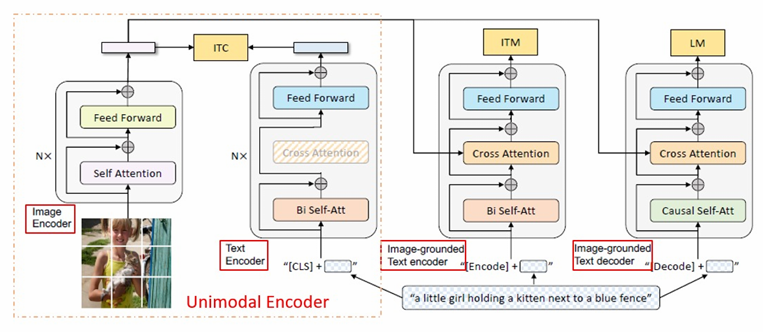
1 ) Multimodal mixture of Encoder-Decoder
- Unimodal Encoder
-
Image Encoder : ViT 사용
-
Text Encoder : BERT 사용
- sentence를 요약하기 위해 text의 시작에 [CLS] 토큰이 첨부됨→ ITC (Image‑Text Contrastive) : CLS 임베딩을 정규화 후 코사인 거리로 맞추기 → 이미지·텍스트 임베딩 공간 정렬
-
- Image-grounded text encoder
-
cross attention에서 visual information을 주입함
- Cross‑Attention: Query=텍스트 토큰, Key/Value=이미지 토큰→ ITM (Image‑Text Matching) : (이미지,텍스트) 쌍이 맞는지 판별 – fine‑grained 정합성 학습
-
- Image-grounded text decoder
-
Language Modeling으로 이미지 조건부 캡션 생성
단계 입력(Decoder) 라벨 설명 Teacher Forcing <BOS>+ y₁ … y_{L−1}y₁ … y_L 토큰 시퀀스를 한 글자씩 오른쪽으로 시프트해 넣음.→ 디코더는 현재 시점까지의 정답 토큰 + 이미지 정보를 보고 다음 토큰을 예측. Cross-Attention Vision Encoder 출력 패치 토큰 고정 컨텍스트 모든 시점에서 이미지 특징을 함께 확인.
-
2 ) CapFilt
- Noist web data 문제를 해결
- 인간이 직접 제작한 image, text 쌍으로 captioner(image-grounded text decoder)와 filter (image-grounded text encoder)
개인적으로 궁금한 점
Q. 왜 Unimodal에서만 CLS를 사용하는가?
-
ITC는 “시퀀스/이미지 전체를 대표하는 단일 벡터”가 필요 → BERT·ViT 모두 CLS를 자연스럽게 제공.
-
Image-grounded 단계부터는 토큰 단위 cross-attention으로 상호작용하므로, 전체 요약 벡터가 필수적이지 않음(있긴 하지만 loss에 직접 쓰진 않음).
-
Decoder는 CLS가 있어도 causal mask 때문에 첫 토큰에서만 볼 수 있어 효용이 크지 않아서 사용하지 않음.
정리
-> 이미지-텍스트를 ITC로 학습시켜 노이즈가 심한 쌍을 걸러냄
-> ITM으로 이미지와 텍스트 매칭 (ITC로도 걸러내지 못한 것을 거르기 위함) 하여 언어 불일치 샘플들 걸러냄
-> 남은 이미지들에 BLIP으로 새 캡션 생성 후 원본과 비교
