[tensorflow](3) keras로 딥러닝 모델 만들기
tf.keras.models.Sequential([레이어1, 레이어2, 레이어3 ...])
딥러닝 모델 디자인하는 법
Sequential을 쓰면 신경망 레이어들을 자동으로 만들어줌
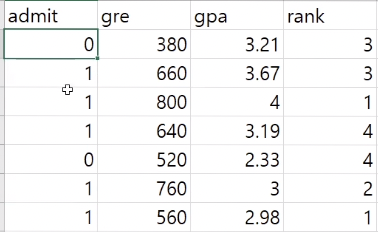
사용 데이터셋
tf.keras.layers.Dense(노드의 개수)
노드의 개수는 관습적으로 2의 배수를 사용
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64), #중간레이아
tf.keras.layers.Dense(128), #중간레이어
tf.keras.layers.Dense(1)
])결과가 (0과 1로) 하나가 나와야하므로
마지막 출력 레이어에는 노드의 개수를 1로 주어줌
레이어를 디자인할때는 꼭 활성 함수가 있어야 함
tf.keras.layers.Dense(64, activation='sigmoid')ex) sigmoid / tanh / relu / softmax
확률 예측 문제이므로 마지막 레이어는 항상 예측 결과를 도출해야함
sigmoid는 모든 값을 0-1 사이로 압축해줌 -> 딥러닝이 도출한 0과 1 사이의 결과를 확률로 해석할 수 있음
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(128, activation='tanh'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='', loss='', metrics=['accuracy'])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])optimizer : 경사하강법에서 러닝레이트나 기울기값들을 조정하는 역할을 함
ex) adagrad / adadelta / rmspop / sgd / adam
loss : 손실함수
0인지 1 사이의 분류 / 확률예측문제에는 binary_crossentropy
metrix
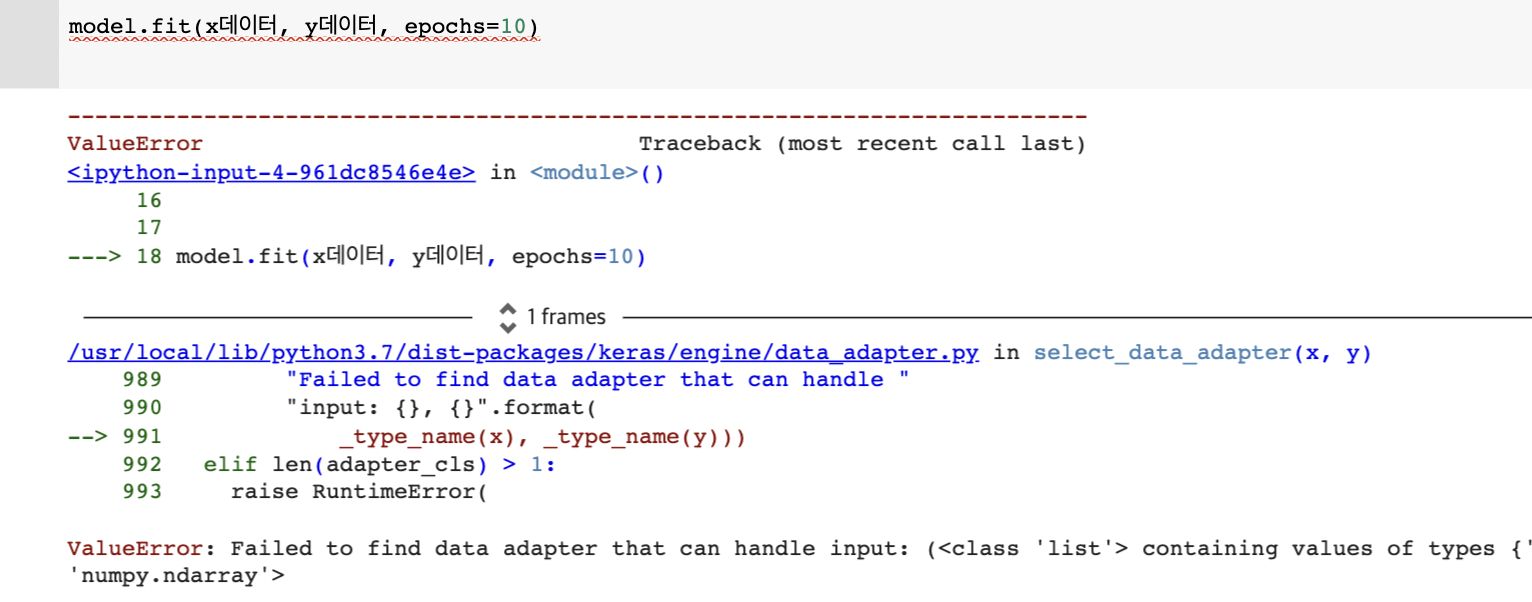
model.fit(x데이터, y데이터, epochs=10)
x데이터로 y데이터를 추론해주세요
10번 학습을 시킬게요
x데이터 : 트레이닝 데이터 ! 주어진 데이터 셋에서는 gre / gpa / rank
y데이터 : 실제 정답 admit
epochs : 몇번 학습을 시킬지
x데이터 = [[데이터1], [데이터2], [데이터3], ...]
y데이터 = [정답1, 정답2, 정답3, ...]
pandas와 numpy 이용하기
pandas import
import pandas as pd
data = pd.read_csv('gpascore.csv')
print(data)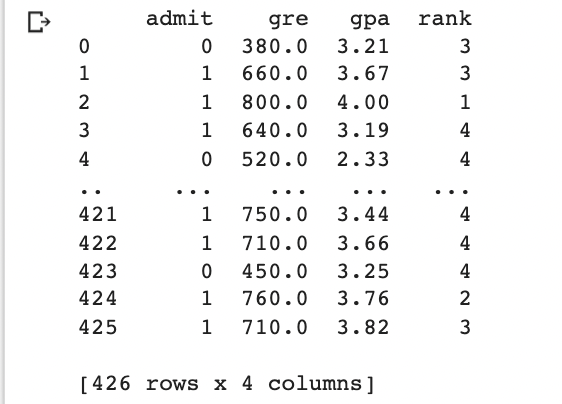
데이터 전처리하기
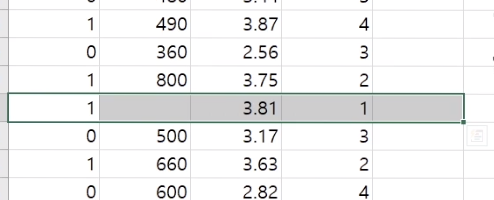
위와 같이 결측된 데이터가 있다면 ?
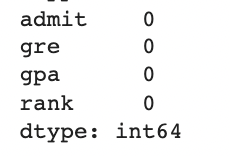
print(data.isnull().sum())
결측 데이터 확인하기

data.dropna() / data.fillna(0)
결측값 제거
data['gpa'].min() / data['gpa'].max()
특정 열의 최대 최소값 확인하기
data['admit'].values
리스트 안에 데이터를 담아줘요
y데이터 = data['admit'].valuesdata.iterrow()
pandas로 연 데이터를 dataframe 이라고 하는데,
거기에 붙일 수 있는 함수
iterrow()를 통해 한행씩 출력이 가능함
for i, rows in data.iterrows():
x데이터.append([rows['gre'], rows['gpa'], rows['rank']])
x데이터와 y데이터는 numpy array or tensor 을 줘야함
파이썬 일반 리스트는 ㄴㄴ
그래서 리스트를 numpy array 라는 자료형으로 변환해야함
np.array(x데이터)
model.fit(np.array(x데이터), np.array(y데이터), epochs=10)numpy 는 파이썬으로 행렬 , 벡터 이런 거 만들때 사용하는 라이브러리
Epoch 1/10 : 전체 데이터셋을 한번써서 한번 학습이 이뤄졌음
loss : 예측값과 실제 데이터의 차이를 합산한 값, 손실값이 적을 수록 좋아요
accuaracy : 실제 예측값과 실제 데이터와 얼마나 정확히 맞는지 ! 높을수록 좋음
epochs 값을 올릴수록 성능 향상이 일어남
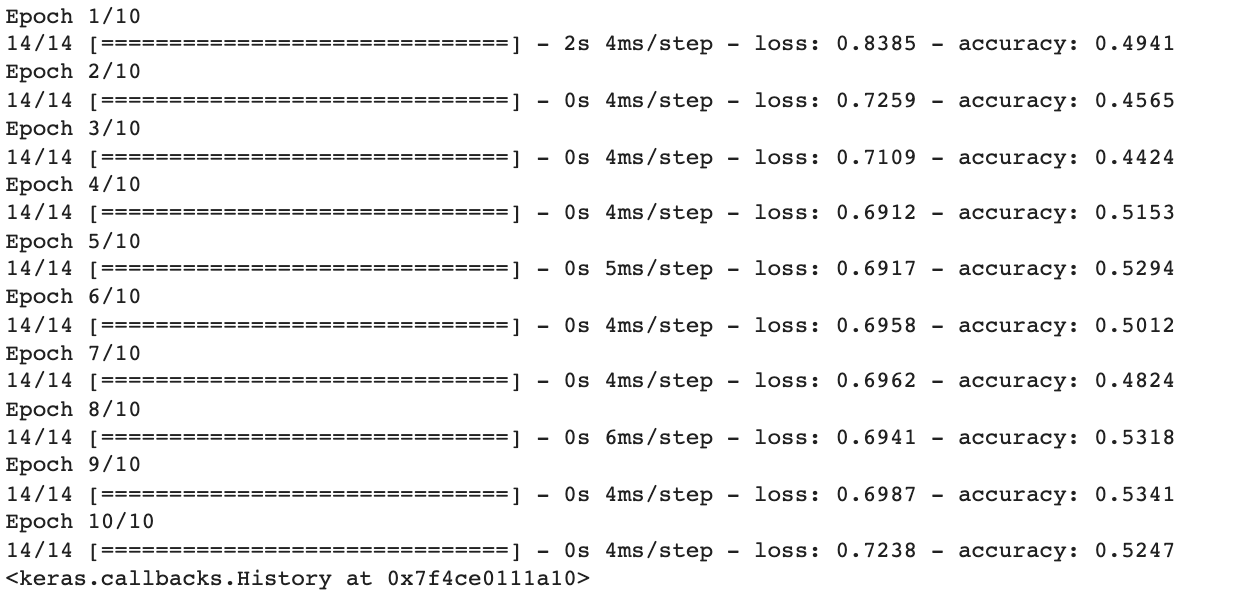
근데 가끔 epochs 값을 늘어도 accuracy나 loss 성능향상이 일어나지 않을수도 있음 이건운빨
학습시킨 모델로 예측해보자
예측값 = model.predict([[750, 3.70, 3], [400, 2.2, 1]])
print(예측값)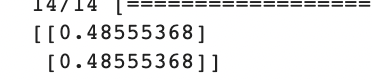
딥러닝의 프로세스
- 모델만들고
- 데이터 집어넣고 학습
- 새로운 데이터 넣고 예측하기
성능향상요소
- 데이터 전처리를 깔끔하게
- 하이퍼파라미터 튜닝 : 노드의 개수나 기타 값을 실험적으로 조정하면서 성능 향상시키기
