입력
첫째 줄에 반에 있는 학생의 수 n이 주어진다. (1 ≤ n ≤ 100)
다음 n개 줄에는 각 학생의 이름과 생일이 "이름 dd mm yyyy"와 같은 형식으로 주어진다. 이름은 그 학생의 이름이며, 최대 15글자로 이루어져 있다. dd mm yyyy는 생일 일, 월, 연도이다. (1990 ≤ yyyy ≤ 2010, 1 ≤ mm ≤ 12, 1 ≤ dd ≤ 31) 주어지는 생일은 올바른 날짜이며, 연, 월 일은 0으로 시작하지 않는다.
이름이 같거나, 생일이 같은 사람은 없다.
출력
첫째 줄에 가장 나이가 적은 사람의 이름, 둘째 줄에 가장 나이가 많은 사람 이름을 출력한다.
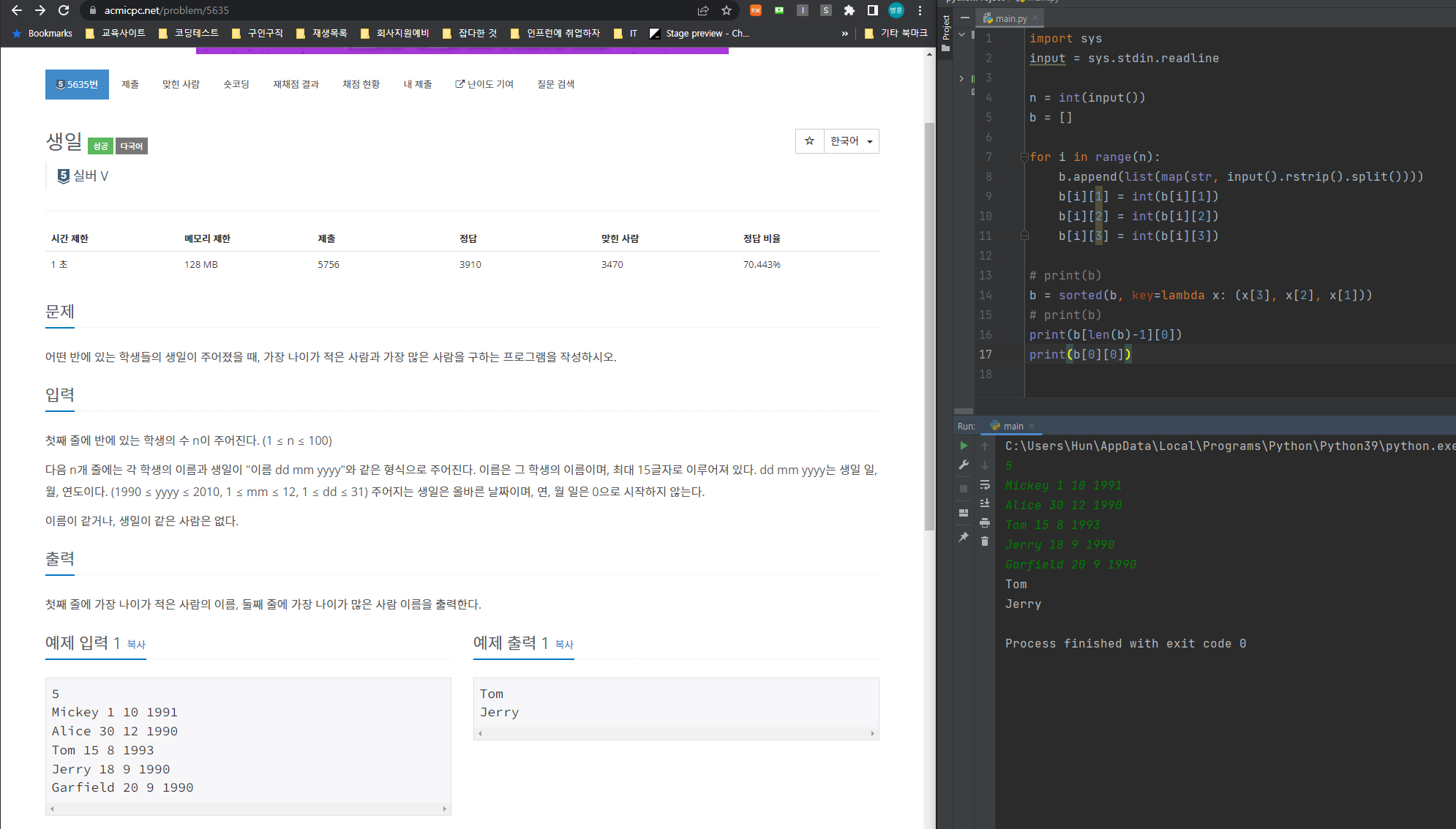
input = sys.stdin.readline 으로 정의함으로써
길게 써야 하는 일을 줄였다.
이렇게 해도 작동을 하나 궁금했는데, 잘 동작한다.
다른 분의 코드를 보고 배웠다.
b = []
b.append(list(map(str, input().strip().split()))))공백으로 입력받은 것은 str(문자열) 형식으로 순서대로 list에 저장하여 이 list를
b라는 list에 넣어 2차원 list를 만들었다.
생일의 일, 월, 연도가 str(문자열)로 저장되어서
나중에 lambda에서 제대로 비교해주기 위해
int형으로 형변환했다.
2차원 list의 정렬을 위해,
내부의 특정 index를 기준으로 list를 정렬할 수 있는 lambda를 사용했다.
b = sorted(b, key=lambda x: (x[3], x[2], x[1]))b라는 list를 lambda를 이용해 정렬한 후 다시 b에 저장하는 코드다.
뒤에 (x[3], x[2], x[1]) 가 2차원 list의 특정 index 순서대로 정렬하는 것인데
이 문제의 경우에는
x[3]은 '연도'로서, 연도를 기준으로 먼저 정렬한다.
x[2]은 '월'로서, 연도 후에는 월을 기준으로 정렬한다.
x[1]은 '일'로서, 월 다음 마지막에는 일자를 기준으로 정렬한다.
이 정렬을 위해 int형 형변환을 한 것이다.
형변환을 하지 않았다면 숫자로 보고 정렬하는 것이 아니라,
문자열로 보고 정렬된다.
결론
-
input = sys.stdin.readline
이 된다는 것을 알았다. 더 편하게 코드를 작성하고, 더 빠르게 실행시킬 수 있다!! -
빠르게 여러 입력을 받는 방법을 공부했다!!
list(map(str, input().strip().split()))) -
lambda에서 숫자를 기준으로 정렬하려면 그에 맞게 숫자형 형변환이 필요하다!!
-
lambda를 통해 2차원 list의 정렬을 할 수 있고, 특정 index들을 기준으로 정렬할 수 있다!!
