인코더-디코더 모델
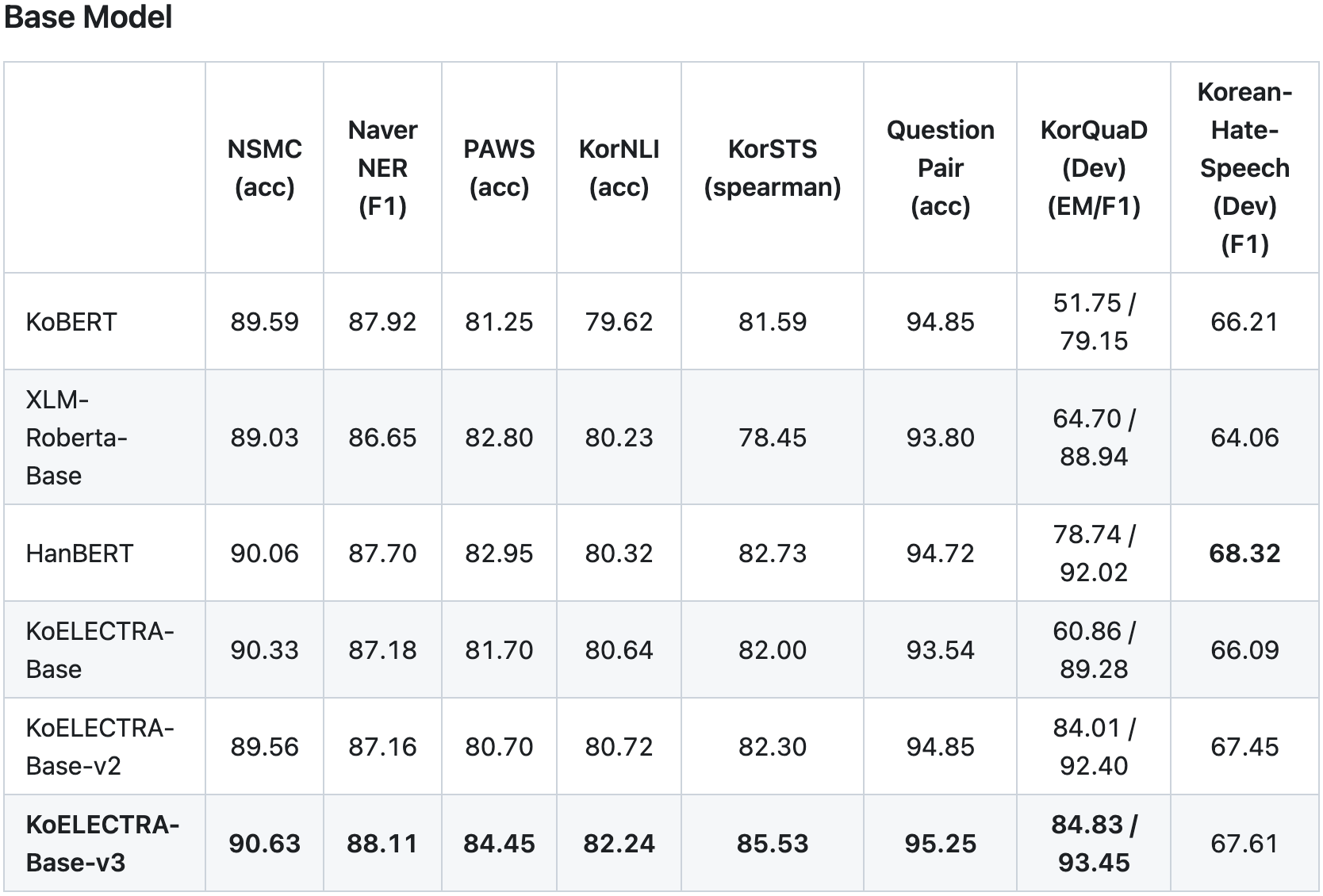
1. KoELECTRA
- Transformers 라이브러리만 있으면 모델을 곧바로 사용 가능합니다.
- Huggingface S3에 모델이 이미 업로드되어 있어서, 모델을 직접 다운로드할 필요 없이 곧바로 사용할 수 있습니다.
https://huggingface.co/monologg/koelectra-base-v3-discriminator
https://github.com/monologg/KoELECTRA
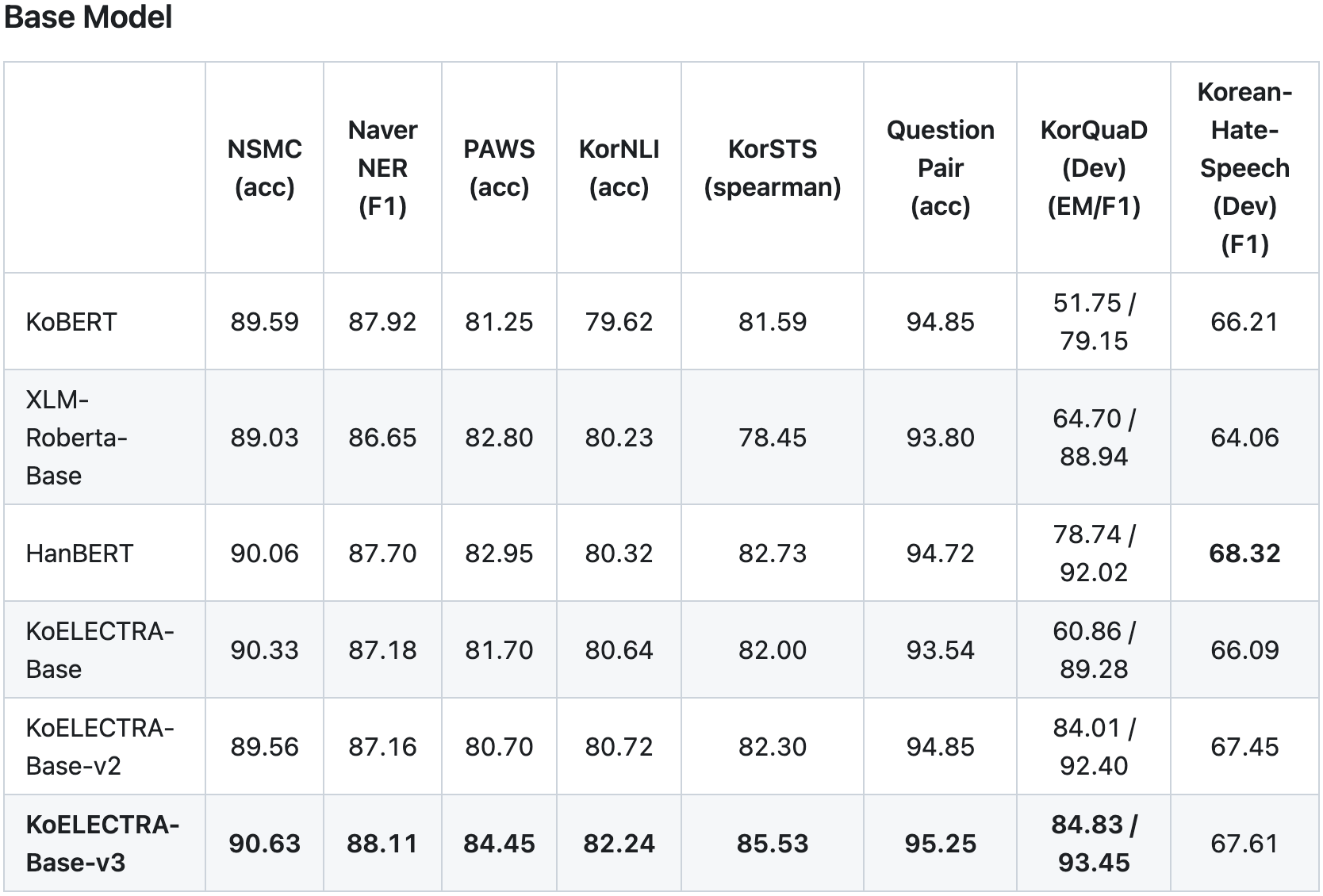
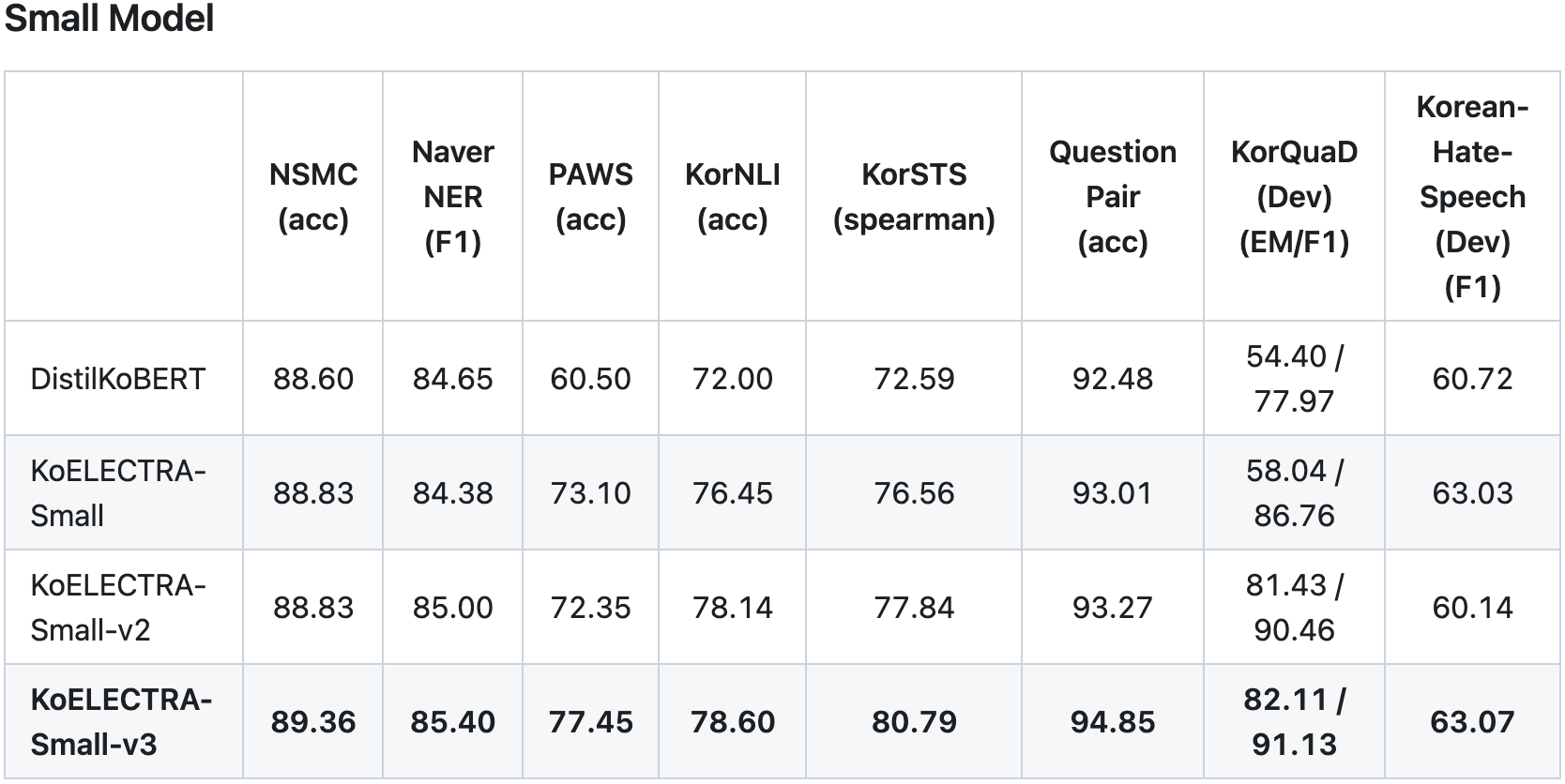
2. KcELECTRA
- 공개된 한국어 Transformer 계열 모델들은 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 User-Generated Noisy text domain 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
- KcELECTRA는 위와 같은 특성의 데이터셋에 적용하기 위해, 온라인 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 ELECTRA모델을 처음부터 학습한 Pretrained ELECTRA 모델입니다.
https://huggingface.co/beomi/KcELECTRA-base-v2022
https://github.com/Beomi/KcELECTRA

개발자