Spring-데이터베이스(Oracle VS MySQL)
spring을 통해서 친구 추가 기능을 구현하기 위해 공부해보자.
가장 간단하게 설명해보자면 email을 입력하고 해당 email을 가지는 유저를 친구 추가하면 된다.
우선 데이터베이스를 구현해야 했다. 데이터베이스는 aws를 통해 rds를 활용하여 mysql을 사용하기로 했다.
aws에서 만든 rds의 엔드포인트와 workbench에서 만든 새로운 커넥션의 host ip를 일치시켜서 연결시킨다.
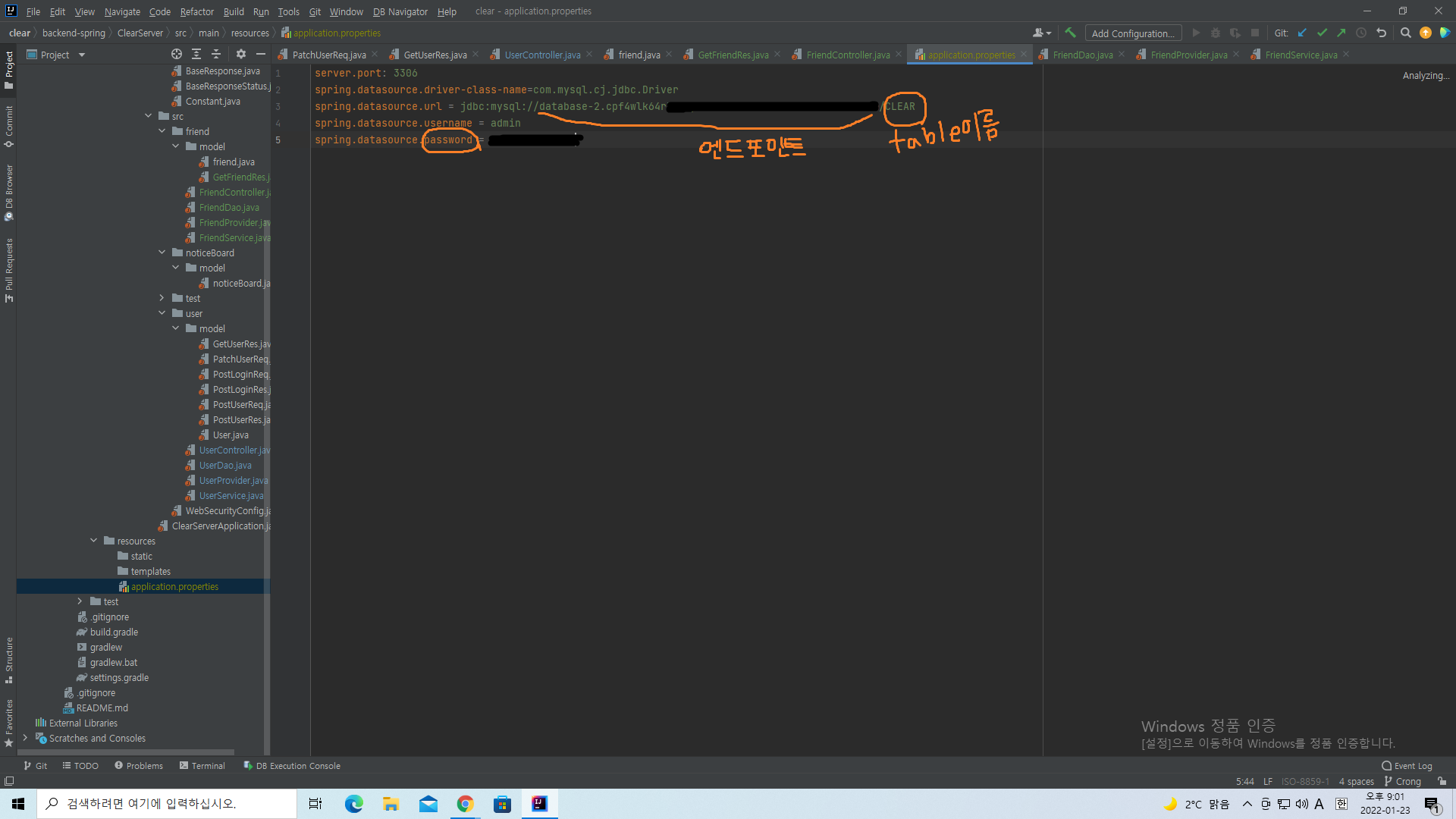
spring과도 연결시켜 보자. intellij에서 application.properties 파일에 workbench와 관련된 정보를 넣어 연결시킨다.

(application.yml 형식은 이렇게 중복되는 부분을 들여쓰기로 처리 가능하다.)
이렇게 하면 데이터베이스와 연결이 완료되었다.
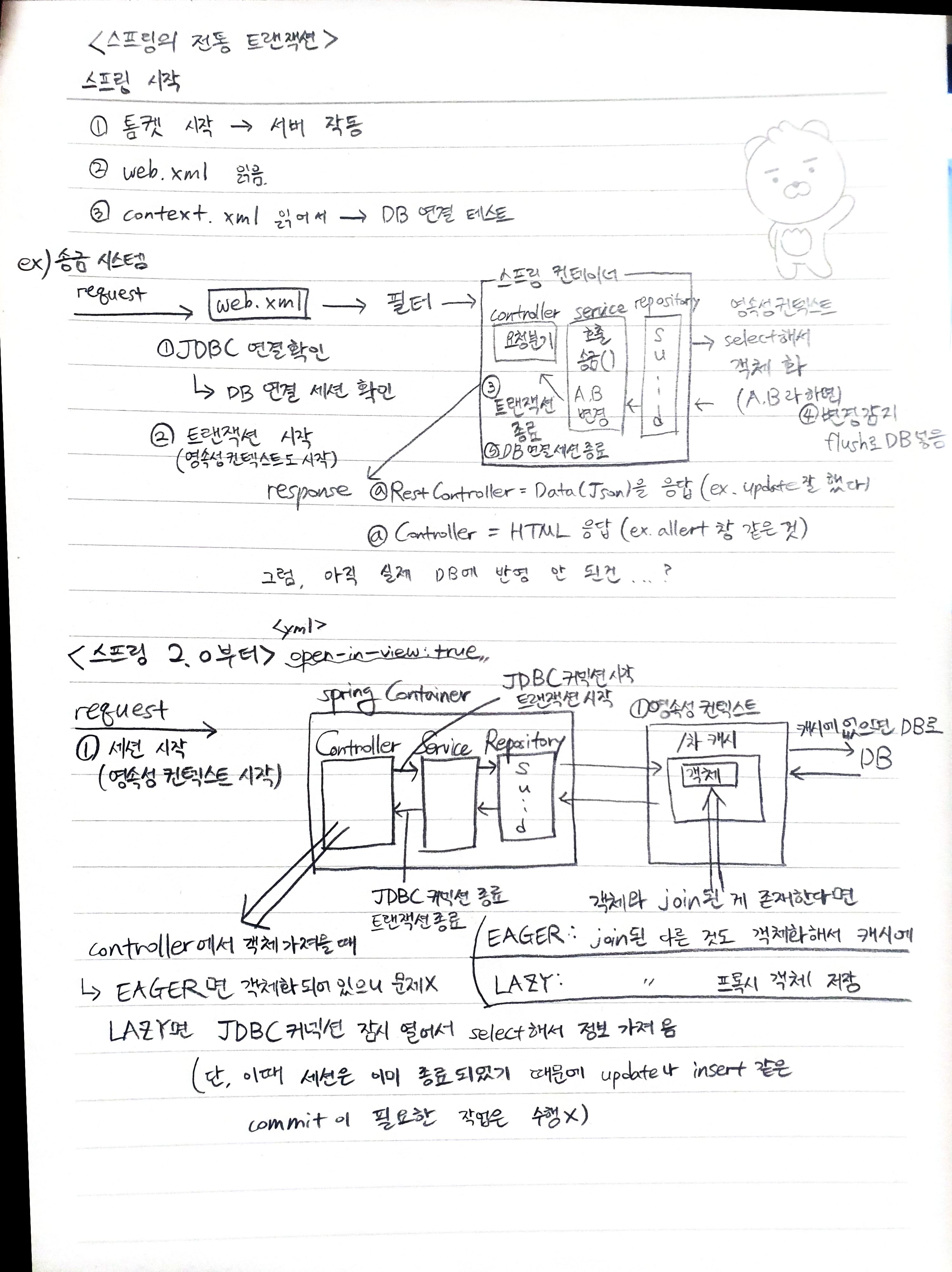
그렇다면 spring에서 DB와 관련된 개념에는 어떤 것이 있을까?
나는 mysql을 활용했지만 oracle과 mysql의 차이점은 어떤 것이 있을까?
다음은 유튜버 '메타코딩' 님의 강의를 듣고 정리한 내용입니다.
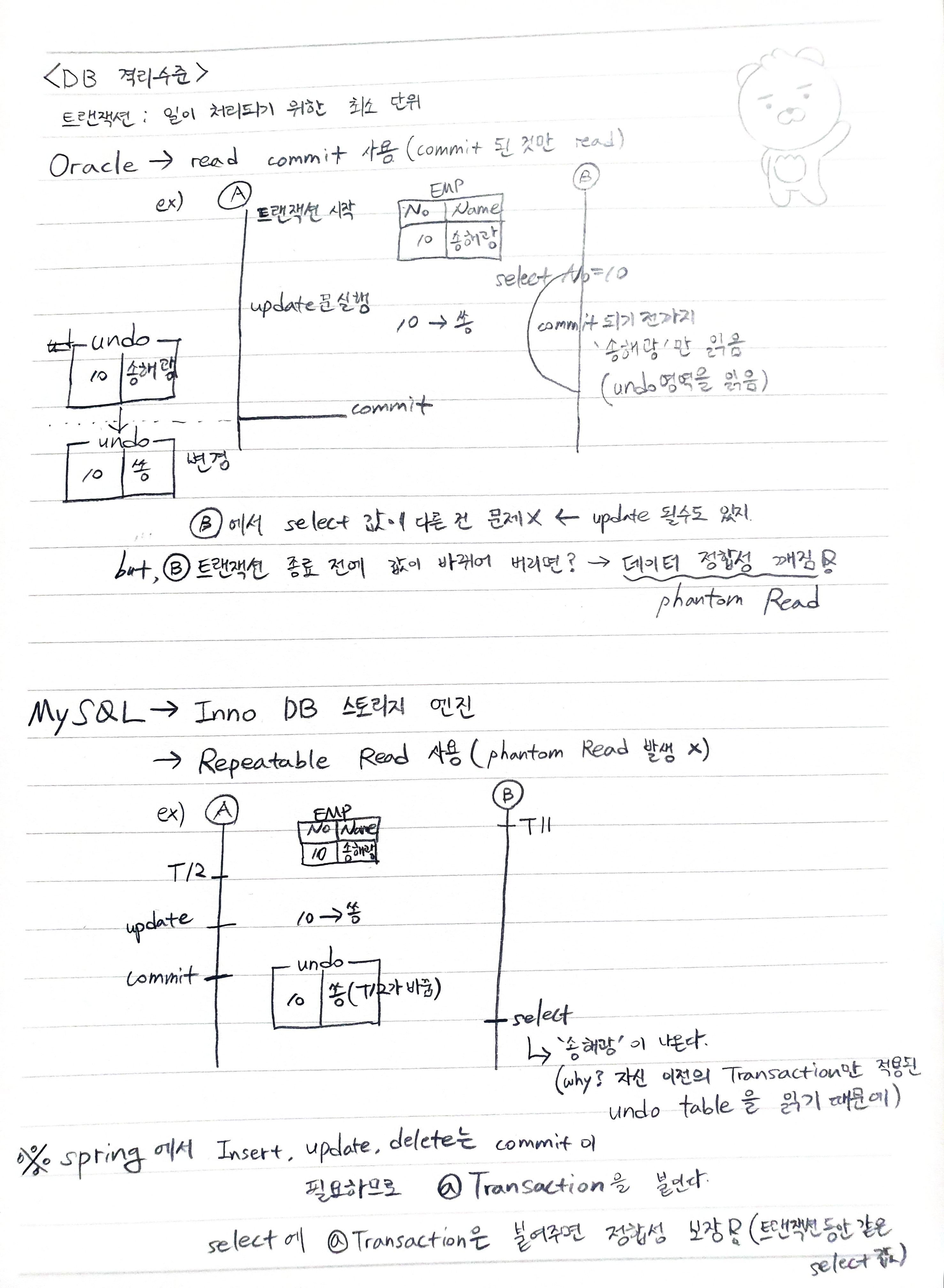
먼저, mysql과 oracle의 DB 격리 수준의 차이점에 대해서 살펴보도록 하자.
그림에 나와 있듯이 Oracle은 read commit 방식을 활용한다. commit 된 것만 read 한다는 의미이다.
아래 그림을 봐보자 A에서 10번에 해당하는 Name인 송해광을 쏭으로 바꾸기 위한 update문을 실행하였다.
근데 update문이 끝나기 전에 B에서 select 문을 실행하였고 아직 A에서 '쏭'으로 바뀌기 전이기 때문에 '송해광'을 읽는 것이다.
이 상황에서 가장 큰 문제는 B가 select로 읽기 시작할 때와 select 문의 종료 시점에서 값이 다른 상황이다. 이런 상황을 데이터 정합성이 깨졌다고 표현하고 phantom Read 현상이라고 표현한다.
이와 반면 MySQL은 Inno DB 스토리지 엔진을 사용하여 Repeatable Read 방식을 활용한다.
그림을 보면 Transaction11이 실행되고 나서 Transaction12가 update문을 실행하였고 '송해광'을 '쏭'으로 바꾸었다. 하지만 Transaction11은 No 10을 select하여 결과로 '송해광'을 얻는다.
왜 그럴까?
바로 자신 이전의 Transaction만 적용된 undo table을 읽기 때문이다.
이 경우에는 Transaction11이 실행되기 전까지 적용된 Transaction1 ~ Transaction10 까지의 결과만을 가지는 undo table을 읽기 때문에 update문이 실행된 Transaction12의 결과는 읽지 않는 것이다.
추가적으로, spring에서 read를 제외한 Insert, update, delete는 반드시 commit이 필요하기 때문에 @Transaction 어노테이션을 붙여주여야 한다.
select에 붙이는 Transaction 어노테이션은 정합성을 보장해준다(하나의 Transaction 동안 값을 select 값을 보장하기 때문이다)