책 내용
1.1 시퀀스란
- 순서가 있는 항목의 모음
- 순차 데이터
▶ 예시
The book is on the table.
The boos are on the table.위 두개의 문장은 영어에서 다수인지 복수인지에 따라 동사가 달라진다. 이런 문장은 아래와 같이 문장이 길어질 수록 의존성이 더 높아질 수 있다.
The book that I got yesterday is on the table.
The books read by the second=grade children are shelved in the lower rack.딥러닝에서의 시퀀스 모델링은 숨겨진 '상태 정보(은닉 상태)'를 유지하는 것과 관련이 있다. 시퀀스에 있는 각 항목이 은닉 상태를 업데이트 하고, 시퀀스 표현이라고 불리는 이 은닉상태의 벡터를 시퀀스 모델링 작업에 활용하는 과정을 거친다. 가장 대표적인 시퀀스 신경망 모델은 'RNN(Recurrent nerual network)'이다. NLP에서의 시퀀스 모델 RNN에 대해서 알아보도록 하자.
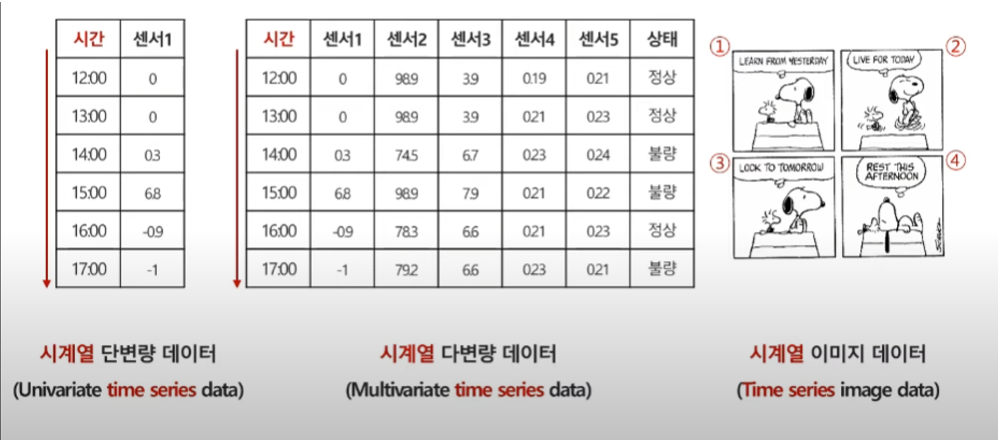
단변량 데이터가 시간에 따라 얻어지면 시계열 단변량 데이터
다변량 데이터가 시간에 따라 얻어지면 시계열 다변량 데이터
시간에따라 이미지가 변하면 시계열 이미지 데이터
DNN vs RNN
책내용
순환 신경망, RNN (recurrent neural network)
- RNN의 목적은 시퀀스 텐서를 모델링 하는 것
- 입력과 출력을 시퀀스 단위로 처리함
- RNN의 종류는 여러가지가 있지만, 해당 포스팅에서는 엘만RNN에 대해 다룰 것임
- 두 개의 RNN 을 활용한 sequence2sequence 다양한 RNN모델이 NLP영역에서 활용되고 있다.
- 같은 파라미터를 활용해서 타임 스텝마다 출력을 계산하고, 이때 은닉 상태의 벡터에 의존해서 시퀀스의 상태를 감지한다.
- RNN의 주 목적은 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산함으로써 시퀀스의 불변성을 학습하는 것이다.
순환 신경망, RNN (recurrent neural network)
- RNN의 목적은 시퀀스 텐서를 모델링 하는 것
- 입력과 출력을 시퀀스 단위로 처리함
- RNN의 종류는 여러가지가 있지만, 해당 포스팅에서는 엘만RNN에 대해 다룰 것임
- 두 개의 RNN 을 활용한 sequence2sequence 다양한 RNN모델이 NLP영역에서 활용되고 있다.
- 같은 파라미터를 활용해서 타임 스텝마다 출력을 계산하고, 이때 은닉 상태의 벡터에 의존해서 시퀀스의 상태를 감지한다.
- RNN의 주 목적은 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산함으로써 시퀀스의 불변성을 학습하는 것이다.
DNN = 시계열 데이터를 반영하지 않은 모델.
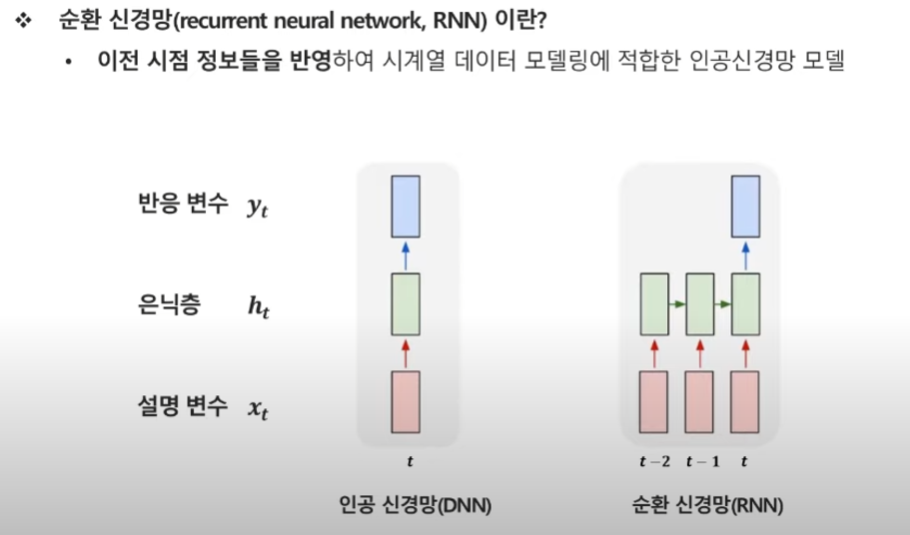
일반적인 DNN은 입력 데이터를 넣으면 은닉층을 거쳐 출력값을 예측하는 구조라면,
시계열을 반영하는 RNN은 현 시점t 정보 뿐만 아니라 , t-1, t-2 시점의 정보까지 모두 활용하여 t시점의 y값을 예측하는 방식이다.
RNN
2. 순환 신경망, RNN (recurrent neural network)
- RNN의 목적은 시퀀스 텐서를 모델링 하는 것
- 입력과 출력을 시퀀스 단위로 처리함
- RNN의 종류는 여러가지가 있지만, 해당 포스팅에서는 엘만RNN에 대해 다룰 것임
- 두개의 RNN 을 활용한 sequence2sequence 다양한 RNN모델이 NLP영역에서 활용되고 있다.
- 같은 파라미터를 활용해서 타임 스텝마다 출력을 계산하고, 이때 은닉 상태의 벡터에 의존해서 시퀀스의 상태를 감지한다.
- RNN의 주 목적은 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산함으로써 시퀀스의 불변성을 학습하는 것이다.
일반적인 DNN
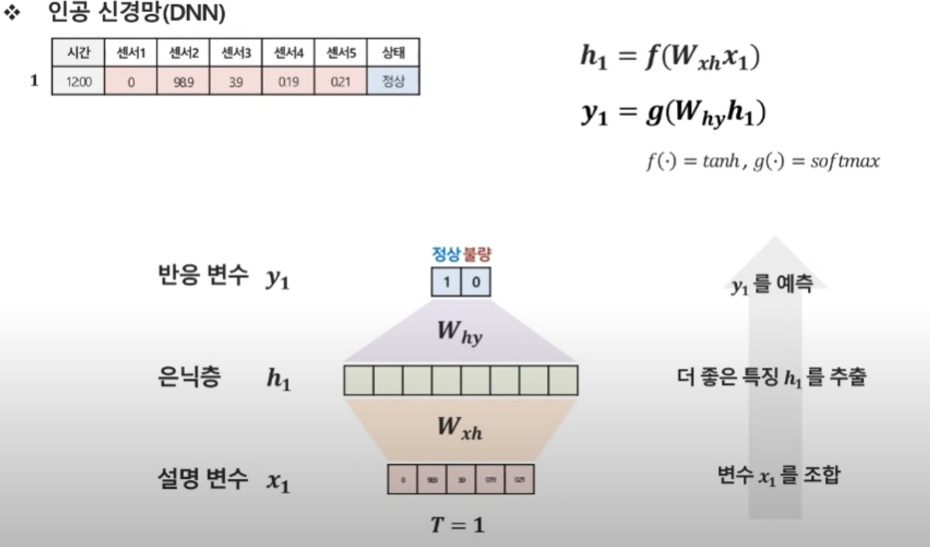
첫 번째 시점의 데이터
t =1인 시점은, 이 시점만 갖고 데이터를 사용.
시점에 대한 데이터가 들어옴 → 은닉층의 히든 벡터가 고정이 됨 → 히든벡터를 이용해 y값을 예측
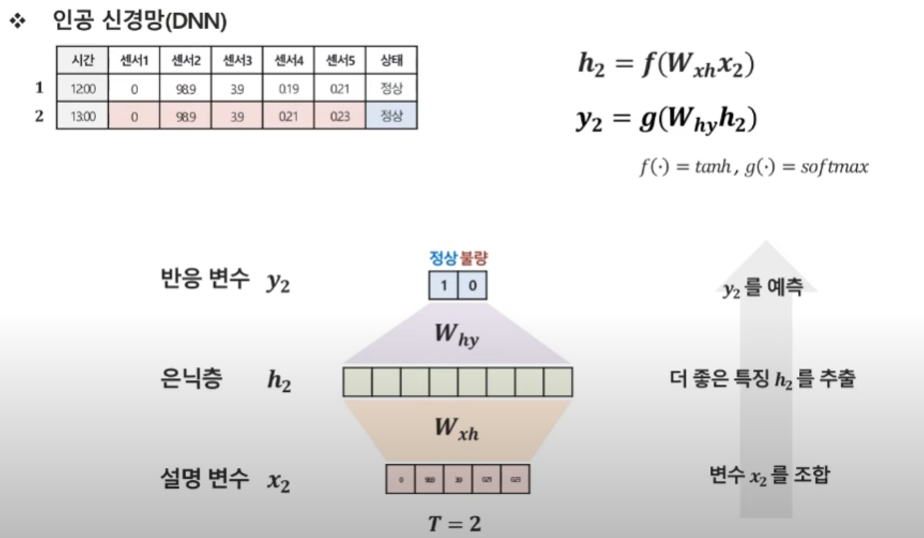
두 번째 시점의 데이터.
첫번쨰 시점을 이용하지 않고 두번째 데이터만 이용 → 두번쨰 시점의 히든벡터 고정- > 두번째 시점의 히든 벡터를 예측
세번째도 전과동.
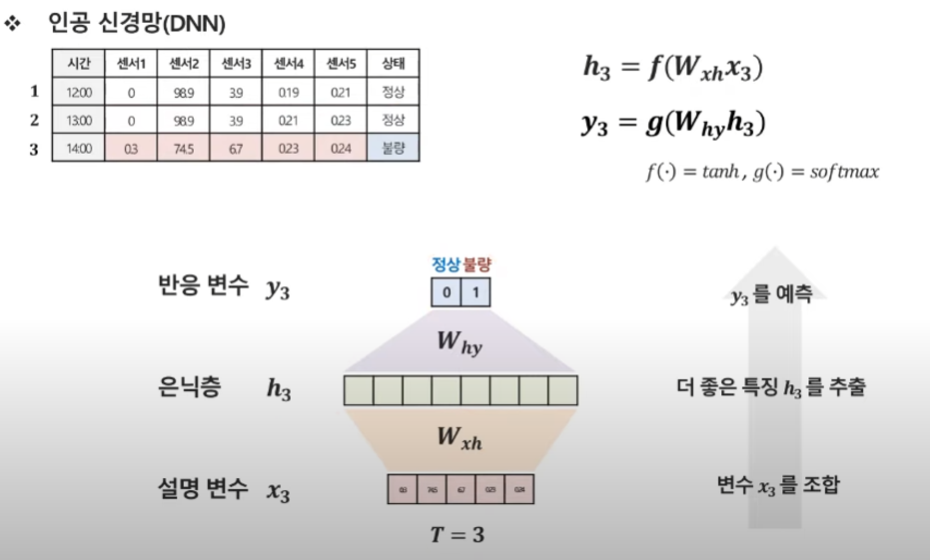
우리가 여태까지 한 것은 한 시점의 데이터를 예측할 때, 이전 시점의 정보의 영향을 받지 않음
시계열 데이터는 이전 시점의 정보의 영향을 받는 대표적인 데이터.
이전 시점의 정보를 이용 안하면 정확하지 않을 수 있다.
전시점과 전전시점의 데이터를 이용하면 더 정확하게 예측할 수 있지 않을까? 란 생각으로 진행.
이전시점 정보를 더해야하는데 어떻게 더하냐
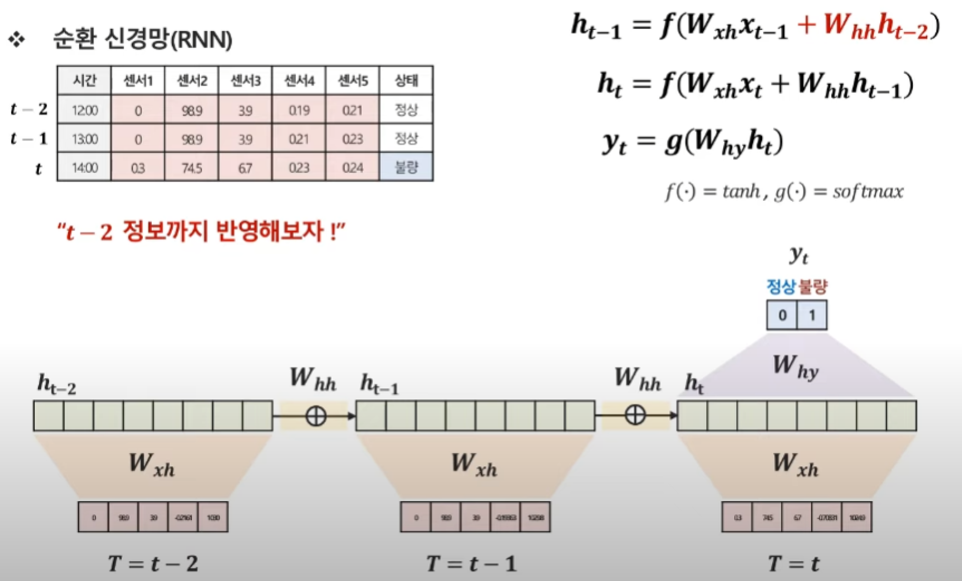
t시점을 예측하고 싶어 → t-1 시점을 반영하고 싶어 → t-1에서의 히든 벡터가 있네? →t시점의 히든벡터와 합성을 하면 될 것 같은데? → 어떻게 합성하지?
t-1시점의 히든 벡터를 갖고 와 → 해당하는 웨이트를 곱해 Whh → t시점과 t-1시점의 히든벡터를 더해 → 새로운 히든 벡터 등장
이런 방식으로 t-2도 이용을 해!
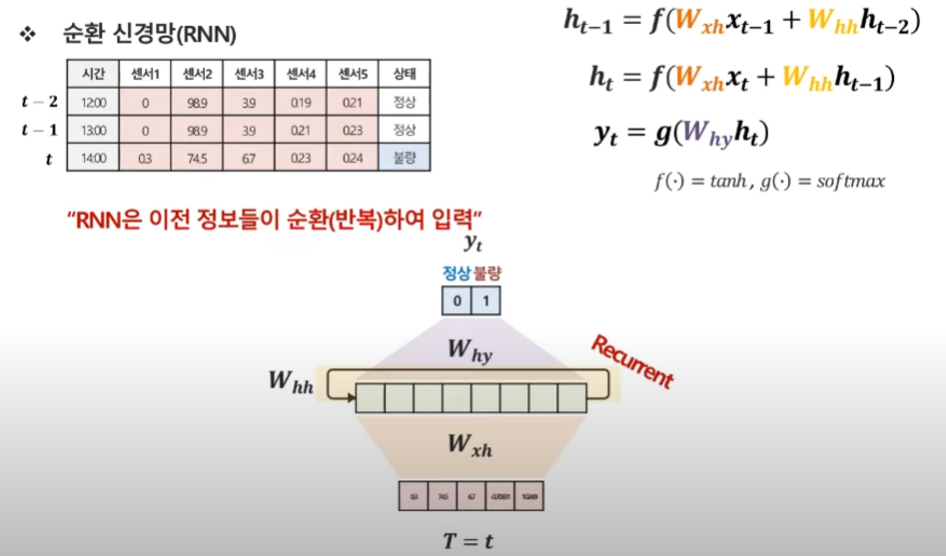
결론 : t시점에선 t-1, t-2 정보를 모두 이용한 꼴이 된다.
이게 RNN의 기본 개념
과거 시점이 굉장히 많은 경우에는 이걸 쭉 늘려 나가야한다. → 어떻게 표현을 할거냐
하나의 그림으로 요약을 해버려 (Recurrent Neural Network)
순환 신경망의 구조
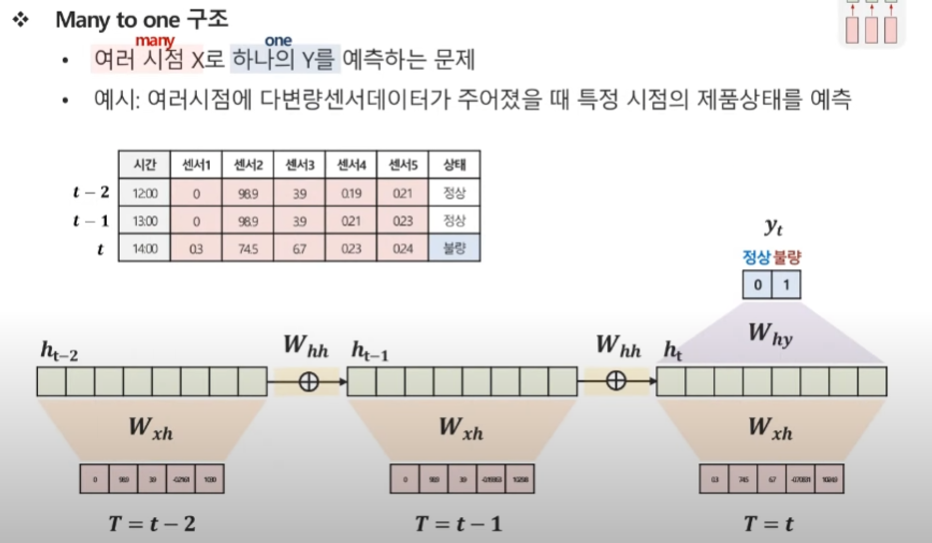
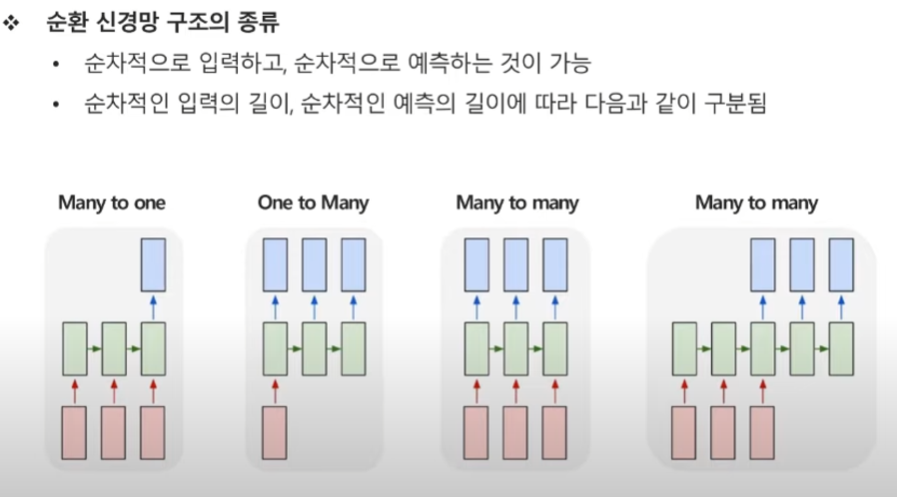
Many to one
여러 시점 X로 하나의 Y를 예측하는 문제
예시 : 여러시점에 다변량 센서 데이터가 주어졌을 때 특정 시점의 제품상태를 예측
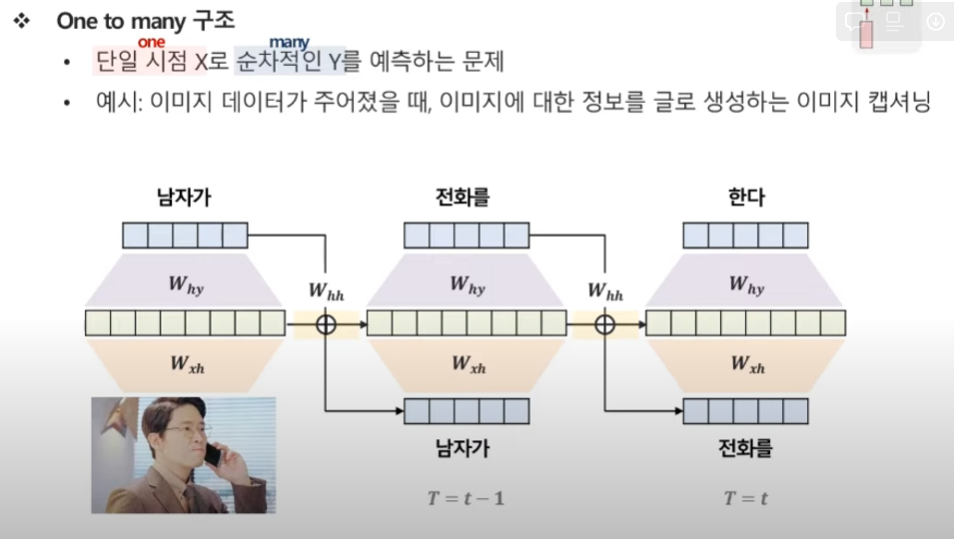
One to Many
단일 시점 X로 순차적인 Y를 예측하는 문제
예시 : 이미지데이터가 주어졌을 때, 이미지에 대한 정보르 ㄹ글로 생성하는 이미지 캡셔닝
이미지가 주어졌을 떄, 이미지를 설명하는 문제.
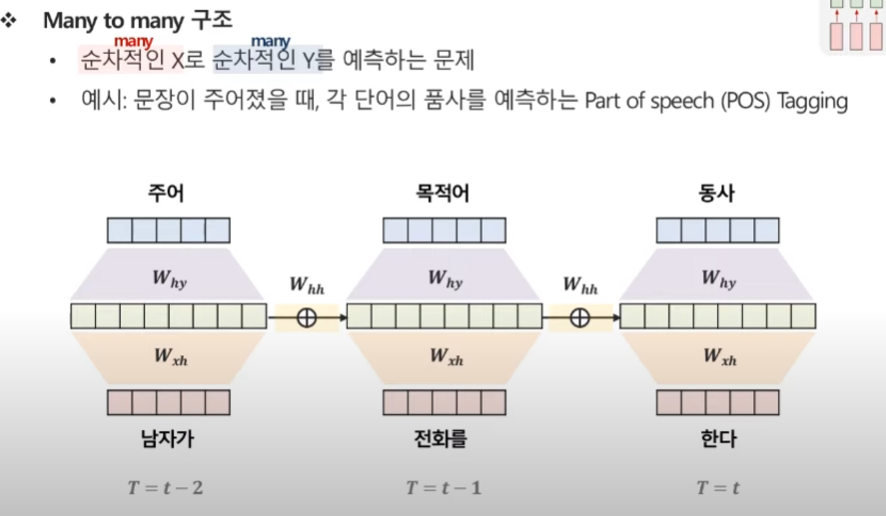
Many to Many(1)
순차적인 X로 순차적인 Y를 예측하는 문제
예시 : 문장이 주어졌을 때, 각 단어의 품사를 예측하는 예제
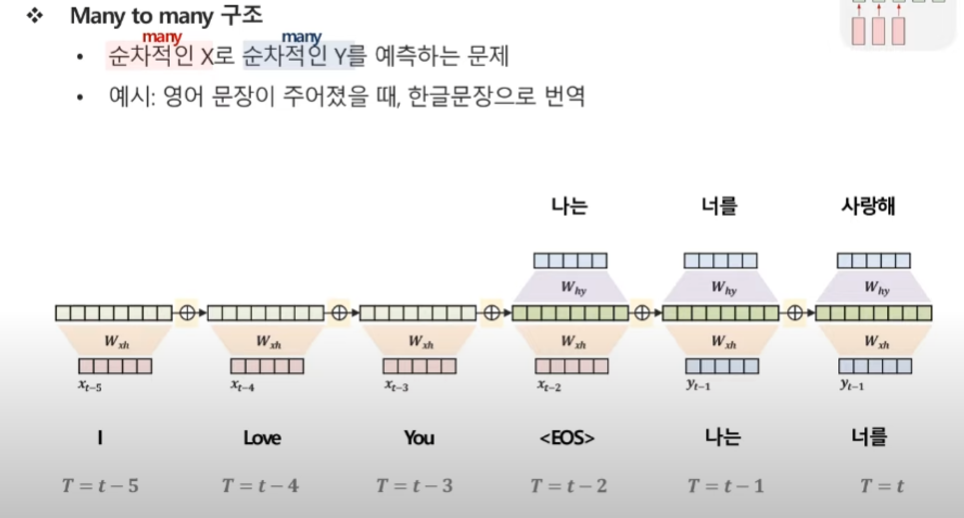
Many to Many(2)

영어 문장이 주어졌을 때, 한글 문장으로 번역
인코더 : 들어오는 입력부분
디코더 : 출력되는 부분
알쓸잡
디코더가 단어를 예측하려고 인코더의 마지막 시점 은닉층 정보(context vector,C)만을 활용.
중요도를 어떻게 정의할까? ⇒ 중요도 = 유사도 ⇒ 유사도 측도? 내적!
이런 구조를 Sequence to Sequence
잡것들
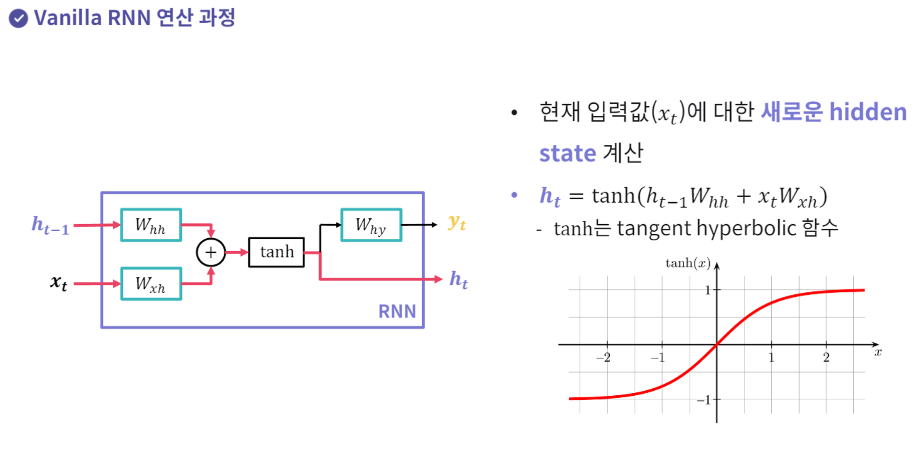
1.현재 입력값에 대한 새로운 hidden state 계산.
tanh에 통과한다. 왜? 곱하고 더하는 연산 = 선형 연산은 딥러닝 모델 성능에 좋지 않은 성질 → 활성화 함수를 통해 비선형성을 추가해줌
Hidden state의 의미
특정 시점 t 까지 들어온 입력값들의 상관관계나 경향성 정보를 압축해서 저장.
Parameter Sharing
Hidden state와 출력값 계산을 위한 FC layer를 모든 시점의 입력값이 재상용
FC Layer 세 개가 모델 파라미터의 전부
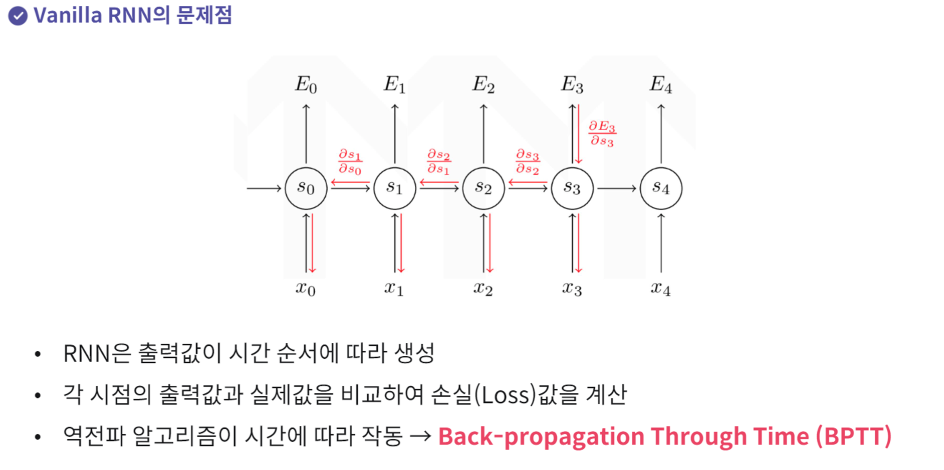
RNN의 문제점.
각 시점마다 손실함수를 따로 구한다. → 오차의 역전파 알고리즘이 시간에 따라 계산하게됨. → Backpropagation Through Time(BPTT)
입력값의 길이가 매우 길어질경우
기울기 값이 점점작아진다.
기울기 소실 문제가 발생한다.
RNN 모델을 구성할 때 무엇을 고려해야 할까
은닉 상태 크기 (hidden state size): RNN의 각 타임 스텝에서의 은닉 상태의 크기를 결정
입력 데이터의 차원: 모델에 입력되는 데이터의 특성 수를 정의
출력 데이터의 차원 (선택적): 모델이 어떤 형태의 출력을 제공해야 하는지에 따라 결정.
학습률, 에포크 수 등의 학습 관련 하이퍼파라미터: 모델 학습 과정을 조절하는 파라미터를 설정
초기화 방법: 가중치 초기화 방법을 선택하거나 사용자 정의
Rnn 가중치 뭐는 같고 뭐는 달라
RNN의 가중치는 학습 중에 업데이트됨.
RNN은 순환적인 구조를 가지며, 각 타임 스텝의 출력계층에서 입력 데이터와 이전 타임 스텝의 출력을 고려하여 예측을 수행.
이때 가중치는 역전파 알고리즘을 통해 학습 중에 조정됨
RNN의 hidden state와 활성화 함수는 각 타임 스텝에서 동일한 가중치 사용.
즉, RNN은 순환적으로 동작하면서 이전 타임 스텝의 hidden state를 현재 타임 스텝의 입력과 함께 사용하고, 이 작업은 동일한 가중치와 활성화 함수를 사용하여 수행
결론
- 입력에서 hidden state로의 가중치 (W_xh): 입력 데이터에서 hidden state로의 연결을 정의, 이 가중치는 각 타임 스텝에서 동일하게 사용
- 이전 hidden state에서 hidden state로의 가중치 (W_hh): 이전 타임 스텝의 hidden state에서 현재 타임 스텝의 hidden state로의 연결을 정의합니다. 이 가중치도 각 타임 스텝에서 동일하게 사용됩니다.
- hidden state에서 출력으로의 가중치 또는 출력 계층의 가중치 (W_hy): hidden state에서 실제 출력으로의 연결을 정의, 이 가중치는 각 타임 스텝에서 다를 수 있음. 즉, 각 타임 스텝에서 다른 출력을 생성.
요약하면, 입력에서 hidden state로의 가중치 (W_xh)와 이전 hidden state에서 hidden state로의 가중치 (W_hh)는 각 타임 스텝에서 동일하게 공유되며, hidden state에서 출력으로의 가중치 (W_hy)는 타임 스텝에 따라 달라질 수 있음
