문자집합
: 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
인코딩
: 문자들을 컴퓨터가 이해할 수 있는 0과 1로 변환하는 과정
디코딩
: 0과 1로 표현된 문자 코드를 사람이 읽을 수 있는 문자로 변환하는 과정
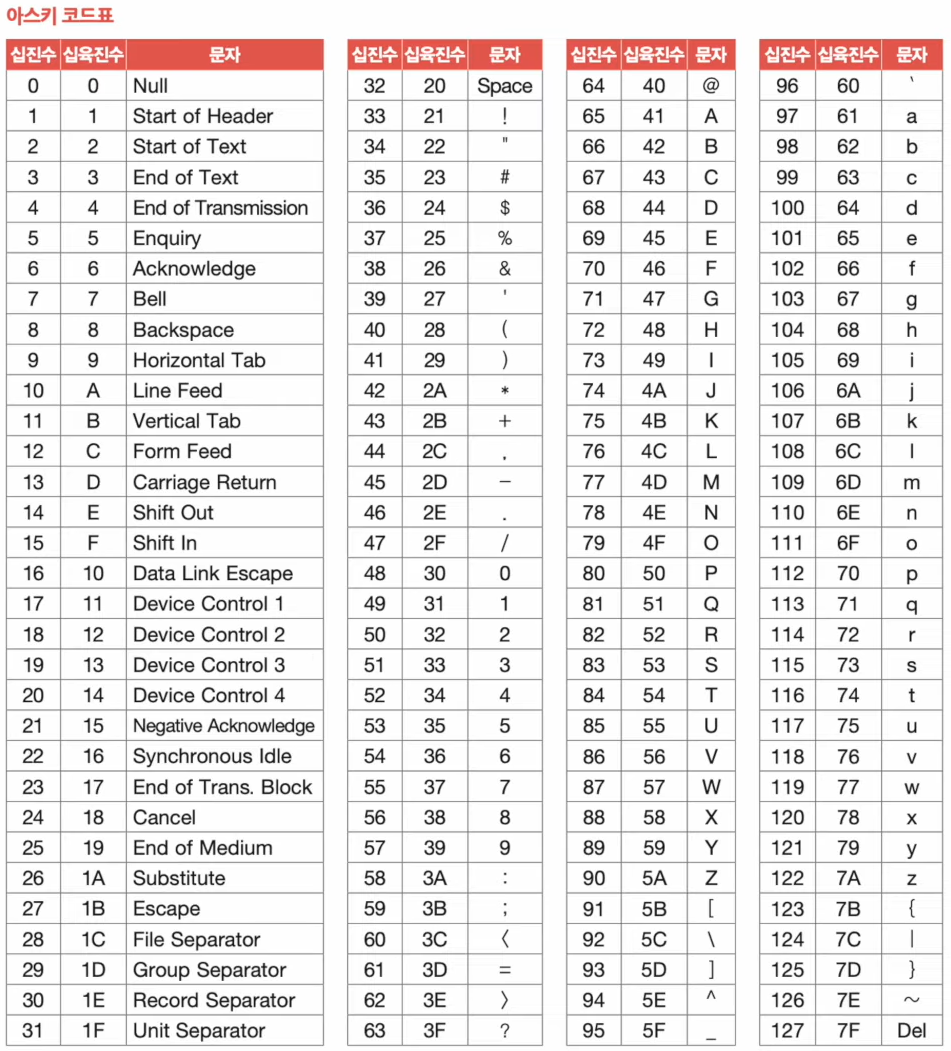
아스키 코드 (ASCII Code)
- 초창기 문자 집합 중 하나
- 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어 문자
- 7비트로 하나의 문자 표현 (8비트 중 1비트는 오류 검출을 위한
패리티 비트(parity bit))- 간단한 인코딩
- 단점
- 한글을 포함한 다른 언어 문자, 다양한 특수 문자 표현 불가
- 이유
- 7비트로 하나의 문자를 표현
- 128개보다 많은 문자를 표현할 수 없음
2⁷= 128
그래서 8비트 확장 아스키가 등장했지만 여전히 부족그래서 EUC-KR 등장
EUC-KR
- 한글을 위한 인코딩이 필요해서 생김
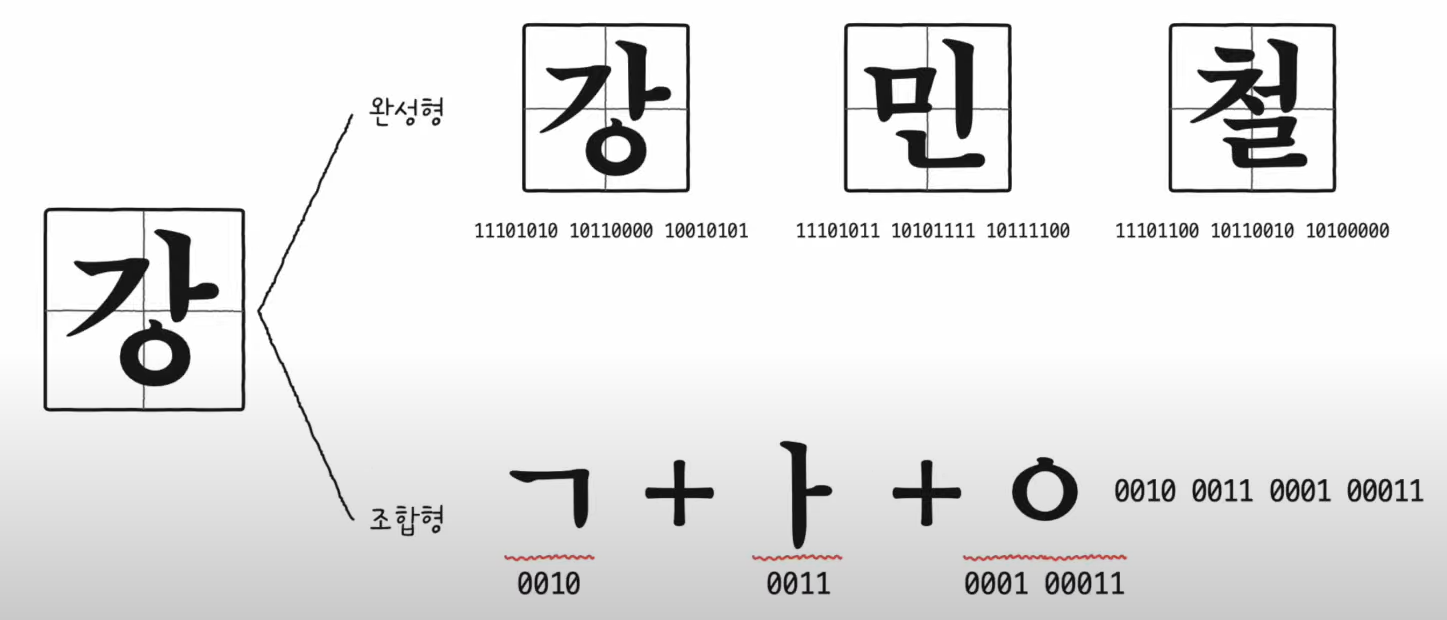
- 한글의 특징 반영(초성, 중성, 종성의 조합)
- KS X 1001 KS X 1003 문자집합 기반의 한글 인코딩 방식
- 완성형 인코딩
참고) 한글 인코딩에는 2가지 방식이 있음 (완성형, 조합형)
- 글자 하나당 2byte 크기의 코드 부여 (2byte==16bit임으로 4자리 16진수로 표현)
- 한계
- 2300개 정도의 한글 표현만 가능
- 쀏, 뙠 같은 한글 표현 불가능 (
근데 이런 단어를 쓰나?)- 다국어를 지원하는 프로그램을 개발한다면 언어별 인코딩 방식을 모두 고려해야함
그래서 유니코드 문자 집합과 utf-8 등장
유니코드
- 여러 나라의 문자를 광범위하게 표현할 수 있는 통일된 문자 집합
- 유니코드의 인코딩 방식
- utf-8, utf-16, utf-32 등등
UTF (Unicode Transformation Format)- utf-8 인코딩 방식
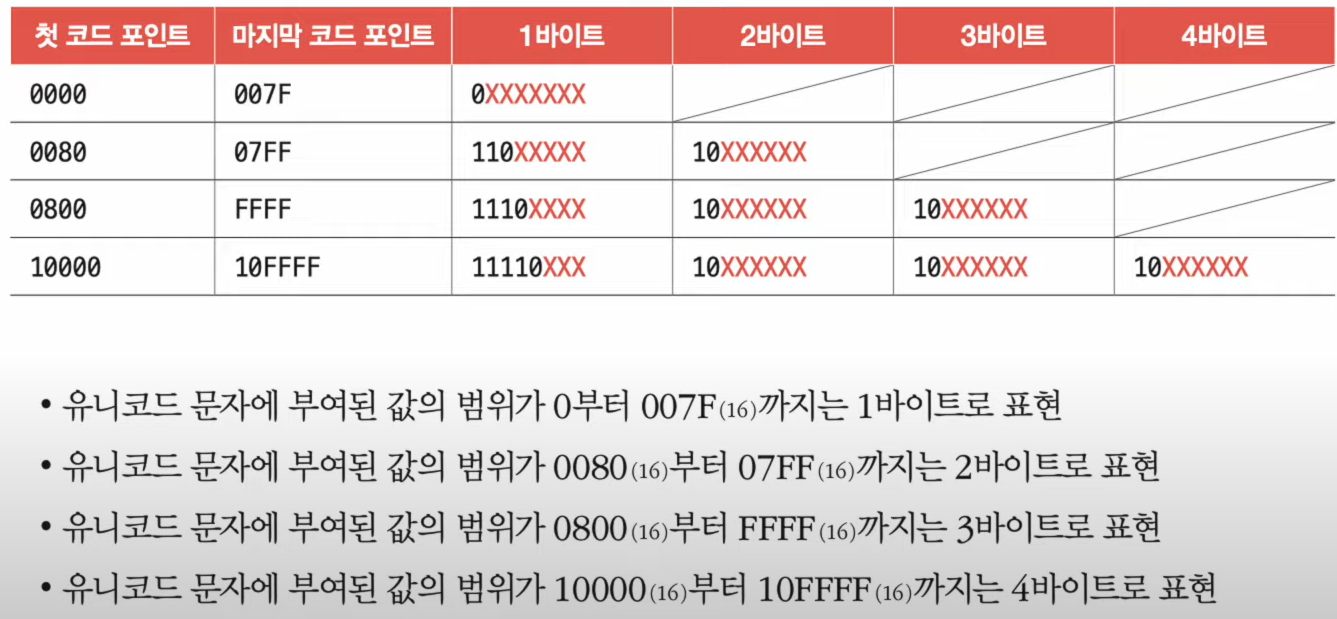
- 가변 길이 인코딩 (인코딩 결과가 1~4byte)
- 인코딩 결과가 몇 byte가 될지는 유니코드에 부여된 값(유니코드 코드 포인트)에 따라 다름
<출처>
"혼자 공부하는 컴퓨터구조+운영체제".강민철.https://www.youtube.com/playlist?list=PLVsNizTWUw7FCS83JhC1vflK8OcLRG0Hl (2023.04.01)
책과 강의를 통해 학습한 내용을 요약 정리했습니다.

인간은 적응의 동물