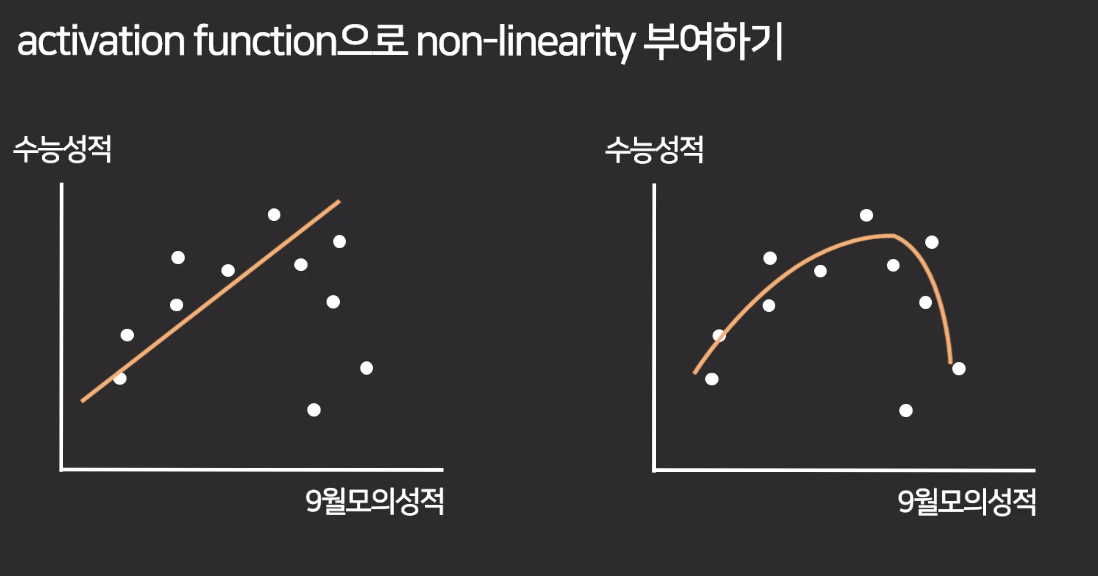
활성함수 없이 예측 : 선형적이고 단순
활성함수 포함한 예측 : 비선형적이고 복잡 -> 특이한 케이스에 대한 예측이 가능함 (비선형성을 부여하는 이유)
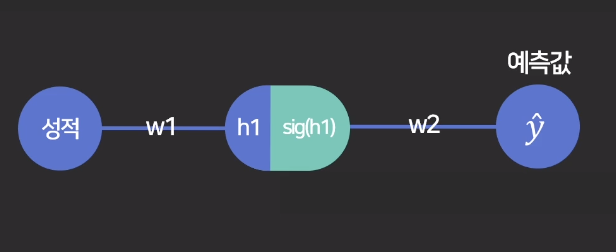
- 0-1 사이의 수로 결과물을 출력하고 싶을 때 출력 layer에도 사용함
결국 컴퓨터는 Loss 를 최소화하는 weight 를 찾으면 됨

경사하강법
머신러닝은 손실을 최소화하는 w값을 찾게 시키는 것 -> w값을 찾는 방법이 경사하강법
최초의 랜덤값 w1에서, 해당 점의 접선의 기울기를 빼면 최적의 w1값을 구할 수 있음
w1이 변하면 최종 Loss값, 총 손실 E값도 변함
최적의 w1값을 찾는 방법
1.첫 w1값은 랜덤 -> 총손실값 계산
2.w1 하나면 2차원 그래프 그려서 판단 가능한데 가중치가 수백개라서 그래프를 못 그림
-> 경사하강법을 이용하자
현재 w1값에서 접선의 기울기를 w1에서 뺀다
여기서 기울기는 w1의 변화가 총손실 E에 얼마나 큰 영향을 끼치는가를 나타냄(편미분)
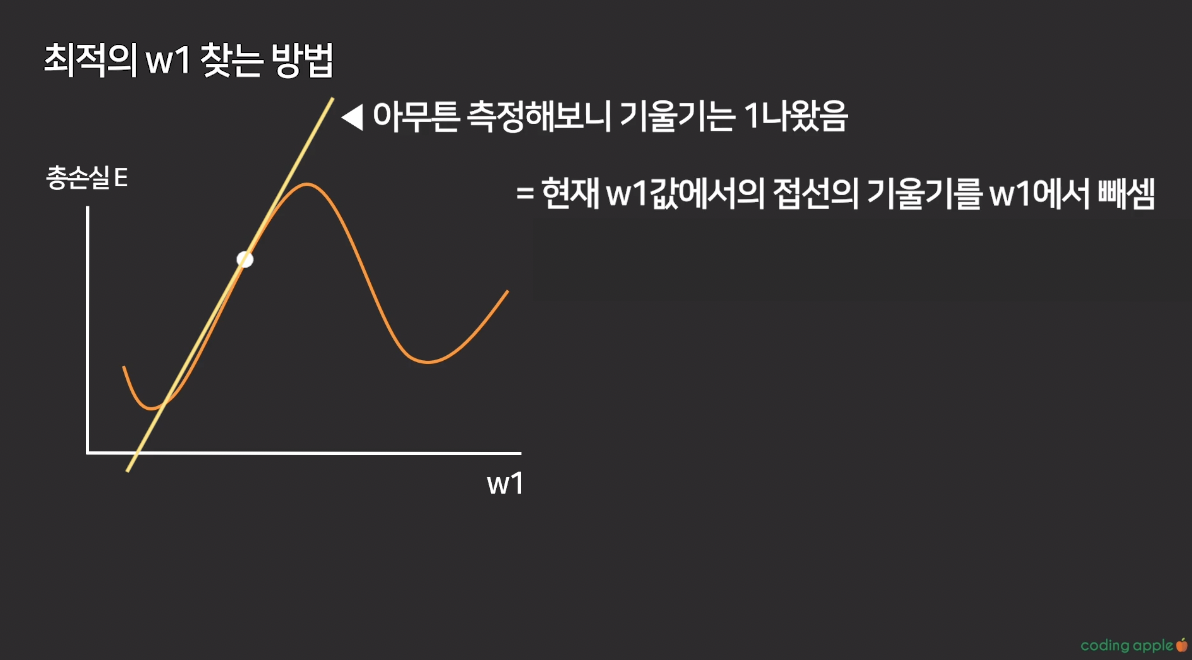
-> new w1 = 현재 w1 - 접선의 기울기
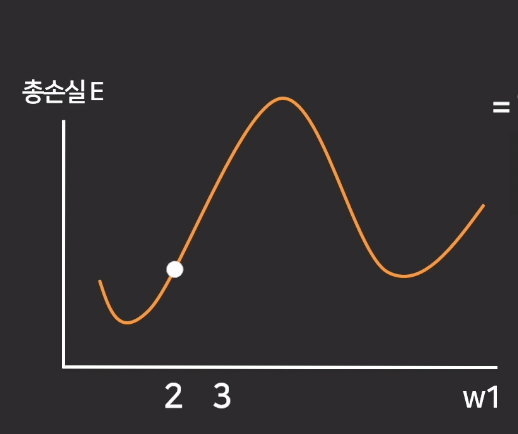
-> 따라서 new w1 = 2

딥러닝 학습 과정
1. w값들 랜덤으로 찍음
2. w값 바탕으로 총 손실 E를 계산함
3. 경사하강으로 새로운 w값 업데이트
-> w1의 갱신
4. w값 바탕으로 총 손실 E를 계산함
5. 경사하강으로 새로운 w값 업데이트
6. w값 바탕으로 총 손실 E를 계산함
7. 경사하강으로 새로운 w값 업데이트
... 총손실 E가 더 이상 안줄어들때까지
learning rate
이런 케이스라면?
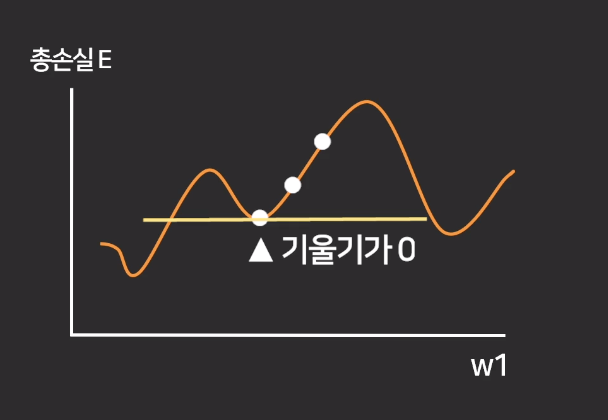
기울기가 0이기 때문에 저 점에서 경사 하강을 더 하지 못함
but 실제 최저점이 아님..!
new w1 = old w1 - learning rate*기울기
인 이유
learning rate 는 local minal한 값을 띄어 넘어 실제 최저값을 찾을 수 있음!
이 값은 직접 찾아야됨
그런데 고정값이면 복잡한 문제인 경우 학습이 안 일어나는 문제도 있음
learning rate optimizer
학습이 일어 날때마다 가변적으로 최적화해주는 수학적 알고리즘
학습 중간중간 learning rate 수정
ex) Momentum, AdaGrad, RMSProp, AdaDelta, Adam

--
w값을 어떻게 업데이트할까?
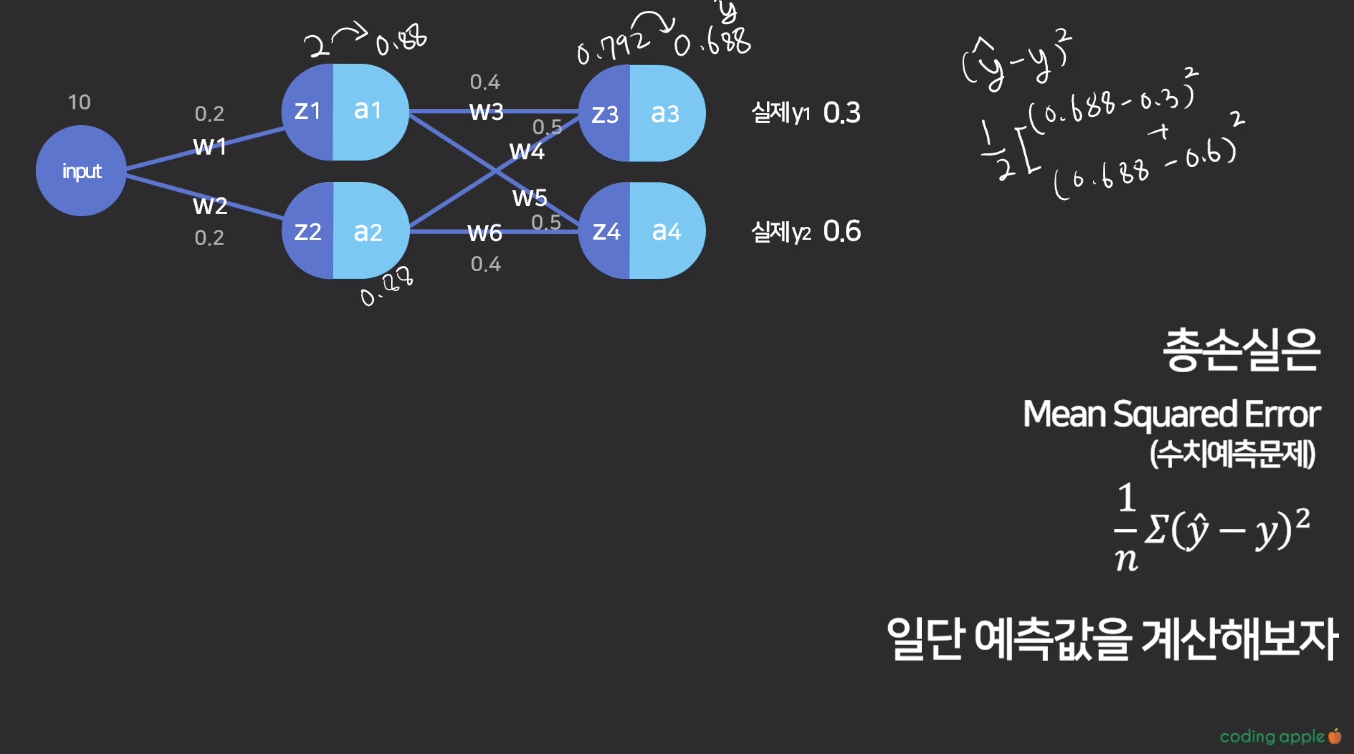
w값 업데이트 순서는 마지막 레이어와 가까운 애부터
neww3=oldw3 - a*변화량
여기서 변화량, 즉 w가 총손실에 끼치는 영향을 어떻게 구하지?
w3 구하는 방법
w3-> z3 * z3 -> a3
w3 가 z3에 얼마나 큰영향을 끼치는지와
z3가 a3에 얼마나 큰 영향을 끼치는지를 곱한다
