참고 자료
Diffusion Model 수학이 포함된 tutorial
https://youtu.be/uFoGaIVHfoE?si=c6zYSyl_3Nq4GBHn
Diffusion Model 설명 – 기초부터 응용까지
https://ffighting.net/deep-learning-paper-review/diffusion-model/diffusion-model-basic/
본격적으로 Diffusion을 공부하기 앞서, intuition과 flow를 확립하기 위한 내용이다.
Diffusion이 뭔지, DDPM과 DDIM 맛보기, 그 외의 것들을 순서로 진행된다.
Diffusion이란?
확산 개념을 생각하면서 intuition을 가져보자.
눈을 감고 냄새가 확산되는 걸 상상해봐라
냄새분자를 떠올려라
그 분자는 어디로 퍼질까?
그게 가우시안 분포를 따라 확산된다고 생각해보자.
평균과, 표준편차만 알면 우린 가우시안 분포를 알 수 있다.
그럼 냄새 분자가 어디로 가는지도 알 수 있다.
역으로 생각해보면, 우리가 알고 있는 평균과 분산을 통해 확산된 냄새의 근원지를 알 수 있다.
뭐 이런 직관이 작용한다.
그래서 어떻게 사용되는데?
냄새분자를 노이즈라고 생각해보자.

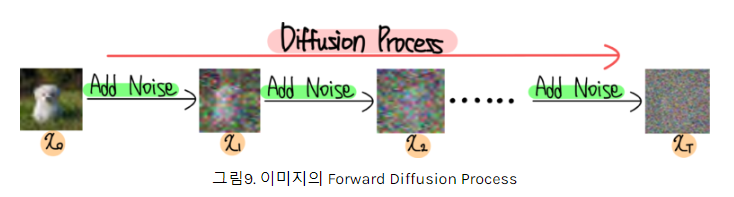
원본 Data에서 점차 Noise를 추가(냄새 확산)해서 Noise를 만든다(확산된 냄새)
Noise가 확산 되는 방향(가우시안분포)를 우리가 알고 있다면?(평균, 분산)
Noise(냄새)로 부터 Data(냄새의 근원지)를 알아 낼 수 있는 것이다.
DDPM
그러니까 Data(냄새의 근원지)를 어떻게 알아내냐면
= 이미지를 어떻게 생성하냐면
RGB image가 random한 값으로 채워져있다면 Noise 화면이 보일텐데,
거기서 Noise를 조금씩 분포를 따라 차근차근 걷어내서
이미지를 생성하는 것이다. 그래서 이름이 바로 DDPM!
Denoising Diffusion Probabilistic Models
근데 어차피 앞으로 신나게 논문을 읽으면서 자세히 설명 할 것 같으니
설명은 직관 위주로 흐름 잡는다는 생각으로 작성할 것이다.
- Forward Process (확산 과정): 원본 데이터에 점진적으로 노이즈를 추가하여 데이터를 표준 가우시안 분포로 변환한다.
각 단계에서의 노이즈 추가는 매우 작으며, 이 과정을 많은 단계에(1000단계 정도) 걸쳐 반복함으로써 데이터는 점차 노이즈로 변한다. 수식으로 표현하면 다음과 같다:
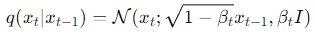
여기서 는 시간 단계 ()에서의 노이즈 수준을 조절하는 매개변수
-
Reverse Process (디노이징 과정): 노이즈가 포화된 데이터에서 시작하여, 딥러닝을 사용하여 원본 데이터로 점차 복원한다.
이 과정에서 각 단계는 이전 단계의 출력을 입력으로(Unet connection) 사용하며, 네트워크는 노이즈를 제거하는 방법을 학습한다. 수식으로 표현하면 다음과 같다: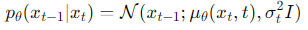
여기서 는 네트워크에 의해 학습된 평균을 나타내고, 는 고정된 분산이다.
Notation을 보면, 가 들어간걸 학습한다는걸 느낄 수 있다.

학습한 저것들을 이용해서, 우린 Sampling(Denoising : 이미지를 만들어가는 과정)을 한다.
각 time step에 대한 정보를 주기 위해 Positional encoding(sin,cos를 활용한)를 사용하고, 그걸 각 step마다 넘겨주는 다양한 기법을 사용하는데, 스킵 하겠다. 손실함수도 스킵. 마코브 체인을 이용해 뭐 다 생략하고 베이지안 룰 사용해서 이 식이 등장한다!라고 하는데 나중에하자 나중에. 지금은 초보니까.
밑에 DDIM이 마코브 체인을 사용 안하는 Idea로 나왔다.
DDIM: Denoising Diffusion Implicit Models
DDIM은 DDPM에서 발전된 모델로, 비마코브 체인(non-Markovian diffusion process)을 사용하여 각 단계에서 원본 데이터 에 직접 접근하는 것이 가능하다.
비마코브 체인의 적용
DDPM이 마코브 체인을 따라 이전 상태의 정보만을 이용하는 데 반해, DDIM은 모든 시간 단계에서 원본 데이터 와의 직접적인 관계를 유지한다.

수식적 표현
DDIM의 작동 원리를 수식으로 살펴보면 다음과 같다:
-
Forward Process:
- 는 에서 로의 전이 확률을 나타내며, 이 때 의 정보가 포함되어 있다.
-
Reverse Process:
- 는 과 의 정보를 바탕으로 를 복원하는 과정이다. 여기서 는 모델의 학습 파라미터이다.
이미지 복원의 차별점
DDIM의 이미지 복원 과정은 다음과 같이 진행된다:
-
Forward Process:
- 원본 데이터 에서 시작하여 점진적으로 노이즈를 추가해 가는 과정에서, 각 단계마다 원본 데이터의 정보를 활용한다는 점에서 DDPM과 큰 차이를 보인다.
-
Reverse Process:
- 노이즈가 가득한 상태에서 시작하여, 원본 데이터 와 이전 상태 의 정보를 결합하여 노이즈를 제거하고 원본 이미지를 복원한다.
효율성과 복원 정확도 면에서 DDPM에 비해 상당한 개선을 보여준다고 한다.
그 외 다양한 것들
ADM-G (Accelerated Denoising Diffusion Probabilistic Models with Guidance)
ADM-G는 가이던스 기술을 통합한 확산 모델의 변형이다. 기본적인 확산 모델에 조건부 생성이 가능한 가이드를 추가하여, 특정 조건을 만족하는 이미지를 더 정확하고 빠르게 생성할 수 있게 한다. 예를 들어, 특정 텍스트에 맞는 이미지를 생성하는 데 사용될 수 있다.
NCSN (Noise Conditional Score Network)
NCSN은 점수 기반 확산 모델 중 하나로, 데이터 분포의 점수 함수를 추정하여 노이즈를 제거하는 방법을 학습한다. 점수 함수는 데이터 분포의 기울기를 나타내며, 이를 통해 점진적으로 노이즈를 제거하고 데이터를 복원한다. 이 모델은 주로 이미지나 복잡한 자료의 복원과 생성에 사용된다.
Score-Based Models
점수 기반 모델은 데이터 분포의 점수 함수(또는 그래디언트)를 학습하여, 데이터 생성 과정에서 사용한다. 이러한 모델은 연속적인 확산 과정을 사용하여 점진적으로 노이즈를 증가시킨 후, 역과정에서 점수 함수를 활용하여 원본 데이터를 재생성한다. 점수 기반 방식은 다양한 데이터 유형에 대한 강력한 유연성과 성능을 제공한다.
그 외에도 Cascaded Generation, GLIDE, DALLE, Imagen, Diffusion Autoencoders, Super-Resolution, Semantic Segmentation 등 다양하게 활용 가능하다.
